
Как TripAdvisor обеспечивает персонализацию в реальном времени в масштабе с ML
23 июля 2025 г.Посмотрите на инженерию персонализации в режиме реального времени в масштабе TripAdvisor's Massive (и быстро растущего) масштаба
Какой ты путешественник? TripAdvisor пытается оценить это, как только вы взаимодействуете с сайтом, а затем предлагаете вам все более актуальную информацию при каждом клике - с вопросом миллисекунды. Эта персонализация оснащена передовыми моделями ML, действующими на данные, которые хранятся на Scylladb, работающих на AWS.
В этой статье Дин Полин (TripAdvisor Data Engineering Lead в команде службы услуг и продуктов ИИ) дает представление о том, как они прикрепляют эту персонализацию. Дин разделяет вкус технических проблем, связанных с реализацией персонализации в режиме реального времени в масштабных (и быстро растущих) масштабах TripAdvisor.
Он основан на следующем AWS Re: Invent Talk:
Ориентация перед поездкой
По словам Дина ...
Давайте начнем с быстрого снимка того, кто такой TripAdvisor, и масштаб, в котором мы работаем. Основанная в 2000 году, TripAdvisor стал мировым лидером в области путешествий и гостеприимства, помогая сотням миллионов путешественников планировать свои идеальные поездки. TripAdvisor приносит доход более 1,8 млрд. Долл. США и является публичной компанией на фондовой бирже NASDAQ. Сегодня у нас есть талантливая команда из более чем 2800 сотрудников, которые водят инновации, и наша платформа обслуживает ошеломляющие 400 миллионов уникальных посетителей в месяц - число, которое постоянно растет.
В любой день наша система обрабатывает более 2 миллиардов запросов от 25 до 50 миллионов пользователей. Каждый щелчок, который вы делаете на TripAdvisor, обрабатывается в режиме реального времени. За этим мы используем модели машинного обучения для предоставления персонализированных рекомендаций - приближая вас к этой идеальной поездке. В основе этого движения персонализации лежит Scylladb, работающий на AWS. Это позволяет нам доставлять миллисекундную латтность в масштабе, который достигают немногие организации. При пиковом движении мы ударили425K Operations в секунду на SCYLLADB с задержками P99 для чтения и пишет около 1-3 миллисекунд.Полем
Я расскажу, как TripAdvisor использует силу Scylladb, AWS и машинного обучения в реальном времени, чтобы предоставить персонализированные рекомендации для каждого пользователя. Мы рассмотрим, как мы поможем путешественникам обнаружить все, что им нужно, чтобы спланировать их идеальную поездку: будь то обнаружение скрытых драгоценных камней, обязательных достопримечательностей, незабываемых впечатлений или лучших мест для отдыха и пообедать. Эта [статья] о инженерии, стоящей за этим - как мы доставляем бесшовный, актуальный контент для пользователей в режиме реального времени, помогая им точно найти то, что они ищут как можно быстрее.
Персонализированное планирование поездки
Представьте, что вы планируете поездку. Как только вы попадаете на домашнюю страницу TripAdvisor, TripAdvisor уже знает, является ли вы гурманом, авантюристом или любителем пляжа-и вы видите точные рекомендации, которые кажутся персонализированными для ваших собственных интересов. Как это происходит за миллисекунд?

Пока вы просматриваете TripAdvisor, мы начинаем персонализировать то, что вы видите, используя модели машинного обучения, которые рассчитывают оценки на основе вашей текущей и предшествующей деятельности просмотра. Мы рекомендуем отели и опыт, которые, по нашему мнению, вам будут интересоваться. Мы сортируем отели на основе ваших личных предпочтений. Мы рекомендуем популярные интересы возле отеля, который вы просматриваете. Все они настроены на основе ваших личных предпочтений и предварительного просмотра.
Модель TripAdvisor модели служащей архитектурой
TripAdvisor работает по сотням независимо масштабируемых микросервисов в Kubernetes в Prem и Amazon EKS. Наша модель ML -модель, представленная через один из этих микросервисов.
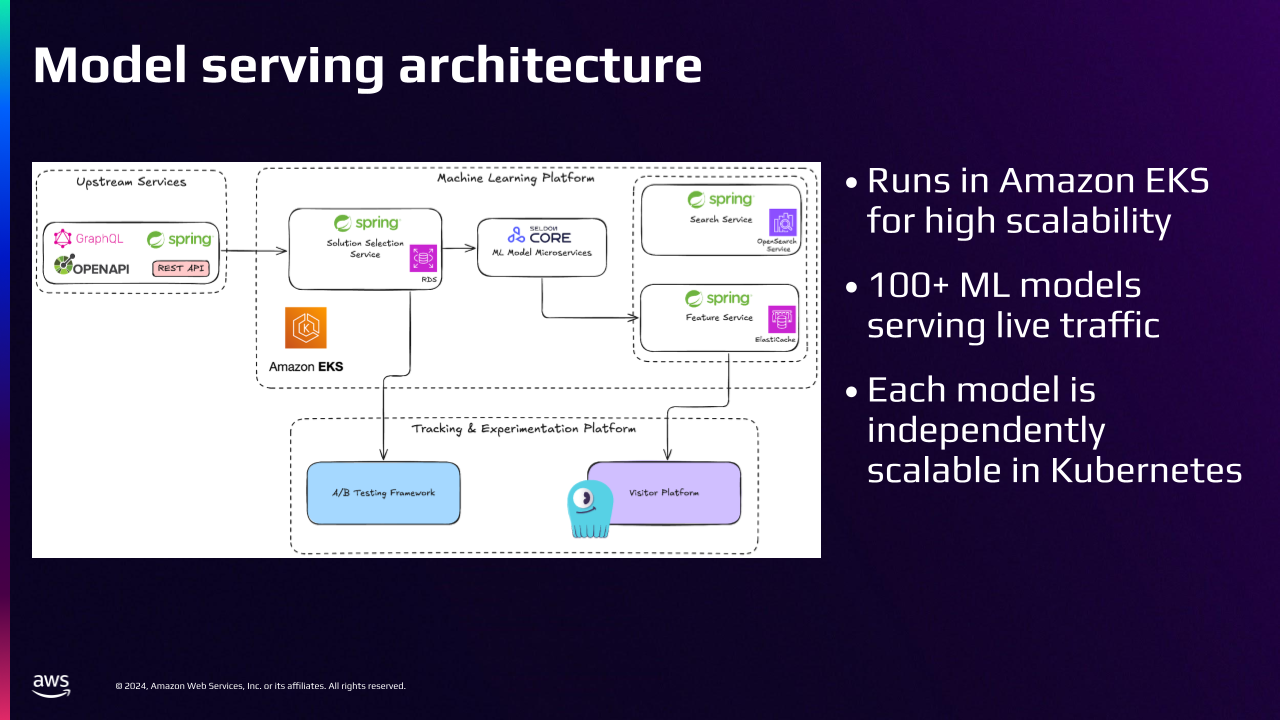
Этот сервис шлюза реферирует более 100 мл моделей от клиентских служб, что позволяет нам запускать A/B -тесты, чтобы найти лучшие модели, используя нашу экспериментальную платформу. Модели ML в основном разрабатываются нашими учеными и инженерами по машинному обучению с использованием ноутбуков Jupyter на Kubeflow. Они управляются и обучены с использованием ML Flow, и мы развертываем их на Core Core в Kubernetes. Наш пользовательский магазин функций предоставляет функции для наших моделей ML, что позволяет им делать точные прогнозы.
Пользовательский магазин функций
Магазин функций в основном обслуживает пользовательские функции и статические функции. Статические особенности хранятся в Redis, потому что они не меняются очень часто. Мы ежедневно запускаем трубопроводы данных, чтобы загружать данные из нашего автономного хранилища данных в наш магазин функций в качестве статических функций.
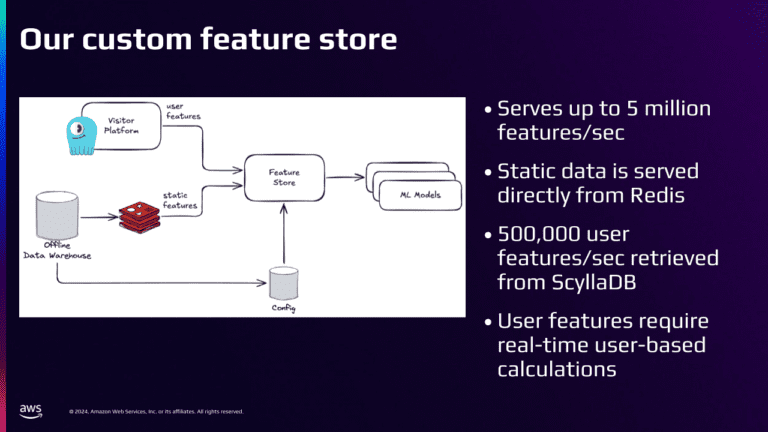
Пользовательские функции обслуживаются в режиме реального времени через платформу для посетителей. Мы выполняем динамические запросы CQL против Scylladb иНам не нужен слой кэширования, потому что Scylladb такой быстрыйПолем
Наш магазин функций обслуживает до 5 миллионов статических функций в секунду и полмиллиона пользовательских функций в секунду.
Что такое функция ML?
Особенности являются входными переменными для моделей ML, которые используются для прогнозирования. Есть статические функции и пользовательские функции.
Некоторые примеры статических особенностей-это награды, которые ресторан выиграл, или удобства, предлагаемые отелем (например, бесплатный Wi-Fi, Pet Pettry или фитнес-центр).
Пользовательские функции собираются в режиме реального времени, когда пользователи просматривают сайт. Мы храним их в Scylladb, чтобы мы могли получить молниеносные запросы. Некоторые примеры пользовательских функций - отели, просмотренные за последние 30 минут, рестораны, просмотренные за последние 24 часа, или отзывы, представленные за последние 30 дней.
Платформа технологий, включающих посетителей,
Scylladb лежит в основе платформы для посетителей. Мы используем пружинные загрузочные микросервисы на основе Java, чтобы выявить платформу нашим клиентам. Это развернуто на AWS ECS Fargate. Мы запускаем Apache Spark на Kubernetes для наших повседневных работ по хранению данных, нашей автономной работы в онлайн. Затем мы используем эти задания для загрузки данных из нашего автономного хранилища данных в Scylladb, чтобы они были доступны на сайте Live. Мы также используем Amazon Kinesis для обработки потоковых событий отслеживания пользователей.
Поток данных платформы посетителей
Следующая графика показывает, как данные протекают через нашу платформу в четырех этапах: производить, проглатывать, организовать и активировать.
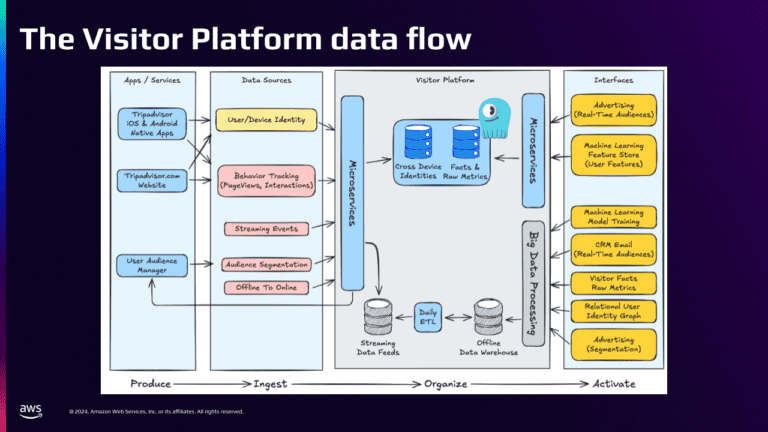
Данные создаются нашим веб -сайтом и нашими мобильными приложениями. Некоторые из этих данных включают в себя наш график идентификации пользователей в междайке, события отслеживания поведения (например, виды страниц и клики) и потоковые события, которые проходят через кинезис. Кроме того, сегментация аудитории загружается в нашу платформу.
Микросервисы платформы для посетителей используются для приема и организации этих данных. Данные в Scylladb хранятся в двух классах:
- Core -клавиша для посетителя, которая содержит график идентификации посетителей
- Метрическая клавиша для посетителя, которая содержит факты и метрики (вещи, которые люди делали, когда они просматривали сайт)
Мы используем ежедневные процессы ETL для поддержания и очистки данных на платформе. Мы производим продукты для данных, ежедневно штамп в нашем автономном хранилище данных, где они доступны для других интеграций и других конвейеров данных для использования при их обработке.
Вот посмотрите на платформу для посетителей по цифрам:
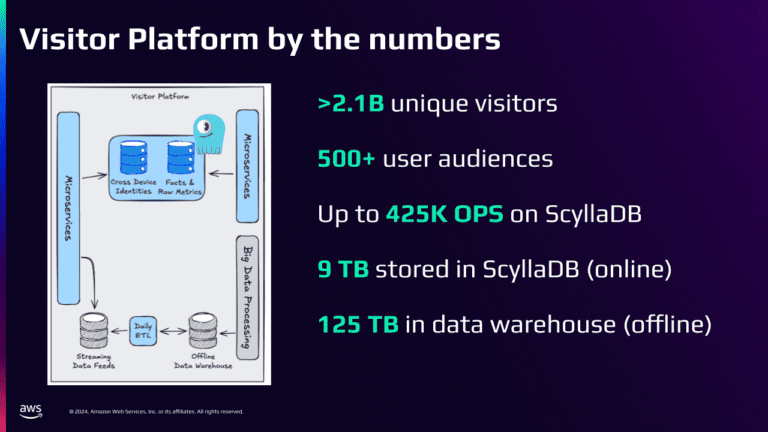
Почему две базы данных?
Наша онлайн-база данных ориентирована на трафик в реальном времени, живой веб-сайт. Scylladb выполняет эту роль, предоставляя очень низкую задержку и высокую пропускную способность. Мы используем краткосрочные TTL для предотвращения роста данных в онлайн -базе данных на неопределенный срок, и наши задания по хранению данных гарантируют, что мы храним данные об активности пользователей только для реальных посетителей. TripAdvisor.com получает много трафика ботов, и мы не хотим хранить их данные и пытаться персонализировать ботов - поэтому мы удаляем и очищаем все эти данные.

Наше автономное хранилище данных сохраняет исторические данные, используемые для отчетности, создания других продуктов данных и обучения наших моделей ML. Мы не хотим, чтобы крупномасштабные офлайн-процессы, влияющие на производительность нашего живого сайта, поэтому у нас есть две отдельные базы данных, используемые для двух разных целей.
Микросервисы платформы для посетителей
Мы используем 5 микросервисов для платформы для посетителей:
- Ядро посетителяУправляет графиком идентификации пользователя в перекрестном устройстве на основе файлов cookie и идентификаторов устройства.
- Метрика посетителейэто наш двигатель запроса, который дает нам возможность разоблачить факты и показатели для конкретных посетителей. Мы используем конкретный домен, называемый языком запросов для посетителей, или VQL. Этот пример VQL позволяет вам увидеть последнюю коммерцию нажимать факты за последние три часа.
- Издатель посетителейиПосетитель вблачиваетОбработайте путь записи, написание данных в платформу. Помимо сохранения данных в SCYLLADB, мы также транслируем данные в автономное хранилище данных. Это сделано с Amazon Kinesis.
- Посетитель КомпозитУпрощает публикацию данных на заданиях по обработке партий. Он абстрагирует вкладчиков посетителей и посетителя, чтобы идентифицировать посетителей и публиковать факты и метрики в одном вызове API.
Задержка микросервиса об обратном пути
Этот график иллюстрирует, как наши задержки из микросервиса остаются стабильными с течением времени.
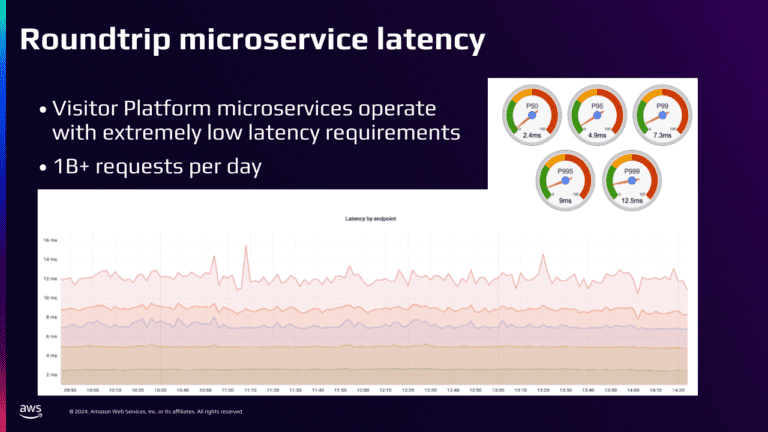
Средняя задержка составляет всего 2,5 миллисекунд, а наша P999 составляет менее 12,5 миллисекунд. Это впечатляющая производительность, особенно учитывая, что мы обрабатываем более 1 миллиарда запросов в день.
Наши клиенты MicroService имеют строгие требования к задержке. 95% вызовов должны завершить за 12 миллисекунд или менее. Если они пойдут на это, то мы получим страницы и должны выяснить, что влияет на задержки.
Задержка SCYLLADB
Вот снимок производительности Scylladb в течение трех дней.
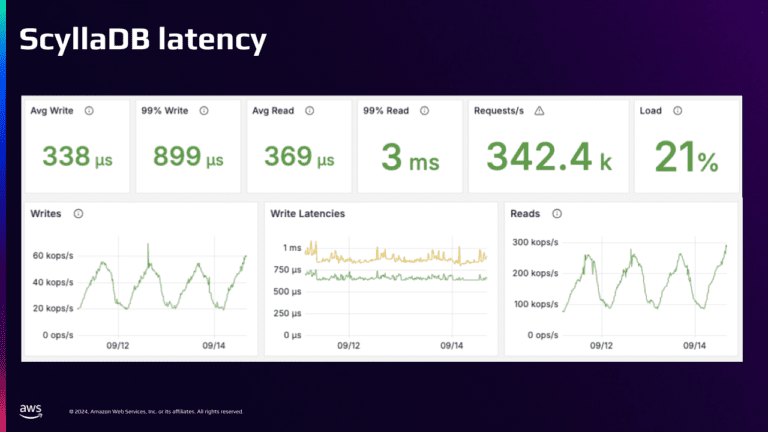
В пике Scylladb справляется с 340 000 операций в секунду (включая записи и чтения и удаления), а ЦП колеблется всего на 21%. Это высокий масштаб в действии!
Scylladb доставляет Microsecond, и Millisecond читает для нас. Этот уровень пылающей быстрой производительности именно поэтому мы выбрали Scylladb.
Разделение данных на scylladb
Это изображение показывает, как мы разделяем данные на scylladb.
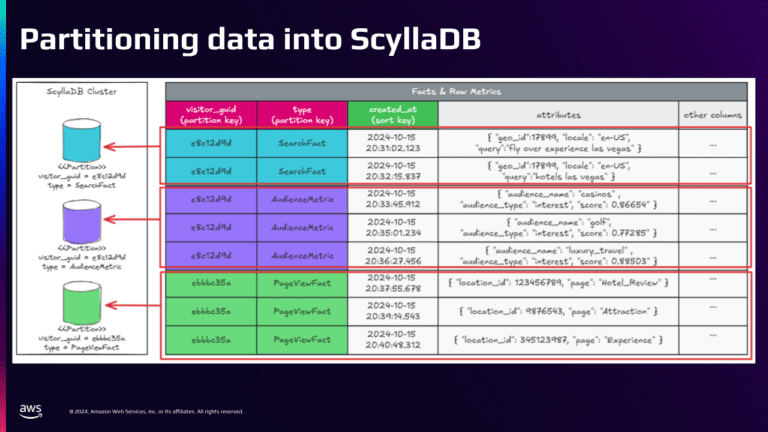
Метрическая клавиша для посетителей имеет две таблицы: факты и необработанные метрики. Основным ключом в таблице фактов является Guid Guid, тип факта, и создан на дату. Композитный ключ раздела - тип Guid и факт посетителя. Ключ кластеризации создается на дату, что позволяет нам сортировать данные в разделах по дате. Столбец атрибутов содержит объект JSON, представляющий событие, которое произошло там. Некоторым примером фактов являются поисковые термины, представления страниц и бронирование.
Мы используем выровненную стратегию уплотнения Scylladb, потому что:
- Он оптимизирован для запросов диапазона
- Он очень хорошо справляется с высокой кардинальностью
- Это лучше для рабочих нагрузок, и у нас примерно в 2-3 раза больше чтений, чем записи
Почему scylladb?
Наше решение было первоначально построено с использованием кассандры в Prem. Но по мере увеличения масштаба, оперативная нагрузка. Это требовало специальной поддержки операций, чтобы мы могли управлять обновлениями базы данных, резервных копий и т. Д. Кроме того, наше решение требует очень низких задержек для основных компонентов. Наша система управления идентификацией пользователя должна идентифицировать пользователя в течение 30 миллисекунд - и для лучшей персонализации мы требуем, чтобы наша платформа отслеживания событий отвечала за 40 миллисекунд. Очень важно, чтобы наше решение не блокировало рендеринг страницы, поэтому наши SLA очень низкие. С Кассандрой мы оказали влияние на производительность от сборов мусора. Это в первую очередь влияло на задержки хвоста, задержки P999 и P9999.

Мы провели доказательство концепции с Scylladb и обнаружили, что пропускная способность намного лучше, чем Кассандра, и оперативное бремя было устранено. Scylladb дал нам чудовищную базу данных обслуживания с минимальными задержками.
Мы хотели полностью управлять вариантом, поэтому мы мигрировали из Кассандры в облако Scylladb, следуя двойной стратегии записи. Это позволило нам мигрировать с нулевым временем простоя при выполнении 40 000 операций или запросов в секунду. Позже мы мигрировали из модели Scylladb Cloud в модель Scylladb «Принести свою собственную учетную запись», где вы можете попросить команду Scylladb развернуть базу данных Scylladb в свою учетную запись AWS. Это дало нам улучшенную производительность, а также лучшую конфиденциальность данных.
Эта диаграмма показывает, как выглядит развертывание BYOA Scylladb.
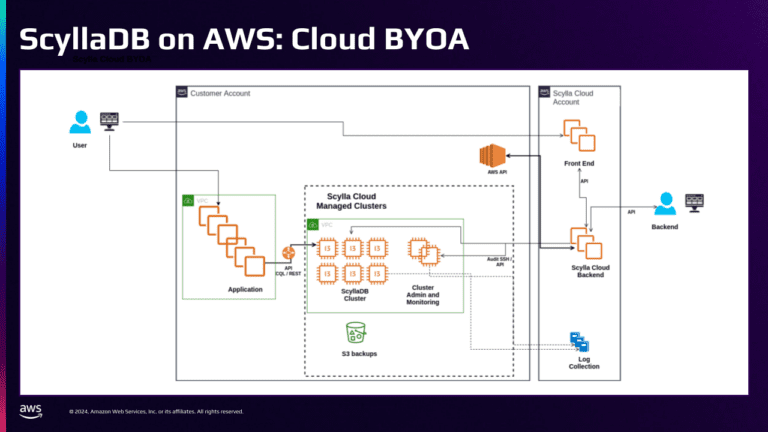
В центре диаграммы вы можете увидеть кластер ScylladB с 6 узлами, который работает на EC2. А потом есть два дополнительных экземпляра EC2.
- Scylladb Monitor дает нам мониторные панели Grafana, а также метрики Prometheus.
- Manager Scylladb заботится об автоматизации инфраструктуры, такой как запуска резервного копирования и ремонта.
С помощью этого развертывания Scylladb можно было бы совместно расположена очень близко к нашим микросервисам, чтобы дать нам еще более низкую задержку, а также гораздо более высокую пропускную способность и производительность.
Я надеюсь, что теперь вы лучше понимаете нашу архитектуру, технологии, которые поддерживают платформу, и о том, как Scylladb играет важную роль в том, чтобы позволить нам справиться с чрезвычайно высоким масштабом TripAdvisor.
О Синтии Данлоп
Синтия - старший директор по контент -стратегии в Scylladb. Она писала о разработке программного обеспечения и качественной инженерии в течение 20+ лет.
Оригинал