
ICE-T превосходит нулевой выставки в задачах NLP в нескольких доменах
11 июня 2025 г.Авторы:
(1) Горан Мурич, Inferlink Corporation, Лос -Анджелес, (Калифорния gmuric@inferlink.com);
(2) Бен Зал, Inferlink Corporation, Лос -Анджелес, Калифорния (bdelay@inferlink.com);
(3) Стивен Минтон, корпорация Inferlink, Лос -Анджелес, Калифорния (sminton@inferlink.com).
Таблица ссылок
Аннотация и 1 введение
1.1 Мотивация
2 Связанная работа и 2,1 методы подсказки
2.2 Внутреннее обучение
2.3 модели интерпретируемость
3 Метод
3.1 Создание вопросов
3.2 Подсказка LLM
3.3. Сорбализация ответов и 3.4 Обучение классификатора
4 данные и 4.1 клинические испытания
4.2 Корпус независимости Каталонии и 4.3 Корпус обнаружения климата
4.4 Данные по медицинскому здоровью и 4.5 Данные Европейского суда по правам человека (ECTHR)
4.6 Набор данных Necure-Tos
5 экспериментов
6 результатов
7 Обсуждение
7.1 Последствия для интерпретации модели
7.2 Ограничения и будущая работа
Воспроизводимость
Подтверждение и ссылки
Вопросы, используемые в методе ICE-T
6 результатов
Результаты экспериментов по классификации обобщены в таблице 1. Мы можем видеть, что во всех наборах данных метод ICE-T последовательно превосходит подход с нулевым выстрелом в производительности для данных языковых моделей. В частности, использование модели GPT-3.5, средний µF1 для подхода с нулевым выстрелом составляет 0,683, но она увеличивается до 0,845 с помощью метода ICET. Подобная тенденция наблюдается с более крупной моделью GPT-4, где средний показатель F1 улучшается с 0,7 с использованием нулевого выстрела до 0,892 с помощью метода ICE-T. Это улучшение не является постоянным для наборов данных, так как мы видим значительные различия в производительности и в улучшении в разных задачах.
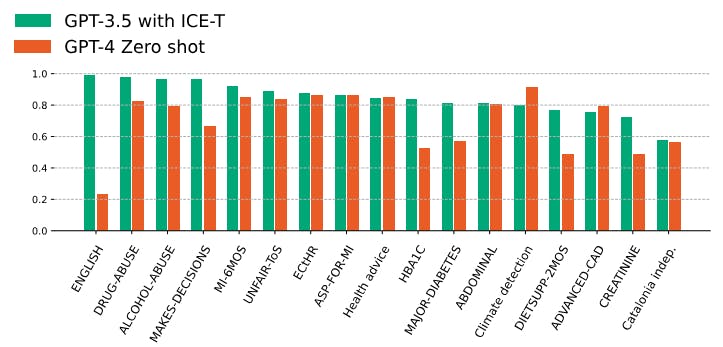
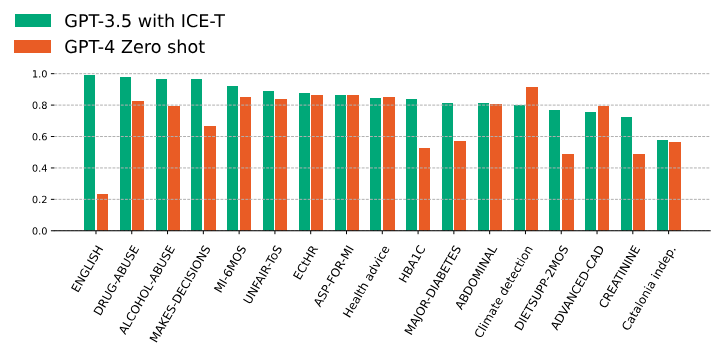
Верхняя часть таблицы 1 демонстрирует результаты из набора данных клинических испытаний, как подробно описано в разделе 4. Содержание набора данных остается последовательным во всех подзаголках в этом наборе данных клинических испытаний, хотя каждая подзадача включает в себя отдельный критерий классификации, основанный на 12 различных критериях. В некоторых подзадатах существенные улучшения наблюдались по методу нулевого выстрела. Например, в задаче креатинина (включающего уровни креатинина в сыворотке, превышающий верхний нормальный предел), метод нулевого выстрела достиг µF1 0,349. Напротив, метод ICE-T, использующий ту же модель большой языка, значительно улучшила этот балл до 0,721. Аналогичным образом, для английского языка (определение того, говорит ли пациент по-английски) с использованием более крупной модели GPT4, наибольшее увеличение отмечено, превышало 0,733 балла, при этом подход с нулевым выстрелом при µF1 0,233 и техника ICE-T, улучшающий его до 0,966. Анализ задач за пределами набора данных клинических испытаний выявил различные результаты, зависящие от конкретного домена. Задача, оценивающая «Независимость каталонии», представила заметную проблему в установке с нулевым выстрелом для обеих моделей, что едва достигло µF1 выше 0,5, без значительных улучшений, отмеченных методом ICE-T.
Задача, связанная с Европейским судом по правам человека (ECTHR), уже демонстрировала высокие базовые оценки в обстановке с нулевым выстрелом, достигнув 0,853 с GPT-3,5 и 0,861 с GPT-4. Применение метода ICE-T дало минимальное улучшение, причем обе модели достигли µF1 0,873. Аналогичный сценарий наблюдался с набором данных консультаций по здоровью, где усовершенствования были незначительными.
Тем не менее, задача несправедливости продемонстрировала значительное улучшение с использованием подхода ICE-T, особенно с моделью GPT-3.5. Здесь оценка µF1 наблюдается резкое увеличение с 0,335 до 0,887.
Кроме того, наш анализ показывает, что метод ICE-T при применении к меньшей модели может превзойти или соответствовать производительности более крупной модели, которая использует подход с нулевым выстрелом. В наших экспериментах мы оценили µF1 задач классификации, выполняемых GPT-4 в нулевом выстреле против тех, которые выполняются GPT-3.5 с использованием метода ICE-T в различных наборах данных. Почти во всех случаях, за исключением двух, GPT-3,5 ICE-T, превзошли или сравнял более крупную модель GPT-4 по идентичным задачам. Эти результаты изображены на рисунке 2.
Мы наблюдали незначительные различия в производительности в разных задачах. Категоризируя задачи клинических испытаний на одну группу и другие задачи в другую, мы наблюдали сопоставимое улучшение средней производительности при сравнении нулевого выстрела с подходом ICE-T, как подробно описано в таблице 4 в Приложении B. Эта согласованность не затрагивает универсальность метода ICE-T в различных доменах и задачах.
Чтобы изучить, как количество функций влияет на оценку Micro F1 (µF1), мы провели дополнительный анализ чувствительности. Результаты этого
Анализ изображен на рисунке 3. Этот рисунок иллюстрирует изменение µF1, поскольку мы постепенно вводим больше функций (полученные вторичными вопросами). Сплошная апельсиновая линия показывает среднюю µF1 во всех наборах данных, в то время как окружающая заштрихованная область указывает на одно стандартное отклонение от среднего значения, основываясь на 100 итерациях. Как и ожидалось, существует последовательное увеличение показателя Micro F1 с добавлением более вторичных вопросов. В среднем, добавление трех вторичных вопросов увеличивает оценку µF1 с 0,76 до 0,80, при этом дополнительные дополнения повышают его до 0,82.
Важно подчеркнуть, что эта рисунок в среднем является результатом 17 различных наборов данных, используя только случайный классификатор леса. Подробные результаты для каждой отдельной задачи доступны на рисунке 4 в Приложении B. Использование одного классификатора в этом анализе стало преднамеренным выбором для выделения влияния увеличения количества функций, что минимизирует влияние выбора классификатора на результаты. Однако этот выбор также может ограничить обобщение результатов, так как он отличается от предыдущих анализов, где для каждой задачи был выбран оптимальный классификатор.
Эта статья есть
Оригинал