

Как создать собственный голосовой помощник и запустить его локально с помощью Whisper + Ollama + Bark
3 апреля 2024 г.После моего последнего поста о том, как создать свой собственный RAG и запустить его локально, сегодня мы делаем еще один шаг вперед, не только реализуя разговорные возможности больших языковых моделей, но и добавляя возможности аудирования и говорения. Идея проста: мы собираемся создать голосового помощника, напоминающего Джарвиса или Пятницу из культовых фильмов о Железном человеке, который сможет работать на вашем компьютере в автономном режиме.
Поскольку это вводное руководство, я реализую его на Python и сделаю его достаточно простым для новичков. Наконец, я дам несколько рекомендаций по масштабированию приложения.

Технический стек
Сначала вам следует настроить виртуальную среду Python. Для этого у вас есть несколько вариантов, включая pyenv, virtualenv, поэтику и другие, которые служат аналогичной цели. Лично я буду использовать Poetry для этого урока из-за моих личных предпочтений. Вот несколько важных библиотек, которые вам необходимо установить:
* rich: для визуально привлекательного вывода на консоль. * openai-whisper: надежный инструмент для преобразования речи в текст. * suno-bark: передовая библиотека для синтеза речи, обеспечивающая высококачественный аудиовыход. * langchain: простая библиотека для взаимодействия с моделями большого языка (LLM). * звуковое устройство, pyaudio и распознавание речи: необходимы для запись и воспроизведение звука.
Подробный список зависимостей можно найти по ссылке здесь.
Наиболее важным компонентом здесь является серверная часть модели большого языка (LLM), для которой мы будем использовать Ollama. Ollama широко известен как популярный инструмент для запуска и обслуживания программ LLM в автономном режиме. Если Оллама для вас новичок, я рекомендую прочитать мою предыдущую статью об автономной RAG: "Создайте свой собственный RAG и запустите его локально: Langchain + Ollama + Streamlit." По сути, вам просто нужно загрузить приложение Ollama, извлечь предпочитаемую модель и запустить ее. .
Архитектура
Хорошо, если все настроено, переходим к следующему шагу. Ниже представлена общая архитектура нашего приложения, которая состоит из трех основных компонентов:
* Распознавание речи. Используя OpenAI's Whisper, мы преобразуем устную речь в текст. Обучение Whisper на различных наборах данных обеспечивает знание различных языков и диалектов.
* Разговорная цепочка. Для обеспечения диалоговых возможностей мы будем использовать интерфейс Langchain для Llama-2 модель, которая обслуживается с помощью Ollama. Такая установка обещает беспрепятственный и увлекательный диалог.
* Синтезатор речи: преобразование текста в речь достигается с помощью Bark, состояния -современная модель от Suno AI, известная своей реалистичной речью.
Рабочий процесс прост: записывайте речь, транскрибируйте в текст, генерируйте ответ с помощью LLM и озвучивайте ответ с помощью Bark.
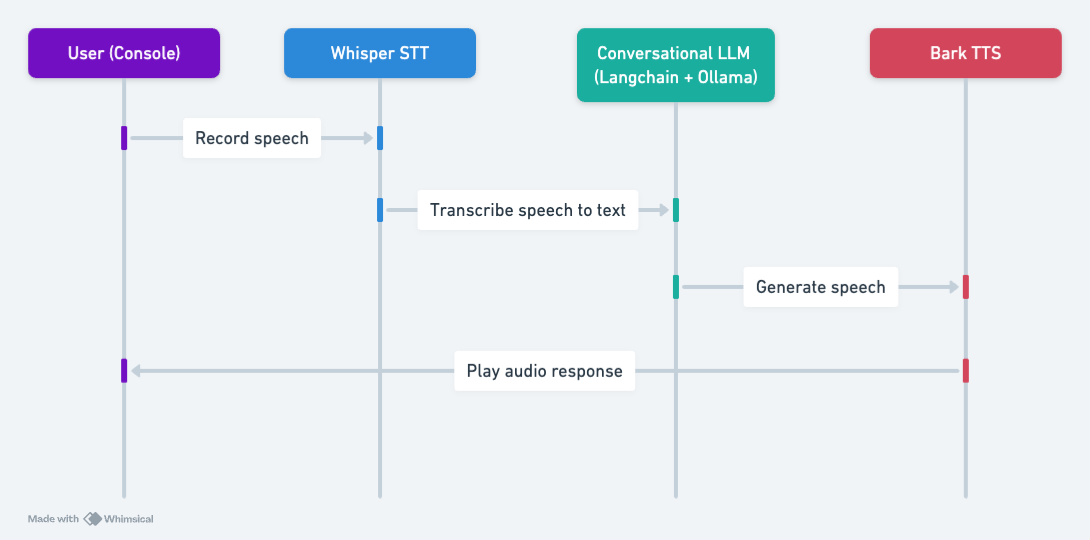
Схема последовательности действий голосового помощника с Whisper, Ollama и Bark.
Реализация
Реализация начинается с создания TextToSpeechService на основе Bark, включающего методы синтеза речи из текста и беспрепятственной обработки более длинных текстовых вводов следующим образом:
import nltk
import torch
import warnings
import numpy as np
from transformers import AutoProcessor, BarkModel
warnings.filterwarnings(
"ignore",
message="torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.",
)
class TextToSpeechService:
def __init__(self, device: str = "cuda" if torch.cuda.is_available() else "cpu"):
"""
Initializes the TextToSpeechService class.
Args:
device (str, optional): The device to be used for the model, either "cuda" if a GPU is available or "cpu".
Defaults to "cuda" if available, otherwise "cpu".
"""
self.device = device
self.processor = AutoProcessor.from_pretrained("suno/bark-small")
self.model = BarkModel.from_pretrained("suno/bark-small")
self.model.to(self.device)
def synthesize(self, text: str, voice_preset: str = "v2/en_speaker_1"):
"""
Synthesizes audio from the given text using the specified voice preset.
Args:
text (str): The input text to be synthesized.
voice_preset (str, optional): The voice preset to be used for the synthesis. Defaults to "v2/en_speaker_1".
Returns:
tuple: A tuple containing the sample rate and the generated audio array.
"""
inputs = self.processor(text, voice_preset=voice_preset, return_tensors="pt")
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.no_grad():
audio_array = self.model.generate(**inputs, pad_token_id=10000)
audio_array = audio_array.cpu().numpy().squeeze()
sample_rate = self.model.generation_config.sample_rate
return sample_rate, audio_array
def long_form_synthesize(self, text: str, voice_preset: str = "v2/en_speaker_1"):
"""
Synthesizes audio from the given long-form text using the specified voice preset.
Args:
text (str): The input text to be synthesized.
voice_preset (str, optional): The voice preset to be used for the synthesis. Defaults to "v2/en_speaker_1".
Returns:
tuple: A tuple containing the sample rate and the generated audio array.
"""
pieces = []
sentences = nltk.sent_tokenize(text)
silence = np.zeros(int(0.25 * self.model.generation_config.sample_rate))
for sent in sentences:
sample_rate, audio_array = self.synthesize(sent, voice_preset)
pieces += [audio_array, silence.copy()]
return self.model.generation_config.sample_rate, np.concatenate(pieces)
- Инициализация (
__init__): класс принимает необязательный параметрdevice, который указывает устройство, которое будет используемый для модели (либоcuda, если доступен графический процессор, либоcpu). Он загружает модель Bark и соответствующий процессор из предварительно обученной моделиsuno/bark-small. Вы также можете использовать большую версию, указавsuno/barkдля загрузчика модели.
* Synthesize (synthesize): этот метод принимает входные данные text и voice_preset. параметр, который определяет голос, который будет использоваться для синтеза. Вы можете проверить другое значение voice_preset здесь. Он использует процессор для подготовки входного текста и голосовых настроек, а затем генерирует аудиомассив с помощью метода model.generate(). Сгенерированный аудиомассив преобразуется в массив NumPy, и вместе с аудиомассивом возвращается частота дискретизации.
* Синтез длинной формы (long_form_synthesize): этот метод используется для синтеза более длинных текстовых вводов. Сначала он разбивает входной текст на предложения с помощью функции nltk.sent_tokenize. Для каждого предложения он вызывает метод synthesize для создания аудиомассива. Затем он объединяет сгенерированные аудиомассивы, добавляя между каждым предложением короткую паузу (0,25 секунды).
Теперь, когда у нас настроен TextToSpeechService, нам нужно подготовить сервер Ollama для обслуживания модели большого языка (LLM). Для этого вам необходимо выполнить следующие действия:
* Извлечь последнюю модель Llama-2. Чтобы загрузить последнюю модель Llama-2 из репозитория Ollama, выполните следующую команду: ollama pull llama2. >
* Запустить сервер Ollama. Если сервер еще не запущен, выполните для его запуска следующую команду: ollama serve.
После выполнения этих шагов ваше приложение сможет использовать сервер Ollama и модель Llama-2 для генерации ответов на ввод пользователя.
Далее мы перейдем к основной логике приложения. Во-первых, нам нужно инициализировать следующие компоненты:
- Расширенная консоль. Мы будем использовать библиотеку Rich, чтобы создать более качественную интерактивную консоль для пользователя в терминале.
* Преобразование речи в текст: мы инициализируем модель распознавания речи Whisper, которая представляет собой современную систему распознавания речи с открытым исходным кодом, разработанную OpenAI. Мы будем использовать базовую английскую модель (base.en) для расшифровки пользовательского ввода.
* Преобразование текста в речь Bark: мы инициализируем экземпляр синтезатора речи Bark, который был реализован выше.
* Цепочка диалога: мы будем использовать встроенный ConversationalChain из библиотеки Langchain, который предоставляет шаблон для управления потоком диалога. Мы настроим его для использования языковой модели Llama-2 с серверной частью Ollama.
import time
import threading
import numpy as np
import whisper
import sounddevice as sd
from queue import Queue
from rich.console import Console
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain_community.llms import Ollama
from tts import TextToSpeechService
console = Console()
stt = whisper.load_model("base.en")
tts = TextToSpeechService()
template = """
You are a helpful and friendly AI assistant. You are polite, respectful, and aim to provide concise responses of less
than 20 words.
The conversation transcript is as follows:
{history}
And here is the user's follow-up: {input}
Your response:
"""
PROMPT = PromptTemplate(input_variables=["history", "input"], template=template)
chain = ConversationChain(
prompt=PROMPT,
verbose=False,
memory=ConversationBufferMemory(ai_prefix="Assistant:"),
llm=Ollama(),
)
Теперь определим необходимые функции:
record_audio: эта функция выполняется в отдельном потоке для захвата аудиоданных с микрофона пользователя с помощьюsounddevice.RawInputStream. Функция обратного вызова вызывается всякий раз, когда доступны новые аудиоданные, и помещает данные вdata_queueдля дальнейшей обработки.
* transcribe: эта функция использует экземпляр Whisper для расшифровки аудиоданных из data_queue в текст.
* get_llm_response: эта функция передает текущий контекст разговора в языковую модель Llama-2 (через Langchain ConversationalChain) и извлекает сгенерированный текстовый ответ.
* play_audio: эта функция принимает аудиосигнал, сгенерированный процессором преобразования текста в речь Bark, и воспроизводит его пользователю с помощью библиотеки воспроизведения звука (например, sounddevice). .
def record_audio(stop_event, data_queue):
"""
Captures audio data from the user's microphone and adds it to a queue for further processing.
Args:
stop_event (threading.Event): An event that, when set, signals the function to stop recording.
data_queue (queue.Queue): A queue to which the recorded audio data will be added.
Returns:
None
"""
def callback(indata, frames, time, status):
if status:
console.print(status)
data_queue.put(bytes(indata))
with sd.RawInputStream(
samplerate=16000, dtype="int16", channels=1, callback=callback
):
while not stop_event.is_set():
time.sleep(0.1)
def transcribe(audio_np: np.ndarray) -> str:
"""
Transcribes the given audio data using the Whisper speech recognition model.
Args:
audio_np (numpy.ndarray): The audio data to be transcribed.
Returns:
str: The transcribed text.
"""
result = stt.transcribe(audio_np, fp16=False) # Set fp16=True if using a GPU
text = result["text"].strip()
return text
def get_llm_response(text: str) -> str:
"""
Generates a response to the given text using the Llama-2 language model.
Args:
text (str): The input text to be processed.
Returns:
str: The generated response.
"""
response = chain.predict(input=text)
if response.startswith("Assistant:"):
response = response[len("Assistant:") :].strip()
return response
def play_audio(sample_rate, audio_array):
"""
Plays the given audio data using the sounddevice library.
Args:
sample_rate (int): The sample rate of the audio data.
audio_array (numpy.ndarray): The audio data to be played.
Returns:
None
"""
sd.play(audio_array, sample_rate)
sd.wait()
Затем мы определяем основной цикл приложения. Основной цикл приложения проводит пользователя через диалоговое взаимодействие следующим образом:
- Пользователю предлагается нажать Enter, чтобы начать запись введенных данных.
- Оптимизация производительности. Включите оптимизированные версии моделей, таких как quiet.cpp, llama.cpp и bark.cpp, которые предназначены для повышения производительности, особенно на компьютерах более низкого уровня.< /ли>
2. Как только пользователь нажимает Enter, функция record_audio вызывается в отдельном потоке для захвата аудиовхода пользователя.
3. Когда пользователь снова нажимает Enter, чтобы остановить запись, аудиоданные расшифровываются с помощью функции transscribe.
4. Расшифрованный текст затем передается в функцию get_llm_response, которая генерирует ответ с использованием языковой модели Llama-2.
5. Сгенерированный ответ выводится на консоль и воспроизводится пользователю с помощью функции play_audio.
if __name__ == "__main__":
console.print("[cyan]Assistant started! Press Ctrl+C to exit.")
try:
while True:
console.input(
"Press Enter to start recording, then press Enter again to stop."
)
data_queue = Queue() # type: ignore[var-annotated]
stop_event = threading.Event()
recording_thread = threading.Thread(
target=record_audio,
args=(stop_event, data_queue),
)
recording_thread.start()
input()
stop_event.set()
recording_thread.join()
audio_data = b"".join(list(data_queue.queue))
audio_np = (
np.frombuffer(audio_data, dtype=np.int16).astype(np.float32) / 32768.0
)
if audio_np.size > 0:
with console.status("Transcribing...", spinner="earth"):
text = transcribe(audio_np)
console.print(f"[yellow]You: {text}")
with console.status("Generating response...", spinner="earth"):
response = get_llm_response(text)
sample_rate, audio_array = tts.long_form_synthesize(response)
console.print(f"[cyan]Assistant: {response}")
play_audio(sample_rate, audio_array)
else:
console.print(
"[red]No audio recorded. Please ensure your microphone is working."
)
except KeyboardInterrupt:
console.print("n[red]Exiting...")
console.print("[blue]Session ended.")
Результат
Как только все будет собрано, мы сможем запустить приложение, как показано в видео выше. Приложение работает на моем MacBook довольно медленно, поскольку модель Bark большая, даже в уменьшенной версии. Поэтому я немного ускорил видео. Для тех, у кого есть компьютер с поддержкой CUDA, он может работать быстрее. Вот ключевые возможности нашего приложения:
* Голосовое взаимодействие. Пользователи могут запускать и останавливать запись своего голосового ввода, а помощник в ответ воспроизводит сгенерированный звук.
* Контекст разговора. Ассистент поддерживает контекст разговора, обеспечивая более связные и релевантные ответы. Использование языковой модели «Лама-2» позволяет ассистенту давать краткие и целенаправленные ответы.
Тем, кто хочет поднять это приложение до статуса готового к использованию, рекомендуются следующие улучшения:
* Настраиваемые подсказки бота: внедрите систему, которая позволяет пользователям настраивать персональный облик и подсказки бота, позволяя создавать различные типы помощников (например, личных, профессиональных или специфичных для конкретной области).
* Графический интерфейс пользователя (GUI). Разработайте удобный графический интерфейс пользователя, чтобы улучшить общее взаимодействие с пользователем, сделав приложение более доступным и визуально привлекательным.
* Мультимодальные возможности. Расширьте приложение, чтобы поддерживать мультимодальные взаимодействия, например возможность создавать и отображать изображения, диаграммы или другой визуальный контент в дополнение к голосовым ответам.
Наконец, мы завершили работу над нашим простым приложением голосового помощника, полный код можно найти по адресу: https://github.com/vndee/ local-talking-llm. Такое сочетание распознавания речи, языкового моделирования и технологий преобразования текста в речь демонстрирует, как мы можем создать что-то, что кажется сложным, но на самом деле может работать на вашем компьютере. Давайте наслаждаться программированием и не забудьте подписаться на мой блог, чтобы не пропустить последние статьи об искусственном интеллекте и программировании. .
Также опубликовано здесь
Оригинал