

Как ускорить автоматическую маркировку данных для автономного вождения в гибридном облаке
23 марта 2022 г.В этом блоге приглашенный автор Feifei Cai (старший инженер-программист) и Hao Zhu (старший инженер-программист) делятся опытом использования Alluxio и Spark для ускорения системы маркировки данных автомобилей в WeRide, компании, занимающейся технологиями автономного вождения. Исходный контент был опубликован в блоге Alluxio (отказ от ответственности: автор является членом-основателем @Alluxio).
О WeRide

WeRide — ведущая мировая компания, разрабатывающая технологии автономного вождения L4. Компания WeRide, основанная в 2017 году, имеет штаб-квартиру в Гуанчжоу, Китай, а также научно-исследовательские и операционные центры в Пекине, Шанхае, Нанкине, Чжэнчжоу, Шэньчжэне, а также в Сан-Хосе в США.
WeRide запустила первую в Китае коммерческую услугу роботакси, полностью открытую для публики в 2019 году. Теперь WeRide предлагает комплексный набор продуктов для роботакси, мини-роботавтобуса и роботов. Мы предоставляем множество услуг, включая онлайн-заказ такси, транспорт по запросу и городскую логистику.
Почему Аллюксио
У Alluxio есть три основных преимущества: это быстро, просто и легко в использовании.
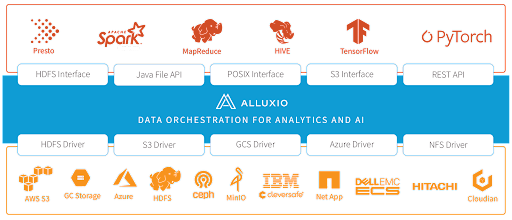
Во-первых, Alluxio работает быстро, так как обеспечивает распределенное кэширование. Ввод-вывод со скоростью памяти обеспечивается службой кэширования Alluxio. Кроме того, многоуровневое хранилище может использовать как память, так и диск, что делает его эластичным для экономичного масштабирования приложений, управляемых данными. Во-вторых, Alluxio обеспечивает упрощенный и унифицированный доступ к данным и управление ими. Наконец, Alluxio очень просто развернуть и использовать на существующей платформе данных. Например, Spark может работать поверх Alluxio без каких-либо изменений кода, всего одна строка изменения конфигурации.
Как мы используем Alluxio в WeRide
Разработка автономного вождения
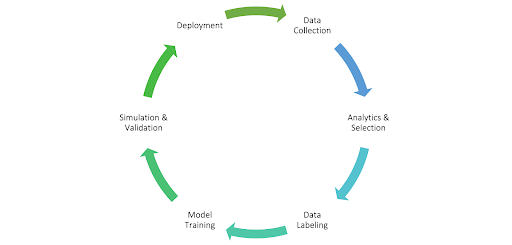
На приведенной выше диаграмме показан типичный рабочий процесс разработки автономного вождения в WeRide. Мы начинаем со сбора данных, каждый день собирая данные датчиков из парков тестовых автомобилей. После того, как данные собраны, мы загружаем их в облако. Затем данные обрабатываются и анализируются. После этого мы сделаем маркировку данных, маркировку карты HD и разработку. Далее мы проведем обучение модели машинного обучения для разработки алгоритма ИИ. Также будет проведено моделирование и проверка. Наконец, мы развернем как бортовой парк транспортных средств, так и внешние серверы.
У нас есть как аппаратное, так и программное обеспечение. Самая большая проблема — это размер данных. Мы генерируем много терабайт данных каждый день и накопили миллионы километров пробега, поэтому весь размер в петабайтах. Это требует огромных объемов памяти и значительной вычислительной мощности.
Тегирование данных
Теги иногда путают с метками. В автономном вождении метки обычно означают сценарии, а метки могут быть препятствиями или ящиками.
Например, на левом изображении ниже показан сценарий смены полосы движения, а на правом изображении — сценарий поворота направо. Мы пометим последовательность кадров тегами смены полосы движения или поворота направо. Метки здесь — это полоса движения, окружающие транспортные средства, препятствия и светофоры, которые отличаются от меток.
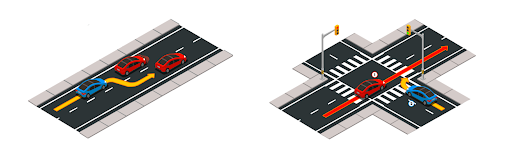
В рабочем процессе автономного вождения на основе данных теги данных играют важную роль в анализе данных. Имея результаты тегирования, мы можем выполнять выборку данных для поддержки последующих конвейеров, включая обучение модели, эталонное тестирование и долгосрочную оценку.
Alluxio + Spark в Kubernetes
Сквозной конвейер тегирования предназначен для сбора и загрузки файлов пакетов ROS (операционной системы для роботов) с тестовых автомобилей, а затем преобразования их в формат Parquet. После этого мы можем запускать задания Spark для выполнения алгоритмов анализа данных. Оттуда мы можем экспортировать результаты тегирования в нижестоящие конвейеры.
Как видно выше, архитектура системы вполне типична. Мы создаем и запускаем приложения в гибридном облаке как с общедоступным облаком, так и с локальными центрами обработки данных, исходя из следующих соображений: локальный центр обработки данных более экономичен и может быть настроен, а общедоступное облако легко масштабировать.
Как в общедоступном облаке, так и в локальных центрах обработки данных мы используем Kubernetes для управления вычислительными ресурсами кластеров ЦП и ГП, а также для планирования рабочего процесса и задач. На уровне хранилища мы используем MinIO для создания службы хранения объектов, совместимой с S3.
Alluxio предоставляет быстрый, упрощенный, унифицированный уровень данных, который объединяет S3, MinIO и Spark, а также другие приложения для анализа данных, что ускоряет рабочий процесс маркировки данных с появлением Alluxio.
Результаты теста
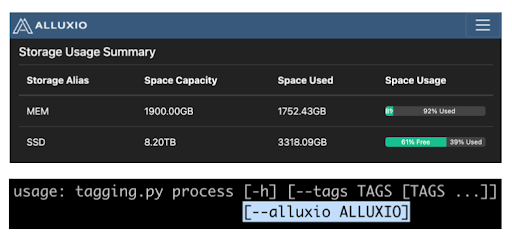
Мы следовали документации Alluxio для развертывания. Мы использовали контрольную диаграмму для развертывания тестового кластера на кластерах ЦП и ГП для 42 рабочих нагрузок. Мы использовали многоуровневое хранилище: нулевой уровень — это память с 50 ГБ, а первый уровень — SSD с 200 ГБ. На основе 42 рабочих узлов мы получили 2 ТБ памяти и 8 ТБ SSD.
Для тестов с тегами данных есть только одна строка изменения конфигурации, которую очень легко использовать. Мы добавили Alluxio в инструменты командной строки, но Alluxio включен по умолчанию и скрыт от конечных пользователей.
В целом, тест показывает примерно 7-кратное ускорение выполнения задач по добавлению тегов с введением Alluxio.
Будущая работа
Использование Alluxio в качестве унифицированного уровня оркестровки данных
Мы планируем создать унифицированный уровень данных с Alluxio в качестве уровня оркестровки данных. Наша цель — интегрироваться с большим количеством приложений, включая Presto, HIVE и TensorFlow, которые уже работают внутри WeRide.

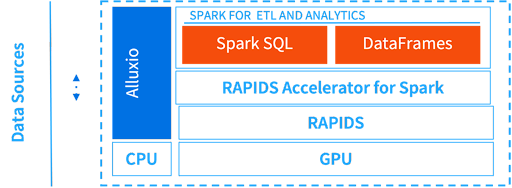
Furthur Ускорьте рабочий процесс с помощью Spark + GPU + Alluxio
Мы интегрируем Spark, RAPIDS и GPU с Alluxio, чтобы получить больше ускорения не только для автоматической маркировки данных, но и во многих других приложениях.
(Отказ от ответственности: автор является одним из основателей @Alluxio)
Оригинал