
Как использовать профилировщик TensorFlow для оптимизации производительности модели
13 августа 2025 г.Обзор контента
- Соберите данные производительности
- Профилирование API
- Профилирование индивидуальных тренировок
- Профилирование вариантов использования
- Лучшие практики для оптимальной производительности модели
- Оптимизировать конвейер входных данных
- Используйте потоки и параллельное выполнение
- Разнообразный
- Улучшить производительность устройства
- Дополнительные ресурсы
- Известные ограничения
- Профилирование нескольких графических процессоров на Tensorflow 2.2 и Tensorflow 2.3
Соберите данные производительности
Профилировщик TensorFlow собирает действия хоста и следы графических процессоров вашей модели TensorFlow. Вы можете настроить Profiler для сбора данных о производительности через программный режим или режим отбора проб.
Профилирование API
Вы можете использовать следующие API для выполнения профилирования.
- Программный режим с использованием обратного вызова Tensorboard Keras (
tf.keras.callbacks.TensorBoard)
# Profile from batches 10 to 15
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
profile_batch='10, 15')
# Train the model and use the TensorBoard Keras callback to collect
# performance profiling data
model.fit(train_data,
steps_per_epoch=20,
epochs=5,
callbacks=[tb_callback])
- Программный режим с использованием
tf.profilerФункция API
tf.profiler.experimental.start('logdir')
# Train the model here
tf.profiler.experimental.stop()
- Программный режим с использованием диспетчера контекста
with tf.profiler.experimental.Profile('logdir'):
# Train the model here
pass
Примечание:Запуск профилировщика слишком долго может привести к тому, что он закончится от памяти. Рекомендуется профилировать не более 10 шагов за раз. Избегайте профилирования первых нескольких партий, чтобы избежать неточностей из -за накладных расходов инициализации.
Режим отбора проб: выполнить профилирование по требованию, используя
tf.profiler.experimental.server.startЧтобы запустить сервер GRPC с запуском модели TensorFlow. После запуска сервера GRPC и запуска вашей модели вы можете захватить профиль черезЗахват профильКнопка в плагине профиля Tensorboard. Используйте скрипт в разделе «Установка Profiler» выше, чтобы запустить экземпляр Tensorboard, если он еще не работает.В качестве примера,
# Start a profiler server before your model runs.
tf.profiler.experimental.server.start(6009)
# (Model code goes here).
# Send a request to the profiler server to collect a trace of your model.
tf.profiler.experimental.client.trace('grpc://localhost:6009',
'gs://your_tb_logdir', 2000)
Пример для профилирования нескольких работников:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
# would like to profile for a duration of 2 seconds.
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466',
'gs://your_tb_logdir',
2000)
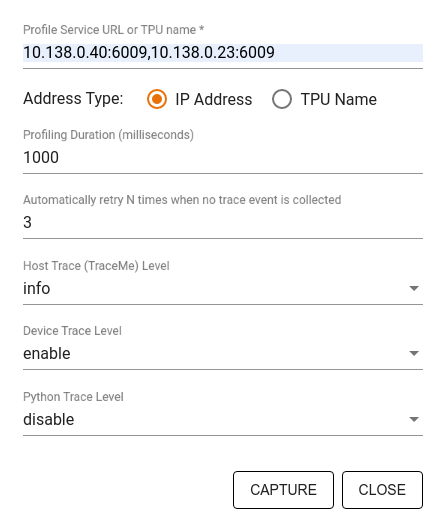
ИспользуйтеЗахват профильдиалог, чтобы указать:
- Список URL-адреса услуг или названия TPU с разрешением с запятой.
- Профилирование.
- Уровень устройства, хоста и трассировки вызовов функции Python.
- Сколько раз вы хотите, чтобы профилировщик повторил профили захвата, если сначала неудачно.
Профилирование индивидуальных тренировок
Чтобы профилировать пользовательские петли обучения в вашем коде TensorFlow, инструмент обучайте петлю сtf.profiler.experimental.TraceAPI, чтобы отметить границы шага для профилировщика.
Аnameаргумент используется в качестве префикса для имен шагов,step_numАргумент ключевого слова добавляется в имена шагов и_rАргумент ключевого слова заставляет это событие трассировки обрабатывается как шаг -событие профилировщиком.
В качестве примера,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Это позволит профилируемому анализу эффективности и приведет к появлению событий Step в Trace Viewer.
Убедитесь, что вы включите итератор набора данных вtf.profiler.experimental.TraceКонтекст для точного анализа входного трубопровода.
Приведенный ниже фрагмент кода-анти-паттерн:
Предупреждение:Это приведет к неточному анализу входного трубопровода.
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Профилирование вариантов использования
Профилировщик охватывает ряд вариантов использования вдоль четырех разных оси. Некоторые из комбинаций в настоящее время поддерживаются, а другие будут добавлены в будущем. Некоторые из вариантов использования:
- Местный против удаленного профилирования: Это два распространенных способа настройки вашей среды профилирования. В локальном профилировании профилирование API вызывается на той же машине, которую ваша модель выполняет, например, на локальной рабочей станции с графическими процессорами. В удаленном профилировании API профилирования вызывается на другой машине от того, где ваша модель выполняет, например, на облачном TPU.
- Профилирование нескольких работников: Вы можете профилировать несколько машин при использовании распределенных возможностей обучения TensorFlow.
- Аппаратная платформа: Профиль процессоров, графические процессоры и TPU.
Приведенная ниже таблица содержит краткий обзор упомянутых выше вариантов использования, поддерживаемых TensorFlow:
Профилирование API | Местный | Удаленный | Несколько работников | Аппаратные платформы |
|---|---|---|---|---|
Tensorboard Keras обратный вызов | Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
| Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
| Поддерживается | Поддерживается | Поддерживается | ЦП, GPU, TPU |
Контекст -менеджер API | Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
Лучшие практики для оптимальной производительности модели
Используйте следующие рекомендации в соответствии с применимыми для ваших моделей TensorFlow для достижения оптимальной производительности.
В целом, выполните все преобразования на устройстве и убедитесь, что вы используете последнюю совместимую версию библиотек, таких как Cudnn и Intel MKL для вашей платформы.
Оптимизировать конвейер входных данных
Используйте данные из [#Input_pipeline_analyzer], чтобы оптимизировать свой конвейер ввода данных. Эффективный трубопровод ввода данных может резко улучшить скорость выполнения вашей модели за счет сокращения времени простоя устройства. Попробуйте включить лучшие практики, подробно описанные вЛучшая производительность с API TF.DataРуководство и ниже, чтобы сделать ваш входной конвейер данных более эффективным.
- В целом, параллелизация любых операций, которые не нужно выполнять последовательно, может значительно оптимизировать входной конвейер данных.
- Во многих случаях это помогает изменить порядок некоторых вызовов или настроить аргументы, чтобы лучше всего подходил для вашей модели. Оптимизируя трубопровод входных данных, сравните только погрузчик данных без этапов обучения и обратного процесса, чтобы самостоятельно определить влияние оптимизации.
- Попробуйте запустить свою модель с синтетическими данными, чтобы проверить, является ли входной конвейер узким местом производительности.
- Использовать
tf.data.Dataset.shardДля обучения мульти-GPU. Убедитесь, что вы вспыхнули очень рано в входном цикле, чтобы предотвратить снижение пропускной способности. При работе с Tfrecords убедитесь, что вы нарушаете список Tfrecords, а не содержимое Tfrecords. - Параллелизировать несколько OPS, динамически установив значение
num_parallel_callsс использованиемtf.data.AUTOTUNEПолем - Рассмотреть возможность ограничения использования
tf.data.Dataset.from_generatorтак как это медленнее по сравнению с чистым тензорфлоу. - Рассмотреть возможность ограничения использования
tf.py_functionпоскольку он не может быть сериализован и не поддерживается для работы в распределенном тензоре. - Использовать
tf.data.Optionsуправлять статическими оптимизациями в входной трубопровод.
Также прочитайтеtf.dataАнализ производительностигидДля получения дополнительных рекомендаций по оптимизации вашего входного конвейера.
Оптимизировать увеличение данных
При работе с данными изображения, сделайте свойУвеличение данныхболее эффективно, подчиняясь к разным типам данныхпослеприменение пространственных преобразований, таких как переворот, обрезка, вращение и т. Д.
Примечание:Некоторым нравитсяtf.image.resizeпрозрачно изменитьdtypeкfp32Полем Убедитесь, что вы нормализуете свои данные, чтобы лежать между0и1Если это не сделано автоматически. Пропустить этот шаг может привести кNaNОшибки, если у вас были включены
Используйте NVIDIA® DALI
В некоторых случаях, например, когда у вас есть система с высоким графическим процессором к процессору, все вышеперечисленные оптимизации могут быть недостаточно для устранения узких мест в загрузке данных, вызванных из -за ограничений циклов ЦП.
Если вы используете GPU NVIDIA® для компьютерного зрения и приложений глубокого обучения, рассмотрите возможность использования библиотеки загрузки данных (Дали) для ускорения конвейера данных.
ПроверитьNVIDIA® DALI: ОперацииДокументация для списка поддерживаемых Dali Ops.
Используйте потоки и параллельное выполнение
Запустить OPS в нескольких потоках процессора сtf.config.threadingAPI, чтобы выполнить их быстрее.
TensorFlow автоматически устанавливает количество потоков параллелизма по умолчанию. Пул потоков, доступный для запуска TensorFlow Ops, зависит от количества доступных потоков процессора.
Управлять максимальным параллельным ускорением для одного OP, используяtf.config.threading.set_intra_op_parallelism_threadsПолем Обратите внимание, что если вы запускаете несколько OPS параллельно, все они поделится доступным пулом потоков.
Если у вас есть независимые не блокирующие OPS (OPS без направленного пути между ними на графике), используйтеtf.config.threading.set_inter_op_parallelism_threadsЧтобы запустить их одновременно, используя доступный пул потоков.
Разнообразный
При работе с небольшими моделями на графических процессорах NVIDIA® вы можете установитьtf.compat.v1.ConfigProto.force_gpu_compatible=TrueЧтобы все тензоры процессора были выделены с помощью закрепленной памяти CUDA, чтобы обеспечить значительное повышение производительности модели. Тем не менее, проявляйте осторожность при использовании этой опции для неизвестных/очень больших моделей, так как это может негативно повлиять на производительность хоста (ЦП).
Улучшить производительность устройства
Следуйте лучшим практикам, подробно описанным здесь и вРуководство по оптимизации производительности графического процессораДля оптимизации производительности модели тензорфлоу-модели.
Если вы используете GPU NVIDIA, войдите в систему графического процессора и использование памяти в файл CSV, запустив:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Настройте макет данных
При работе с данными, которые содержат информацию о канале (например, изображения), оптимизируйте формат макета данных, чтобы предпочесть в последнее время (NHWC над NCHW).
Форматы данных о канале улучшаютсяТенсор ядроИспользование и обеспечивает значительные улучшения производительности, особенно в сверточных моделях в сочетании с AMP. Макет данных NCHW по -прежнему можно работать с помощью тензоров, но вводить дополнительные накладные расходы из -за автоматического транспонирования OPS.
Вы можете оптимизировать макет данных, чтобы предпочесть макеты NHWC, настройкаdata_format="channels_last"для таких слоевtf.keras.layers.Conv2DВtf.keras.layers.Conv3D, иtf.keras.layers.RandomRotationПолем
Использоватьtf.keras.backend.set_image_data_formatЧтобы установить формат макета данных по умолчанию для API Backend Keras.
Максимально из -за кэша L2
При работе с графическими процессорами NVIDIA® выполните фрагмент кода ниже перед учебным циклом, чтобы максимально использовать гранулярность L2 до 128 байтов.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Настройка использования потока графического процессора
Режим потока GPU решает, как используются потоки GPU.
Установить режим потока наgpu_privateЧтобы убедиться, что предварительная обработка не крадет все потоки графических процессоров. Это уменьшит задержку запуска ядра во время обучения. Вы также можете установить количество потоков на GPU. Установите эти значения, используя переменные среды.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Настройка параметров памяти графических процессоров
В общем, увеличьте размер партии и масштабируйте модель, чтобы лучше использовать графические процессоры и получить более высокую пропускную способность. Обратите внимание, что увеличение размера партии изменит точность модели, поэтому модель должна быть масштабирована путем настройки гиперпараметров, таких как скорость обучения, чтобы соответствовать целевой точности.
Также используйтеtf.config.experimental.set_memory_growthчтобы позволить графическому графическому графическому графическим процессам расти, чтобы предотвратить полное распределение всей доступной памяти на OPS, которая требует лишь доли памяти. Это позволяет другим процессам, которые потребляют память графических процессоров для работы на одном устройстве.
Чтобы узнать больше, проверьтеОграничение роста памяти графического процессораРуководство в GPU Руководство для изучения больше.
Разнообразный
- Увеличьте учебную мини-размер (количество обучающих образцов, используемых на устройство, в одной итерации обучающего цикла) до максимального количества, которое подходит без ошибки вне памяти (OOM) на GPU. Увеличение размера партии воздействует на точность модели - так что убедитесь, что вы масштабируете модель, настраивая гиперпараметры, чтобы соответствовать целевой точности.
- Отключить ошибки отчетности во время распределения тензора в производственном коде. Набор
report_tensor_allocations_upon_oom=Falseвtf.compat.v1.RunOptionsПолем - Для моделей со слоями свертки удалите добавление смещения при использовании нормализации партии. Нормализация пакетов смещает значения на их среднее значение, и это устраняет необходимость иметь постоянный термин смещения.
- Используйте статистику TF, чтобы выяснить, насколько эффективно работают OPS.
- Использовать
tf.functionДля выполнения вычислений и необязательно включитьjit_compile=Trueфлаг (tf.function(jit_compile=True) Чтобы узнать больше, пойти вИспользуйте xla tf.functionПолем - Минимизируйте операции Python в хосте между шагами и уменьшите обратные вызовы. Рассчитайте метрики каждые несколько шагов, а не на каждом шаге.
- Держите устройство, вычислительные подразделения заняты.
- Отправьте данные на несколько устройств параллельно.
- УчитыватьИспользование 16-битных численных представлений, такой как
fp16-Полуоперационная формат с плавающей запятой, указанный IEEE-или мозг с плавающей точкойBfloat16формат.
Дополнительные ресурсы
- АTensorflow Profiler: производительность модели профиляУчебное пособие с Keras и Tensorboard, где вы можете применить советы в этом руководстве.
- АПрофилирование производительности в Tensorflow 2Поговорите с Tensorflow Dev Summit 2020.
- АTensorflow Profiler DemoОт Tensorflow Dev Summit 2020.
Известные ограничения
Профилирование нескольких графических процессоров на Tensorflow 2.2 и Tensorflow 2.3
Tensorflow 2.2 и 2.3 поддерживают несколько профилирования графических процессоров только для отдельных систем хоста; Многочисленное профилирование графических процессоров для систем с несколькими хостами не поддерживается. Чтобы профилировать конфигурации графических процессоров с несколькими работниками, каждый работник должен быть представлен независимо. От Tensorflow 2.4 несколько работников могут быть профилированы с помощьюtf.profiler.experimental.client.traceAPI.
CUDA® Toolkit 10.2 или более поздний цвет требуется для профила нескольких графических процессоров. Поскольку TensorFlow 2.2 и 2.3 поддерживают версии Cuda® Toolkit только до 10,1, вам необходимо создать символические ссылки наlibcudart.so.10.1иlibcupti.so.10.1:
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1
Первоначально опубликовано на
Оригинал