

Как обращаться с бревенчащими шипами, такими как плюсы: как лучшие команды DevOps Tame Bursty Workloads
12 июля 2025 г.Продажа билетов Тейлор Свифт принесла всю платформу на колени ... крипто -биржи, в 10 раз его обычный трафик во время качания по цене ... Праздничные сделки упали в полночь, и розничные сайты встали, чтобы не отставать. Это были не просто моменты с высоким трафиком. Это были бревенчатые штормы.
Для команд DevOps в Bursty Verticals, таких как СМИ, Fintech, Gaming и Retail, подобные моменты, такие как Make Or Break. Независимо от того, планируется ли всплеск (например, падение продукта) или непредсказуем (например, упоминание влияния), то, что происходит за кулисами, интенсивно: трубопроводы могут затопить, затраты на употребление проглатывания могут всплыть, а панели панели часто замерзают, когда вам больше всего нужны.
Мы рассмотрим, как команды лучших подготовки к этим скачкам журнала до того, как они попадут. Вы узнаете, как современные платформы наблюдения предлагают масштабируемые архитектуры, динамическое примирение и модели ценообразования, которые сгибаются с спросом, а не против этого. Мы также распаковываем реальные сценарии, где дела идут не в плане, и показать, как другой подход мог бы смягчить все пожарные в темноте.
Что делает «взрывую» вертикаль такой сложной
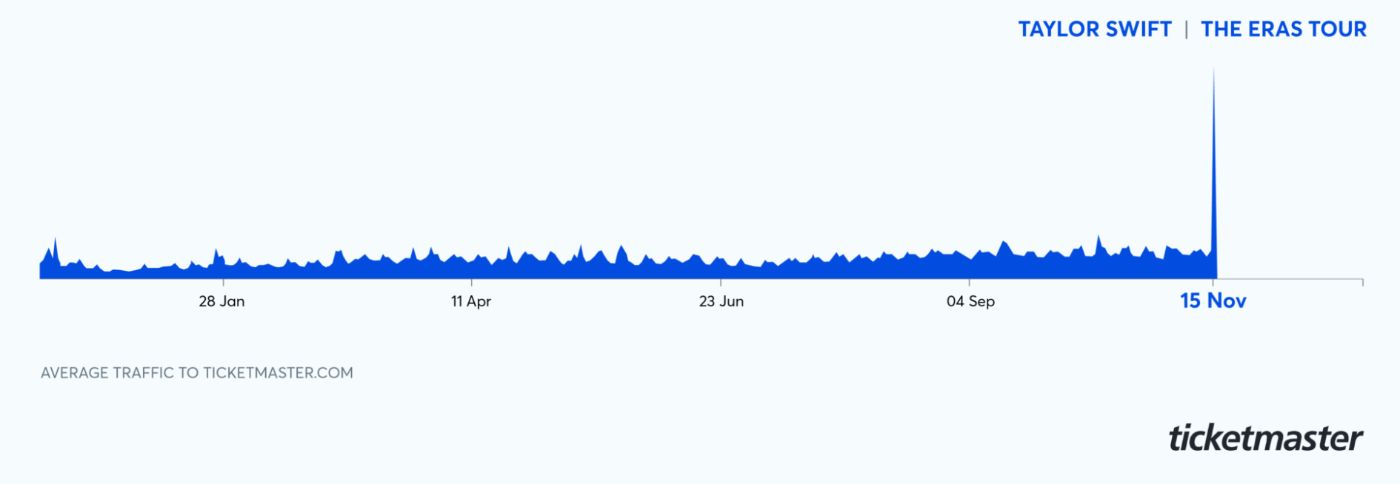
Проблемы с масштабированием: расплавление Ticketmaster
Во -первых, давайте посмотрим на задачу масштабирования. Самое сложное в работе в взрывающей вертикали - это не просто масштабирование; Он делает это быстро, не теряя видимости и не взорвая ваш бюджет.
Обвал Ticketmaster во время предварительной продажи Eras Taylor Swift стал мастер-классом в том, что может пойти не так, когда системы не подготовлены к одновременным глобальным скачкам спроса. Платформа увидела3,5 миллиарда запросов системыЗа один день, в четыре раза выше предыдущего пика. И это был не просто фронт, который боролся.
Сообщается, что конверсии наблюдаемости были перегружены заместимостью, что замедляло анализ первопричин и задержанные усилия по восстановлению. Это был случай, когда Ticketmaster знал, что будет значительный спрос, но они просто не ожидали, что он будет таким большим.
Для команд в области электронной коммерции, медиа, Fintech и игр эти всплески могут прибыть практически без предупреждения. Продажи флэш -продажи, вирусные моменты, разбрызгивание новостей или крипто -рыночные движения создают внезапный спрос, который может опередить даже лучшие модели масштабирования прогнозирования. Даже хорошо организованные кампании, такие как падение продукта или ограниченное излучение NFT Mint, могут выявить объемы, которые затмевают нормальные базовые показатели.
Опять же, задача здесь - не только шкала приложений, но иШкала наблюденияПолем Объем журналов не просто линейно растут с трафиком; Они часто вспыхивают в геометрической прогрессии. Вызовы API увеличиваются. Ошибки умножаются. События безопасности воздушный шар. Внезапно, что была управляемой настройкой журнала, превращается в пожарную часть данных, которые традиционные инструменты ведения журнала не созданы для обращения.
Почему? Большинство устаревших систем управления журналами зависят от жестких трубопроводов и фиксированных цен. Когда увеличивается объем, либо бревна, сброшенные, дроссельные, либо хранятся по неустойчивым затратам.Хуже того, инженерные команды часто предпочитают принимать только конкретные журналы, фильтрующие данные, которые впоследствии могут оказаться критическими для отладки или криминалистики.
Это решение, под давлением, может иметь неприятные последствия.
Потеря доверия: Robinhood - темное
Наша вторая задача - надежная сортировка и поиск основной причины.
РассмотримПеребои в ролиПолем В то время как компания сослалась на «беспрецедентные объемы», пользователи и аналитики отметили, что компания по сути потемнела, пока они пытались выяснить, что происходит. Прозрачность была ограничена длячасыПолем
Без надежной наблюдения во время пикового стресса диагностика сбоев стала догадками, и доверие получило удар.
В средах Bursty командам DevOps нужны инструменты, которые масштабируются так же быстро, как и их спрос, и не менее важно, что модели ценообразования, которые не наказывают их за успех. Именно здесь появляются платформы наблюдения следующего поколения, предлагая эластичное проглатывание и умный уровень, которые сохраняют текущие бревна, видимые и предсказуемые затраты-даже когда все остальное вспыхивает.
Давайте теперь посмотрим на некоторые решения.
Современные платформы наблюдения, которые «созданы для взрыва»
Когда нажимают скачки трафика, ваши пользователи ожидают того же опыта, который они испытали до всплеска. И для этого вашей команде DevOps нужны инструменты наблюдения, которые не тают под давлением.
Вот почему современные платформы наблюдаемости приняли архитектурыпостроен для BurstyПолем Они спроектированы с нуля до динамического масштаба, сохраняют полные бревна и поверхностную информацию, даже когда объемы непредсказуемы.
Они используют без схемы проглатывания, проглатывают все модели и ИИ для сортировки. Давайте посмотрим на каждого.
Без схемы приема
В отличие от устаревших систем, которые полагаются на ручную фильтрацию журнала или схемы с жестким кодированием, сегодняшние лидеры наблюдаемости поддерживают лидеры.Без схемы приема, то есть вы можете перекачивать как структурированные, так и неструктурированные данные. Это означает все, от журналов JSON до необработанных сообщений об ошибках и ослабления оповещений без необходимости перенастроить трубопроводы.
Современные платформы, такие какСумо логикапостроены для обработки внезапных скачков данных, не пропуская ни одного удара. Его архитектура автоматически масштабирует трубопроводы по употреблению и выполняет индексацию в реальном времени, чтобы поддерживать реагирование на панели и быстро реагировать на мониторные панели, даже под принуждением.
В соответствии синженеры, во время крупного производственного события, где объемы проглатывания журнала более чем удвоились, платформа сохраняла производительность, одновременно увеличивая затраты только на 10% благодаря своему упругому масштабированию.
Этот вид эффективности имеет решающее значение во время событий высокого давления, таких как вечера выборов или запуска вирусных продуктов, где команды не могут позволить себе слепые места в своем стеке наблюдения.
Все употребляет
Традиционные платформы заставляют команды переоценки для пиковой нагрузки. Тем не менее, современные платформы предлагают ценообразование платежных и инновационных моделей, такие как Flex Credits, которые позволяют командам временно «взрываться» без более высоких текущих затрат. Лучшие платформы также предлагают планы «проглатывать все», где вы можете войти в систему, но платить только за то, что вы на самом деле используете.
Более современные планы ценообразования, как и вышеупомянутые, контролируют бюджеты и исключают догадки от планирования мощностей.
ИИ для сортировки
Настоящий изменение игры? Встроенное машинное обучение. Когда объем журнала удваивается или тройки, люди не могут просеивать все.
Инструменты, такие как обнаружение аномалий Sumo Logic и Logreduce автоматически кластера повторяющиеся линии журнала, выделяют отклонения от базовых моделей и поднимают основные причины, прежде чем клиенты заметили.
Вот как команды продолжают простоя коротко и посмерти информативны. Если ваша платформа наблюдения не может масштабироваться, индекс и представление о поверхности в режиме реального времени в самые важные часы, она не готова к взрывающим рабочим нагрузкам.
Как лучшие команды остаются спокойными во время шторма
Мало того, что вам нужны правильные инструменты для обработки всплесков, но вам также нужны правильное мышление и обучение. Когда бревна начинают летать, и панель мониторинга загорается, как рождественская елка, паника легкая - проста -Но лучшие команды остаются спокойными, потому что они готовы к хаосуПолем
Стресс-тест на ваши трубопроводы
Ведущие команды DevOps практикуют то, что по сути является инженерией хаоса для наблюдения: они не просто тестируют устойчивость приложений при нагрузке-они намеренно испытывают стресс, испытывают свои трубопроводы.
Например, в Netflix инженеры регулярно имитируют отключения и скачки как часть своего «Испытания на инъекцию сбоя«Структура, которая включает в себя компоненты наблюдаемости для обеспечения работы инструментов мониторинга под давлением.
Но вам не нужно работать в шкале Netflix, чтобы извлечь выгоду из того же мышления. Эффективные команды имитируют наводнения журнала во время нагрузочных испытаний, которые продвигают трафик через промежуточные среды при отслеживании того, как проглатывание, индексация и предупреждение реагируют на повышенную нагрузку. Инструменты, такие как Grafana'sk6иСаранчаМожно имитировать тысячи запросов в секунду, в то время как синтетические генераторы журналов имитируют сценарии ошибок.
Ключевые показатели для просмотра во время этих тестов включают:
- Пропускная способность проглатывания: бревен сбрасываются, задерживаются или задерживаются?
- Задержка предупреждения: критические оповещения все еще вовремя стреляют?
- Переходы уровня хранения: маршрутизируются ли журналы в холодное или более дешевое хранилище, как разработано?
Используйте многословные журналы
Кроме того, команды могут подать заявкуинтеллектуальное распределение, то есть, маршрутизационные журналы отладки вводится на более низкие уровни, сохраняя при этом высокие ценные или производительные журналы в горячем хранилище. Динамические правила выборки и маршрутизации гарантируют, что вы не перегружены, и что более важно, что вы не теряете сигнал во время шума.
Невербозенные журналы (высокое значение):
Держите их в горячем хранилище; Они содержат немедленно полезную информацию.
{
"timestamp": "2025-06-17T13:02:11Z",
"level": "ERROR",
"service": "auth-api",
"message": "Failed login attempt",
"userId": "923188",
"ip": "203.0.113.42",
"error": "Invalid password"
}
Логические журналы (низкое значение):
Эти бревна могут происходить миллионы раз в день, в то время как они не часто полезны для ежедневных метрик, в течение бурных периодов они могут быть ведущим показателем проблемы.
{
"timestamp": "2025-06-17T13:02:12Z",
"level": "DEBUG",
"service": "auth-api",
"message": "Parsed user agent",
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"ip": "203.0.113.42"
}
Воспользуйтесь блюдами
Операционная готовность также означает людей, а не только инструменты. Лучшие команды развиваютсяrunbooks, специально адаптированная документация для сценариев взрыва, включая предупреждение на основе объемов, которое адаптирует пороговые значения в зависимости от временных окон или исторических норм. Четкие пути эскалации и ролевые назначения уменьшают путаницу, когда считать секунды.
Разница между хаосом и контролем? Подготовка. Лучшие платформы наблюдения подтверждают эту подготовку - и лучшие команды рассматривают Bursty Events как тренировки, которые они уже репетировали.
Заключение
Взрывные рабочие нагрузки больше не являются редкими исключениями-они являются новыми нормальными в высокоскоростных отраслях, таких как электронная коммерция, медиа, Fintech и игры. От падения вирусного продукта до торговли бешенствами, эти моменты создают не только пики трафиков, но и кризисы наблюдения.
Традиционные инструменты управления журналами часто терпят неудачу под давлением, либо дросселирующие данные, либо подавляющие команды с шумом. Вот почему ведущие команды DevOps полагаются на платформы наблюдения, специально предназначенные для масштаба, скорости и гибкости. Благодаря без схемы приема, эластичной масштабируемости и моделей ценообразования на основе использования, таких как Flex Credits, эти платформы не просто продолжают течь; Они сохраняют доступ к доступности, когда это важнее всего. Лучшие команды не ждут, когда всплеск проверит свою устойчивость: они репетируют хаос, имитируют всплески и стратегии оповещения тонкой настройки, чтобы они могли действовать с уверенностью, а не путаница. Поскольку в мире, где цифровые показатели напрямую связаны с успехом бизнеса, способность погоды бревенчатым штормам не является роскошью - это конкурентное преимущество.
Оригинал