

Детали реализации: обучение симуляции Transic и сбор данных в реальном мире
4 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предварительные
3 Transic: передача политики с рисованием в реальность путем обучения на онлайн-коррекции и 3.1 базовые политики обучения в моделировании с RL
3.2 ОБУЧЕНИЯ ОТРИЦИЯ ПОЛИТИКИ ОТНОВЛЕНИЯ НАУКЦИИ
3.3 Интегрированная структура развертывания и 3,4 Подробности реализации
4 эксперименты
4.1 Настройки эксперимента
4.2 Количественное сравнение по четырем задачам сборки
4.3 Эффективность в решении различных разрывов с рисунком (Q4)
4.4 Масштабируемость с человеческими усилиями (Q5) и 4,5 интригующих свойств и возникающего поведения (Q6)
5 Связанная работа
6 Заключение и ограничения, подтверждения и ссылки
А. Подробная информация об обучении симуляции
Б. Реальные детали обучения в реальном мире
C. Настройки эксперимента и детали оценки
D. Дополнительные результаты эксперимента
Детали обучения симуляции
В этом разделе мы предоставляем подробную информацию о подготовке к моделированию, включая бэкэнд по использованию симулятора, проектирование задач, обучение обучению подкреплению (RL) политики учителей и дистилляции политики учащихся.
A.1 Симулятор
Мы используем Isaac Gym Preview 4 [10] в качестве бэкэнда симулятора. NVIDIA Physx [1] используется в качестве физического двигателя для обеспечения реалистичного и точного моделирования. Настройки моделирования перечислены в таблице A.I. Модель робота из пакета Franka ROS [2]. Мы заимствуем модели мебели из FurnitureBench [90], чтобы создать различные задачи, которые требуют сложных и богатых контактами манипуляции.

A.2 Реализация задач
Мы реализуем четыре задачи на основе квадратной таблицы модели мебели: стабилизация, достижение и захват, вставка и винт. Обзор смоделированных задач показан на рис. A.1. Мы подробно рассмотрим их начальные условия, критерии успеха, функции вознаграждения и другую необходимую информацию.
A.2.1 стабилизируется
В этой задаче робот должен подтолкнуть квадратную столешницу в правый угол стены, так что он поддерживается и остается стабильным при следующих этапах сборки. Робот инициализируется так, что его захватчик находится в нейтральном положении. Столета инициализируется на координате (0,54, 0,00) относительно базы роботов. Затем мы случайным образом переводим его с помощью смещений, взятых из u (-0,015, 0,015) вдоль направлений x и y (единица расстояния в дальнейшем). Мы также применяем случайное вращение Z со значениями, взятыми из U (-15 °, 15 °). Четыре ноги стола инициализированы в сцене. Задача успешна только при выполнении следующих трех условий:
Квадратная столешница контактирует с передними и правыми стенами;
Квадратная столешница находится в рамках заранее определенной области;
Никакая табличная нога не находится в предварительно определенной области.

A.2.2 Достигнуть и схватить
В этой задаче робот должен достичь и схватить столовую ногу, которая случайно порождена в действительной области рабочей области. Задача успешна, как только робот схватит столовую ногу и поднимает ее для определенного

высота. Нерегулярная форма объекта ограничивает определенные позы. Например, конечный эффектор должен быть почти ортогональным к столовой ноге в плоскости XY и далеко от резьбы винта. Поэтому мы разрабатываем учебную программу над геометрией объекта, чтобы согреть обучение RL. Он постепенно регулирует геометрию объекта от куба, кубоид и, наконец, на столовой ноге. На всех этапах учебной программы функция вознаграждения

A.2.3 Вставка
В этой задаче робот должен вставить предварительную столовую ногу в отверстие в правой правой сборе столешницы, в то время как столешница уже стабилизируется. Столета инициализируется на координате (0,53, 0,05) относительно базы роботов. Затем мы случайным образом переводим его с помощью смещений, отобранных из U (-0,02, 0,02) вдоль направлений x и y. Мы также применяем случайное вращение Z со значениями, взятыми из U (-45 °, 45 °). Кроме того, мы рандомизируем позу робота, добавляя шумы, отобранные из U (-0,25, 0,25) в положения сустава. Задача успешна, когда табличная нога остается вертикальной и находится близко к правильной позиции сборки в небольшом пороге. Мы разрабатываем учебные программы над силой рандомизации, чтобы облегчить обучение. Используется следующая функция вознаграждения:

А.2.4 Винт
В этой задаче робот инициализируется таким образом, что его конечный эффектор близок к вставленной таблице. Он должен прикрутить столовую ногу по часовой стрелке в столешницу. Мы разрабатываем учебные программы над пространством действий: на ранней стадии робот контролирует только ориентацию конечного эффекта; На последнем этапе он постепенно берет полный контроль. Мы слегка рандомизируем объект, а робот позирует во время инициализации. Функция вознаграждения

A.3 Обучение политике учителей
А.3.1 Детали модели
Пространство наблюденияПомимо проприоцептивных наблюдений, политика учителя также получают привилегированные наблюдения для облегчения обучения. Они включают в себя состояния объектов (позы и скорости), скорость Endeffecter, силы контакта, позиции левого и правого пальца, положение центрального центра и скорости соединений. Полные наблюдения суммированы в таблице A.II.
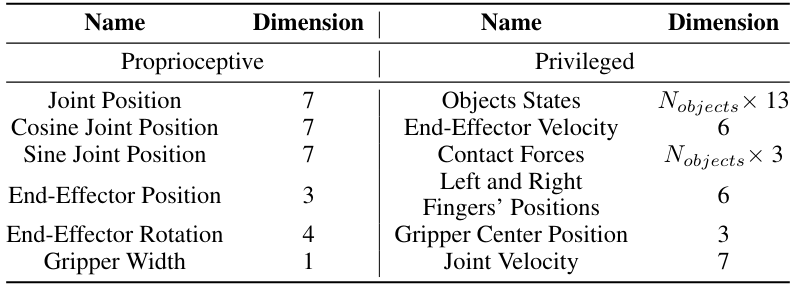

Модель архитектураМы используем политику кормления [155] в обучении RL. Он состоит из кодеров MLP для кодирования проприоцептивных и привилегированных векторных наблюдений, а также унимодальных гауссовых распределений в качестве главы действия. Модель гиперпараметры перечислены в таблице A.III.

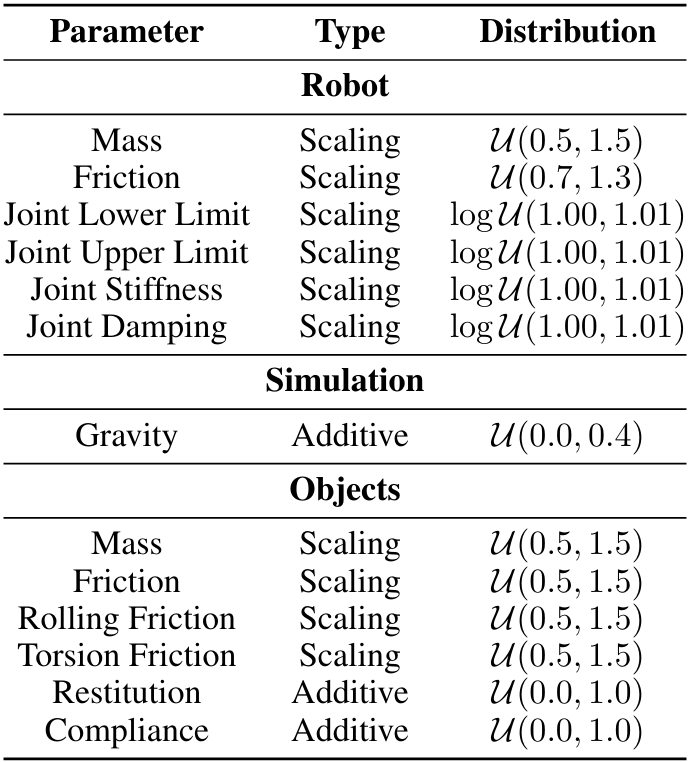
A.3.2 Рандомизация домена
Мы применяем рандомизацию домена во время обучения RL, чтобы изучить более надежную политику учителя. Параметры суммированы в таблице A.iv.
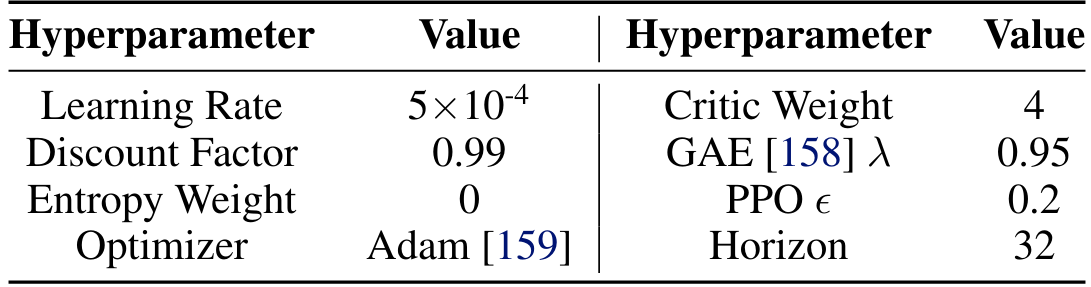
А.3.3 Р.Л. Детали обучения
Мы используем беззаботный алгоритм RL-алгоритма проксимальной политики (PPO) [84] для изучения политики учителя. Гиперпараметры перечислены в таблице A.V. Мы настраиваем структуру от Маковихука и Маковийчука [157], чтобы использовать в качестве нашей учебной структуры.
A.4 Дистилляция политики студентов
A.4.1 Генерация данных
Мы используем обученную политику учителя в качестве оракулов для создания данных для обучения политики учащихся. Конкретно, мы разрабатываем каждую политику учителя, чтобы получить 10 000 успешных траекторий для каждой задачи. Мы исключаем траектории, которые меньше 20 шагов.
A.4.2 Пространство наблюдения


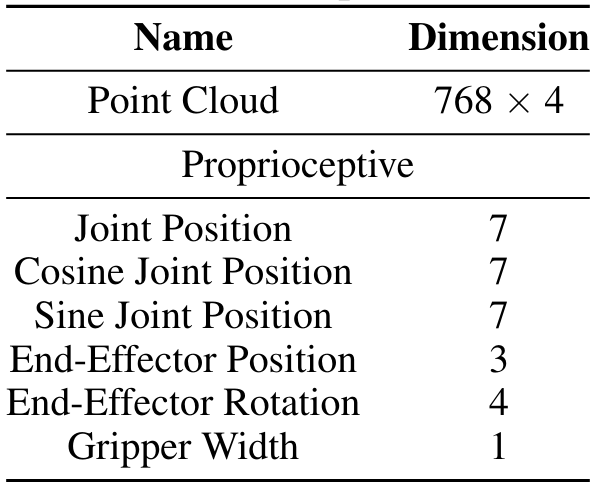
A.4.3 Действие.

A.4.4 Модель архитектура
Мы используем политику подачи на предмет задач, достигая и захвата и вставки и рецидивирующей политики для стабилизирующихся задач и винта, когда мы обнаруживаем, что они достигают наилучших результатов дистилляции. Pointnets [86] используются для кодирования точек облака. Напомним, что каждая точка в облаке точек также содержит семантическую метку, указывающую захватчик или нет. Мы объединяем координаты точек с векторными встроениями этих семантических ярлыков, прежде чем перейти в кодировщик точечной сети. Мы используем гауссовые модели смеси (GMM) [68] в качестве нажителя действия. Подробная модель гиперпараметры перечислены в таблице A.VII.
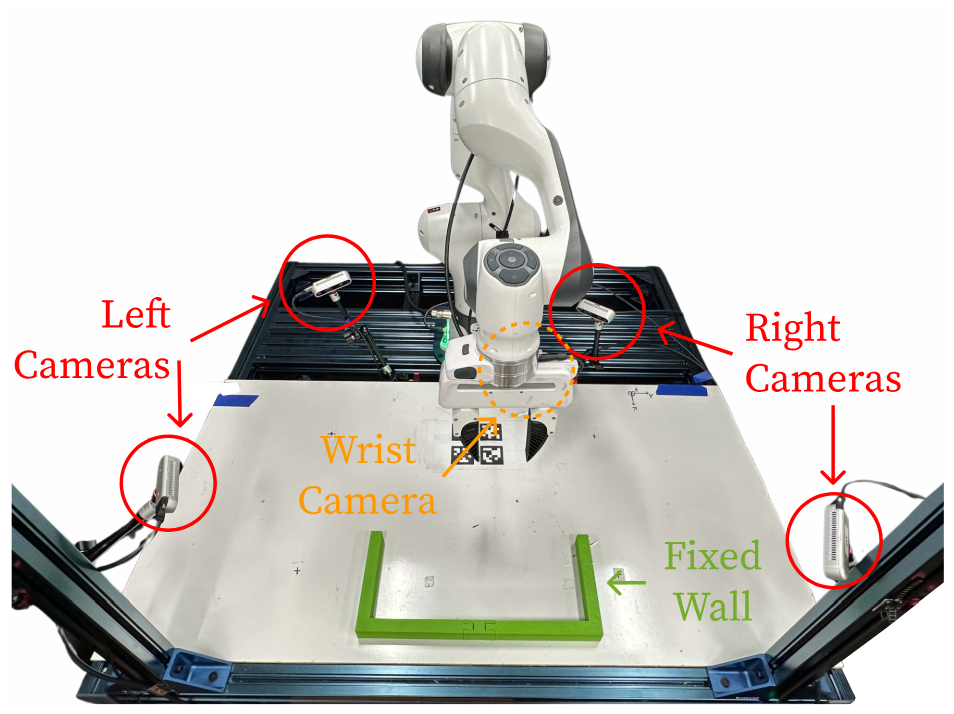

A.4.5 Увеличение данных

А.4.6 Подробная информация об обучении


B Реальные детали обучения
В этом разделе мы предоставляем подробную информацию о реальном обучении, включая настройку оборудования, сбор данных Humanin-the-петли и обучение остаточной политике.
B.1 Настройка оборудования
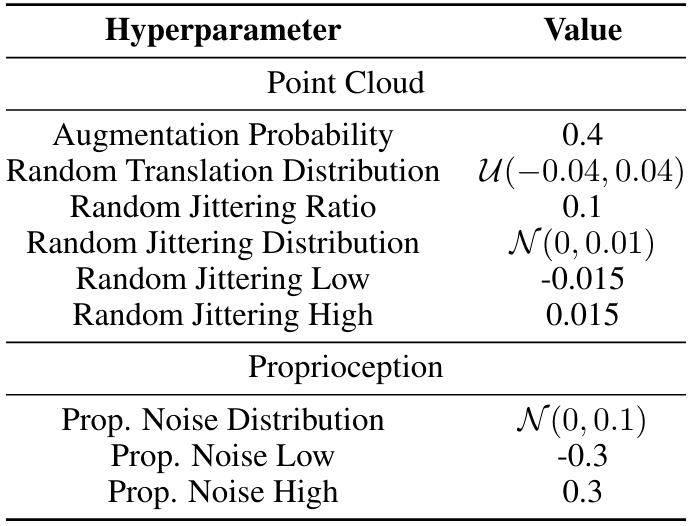
Как показано на рис. A.3, наша система состоит из робота Franka Emika 3, установленного на столешке. Мы используем четыре фиксированные камеры и одну запястье камеру для реконструкции облака точек. Это три RealSense D435 и два RealSense D415. На вершине стола также есть трехмерная трехсторонняя стена, приклеенной для обеспечения внешней поддержки. Мы используем мягкий захватчик для лучшего захвата (рис. A.4). Мы используем контроллер положения совместного положения из библиотеки Deoxys [162], чтобы контролировать нашего робота при 1000 Гц.
B.2
Мы используем несколько камер для реконструкции облака точек, чтобы избежать окклюзий. В частности, мы сначала калибруем все камеры, чтобы получить их позы в базовой раме робота. Затем мы трансформируем захваченные точечные облака в кадрах камеры в базовую раму робота и объединяем их вместе. Мы дополнительно выполняем обрезку на основе координат и удаляем статистические и радиусные выбросы. Чтобы идентифицировать точки, принадлежащие захватке, чтобы мы могли добавить семантические этикетки Gripper (г. Затем мы удаляем измеренные точки, соответствующие пальцам захвата, через ближайший сосед, учитывая позы пальцев и синтетические точки. Впоследствии мы добавляем семантические этикетки в точки, принадлежащие к сцене, и точечные облака синтетического захвата. Наконец, мы равномерно вниз по образцу без замены. Мы предпочитаем не использовать выборку на самую дальнюю точку [163] из -за ее медленной скорости. Один пример показан на рис. A.5.

B.3 Сбор данных человека в петле
Эта процедура сбора данных иллюстрирована в алгоритме 1. Как показано на рис. A.6, мы используем космическую зону 3DConnexion в качестве устройства телеоперации. Мы разрабатываем конкретный пользовательский интерфейс (рис. A.7) для облегчения сбора синхронизированных данных. Здесь человеческий оператор будет предложено вмешаться или нет. Оператор отвечает через клавиатуру. Если оператор не вмешивается, следующее действие базовой политики будет развернуто. Если оператор решает вмешаться, а затем активируется космическая машина для телеоперации робота. После коррекции оператор может выйти из режима вмешательства, нажав одну кнопку на Spacemouse. Мы используем эту систему и интерфейс для сбора 20, 100, 90 и 17 траекторий с коррекцией для стабилизирующихся задач, достижения и захвата, вставки и винта соответственно. Мы используем 90% из них в качестве данных обучения, а оставшиеся в качестве наборов проверки. Мы визуализируем кумулятивную функцию распределения коррекции человека на рисунке A.8.

B.4 Обучение остаточной политики
B.4.1 Модельная архитектура
Остаточная политика принимает те же наблюдения, что и базовая политика (таблица A.VI). Кроме того, для эффективного прогнозирования остаточных действий, оно также обусловлено результатами базовой политики. Его головка действий выводит восьмимерные векторы, в то время как первые семь измерений соответствуют остаточным положениям соединения, а последнее измерение определяет, следует ли отменить действие захвата базовой политики или нет. Кроме того, отдельная руководителя вмешательства предсказывает, следует ли применяться остаточные действия или нет (изученная закрытая остаточная политика, раздел 3.3).

Для стабилизирующихся задач и вставки мы используем точку [86] в качестве энкодера точечного облака. Для задач достигает и захвата и винта, мы используем восприятие [87, 88] в качестве кодера точкового облака. Остаточные политики создаются в качестве политики подачи во всех задачах. Мы используем GMM в качестве головки действий и простой двусторонний классификатор в качестве головки вмешательства. Модель гиперпараметры суммированы в таблице A.IX
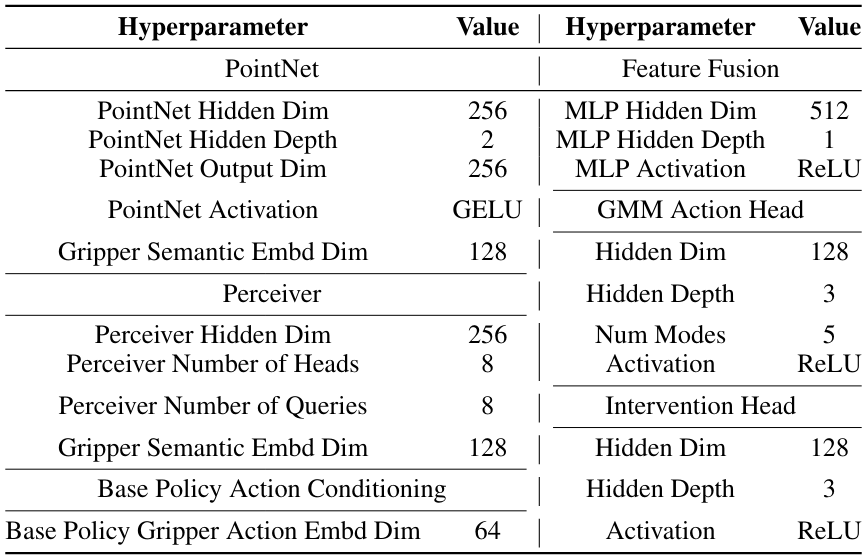
B.4.2 Подробности обучения
Чтобы обучить изученную закрытую остаточную политику, мы сначала изучаем только энкодер функции и главу действия. Затем мы замораживаем всю модель и только изучаем вмешательство. Мы выбираем это двухэтапное обучение, так как мы обнаруживаем, что обучение руководителей действий и вмешательства одновременно приведет к неоптимальному прогнозированию остаточных действий. Мы следуем наилучшей практике для обучения политике [98, 155, 164], включая использование скорости обучения и отжига косинуса [89]. Обучение гиперпараметры перечислены в таблице A.X.


Авторы:
(1) Юнфан Цзян, факультет информатики;
(2) Чен Ван, кафедра компьютерных наук;
(3) Руохан Чжан, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(4) Цзяджун Ву, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(5) Ли Фей-Фей, Департамент информатики и Институт ИИ, ориентированного на человека (HAI).
Эта статья есть
[1] https://developer.nvidia.com/physx-sdk
[2] https://github.com/frankaemika/franka_ros
Оригинал