

Как мы прошли предварительно обучение аудиоканатора параметров 300 м со случайным квантованием
20 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
A.1 Audio Encoder перед тренировкой
Наш аудиокодер представляет собой 24-слойную конформерную модель с измерением признаков 768 и главой внимания 8. Общее количество параметров этой модели энкодера составляет 300 м. Мы принимаем метод лучшего RQ [33], который предварительно обучает модель для прогнозирования маскированных речевых сигналов с этикетками, сгенерированными из квантолизации случайной проекции. Квантизатор проецирует вводы речи с случайно инициализированной матрицей и выполняет поиск ближайшего соседа в случайно инициализированной кодовой книге. Ни матрица проекции, ни кодовая книга не обновляются во время предварительного обучения. Мы строим внутренний набор данных перед тренировкой, содержащий 300 тыс. Часов английского аудио. В предварительном тренировке используется пролет маски 10 с общим эффективным коэффициентом маскировки около 40%. График ставки обучения следует графику скорости обучения трансформаторах с пиковым значением 0,0005 и разминкой 50 тыс. Шагов. Adamw Optimizer принят с распадом веса 0,01. Поскольку энкодер имеет 4 раза снижение временного измерения, квантование со случайными проекциями стекает каждые 4 кадра для проекций. Мы используем 16 отдельных кодовых выпусков, где размер слока каждой кодовой книги составляет 8192, а измерение-16. Модель предварительно обучена для 500 тыс. Всего.
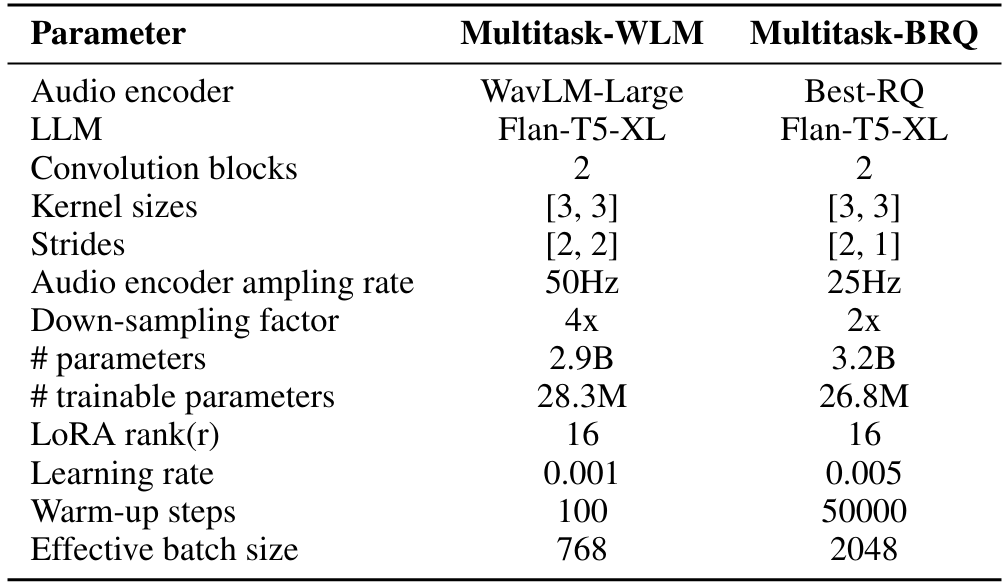
A.2 Гиперпараметры
Мы тренируем все наши модели на группе машин с 8 A100 графическими процессорами, каждый из которых имеет 40 ГБ памяти. Fytorch Lightning Framework [3] используется для нашей реализации. 5% подмножество полного обучающего набора данных для модели используется в качестве набора валидации для выбора важных гиперпараметров. Для многозадачных моделей веса выборки для каждого набора данных также выбираются с использованием этого набора валидации. Кроме того, все модели обучаются до тех пор, пока не сходится потери проверки, и не улучшается в течение 5 последовательных эпох. Подробная информация о скорости обучения, шагов разминки, размера партии для многозадачного WLM и многозадачного BR size = 3, stride = 2) для модели Task-FT и Multysk-WLM, чтобы понизить аудио четыре раза и достичь желаемой скорости отбора проб 12,5 Гц. Для BestRQ аудиокодера на основе базы, скорость отбора проб составляет 25 Гц, и, следовательно, шаг второго сверткого блока установлен на 1, чтобы обеспечить скорость выходной выборки 12,5 Гц.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал