
Как ускорить свой трубопровод TensorFlow TF.Data
29 июля 2025 г.Обзор контента
Обзор
Анализ рабочий процесс
- Достаточно ли ваш трубопровод TF.Data, производящий данные достаточно быстро?
- Вы предварительно выберете данные?
Вы достигаете высокого использования процессора?
Анализ узкого места
Дополнительные ресурсы
Обзор
Это руководство предполагает знакомство с TensorFlowПрофилировщикиtf.dataПолем Он направлен на пошаговые инструкции с примерами, которые помогут пользователям диагностировать и исправить проблемы производительности трубопровода.
Чтобы начать, соберите профиль вашей работы TensorFlow. Инструкции о том, как это сделать, доступны дляЦП/графические процессорыиОблачный TPUПолем
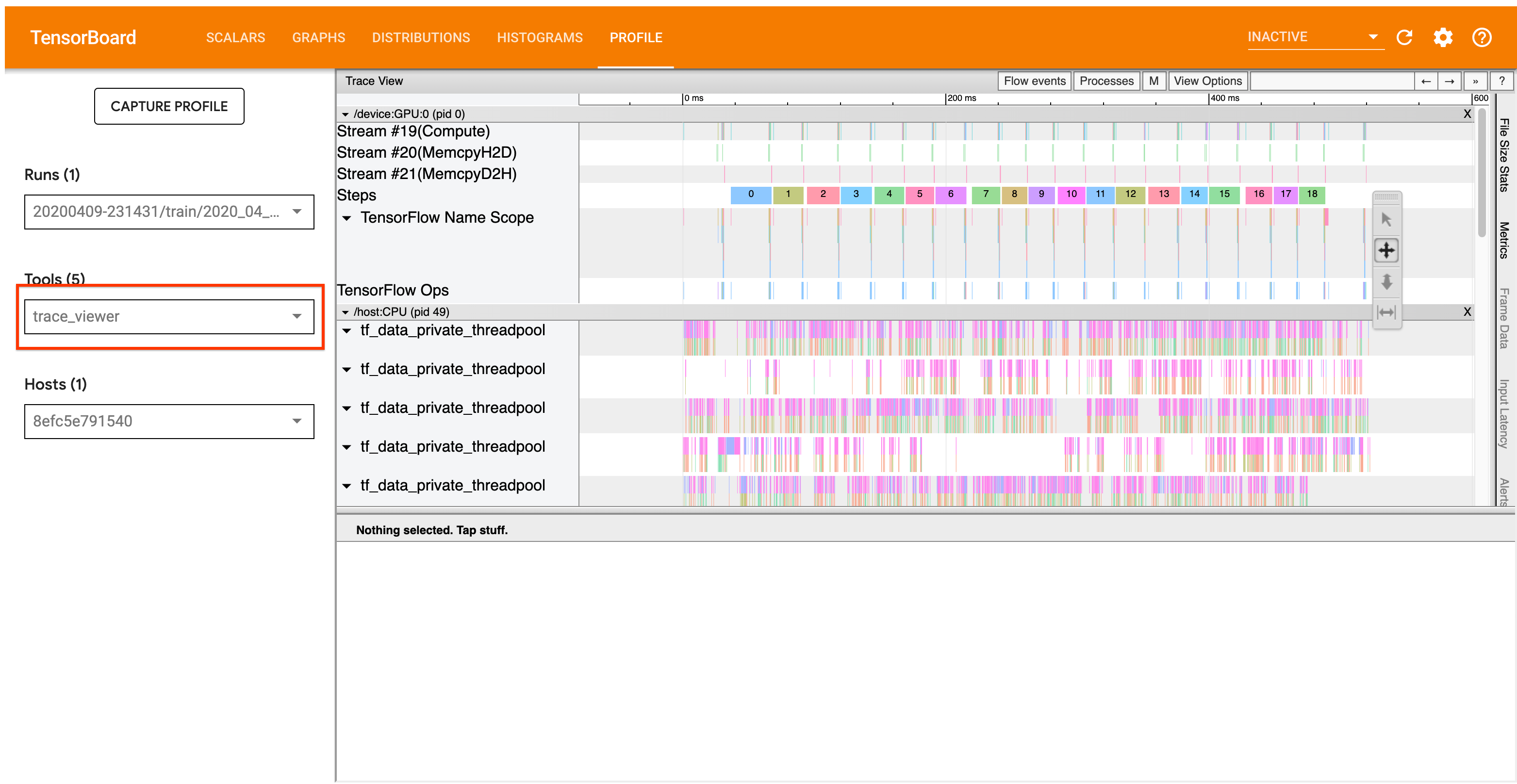
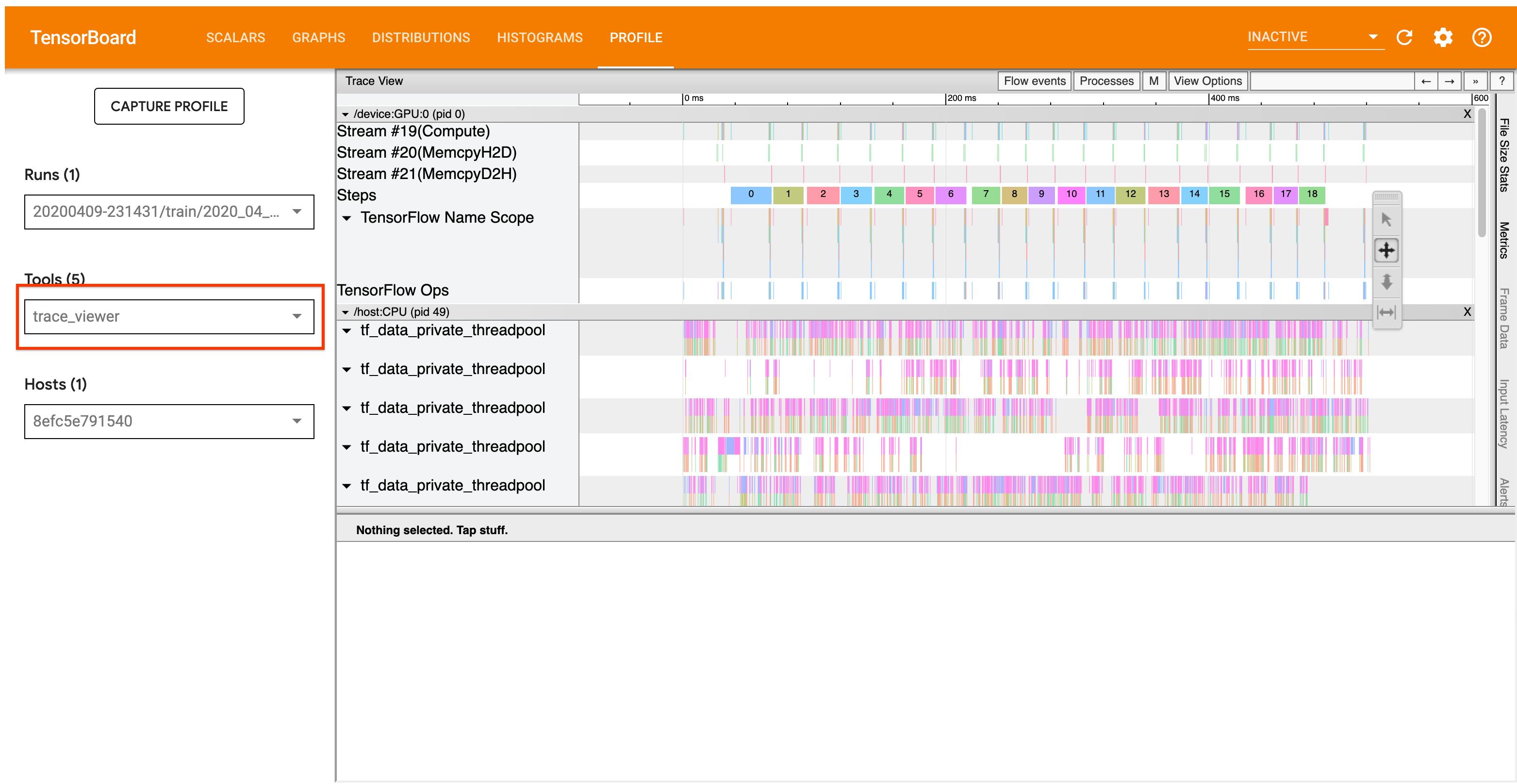
Рабочий процесс анализа, описанный ниже, фокусируется на инструменте Trace Viewer в Profiler. Этот инструмент отображает временную шкалу, которая показывает продолжительность OPS, выполненную вашей программой TensorFlow, и позволяет определить, какие OPS занимает самые длинные для выполнения. Для получения дополнительной информации о Trace Viewer, проверьтеэтот разделруководства TF Profiler. В общем,tf.dataСобытия появятся на временной шкале процессора хоста.
Анализ рабочий процесс
Пожалуйста, следуйте рабочему процессу ниже. Если у вас есть отзывы, чтобы помочь нам улучшить его, пожалуйстаСоздать проблему GitHubС этикеткой «Comp: Data».
1. Это вашtf.dataТрубопровод производит данные достаточно быстро?
Начните с того, что входной трубопровод является узким местом для вашей программы TensorFlow.
Для этого ищитеIteratorGetNext::DoComputeОПС в просмотре трассировки. В общем, вы ожидаете увидеть их в начале шага. Эти срезы представляют собой время, необходимое для вашего входного трубопровода, чтобы получить партию элементов при его запросе. Если вы используете кера или итерации по набору данных вtf.function, они должны быть найдены вtf_data_iterator_get_nextнить
Обратите внимание, что если вы используетеСтратегия распределения, вы можете увидетьIteratorGetNextAsOptional::DoComputeсобытия вместоIteratorGetNext::DoCompute(как TF 2.3).
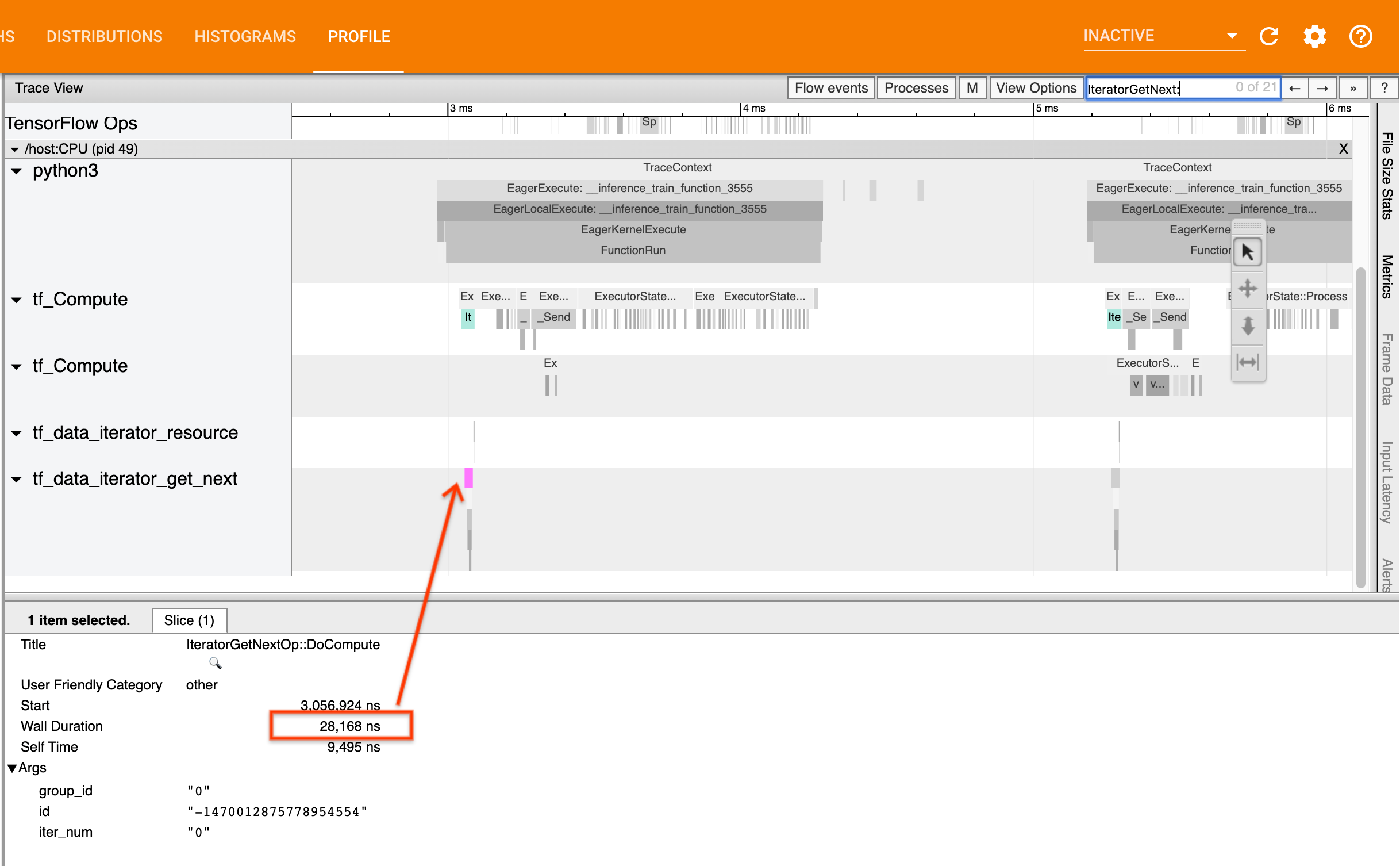
Если вызовы возвращаются быстро (<= 50 нас),Это означает, что ваши данные доступны, когда они запрашиваются. Входной трубопровод не является вашим узким местом; увидетьПрофилировщикДля более общих советов по анализу производительности.
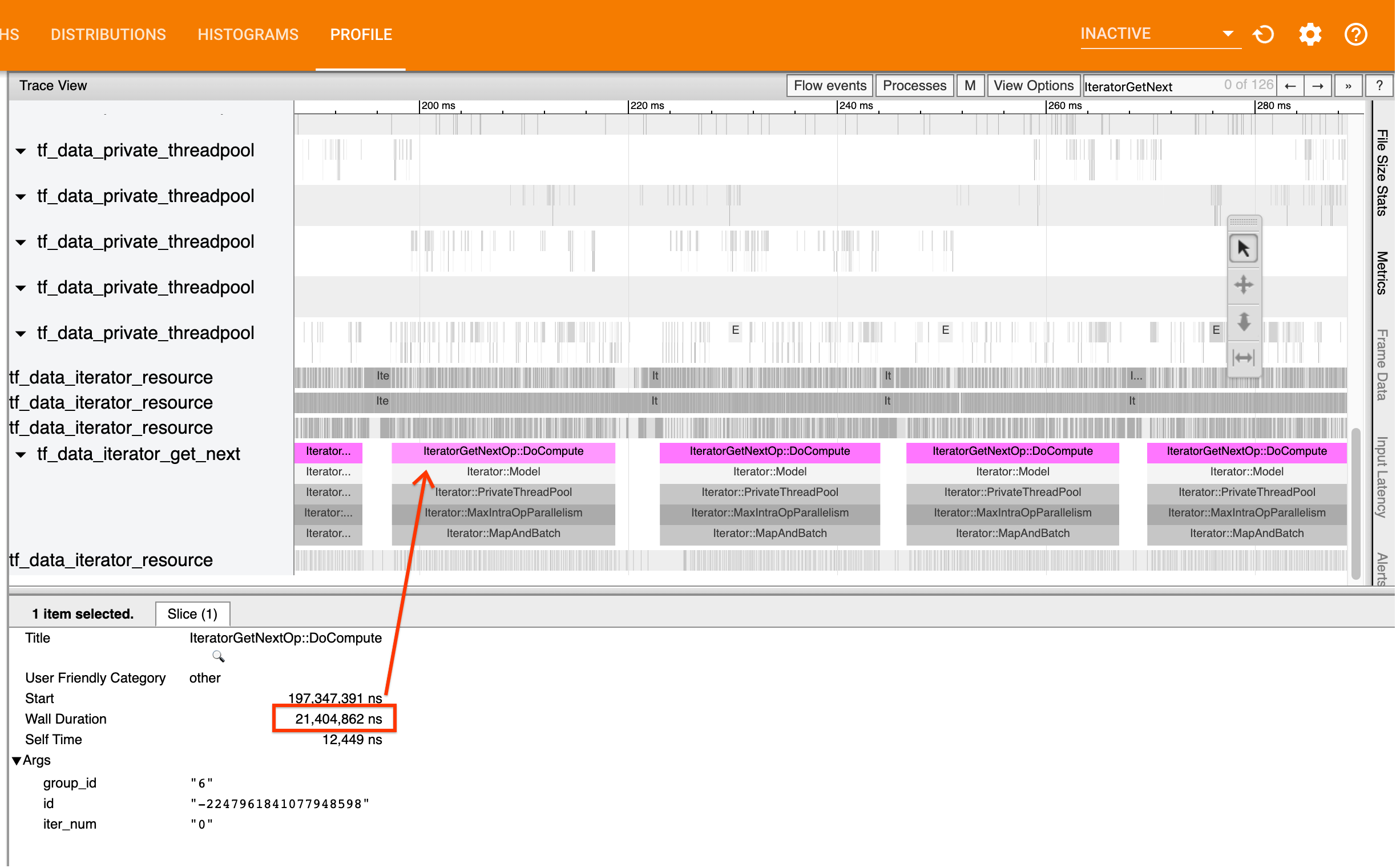
Если звонки возвращаются медленно,tf.dataне может быть в курсе запросов потребителя. Продолжить в следующем разделе.
2. Вы предварительно зарабатываете данные?
Лучшая практика для производительности входного трубопровода - вставитьtf.data.Dataset.prefetchтрансформация в конце вашегоtf.dataтрубопровод. Это преобразование перекрывает вычисление предварительной обработки входного трубопровода со следующим шагом вычисления модели и требуется для оптимальной производительности входного трубопровода при обучении вашей модели. Если вы предварительно выберете данные, вы должны увидетьIterator::Prefetchсрезать ту же нить, что иIteratorGetNext::DoComputeдоклада
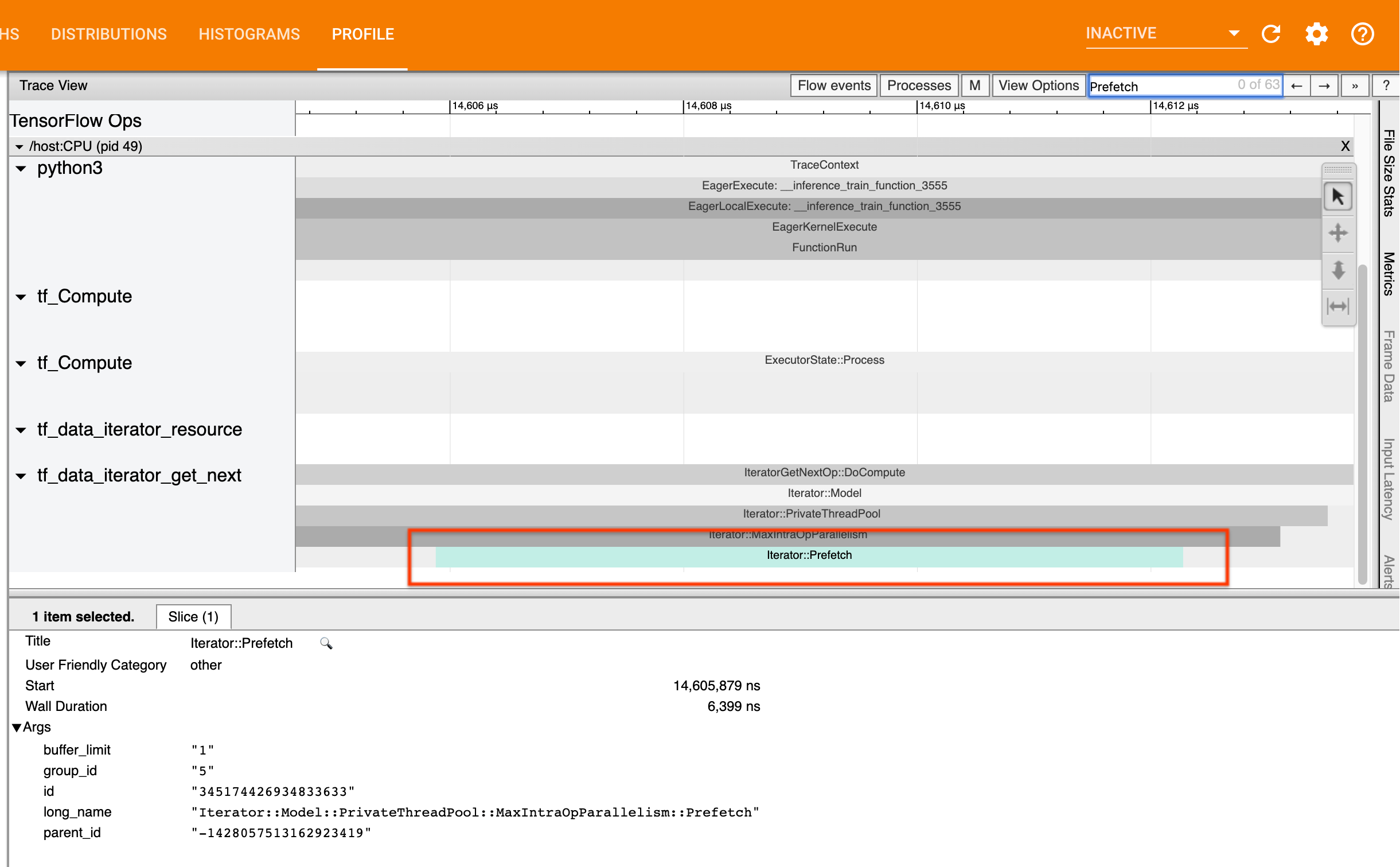
Если у вас нетprefetchВ конце вашего трубопровода вы должны добавить один. Для получения дополнительной информации оtf.dataрекомендации по производительности, см.TF.Data GuideПолем
Если вы уже предварительно выберете данныеи входной трубопровод по -прежнему ваш узкий место, продолжайте в следующем разделе, чтобы дополнительно анализировать производительность.
3. Вы достигаете высокого использования ЦП?
tf.dataдостигает высокой пропускной способности, пытаясь сделать наилучшее использование доступных ресурсов. В общем, даже при запуске вашей модели на ускорителе, как графический процессор или TPU,tf.dataТрубопроводы работают на процессоре. Вы можете проверить использование с такими инструментами, каксар -иHTOP, или вКонсоль мониторинга облакаЕсли вы работаете на GCP.
Если ваше использование низкое,Это говорит о том, что ваш входной конвейер может не использовать в полной мере для процессора хоста. Вы должны проконсультироватьсяTF.Data GuideДля лучших практик. Если вы применили лучшие практики и использование и пропускная способность оставаться низкими, продолжайтеАнализ узкого местаниже.
Если ваше использование приближается к ограничению ресурсаЧтобы улучшить производительность, вам необходимо либо повысить эффективность вашего входного трубопровода (например, избегать ненужных вычислений), либо вычисления разгрузки.
Вы можете повысить эффективность вашего входного трубопровода, избегая ненужных вычислений вtf.dataПолем Один из способов сделать это - вставитьtf.data.Dataset.cacheпреобразование после вычисления, интенсивной работы, если ваши данные вписываются в память; Это снижает вычисления за счет увеличения использования памяти. Кроме того, отключение внутриоперационного параллелизма вtf.dataимеет потенциал для повышения эффективности на> 10%и может быть сделан путем установки следующей опции на вашем входном трубопроводе:
dataset = ...
options = tf.data.Options()
options.experimental_threading.max_intra_op_parallelism = 1
dataset = dataset.with_options(options)
4. Анализ узкого места
Следующий раздел проходит, как читатьtf.dataСобытия в просмотре трассировки, чтобы понять, где находится узкое место и возможные стратегии смягчения последствий.
Пониманиеtf.dataСобытия в профилировке
Каждыйtf.dataСобытие в Profiler имеет имяIterator::<Dataset>, где<Dataset>Имя источника набора данных или преобразования. Каждое событие также имеет длинное названиеIterator::<Dataset_1>::...::<Dataset_n>, что вы можете увидеть, нажав наtf.dataсобытие. В длинном названии,<Dataset_n>матчи<Dataset>Из (короткого) имени, а другие наборы данных в длинном имени представляют собой преобразования вниз по течению.
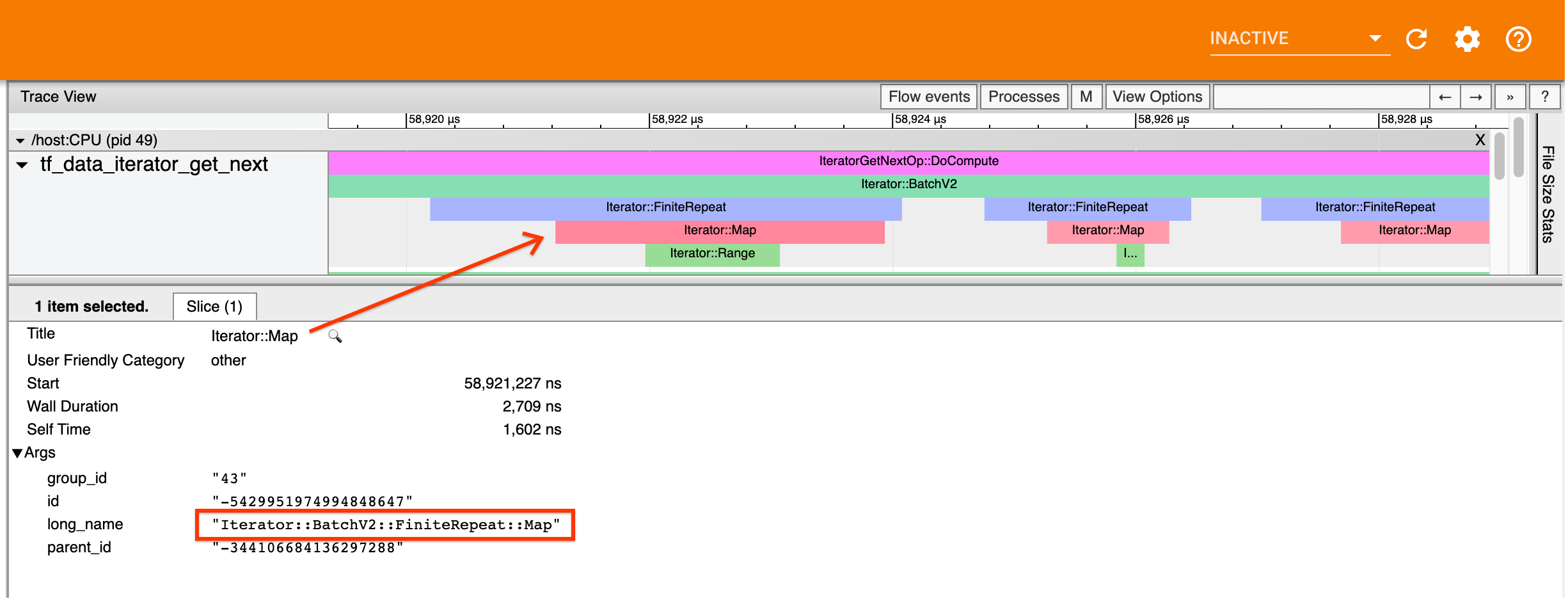
Например, приведенный выше скриншот был сгенерирован из следующего кода:
dataset = tf.data.Dataset.range(10)
dataset = dataset.map(lambda x: x)
dataset = dataset.repeat(2)
dataset = dataset.batch(5)
ЗдесьIterator::MapУ события есть длинное названиеIterator::BatchV2::FiniteRepeat::MapПолем Обратите внимание, что имя наборов данных может немного отличаться от API Python (например, финиалпипей вместо повторного), но должно быть достаточно интуитивно понятным для анализа.
Синхронные и асинхронные преобразования
Для синхронногоtf.dataПреобразования (такие какBatchиMap), вы увидите события из преобразований вверх по течению в том же потоке. В приведенном выше примере, поскольку все используемые преобразования синхронны, все события появляются в одном и том же потоке.
Для асинхронных преобразований (напримерPrefetchВParallelMapВParallelInterleaveиMapAndBatch) События из восходящих преобразований будут в другом потоке. В таких случаях «длинное имя» может помочь вам определить, какое преобразование в конвейере соответствует событию.
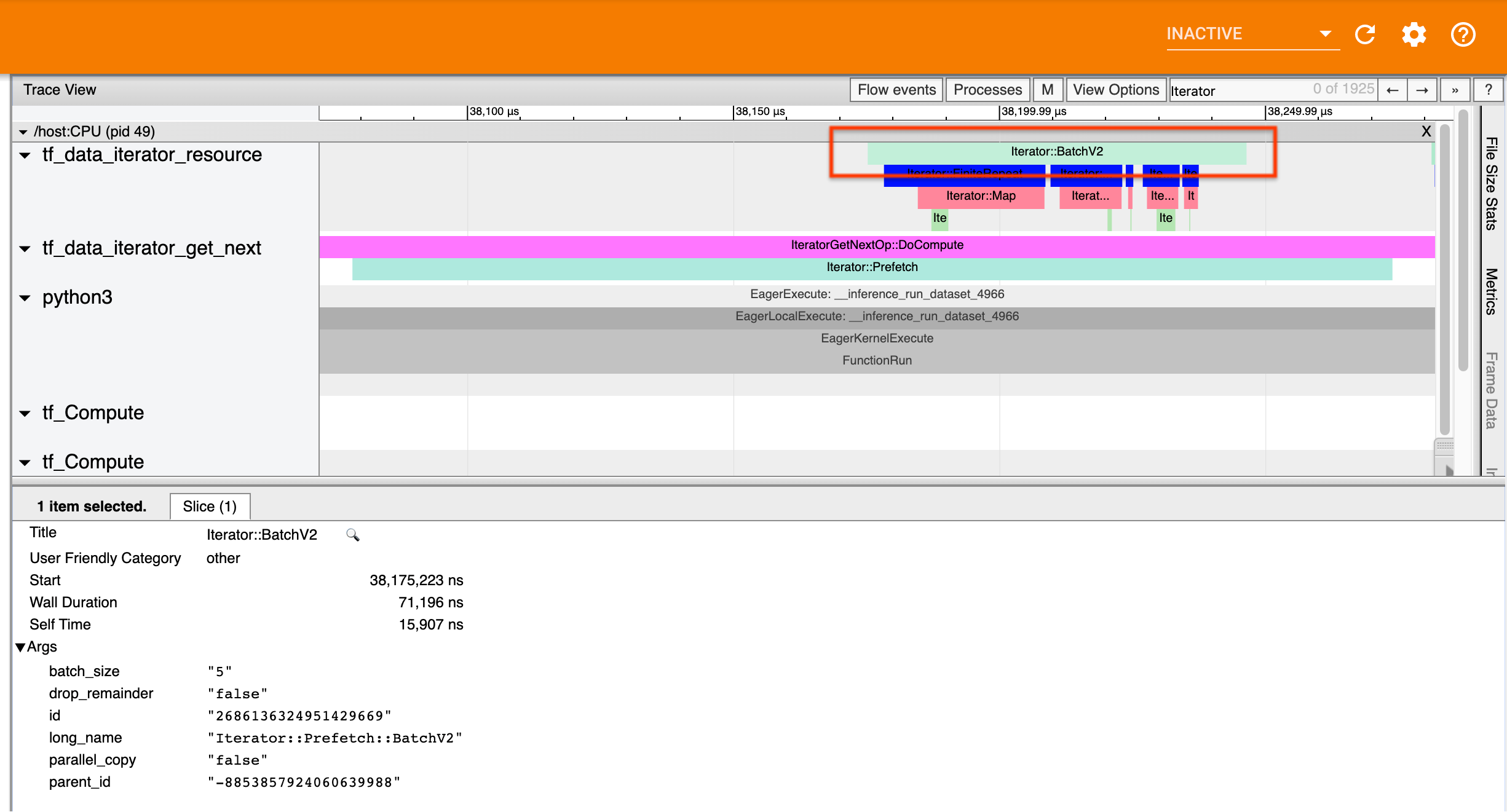 Например, приведенный выше скриншот был сгенерирован из следующего кода:
Например, приведенный выше скриншот был сгенерирован из следующего кода:
dataset = tf.data.Dataset.range(10)
dataset = dataset.map(lambda x: x)
dataset = dataset.repeat(2)
dataset = dataset.batch(5)
dataset = dataset.prefetch(1)
ЗдесьIterator::PrefetchСобытия наtf_data_iterator_get_nextнить СPrefetchасинхронно, его входные события (BatchV2) будет на другом потоке и может быть расположена путем поиска длинного имениIterator::Prefetch::BatchV2Полем В этом случае они находятся наtf_data_iterator_resourceнить. Из его длинного названия вы можете сделать вывод, чтоBatchV2находится выше по течениюPrefetchПолем Кроме того,parent_idпринадлежащийBatchV2событие будет соответствовать идентификаторуPrefetchсобытие.
Определение узкого места
В целом, чтобы идентифицировать узкое место в вашем входном трубопроводе, пройдите входной трубопровод от самого внешнего преобразования вплоть до источника. Начиная с окончательного преобразования в вашем трубопроводе, зарегистрируйтесь в преобразовании превышающего потока, пока не найдете медленное преобразование или не достигнете набора данных источника, например, какTFRecordПолем В примере выше, вы начнете сPrefetch, затем идите вверх по течениюBatchV2ВFiniteRepeatВMapи, наконецRangeПолем
В целом, медленное преобразование соответствует тому, чьи события длинные, но чьи входные события короткие. Некоторые примеры следуют ниже.
Обратите внимание, что окончательное (самое внешнее) преобразование в большинстве входных трубопроводов хоста - этоIterator::Modelсобытие. Трансформация модели автоматически вводитсяtf.dataСредство выполнения и используется для инструментального управления и автоматической производительности входного трубопровода.
Если ваша работа используетСтратегия распределения, просмотр просмотра трассировки будет содержать дополнительные события, которые соответствуют входному трубопроводу устройства. Самое внешнее преобразование трубопровода устройства (вложенное подIteratorGetNextOp::DoComputeилиIteratorGetNextAsOptionalOp::DoCompute) будетIterator::Prefetchмероприятие с восходящимIterator::Generatorсобытие. Вы можете найти соответствующий хост трубопровода, выполнив поискIterator::Modelсобытия.
Пример 1
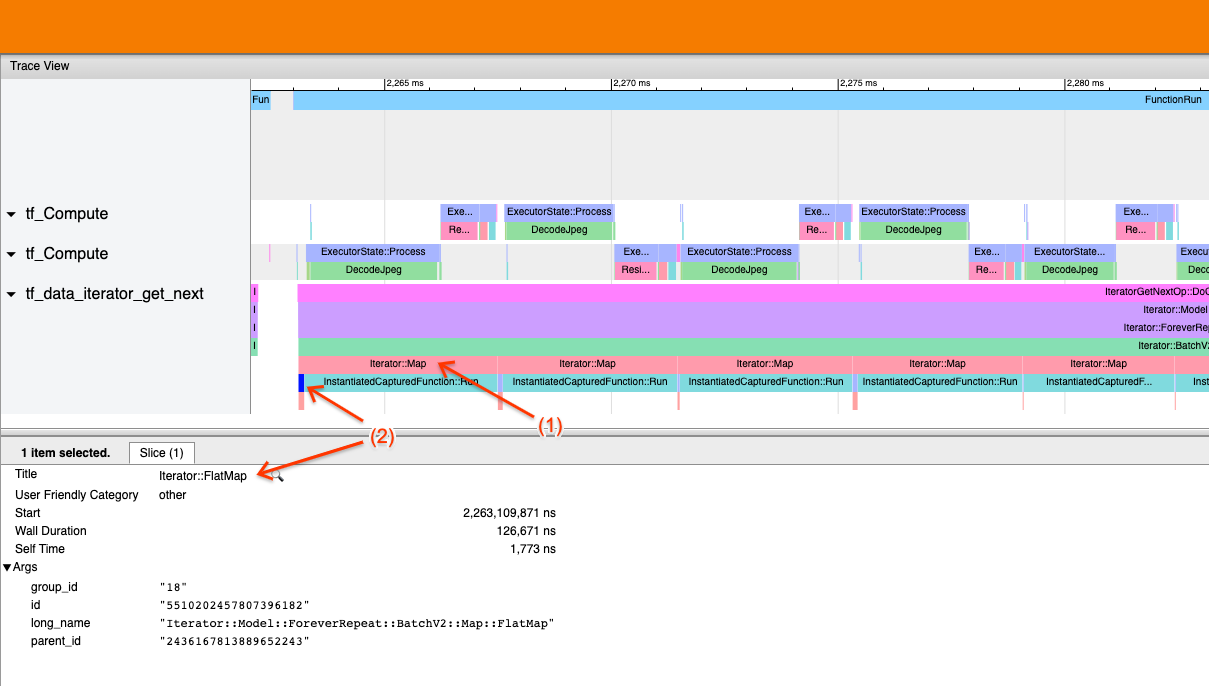
Приведенный выше скриншот генерируется из следующего входного конвейера:
dataset = tf.data.TFRecordDataset(filename)
dataset = dataset.map(parse_record)
dataset = dataset.batch(32)
dataset = dataset.repeat()
На скриншоте, заметите, что (1)Iterator::MapСобытия длинные, но (2) его входные события (Iterator::FlatMap) вернуться быстро. Это говорит о том, что последовательное преобразование карты является узким местом.
Обратите внимание, что на скриншоте,InstantiatedCapturedFunction::RunСобытие соответствует времени, необходимому для выполнения функции карты.
Example 2
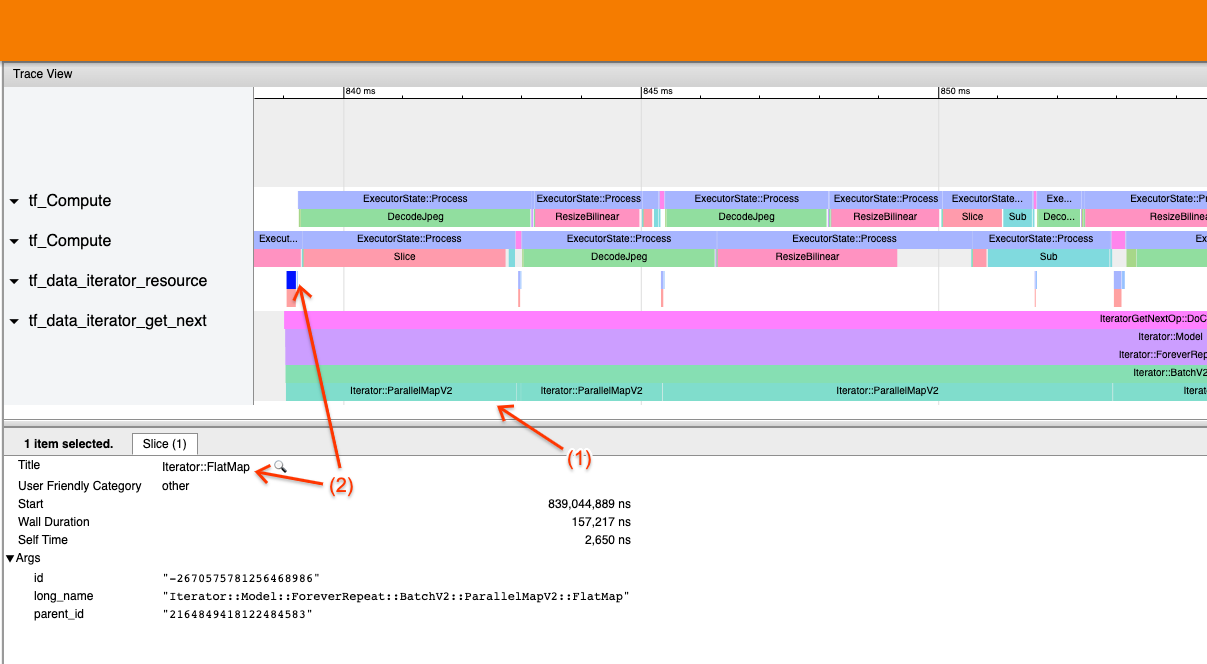
Приведенный выше скриншот генерируется из следующего входного конвейера:
dataset = tf.data.TFRecordDataset(filename)
dataset = dataset.map(parse_record, num_parallel_calls=2)
dataset = dataset.batch(32)
dataset = dataset.repeat()
Этот пример аналогичен вышеуказанному, но использует параллельную карту вместо карты. Здесь замечаем это (1)Iterator::ParallelMapСобытия длинные, но (2) его входные событияIterator::FlatMap(которые находятся в другом потоке, поскольку параллельная карта асинхронна) короткие. Это говорит о том, что трансформация параллельной карты является узким местом.
Обращаясь к узкому месту
Наборы данных источника
Если вы определили источник набора данных в качестве узкого места, например, чтение из файлов TFRECORD, вы можете повысить производительность, параллелизируя извлечение данных. Для этого убедитесь, что ваши данные будут нарушены по нескольким файлам и используютtf.data.Dataset.interleaveсnum_parallel_callsпараметр установлен наtf.data.AUTOTUNEПолем Если детерминизм не важен для вашей программы, вы можете еще больше улучшить производительность, установивdeterministic=Falseфлаг наtf.data.Dataset.interleaveС 2,2. Например, если вы читаете из Tfrecords, вы можете сделать следующее:
dataset = tf.data.Dataset.from_tensor_slices(filenames)
dataset = dataset.interleave(tf.data.TFRecordDataset,
num_parallel_calls=tf.data.AUTOTUNE,
deterministic=False)
Обратите внимание, что файлы Sharded должны быть достаточно большими, чтобы амортизировать накладные расходы открытия файла. Для получения более подробной информации об параллельном извлечении данных см.этот разделпринадлежащийtf.dataРуководство по производительности.
Наборы данных о преобразовании
Если вы определили промежуточныйtf.dataПреобразование как узкое место, вы можете обратиться к нему, параллелизируя преобразование иликэширование вычисленияЕсли ваши данные вписываются в память, и это уместно. Некоторые преобразования, такие какMapиметь параллельные аналоги; аtf.dataРуководство по производительности демонстрирует, как их параллелизировать. Другие преобразования, такие какFilterВUnbatch, иBatchпо своей природе последовательны; Вы можете параллелизировать их, введя «внешний параллелизм». Например, предположить, что ваш входной трубопровод изначально выглядит как следующее, сBatchКак узкое место:
filenames = tf.data.Dataset.list_files(file_path, shuffle=is_training)
dataset = filenames_to_dataset(filenames)
dataset = dataset.batch(batch_size)
Вы можете ввести «внешний параллелизм», запустив несколько копий входного трубопровода по поводу входов с осколками и объединив результаты:
filenames = tf.data.Dataset.list_files(file_path, shuffle=is_training)
def make_dataset(shard_index):
filenames = filenames.shard(NUM_SHARDS, shard_index)
dataset = filenames_to_dataset(filenames)
Return dataset.batch(batch_size)
indices = tf.data.Dataset.range(NUM_SHARDS)
dataset = indices.interleave(make_dataset,
num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.prefetch(tf.data.AUTOTUNE)
Дополнительные ресурсы
- TF.Data Guideо том, как писать производительность
tf.dataВходные трубопроводы - Внутри Tensorflow Video:
tf.dataлучшие практики - Профилировщик
- Учебник по профилировщику с Colab
Первоначально опубликовано на
Оригинал