

Как обучить собственную приватную модель ChatGPT по цене кофе Starbucks
19 июня 2023 г.Затратив чашку Starbucks и два часа своего времени, вы можете стать владельцем собственной обученной крупномасштабной модели с открытым исходным кодом. Модель может быть настроена в соответствии с различными направлениями обучающих данных для улучшения различных навыков, таких как медицина, программирование, торговля акциями и люблю советы, делая вашу крупномасштабную модель более «понимающей» вас. Давайте попробуем обучить крупномасштабную модель с открытым исходным кодом, используя DolphinScheduler с открытым исходным кодом!
Введение
Демократизация ChatGPT
Рождение ChatGPT, несомненно, наполнило нас надеждой на будущее ИИ. Его утонченное выражение и мощная способность понимать язык поразили мир. Однако, поскольку ChatGPT предоставляется как программное обеспечение как услуга (SaaS), проблемы утечки личной конфиденциальности и безопасности корпоративных данных беспокоят каждого пользователя и компанию. Появляется все больше и больше крупномасштабных моделей с открытым исходным кодом, что позволяет отдельным лицам и компаниям иметь свои собственные модели. Однако начало работы, оптимизация и использование крупномасштабных моделей с открытым исходным кодом имеют высокие барьеры для входа, что затрудняет их легкое использование для всех. Чтобы решить эту проблему, мы используем Apache DolphinScheduler, который обеспечивает поддержку одним щелчком мыши для обучения, настройки и развертывания крупномасштабных моделей с открытым исходным кодом. Это позволяет каждому обучать свои собственные крупномасштабные модели, используя свои данные, с очень низкими затратами и техническими знаниями.
Для кого это? — Любой перед экраном
Наша цель – не только профессиональные инженеры по искусственному интеллекту, но и все, кто интересуется GPT, получают удовольствие от модели, которая "понимает" их лучше. Мы считаем, что у каждого есть право и возможность создать своего собственного ИИ-помощника. Интуитивно понятный рабочий процесс Apache DolphinScheduler делает это возможным. В качестве бонуса Apache DolphinScheduler — это инструмент планирования больших данных и искусственного интеллекта с более чем 10 000 звезд на GitHub. Это проект высшего уровня в рамках Apache Software Foundation, что означает, что вы можете использовать его бесплатно и изменять код, не беспокоясь о каких-либо коммерческих проблемах.
Независимо от того, являетесь ли вы отраслевым экспертом, который хочет обучить модель с помощью собственных данных, или энтузиастом ИИ, который хочет понять и изучить обучение моделей глубокого обучения, наш рабочий процесс предоставит вам удобные услуги. Он решает сложные этапы предварительной обработки, обучения модели и оптимизации и требует всего 1–2 часа простых операций плюс 20 часов работы для создания более «понимающей» крупномасштабной модели ChatGPT.
Итак, давайте начнем это волшебное путешествие! Давайте сделаем будущее искусственного интеллекта доступным каждому.
Всего три шага, чтобы создать ChatGPT, который «понимает» вас лучше
- Арендуйте карту GPU по низкой цене, эквивалентной уровню 3090.
- Запустить DolphinScheduler
- Нажмите рабочий процесс обучения и рабочий процесс развертывания на странице DolphinScheduler и непосредственно испытайте ChatGPT.
Подготовка хоста с видеокартой 3090
Во-первых, вам нужна видеокарта 3090. Если у вас есть настольный компьютер, вы можете использовать его напрямую. Если нет, то в сети можно арендовать множество хостов с графическим процессором. Здесь мы используем AutoDL в качестве примера для применения. Откройте https://www.autodl.com/home, зарегистрируйтесь и войдите в систему. После этого вы можете выбрать соответствующий сервер в рынок вычислительной мощности в соответствии с шагами 1, 2 и 3, показанными на экране.
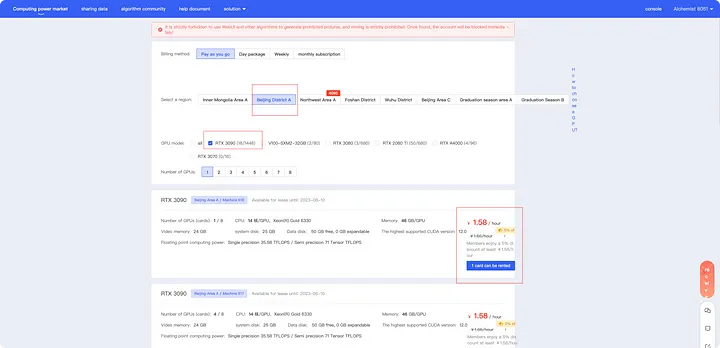
Здесь рекомендуется выбрать видеокарту RTX 3090, которая предлагает высокое соотношение цены и качества. После тестирования было установлено, что один-два человека могут использовать RTX 3090 для онлайн-задач. Если вам нужно более быстрое обучение и скорость отклика, вы можете выбрать более мощную видеокарту. Обучение один раз занимает около 20 часов, а тестирование требует около 2-3 часов. С бюджетом в 40 юаней вы можете легко это сделать.
Зеркало
Нажмите на зеркало сообщества и введите WhaleOps/dolphinscheduler-llm/dolphinscheduler-llm-0521 в красное поле ниже. Вы можете выбрать изображение, как показано ниже. В настоящее время доступна только версия V1. В будущем, по мере выхода новых версий, вы сможете выбрать самую последнюю.
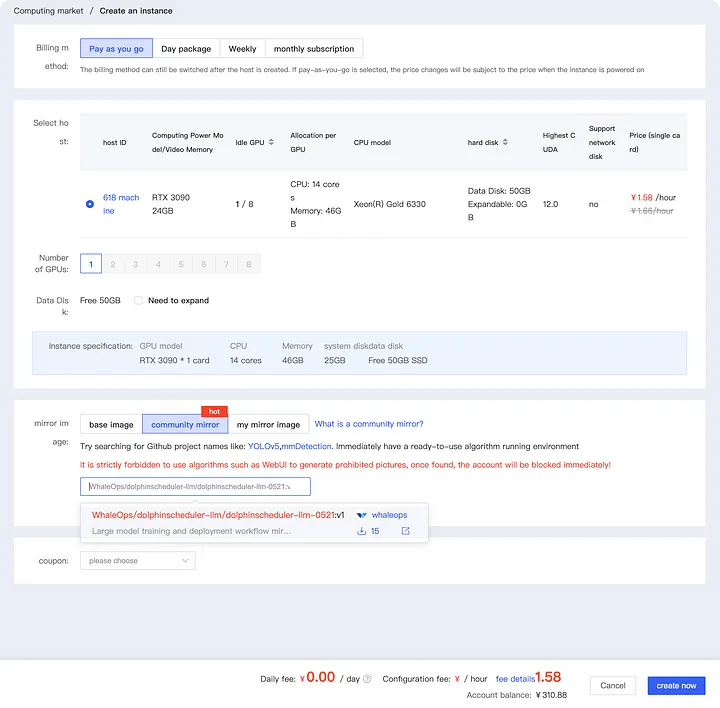
Если вам нужно обучить модель несколько раз, рекомендуется увеличить емкость жесткого диска примерно до 100 ГБ.
После создания дождитесь завершения индикатора выполнения, показанного на следующем рисунке.
Запустить DolphinScheduler
Для развертывания и отладки вашей собственной крупномасштабной модели с открытым исходным кодом в интерфейсе вам необходимо запустить программное обеспечение DolphinScheduler, а нам необходимо выполнить следующие действия по настройке:
Для доступа к серверу
Есть два доступных метода. Вы можете выбрать тот, который соответствует вашим предпочтениям:
- Войти через JupyterLab (для непрограммистов):
Нажмите кнопку JupyterLab, показанную ниже.
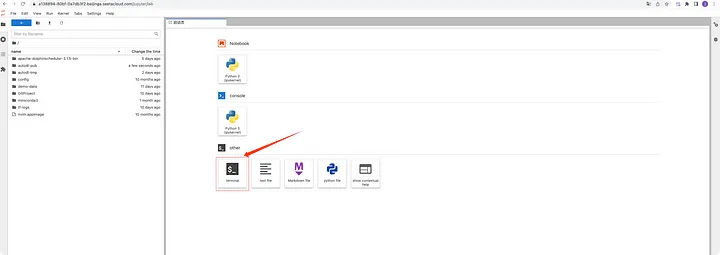
Страница будет перенаправлена на JupyterLab; оттуда вы можете нажать «Терминал», чтобы войти.
<сильный>2. Вход через Терминал (для кодеров):
Мы можем получить команду подключения SSH с помощью кнопки, показанной на следующем рисунке.
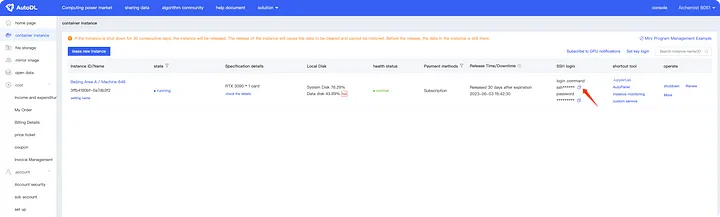
Затем установите соединение через терминал.
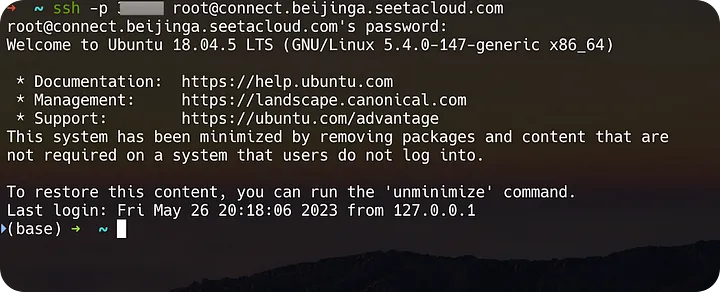
Импорт метаданных DolphinScheduler
В DolphinScheduler все метаданные хранятся в базе данных, включая определения рабочих процессов, конфигурации среды, информацию об арендаторах и т. д. Чтобы пользователям было удобно просматривать эти рабочие процессы при запуске DolphinScheduler, мы можем напрямую импортировать предварительно определенные метаданные рабочих процессов. скопировав его с экрана.
Измените скрипт для импорта данных в MySQL:
Используя терминал, перейдите в следующий каталог:
cd apache-dolphinscheduler-3.1.5-bin
Выполните команду: vim import_ds_metadata.sh, чтобы открыть файл import_ds_metadata.sh. Содержимое файла выглядит следующим образом:
Установить переменные
Имя хоста
HOST="xxx.xxx.xxx.x"
UsernameUSERNAME="root"PASSWORD="xxxx"PortPORT=3306Database для импорта в DATABASE="ds315_llm_test"SQL filenameSQL_FILE="ds315_llm.sql"mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD -e "СОЗДАТЬ БАЗА ДАННЫХ $DATABASE;"mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD $DATABASE < $SQL_FILE
Замените xxx.xxx.xxx.x и xxxx соответствующими значениями конфигурации базы данных MySQL в вашей общедоступной сети (вы можете подать заявку в Alibaba Cloud, Tencent Cloud или установить ее самостоятельно). Затем выполните:
bash import_ds_metadata.sh
После выполнения, если интересно, можно проверить соответствующие метаданные в базе данных (подключиться к MySQL и просмотреть, пропустив этот шаг, если вы не знакомы с кодом).
Запустить DolphinScheduler
В командной строке сервера откройте следующий файл и измените конфигурацию, чтобы подключить DolphinScheduler к ранее импортированной базе данных:
/root/apache-dolphinscheduler-3.1.5-bin/bin/env/dolphinscheduler_env.sh
Измените соответствующую конфигурацию в разделе базы данных, а остальные разделы оставьте без изменений. Измените значения «HOST» и «PASSWORD» на значения конфигурации импортированной базы данных, т. е. xxx.xxx.xxx.x и xxxx:
export DATABASE=mysqlexport SPRING_PROFILES_ACTIVE=${DATABASE}export SPRING_DATASOURCE_URL="jdbc:mysql://HOST:3306/ds315_llm_test?useUnicode=true&characterEncoding=UTF-8&useSSL=false"export SPRING_DATASOURCE_USERNAME="root "экспорт SPRING_DATASOURCE_PASSWORD="xxxxxx"......
После настройки выполните (также в этом каталоге /root/apache-dolphinscheduler-3.1.5-bin):
bash ./bin/dolphinscheduler-daemon.sh запустить автономный сервер
После выполнения мы можем проверить журналы с помощью tail -200f standalone-server/logs/dolphinscheduler-standalone.log. На данный момент DolphinScheduler официально запущен!
После запуска службы мы можем нажать «Пользовательские службы» в консоли AutoDL (выделено красным), чтобы перейти на URL-адрес:
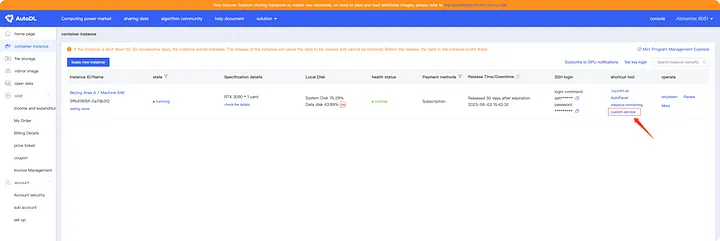
При открытии URL-адреса, если он показывает ошибку 404, не беспокойтесь. Просто добавьте суффикс /dolphinscheduler/ui к URL-адресу:

Модуль AutoDL открывает порт 6006. После настройки порта DolphinScheduler на 6006 вы можете получить к нему доступ через предоставленную точку входа. Однако из-за перенаправления URL вы можете столкнуться с ошибкой 404. В таких случаях необходимо заполнить URL-адрес вручную.
Учетные данные для входа:
Имя пользователя: admin
Пароль: dolphinscheduler123
После входа в систему нажмите «Управление проектами», чтобы увидеть предопределенный проект с именем «викуна». Нажмите на «викунью», чтобы войти в проект.

Обучение и развертывание больших моделей с открытым исходным кодом
Определение рабочего процесса
При входе в проект Vicuna вы увидите три рабочих процесса: Обучение, Развертывание и Kill_Service. Давайте рассмотрим их использование и способы настройки больших моделей и обучения данных.
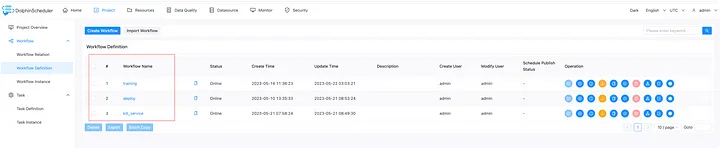
Вы можете нажать кнопку запуска ниже, чтобы выполнить соответствующие рабочие процессы.
Обучение
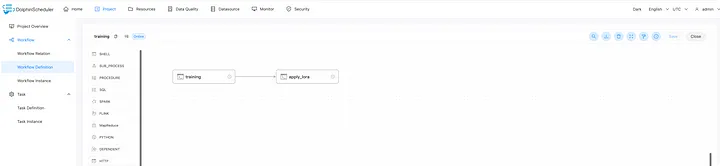
Нажав на рабочий процесс обучения, вы увидите два определения. Один предназначен для точной настройки модели через Lora (в основном с использованием alpaca-lora, https://github.com/tloen/alpaca-lora ), а второй — объединить обученную модель с базовой моделью, чтобы получить окончательную модель.
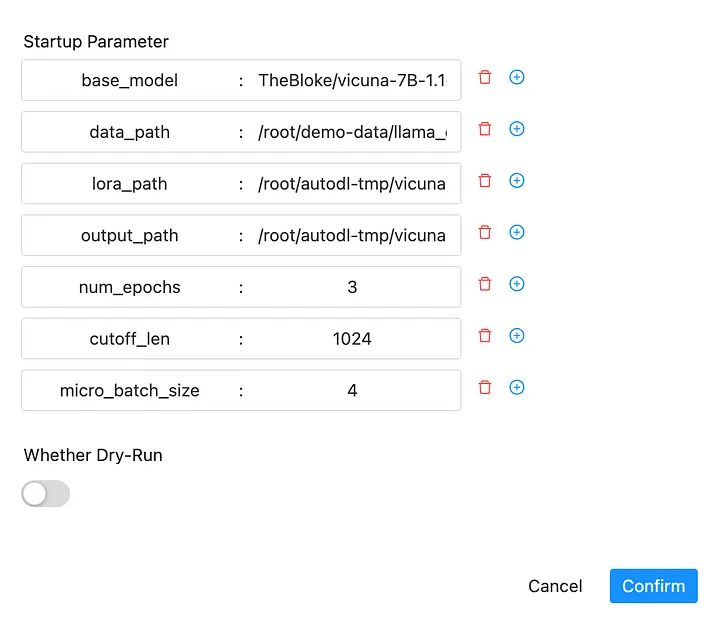
Рабочий процесс имеет следующие параметры (отображается после нажатия кнопки «Выполнить»):
* base_model: Базовая модель, которую можно выбрать и загрузить в соответствии с вашими потребностями. Большие модели с открытым исходным кодом предназначены только для обучения и экспериментальных целей. Текущее значение по умолчанию — TheBloke/vicuna-7B-1.1-HF. * data_path: путь к вашим персонализированным тренировочным данным и данным домена, по умолчанию /root/demo-data/llama_data.json. * lora_path: Путь для сохранения обученных весов Лоры, /root/autodl-tmp/vicuna-7b-lora-weight. * output_path: Путь сохранения окончательной модели после слияния базовой модели и веса Лоры, запишите его, так как он понадобится для развертывания. * num_epochs: Параметр обучения, количество эпох обучения. Для тестирования можно установить 1, обычно 3~10. * cutoff_len: Максимальная длина текста, по умолчанию 1024. * micro_batch_size: Размер партии.
Развернуть
Рабочий процесс развертывания больших моделей (в основном с использованием FastChat, https://github.com/lm-sys/FastChat). Сначала он вызовет kill_service для уничтожения развернутой модели, затем последовательно запустит контроллер, добавит модель и затем откроет веб-службу Gradio.
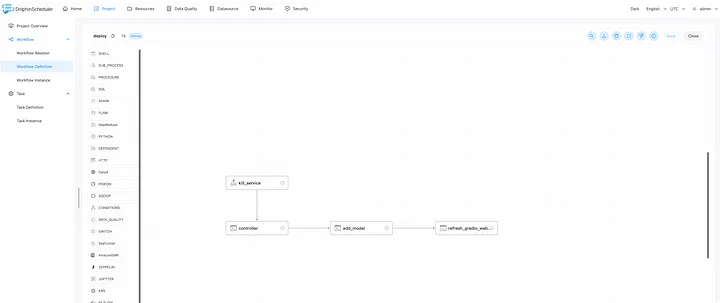
Параметры запуска следующие:

* модель: Путь модели, это может быть идентификатор модели Huggingface или путь модели, обученный нами, т. е. output_path рабочего процесса обучения выше. По умолчанию используется TheBloke/vicuna-7B-1.1-HF. Если используется значение по умолчанию, будет напрямую развернута модель vicuna-7b.
Kill_service
Этот рабочий процесс используется для уничтожения развернутой модели и освобождения памяти графического процессора. Этот рабочий процесс не имеет параметров, и вы можете запустить его напрямую. Если вам нужно остановить развернутую службу (например, когда вам нужно переобучить модель или когда не хватает памяти графического процессора), вы можете напрямую выполнить рабочий процесс kill_service, чтобы убить развернутую службу.
После выполнения нескольких примеров ваше развертывание будет завершено. Теперь давайте посмотрим на практическую работу:
Пример работы большой модели
- Обучение большой модели
Запустите рабочий процесс напрямую, запустив рабочий процесс обучения и выбрав параметры по умолчанию.
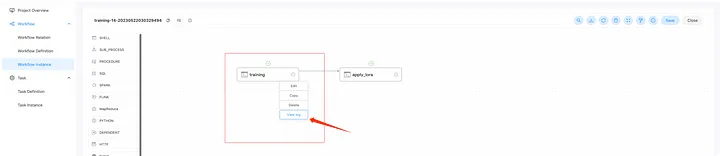
Щелкните правой кнопкой мыши соответствующую задачу, чтобы просмотреть журналы, как показано ниже:
Вы также можете просмотреть статус задачи и журналы на панели экземпляра задачи в левом нижнем углу боковой панели. В процессе обучения вы можете следить за прогрессом, проверяя журналы, в том числе текущие шаги обучения, показатели потерь, оставшееся время и т. д. Имеется индикатор выполнения, указывающий текущий шаг, где шаг = (размер данных * эпоха) / партия размер.

После завершения обучения журналы будут выглядеть следующим образом:

Обновление персональных данных о тренировках
Наши данные по умолчанию находятся в /root/demo-data/llama_data.json. Текущий источник данных — Huatuo, медицинская модель, настроенная с использованием китайских медицинских данных. Да, наш пример — обучение семейного врача:

Если у вас есть данные в определенном поле, вы можете указать свои собственные данные, формат данных следующий:
Один JSON в строке, значение поля:
- instruction ****: инструкция для модели.
- ввод: ввод.
- output: ожидаемый результат модели.
Например:
{"инструкция": "расчет", "ввод": "1+1 равно?", "выход": "2"}
Обратите внимание, что вы можете объединить поле инструкции и поля ввода в одно поле инструкции. Поле ввода также можно оставить пустым.
При обучении измените параметр data_path для выполнения собственных данных.
Примечание.
Во время первого обучения базовая модель будет получена из указанного места, например TheBloke/vicuna-7B-1.1-HF. Будет процесс загрузки, поэтому дождитесь завершения загрузки. Выбор этой модели определяется пользователем, и вы также можете загрузить другие большие модели с открытым исходным кодом (при их использовании соблюдайте соответствующие лицензии).
Из-за проблем с сетью загрузка базовой модели может завершиться ошибкой на полпути к первому выполнению обучения. В таких случаях вы можете щелкнуть невыполненную задачу и выбрать повторный запуск, чтобы продолжить обучение. Операция показана ниже:

Чтобы остановить обучение, вы можете нажать кнопку остановки, которая освободит память графического процессора, используемую для обучения.
Рабочий процесс развертывания
На странице определения рабочего процесса щелкните рабочий процесс развертывания, чтобы запустить его и развернуть модель.
Если вы не обучили свою собственную модель, вы можете выполнить рабочий процесс развертывания с параметрами по умолчанию TheBloke/vicuna-7B-1.1-HF для развертывания модели vicuna-7b, как показано на рисунке ниже. :
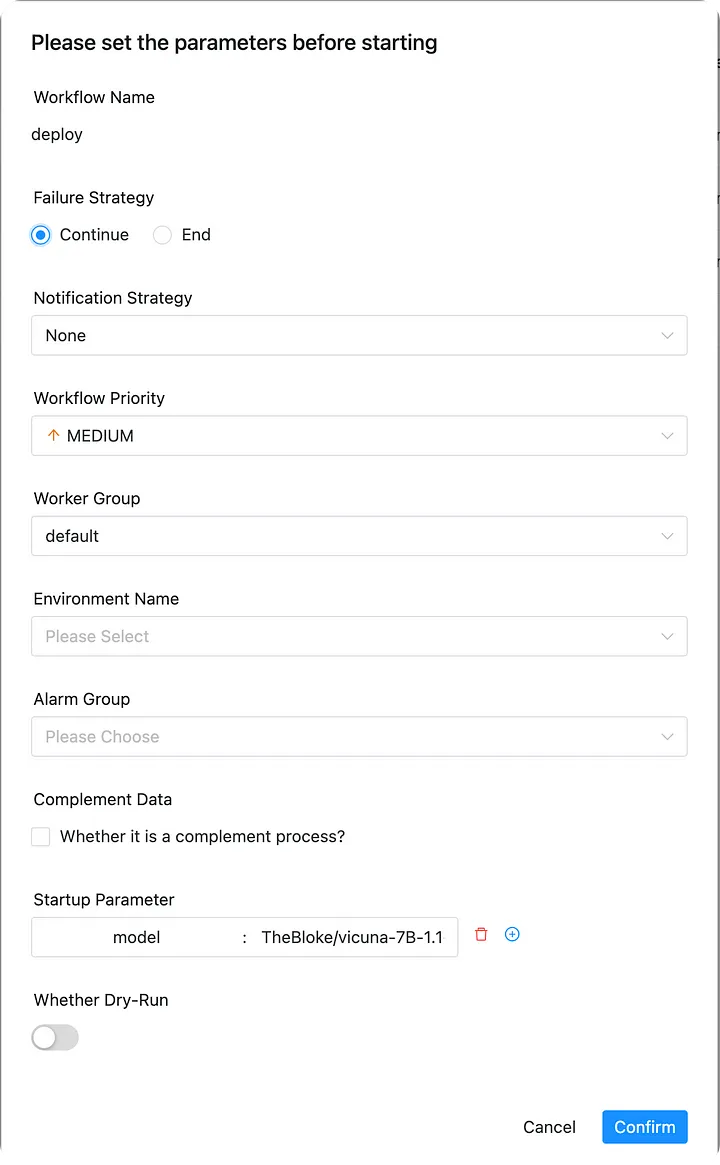
Если вы обучили модель на предыдущем шаге, теперь вы можете развернуть свою модель. После развертывания вы можете испытать свою собственную большую модель. Параметры запуска следующие, где вам нужно заполнить output_path модели из предыдущего шага:

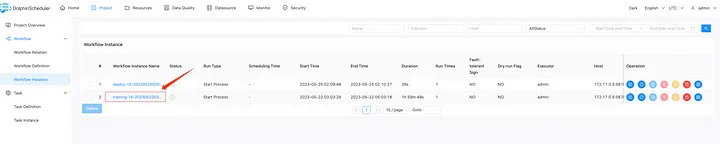
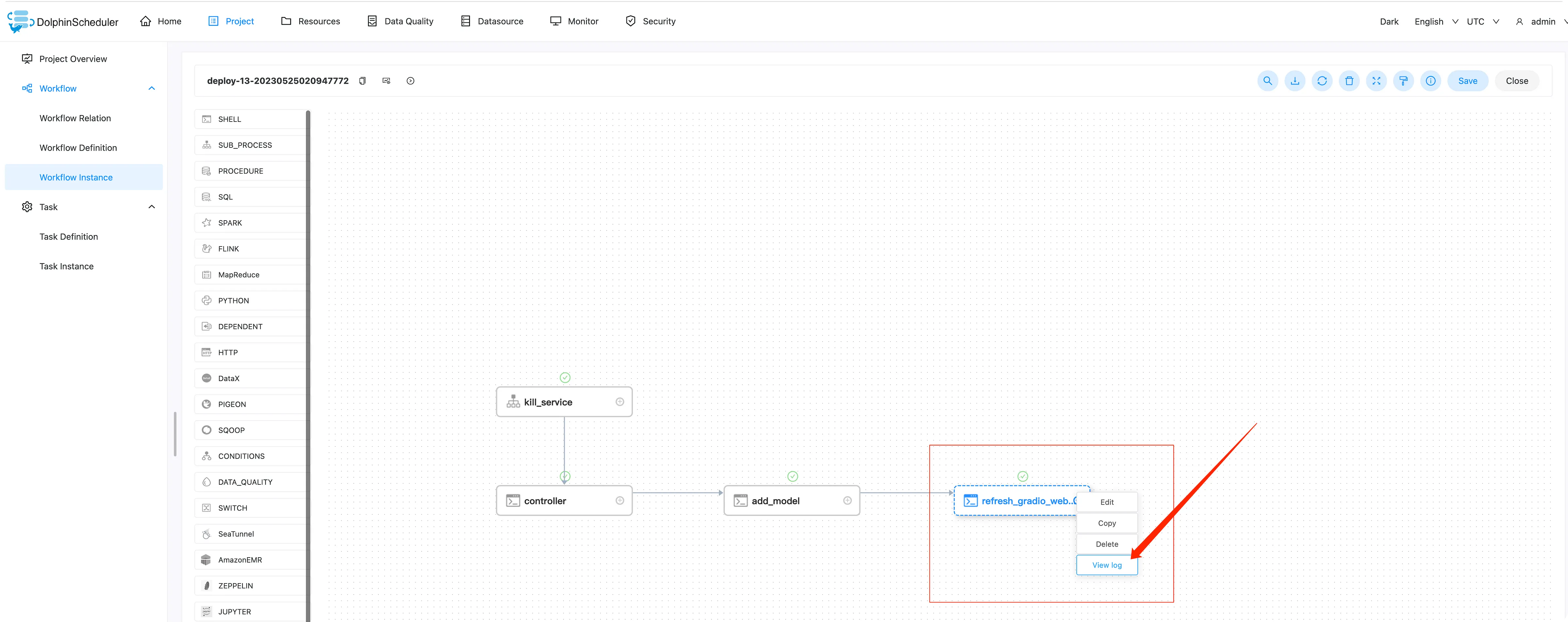
Далее давайте войдем в развернутый экземпляр рабочего процесса. Нажмите на экземпляр рабочего процесса, а затем нажмите на экземпляр рабочего процесса с префиксом «развернуть».

Щелкните правой кнопкой мыши и выберите «refresh_gradio_web_service», чтобы просмотреть журналы задач и найти расположение ссылки на нашу большую модель.
Операция показана ниже:
В журналах вы найдете общедоступную ссылку, например:
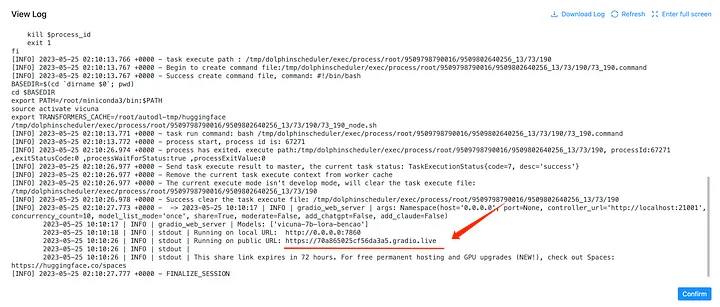
Вот две ссылки. Ссылка 0.0.0.0:7860 недоступна, так как AutoDL открывает только порт 6006, который уже используется для dolphinscheduler. Вы можете напрямую перейти по ссылке ниже, например [https://81c9f6ce11eb3c37a4.gradio.live.](https://81c9f6ce11eb3c37a4.gradio.live.)
Учтите, что эта ссылка может меняться при каждом развертывании, поэтому вам нужно снова найти ее в журналах.
Как только вы введете ссылку, вы увидите страницу разговора вашего собственного ChatGPT!
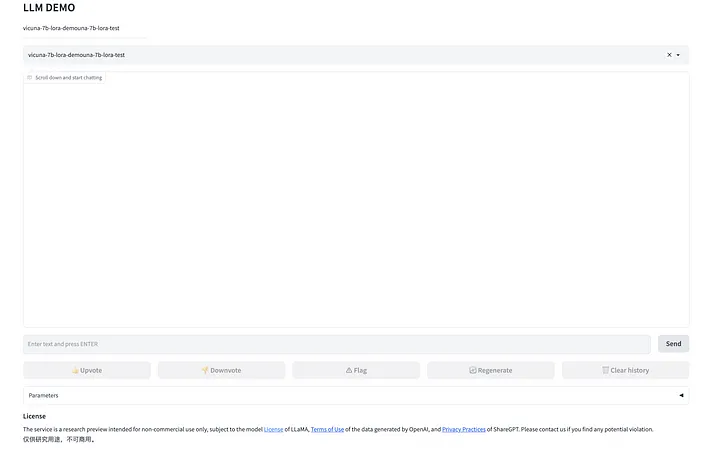
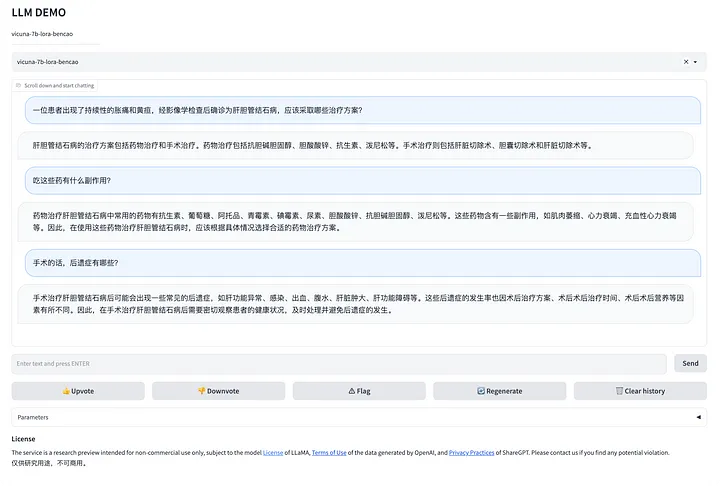
Да! Теперь у вас есть собственный ChatGPT, и его данные служат только вам!
<цитата>И вы потратили меньше, чем стоит чашка кофе~~
Идите вперед и испытайте свой собственный приватный ChatGPT!
Обзор
В этом мире, ориентированном на данные и технологии, выделенная модель ChatGPT имеет неизмеримое значение. С развитием искусственного интеллекта и глубокого обучения мы живем в эпоху, когда можно формировать персонализированных помощников ИИ. Обучение и развертывание вашей собственной модели ChatGPT поможет нам лучше понять ИИ и то, как он меняет наш мир.
Таким образом, самостоятельное обучение и развертывание модели ChatGPT может помочь вам защитить безопасность и конфиденциальность данных, удовлетворить конкретные бизнес-требования, сэкономить на затратах на технологии и автоматизировать процесс обучения с помощью инструментов рабочего процесса, таких как DolphinScheduler. Это также позволяет вам соблюдать местные законы и правила. Поэтому стоит рассмотреть возможность самостоятельного обучения и развертывания модели ChatGPT.
Важные примечания:
- Безопасность и конфиденциальность данных. При использовании ChatGPT через общедоступные службы API у вас могут возникнуть проблемы с безопасностью и конфиденциальностью данных. Это серьезная проблема, поскольку ваши данные могут быть переданы по сети. Обучив и развернув модель самостоятельно, вы можете быть уверены, что ваши данные хранятся и обрабатываются только на вашем собственном устройстве или арендованном сервере, обеспечивая безопасность и конфиденциальность данных.
- Специфические для предметной области знания. Для организаций или отдельных лиц с особыми бизнес-требованиями обучение собственной модели ChatGPT гарантирует, что эта модель содержит самые свежие и актуальные знания, связанные с вашим бизнесом. Независимо от области вашего бизнеса, модель, специально обученная для ваших бизнес-потребностей, будет более ценной, чем универсальная модель.
- Инвестиционные затраты. Использование модели OpenAI ChatGPT может повлечь за собой определенные затраты. Точно так же, если вы хотите обучать и развертывать модель самостоятельно, вам также необходимо инвестировать ресурсы и нести затраты на технологии. Например, вы можете испытать отладку больших моделей всего за 40 юаней, но если вы планируете запускать ее в долгосрочной перспективе, рекомендуется приобрести видеокарту Nvidia RTX 3090 или арендовать облачные серверы. Поэтому вам необходимо взвесить все за и против и выбрать решение, которое наилучшим образом соответствует вашим конкретным обстоятельствам.
- DolphinScheduler. Используя рабочий процесс Apache DolphinScheduler, вы можете автоматизировать весь процесс обучения, значительно уменьшив технические барьеры. Даже если у вас нет обширных знаний об алгоритмах, вы можете успешно обучить собственную модель с помощью таких инструментов. Помимо поддержки обучения больших моделей, DolphinScheduler также поддерживает планирование больших данных и планирование машинного обучения, помогая вам и вашему нетехническому персоналу легко справляться с обработкой больших данных, подготовкой данных, обучением моделей и развертыванием моделей. Кроме того, он имеет открытый исходный код и может использоваться бесплатно.
- Юридические и нормативные ограничения для больших моделей с открытым исходным кодом. DolphinScheduler — это просто визуальный инструмент рабочего процесса ИИ, который не предоставляет больших моделей с открытым исходным кодом. При использовании и загрузке больших моделей с открытым исходным кодом вы должны знать о различных ограничениях использования, связанных с каждой моделью, и соблюдать соответствующие лицензии на открытый исходный код. Примеры, приведенные в этой статье, предназначены только для личного обучения и получения опыта. При использовании больших моделей важно обеспечить соответствие лицензированию модели с открытым исходным кодом. Кроме того, в разных странах действуют разные строгие правила в отношении хранения и обработки данных. При использовании больших моделей вы должны настроить и настроить модель в соответствии с конкретными правовыми нормами и политиками вашего местоположения. Это может включать специальную фильтрацию выходных данных модели в соответствии с местными правилами конфиденциальности и обработки конфиденциальной информации.
Также опубликовано здесь< /а>.
Оригинал