
Как построить пациента с нуля (и все еще доверять результатам)
10 июня 2025 г.Авторы:
(1) Николас I-Hsien Kuo, автор-корреспондент из Центра исследований больших данных в области здравоохранения, факультет медицины, Университет Нового Южного Уэльса, Сидней, Новый Южный Уэльс, Австралия (Австралия (Австралия (Австралия (Австралия (Австралияn.kuo@unsw.edu.au);
(2) Бланка Галлего, Центр исследований больших данных в области здравоохранения, Медицинский факультет, Университет Нового Южного Уэльса, Сидней, Новый Южный Уэльс, Австралия;
(3) Луиза Р. Джорм, Центр исследований больших данных в области здравоохранения, Медицинский факультет, Университет Нового Южного Уэльса, Сидней, Новый Южный Уэльс, Австралия.
Обзор контента
- Аннотация и введение
- Методы
- Результаты
- Дискуссия
- Заключение и ссылки
АбстрактныйПолем Доступ к реальным клиническим данным часто ограничивается из -за обязательств по конфиденциальности, создавая значительные барьеры для исследований в области здравоохранения. Синтетические наборы данных обеспечивают многообещающее решение, обеспечивая безопасное обмен данными и разработку модели. Тем не менее, большинство существующих подходов сосредоточены на реализме данных, а не на утилите - обеспечение того, чтобы модели, обученные синтетическим данным, дают клинически значимую информацию, сравнимую с моментами, обученными реальными данными. В этой статье мы представляем маскированное клиническое моделирование (MCM), структуру, вдохновленную маскарованным языком, предназначенным как для синтеза данных, так и для условного увеличения данных. Мы оцениваем этот прототип на наборе данных WHAS500 с использованием моделей пропорциональных опасностей Кокса, сосредоточив внимание на сохранении соотношений опасности в качестве ключевых клинических показателей. Наши результаты показывают, что данные, генерируемые с использованием структуры MCM, улучшают как дискриминацию, так и калибровку в анализе выживаемости, опережая существующие методы. MCM демонстрирует большой потенциал для поддержки анализа данных выживаемости и более широких приложений здравоохранения.
1. Введение
Доступ к реальным клиническим данным в области здравоохранения часто ограничивается из -за руководящих принципов и правил конфиденциальности, создавая проблемы для воспроизводимости и обобщения в клинических исследованиях [1,2]. Следовательно, растет интерес к реалистичным синтетическим наборам данных, которые позволяют исследовать при защите конфиденциальности пациентов. В то время как генерация данных о синтетических здравоохранениях продвинулась, многое внимание уделялось визуальному и статистическому реализму, часто пренебрегаяутилита- Способность моделей, обученных синтетическим данным для получения результатов в соответствии с тем, что обучалось реальным данным. Немногие исследования оценили полезность синтетических наборов данных для анализа выживаемости [3], ключевого метода, используемого в клинических исследованиях, включая клинические испытания и обсервационные исследования. В этом методе часто используются модели пропорциональных опасностей Кокса (COXPH) [4] для оценки коэффициентов опасности (HRS), которые количественно определяют влияние переменных на результаты времени к событию, такие как ремиссия или смерть.
Чтобы устранить этот пробел, мы предлагаемКлиническое моделирование в масках (MCM),Новая структура, вдохновленная моделированием языка в масках, используемой в таких моделях, как Bert [5]. MCM поддерживает как синтез данных, так и условную генерацию данных, также позволяя увеличить данные. Синтез данных создает реалистичные наборы данных для безопасного обмена, в то время как увеличение данных генерирует целевые данные для конкретных подгрупп (например, пациентов с определенным полом и возрастом), обращаясь к дисбалансу наборов данных. Эта статья оценивает прототип MCM с использованием хорошо известного набора данных WHAS500 [6].
2. Методы
2.1. Набор данных WHAS500
Набор данных WHAS500 представляет собой подмножество более широкого исследования сердечных приступов Вустера (WHAS) [6], долгосрочного популяционного исследования, направленного на понимание заболеваемости и результатов выживания после острого инфаркта миокарда. WHAS500 состоит из 500 пациентов и широко используется для анализа времени до события. Чтобы оценить производительность нашего прототипа MCM, мы сосредоточились на следующих ключевых функциях:
• Демография: Возраст и пол.
• Измерения:Индекс массы тела (ИМТ) и систолическое артериальное давление (SBP).
• Хронические состояния: История аритмии, фибрилляция (AF) и застойная сердечная недостаточность (CHF).
Базовая линия - пациент мужского пола со средним ИМТ, нормальным SBP и без анализа AF или CHF. Основной конечной точкой является смерть. См. Подробные описания переменных в [7].
2.2. Маскированное клиническое моделирование
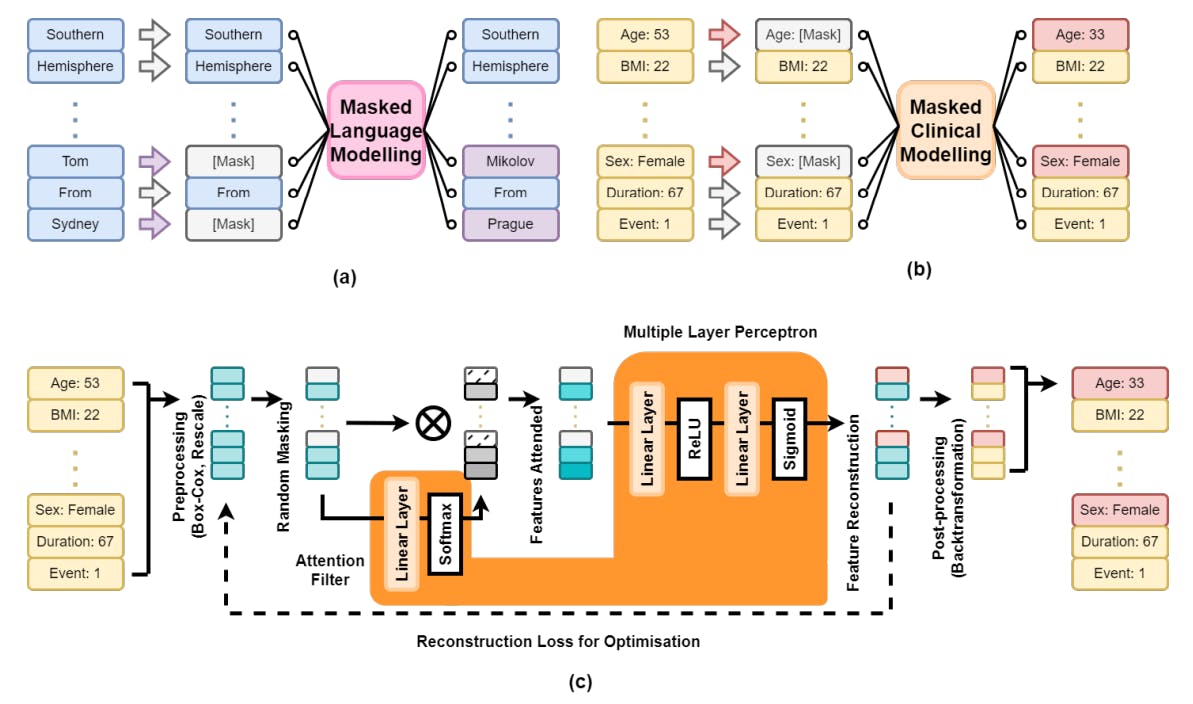
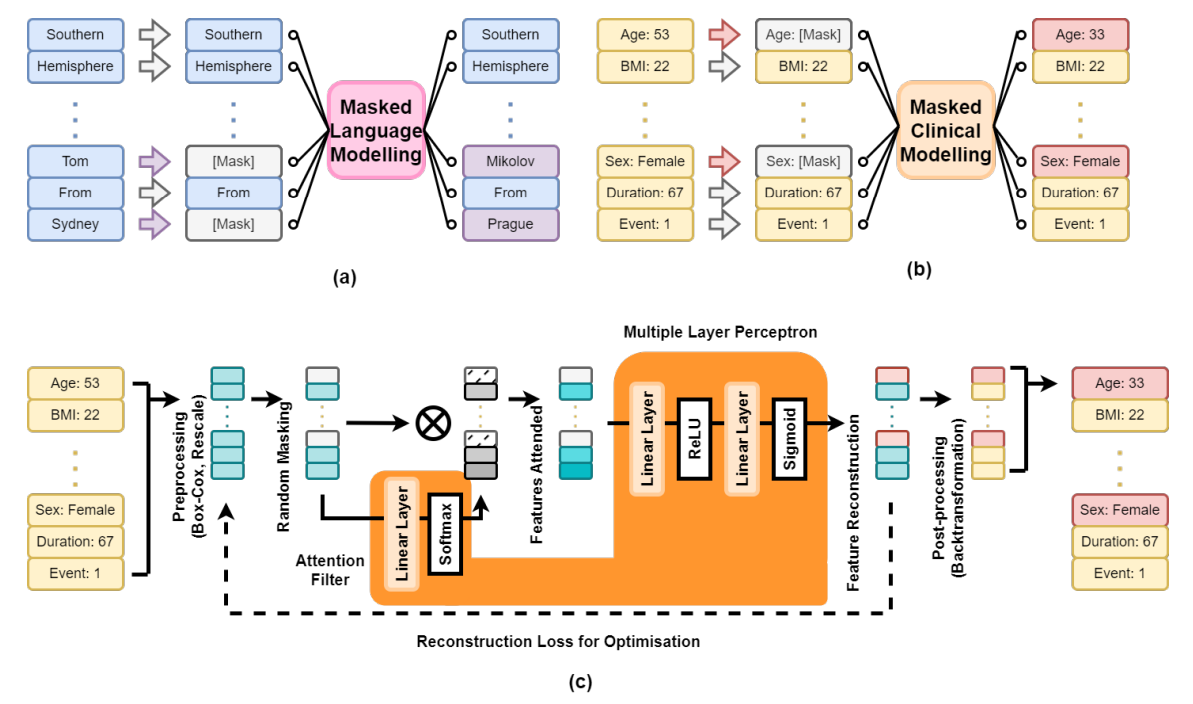
На рисунке 1 представлен обзор нашей структуры клинического моделирования в масках (MCM). В подписании (а) моделирование языка в масках скрывает случайные слова в предложении, предсказывая пропущенные слова с использованием контекста. Подфигура (b) адаптирует это к MCM, где клинические данные пациента x с n функциями случайным образом маскируются (например, возраст, пол), а модель реконструирует недостающую информацию из оставшихся данных. Подфигура (c) показывает инженерный трубопровод: преобразование предварительной обработки x → V через преобразование Box-Cox [8], чтобы нормализовать числовые переменные и восстановление всех функций до [0,1]. После маскировки данные передаются в модель.

Этот подход поддерживает как синтез данных, так и увеличение. Для синтеза части существующего набора данных замаскированы и реконструированы. Для увеличения могут быть получены профили пациентов с определенными признаками. Например, чтобы генерировать 300 пациентов в возрасте 50–55 лет с временем наблюдения 240–300 дней, мы создаем кадр данных с 300 строками, выбираем желаемые значения из равномерных распределений и передаем неполные данные в MCM для завершения. Это позволяет генерации клинически значимых данных для нижестоящих задач.
Мы представляем прототип модели MCM с двухслойным MLP и 64 скрытыми измерениями. Из -за пространственных ограничений выбранные результаты представлены в разделе «Результаты», с более подробным анализом, запланированным для будущей работы. После принятия весь код будет предоставлен публично доступным через GitHub.
3. Результаты
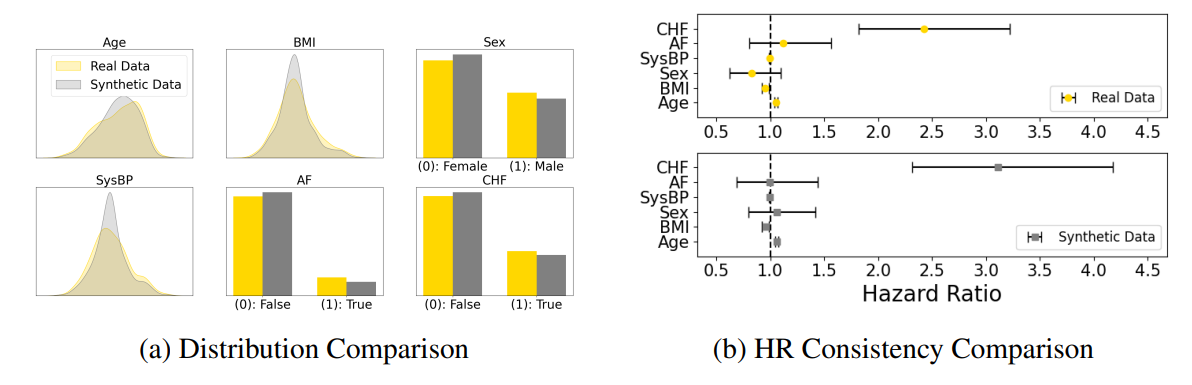
На рисунке 2 мы показываем, как MCM генерирует синтетические данные, которые внимательно отражают основную истину. После маскировки 75% реальных данных модель реконструировала пропущенные значения. Подфигура (а) сравнивает числовые распределения и бинарные переменные, показывая сильное соответствие между реальными и синтетическими данными. Чтобы оценить клиническую полезность, мы обучили модель COXPH на обоих наборах данных и сравнили коэффициенты опасности (HRS). Подфигура (b) демонстрирует сильное выравнивание HR, указывая на то, что синтетические данные сохраняют значимые корреляции для анализа нижнего течения.
Мы исследуем, как синтетические данные могут увеличить истинность наземной истины, чтобы повысить производительность модели COXPH Нижнего потока, сосредоточив внимание на двух ключевых показателях: дискриминация, измеренная C-индексом Харрелла [9] (выше лучше, идеальная дискриминация-1) и калибровка, оцениваемая по отклонению от идеального склона 1 (ниже). Результаты, обобщенные в таблице 1, основаны на перекрестной проверке 5x2 [10], со средним (SD). Базовые сравнения включают в себя модели COXPH, обученные исключительно реальным данным, и дополненные синтетическими данными из SMOTE [11], VAE [12], мышей [13] и нашего метода MCM. Удар обнаруживает классы меньшинства и генерирует данные посредством линейной интерполяции; VAE реконструирует данные с использованием нейронной сети с отобранными скрытыми функциями; и мыши вменяют отсутствующие данные, используя регрессию байесовского хребта после маскировки [14]. Все синтетические данные добавляются в учебные данные для каждой перекрестной проверки.
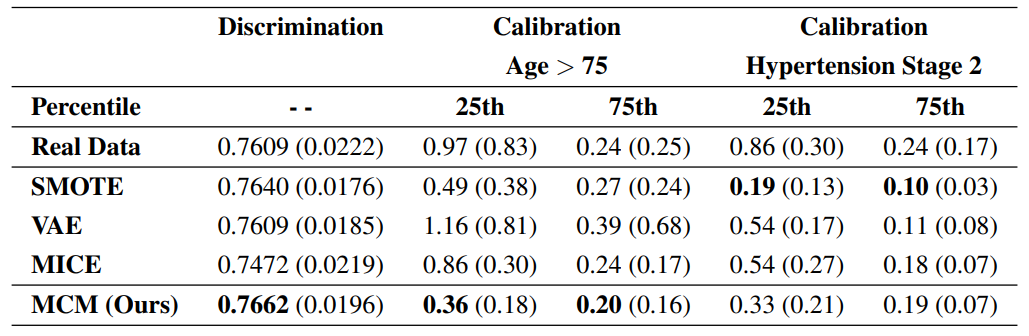
Для дискриминации VAE, мышей и MCM создали 500 новых синтетических пациентов. Мыши и MCM реконструировали данные, случайным образом маскируя 50% функций; и подать синтезировал 70 дополнительных пациентов из класса меньшинства. Наш метод MCM вызвал наибольшее улучшение в C-индексе, увеличив оценку с 0,7609 до 0,7662. Удачно принесло небольшое улучшение, VAE не показал эффекта, а мыши ухудшили производительность модели.
Для калибровки мы распределили пациентов на две когорты: 216 человек в возрасте старше 75 и 276 с стадией гипертонии 2 (SBP> 140 мм рт. Ст.). Калибровка была рассчитана на 25-м и 75-м процентилях продолжительности времени до события для оценки влияния синтетических данных на прогнозирование риска для пациентов с высоким и низким риском. VAE, мыши и MCM условно сгенерировали в 5 раз больше данных для стратифицированной когорты; и Smote был использован для перебалансировки основных распределений. Только с реальными данными, Coxph показал плохую калибровку на 25-м процентиле, с уклоном 0,97 для когорты более 75 и 0,86 для гипертонии. MCM значительно сократил смещения до 0,36 и 0,33 соответственно. На 75 -м процентиле, где Coxph показал хорошо, MCM дополнительно улучшил калибровку. Мыши выполнялись разумно в разных сценариях, VAE были хороши для гипертонии, но не работали для когорты более 75 и ударили с давшими смешанными результатами.
4. Обсуждение
MCM представляет новый подход к синтетической и дополненной генерации данных о выживании. Адаптируя моделирование языка в масках, оно обеспечивает как реализм, так и полезность, сохраняя ключевые клинические показатели, такие как HRS. Применившись к набору данных WHAS500, MCM продемонстрировал улучшенную дискриминацию и калибровку для анализа выживания, превосходящих ударов, VAE и мышей в задачах COXPH. Его условная способность генерации дает потенциал для минимизации рисков раскрытия и атрибуции идентификации (то есть обнаружение чего -то нового о индивидууме) [15] в синтетических данных путем обогащения наборов данных с большим количеством людей, имеющих необычные комбинации характеристик.
5. Заключение
MCM уравновешивает реализм и утилиту данных, что делает его ценным для создания синтетических наборов данных, которые сохраняют клинические данные. Сохранение последовательности персонала, MCM поддерживает обмен данными в клинических исследованиях и образовании.
Ссылки
[1] Н.И. Куо, М.Н. Polizzotto, S. Finfer, F. Garcia, A. Sonnerborg, M. Zazzi, M. Bohm, R. Kaiser, L. Jorm и S. Barbieri, The Health Gym: наборы данных, связанных с здоровьем, для разработки алгоритмов обучения подкрепления, научные данные 9 (2022), 1–24.
[2] Н.И. Kuo, O. perez-concha, M. Hanly, E. Mnatzaganian, B. Hao, M. Di Sipio, G. Yu, J. Vanjara, I.C. Valerie, et al., Обогащение науки о данных и здравоохранении: применение и влияние наборов синтетических данных в рамках проекта по тренажерному зале Health Gym, Jmir Medical Education 10 (2024), E51388.
[3] A. Norcliffe, B. Cebere, F. Imrie, P. Lio и M. van der Schaar, Survivalgan: создание данных о времени для анализа выживания, Международная конференция по искусственному интеллекту и статистике (2023), 10279–10304.
[4] Д.Р. Кокс, Регрессионные модели и столы жизни, Журнал Королевского статистического общества: серия B (методологический) 34 (1972), 187–202.
[5] J. Devlin, Bert: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка, Arxiv Preprint arxiv: 1810.04805 (2018).
[6] Р.Дж. Goldberg, J.M. Gore, J.S. Альперт и Дж. Э. Дален, Частота летальности и летальности заболеваемости и случаев острой инфаркта миокарда (1975–1984): Исследование сердечного приступа Вустера, American Heart Journal 115 (1988), 761–767.
[7] Д.В. Hosmer JR, S. Lemeshow и S. May, Applied Survival Analysis: регрессионное моделирование данных по времени до события, John Wiley & Sons, 2008.
[8] G.E.P. Box и D.R. Кокс, Анализ трансформаций, Журнал Королевского статистического общества: серия B (статистическая методология) 26 (1964), 211–243.
[9] Ф. Э. Харрелл Р.М. Калифф, Д.Б. Прайор, К.Л. Ли и Р.А. Розати, оценка урожайности медицинских испытаний, JAMA 247 (1982), 2543–2546.
[10] Т.Г. Dietterich, приблизительные статистические тесты для сравнения алгоритмов обучения классификации, нейронные вычисления 10 (1998), 1895–1923.
[11] Н.В. Чавла, К.В. Бойер, Л.О. Холл и В.П. Kegelmeyer, Smote: Синтетическое меньшинство избыточной дискретизации, журнал исследований искусственного интеллекта 16 (2002), 321–357.
[12] Д.П. Кингма и М. Веллинг, Вариационные вариационные байеса, Международная конференция по обучению (2014).
[13] S. van Buuren и K. groothuis-oudshoorn, мыши: многомерное вменение цепными уравнениями в R, журнал статистического программного обеспечения 45 (2011), 1–67.
[14] D.J.C. Маккей, Байесовская интерполяция, Нейронная вычисления 4 (1992), 415–447.
[15] К. Эль -Эмам, Л. Москера и Дж. Басс, Оценка риска раскрытия информации о личности в полностью синтетических данных о здоровье: разработка и валидация модели, Журнал медицинского интернета 22 (2020), E23139.
Эта статья естьДоступно на ArxivПо лицензии CC 4.0.
Оригинал