
Как я супер зарядил свой агент Langchain-Mysql: часть 2
4 июня 2025 г.Вставьте тряпичный слой в мой проект и мой опыт работы с курсором
TL; DR
Мой
Что нового в части 2:
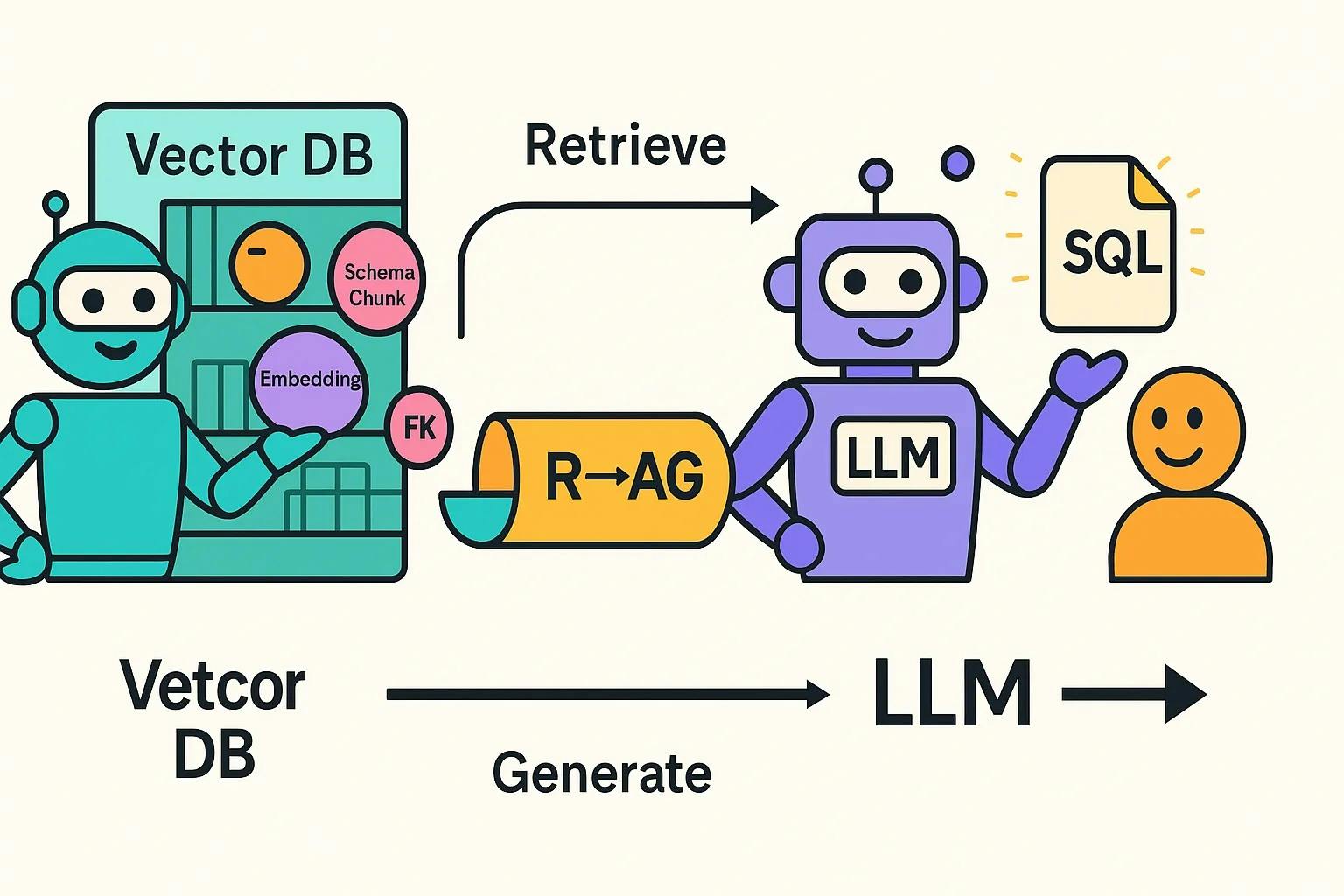
Постоянный векторный магазин FaissЗагружает только куски схемы, которые вам нужны - столбцы, ключи, индексы - поэтому побуждает к сокращению и задержке.
Комплексный тестовый набор- Устройство, интеграция и критерий Mock -DB, подключенные к CI - выводит схемы - поэксплу и извлечение кромков, прежде чем они достигнут производства.
LLM -резолюция по скорости - limit -Добавлены отношения иностранных ключей к вектору DB, что улучшает представление схемы и уменьшает использование токенов.
Прежде чем мы погрузимся, вот два шоу-шоу из части 1:
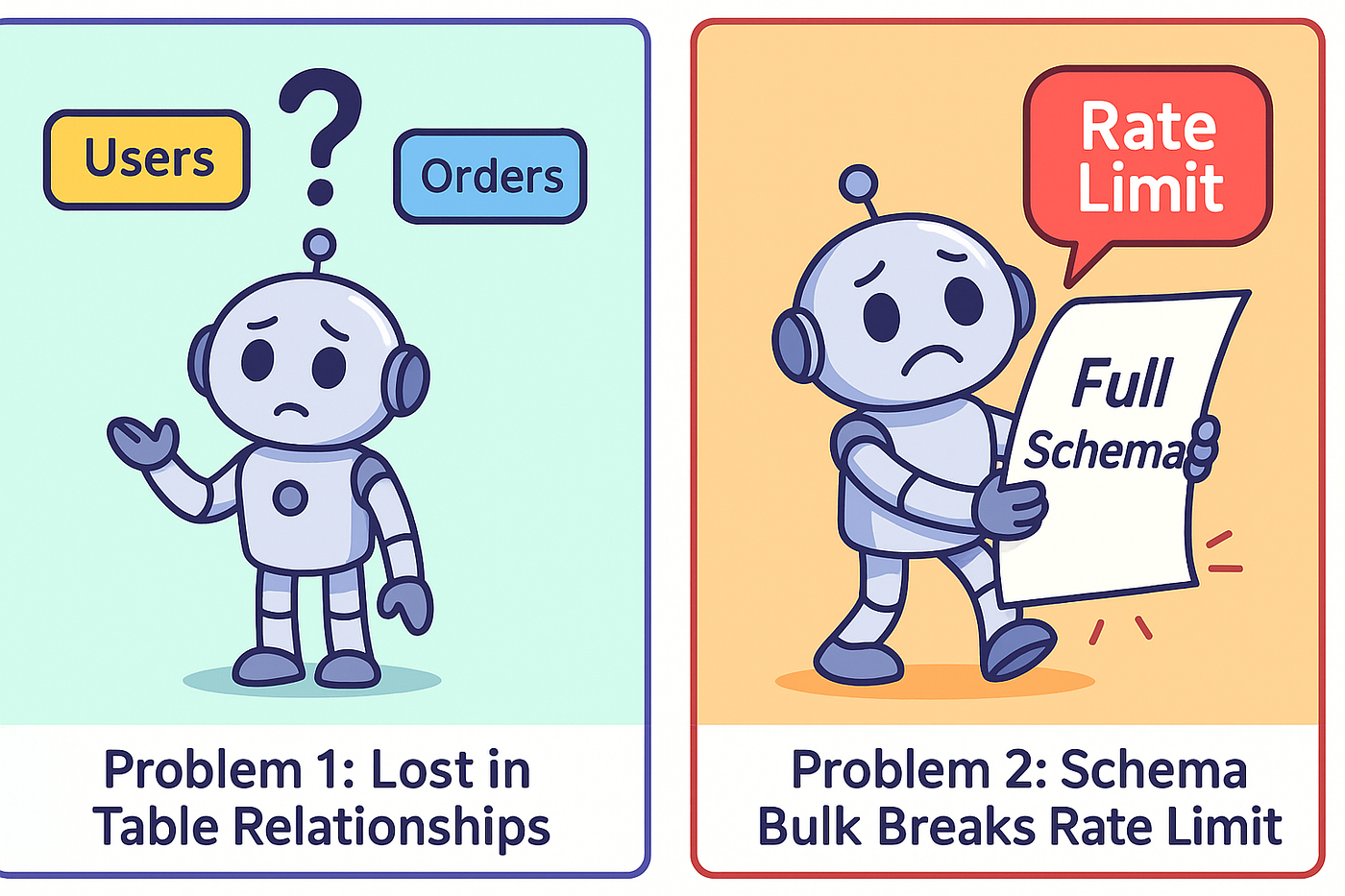
Проблема 1 - LLM, потерянный в табличных отношениях
LLM не знает, как соединяются ваши таблицы - вы в конечном итоге выписываете каждый путь соединения вручную в каждой подсказке.
Задача 2 - ограничения скорости схемы разрыва
Сбросьте полную схему базы данных в вашу подсказку, питает токены и почти всегда ездят на 429 ошибках Openai, прежде чем вы даже получите ответ.
Исследование и решения:
Что такое векторная база данных?
Авекторная база данныхэто специализированный хранилище данных, предназначенный для удержания и запросавекторные представления(массивы чисел) вместо традиционных рядов и столбцов.
Интеграция векторной базы данных
Все метаданные схемы базы данных-отношения DDL, PK/FK, информация об индексе, комментарии-втягиваются в богатые документы, затем внедряют и сохраняются в Faiss для молниеносного семантического поиска.
Почему Файс?
LLM предложил Faiss. КромеФайсс, Я также могу использоватьChroma, Qdrant, илиУкоренившись- Каждый поддерживает встраивание хранения и быстрого поиска и может соответствовать требованиям этого проекта.
Файсс(Facebook AI Searnity Search)-это библиотека с открытым исходным кодом, разработанную фундаментальной исследовательской группой Meta по эффективному поиску сходства и кластеризации плотных векторов.

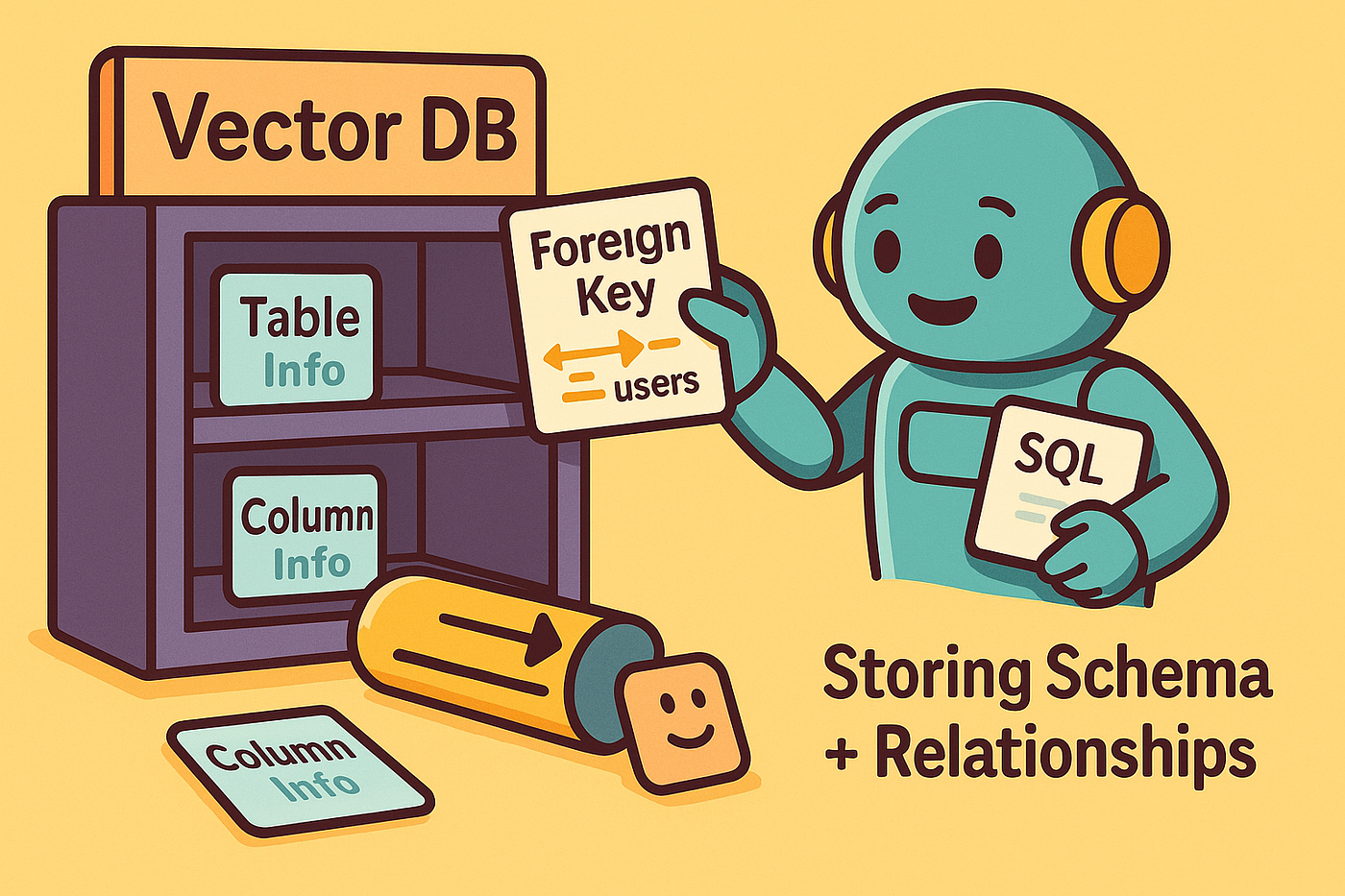
Что я храню: больше, чем просто план стола?
Важно отметить, что я не просто храню базовые схемы, такие как таблицы и названия столбцов в этой векторной базе данных. Я также явно собираю и хранят информацию о отношениях иностранных ключей, которые определяют, как эти таблицы соединяются.
Что такое тряпка?
Поигрывательный поколение (RAG)-это шаблон:
- Получение наиболее актуальных вторжений из векторного DB,
- Увеличение подсказки LLM с помощью этого извлеченного контекста,
- Генерируя окончательный ответ.
Другими словами, RAG зависит от вектора DB, чтобы получить только правильные биты знаний, прежде чем называть LLM.
Почему они имеют значение для приложений LLM?
LLMS может содержать только так много текста в одну подсказку. Vector DB + тряпка позволяет вам держать вашу «базу знаний» вне приглашения и привлекать только то, что нужно.
Думайте о LLM как студенте, который может вспомнить только несколько страниц за раз. Vector DB является каталогом библиотеки, а Rag является рабочим процессом получения точных страниц, необходимых до того, как студент напишет свое эссе.
Как Vector DB помогает с ограничением ставки API LLM?
Векторная база данных хранит вашу схему в качестве внедрения - какая -то таблица, столбец или отношения становятся доступным для поиска кусок. Когда пользователь задает вопрос (например, «Сколько пациентов посетили на прошлой неделе?»), Система превращает этот вопрос в внедрение и выполняет поиск сходства. Вместо того, чтобы вернуть полную схему, она получает толькоTop-K Самые актуальные таблицы-такой какpatientsВvisits, иappointmentsПолем
Этот сфокусированный контекст затем передается в LLM, поддерживая подсказки небольшие, в то же время предоставляя необходимую информацию, необходимую для создания точного SQL.
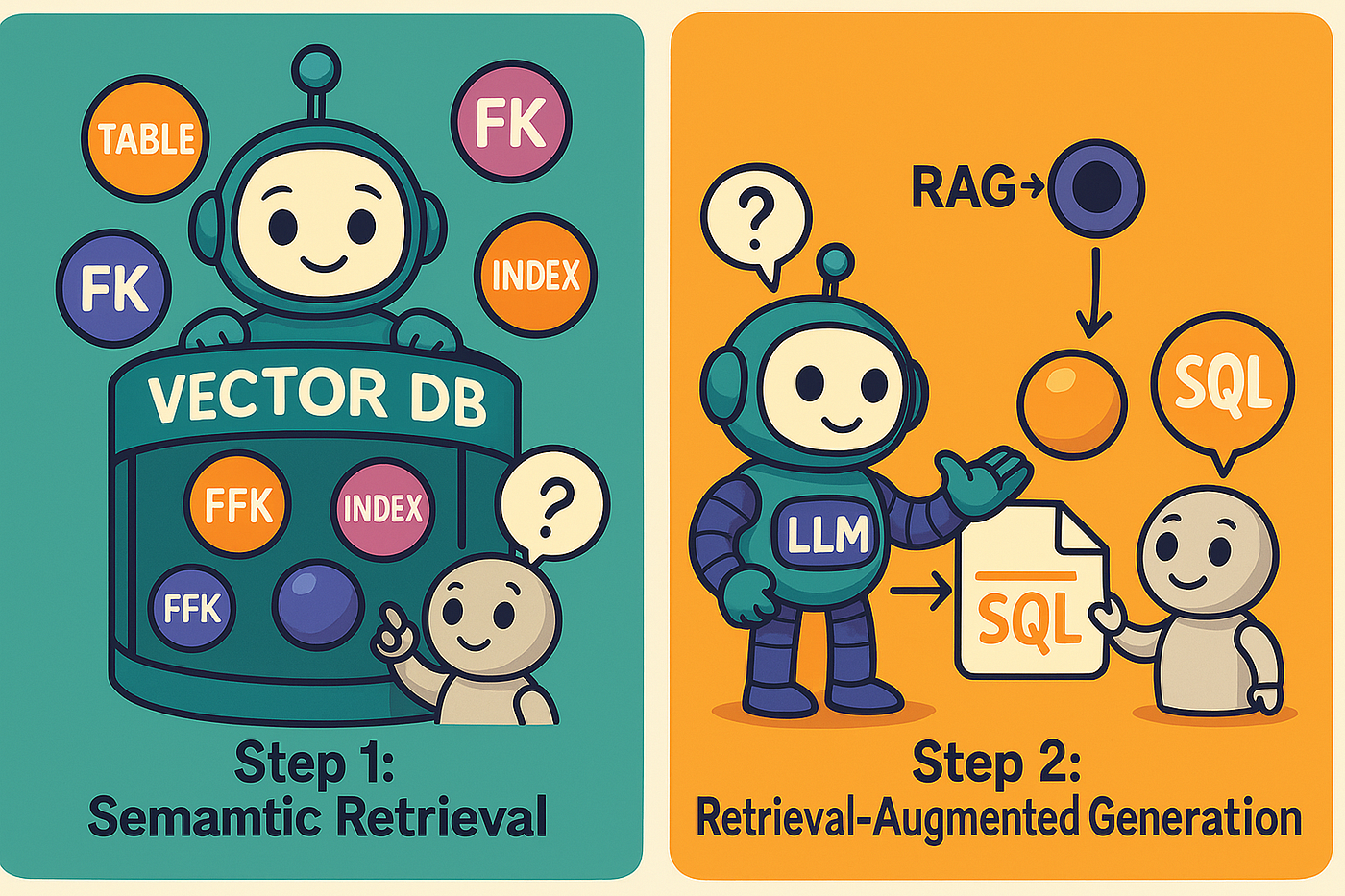
Поиссудистый поток генерации (шаги 4 и 5) для проекта
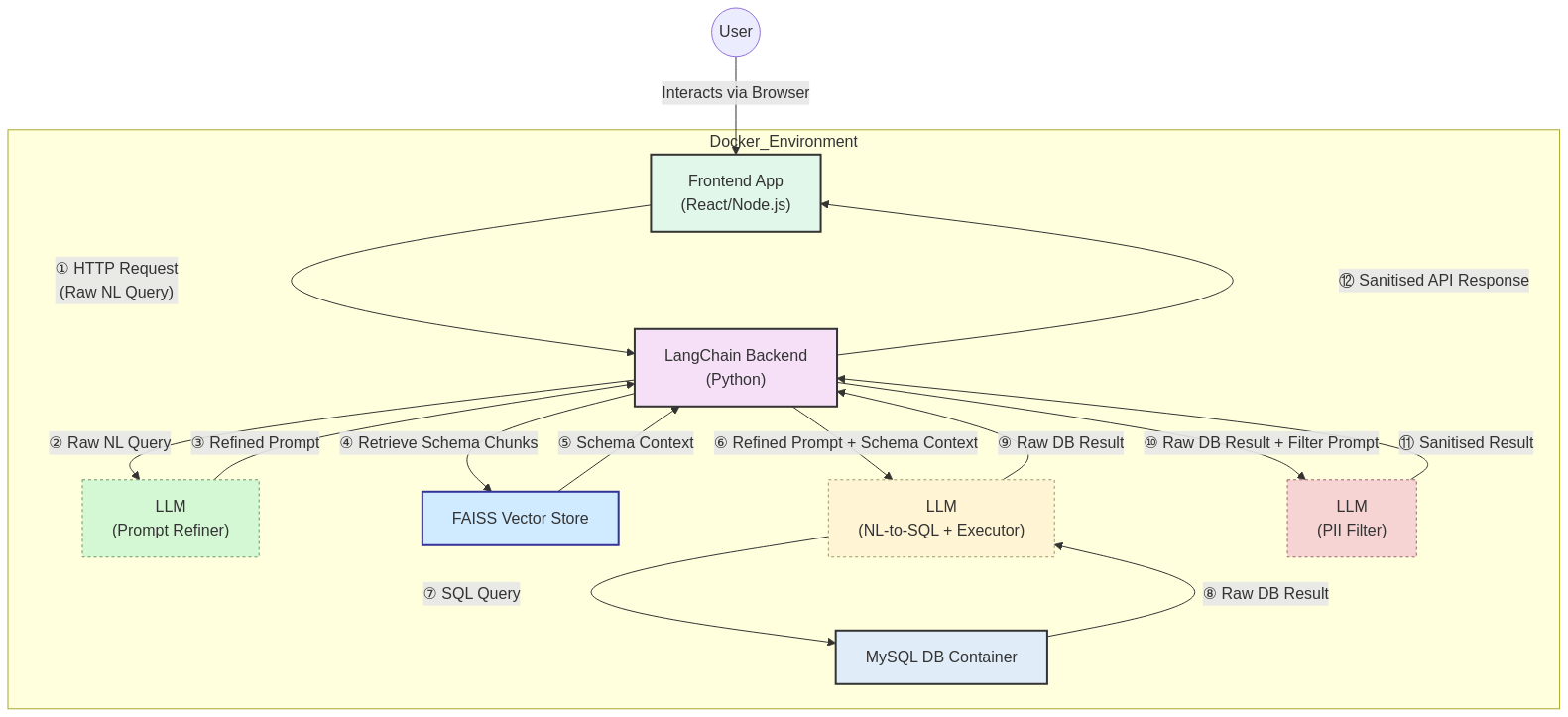
После реализации осведомленности об иностранном ключе в моей векторной базе данных две проблемы (указанные ранее) решаются должным образом.
Ссылка GitHub:нажимать
Демо
Я загружаю образцы базы данных -
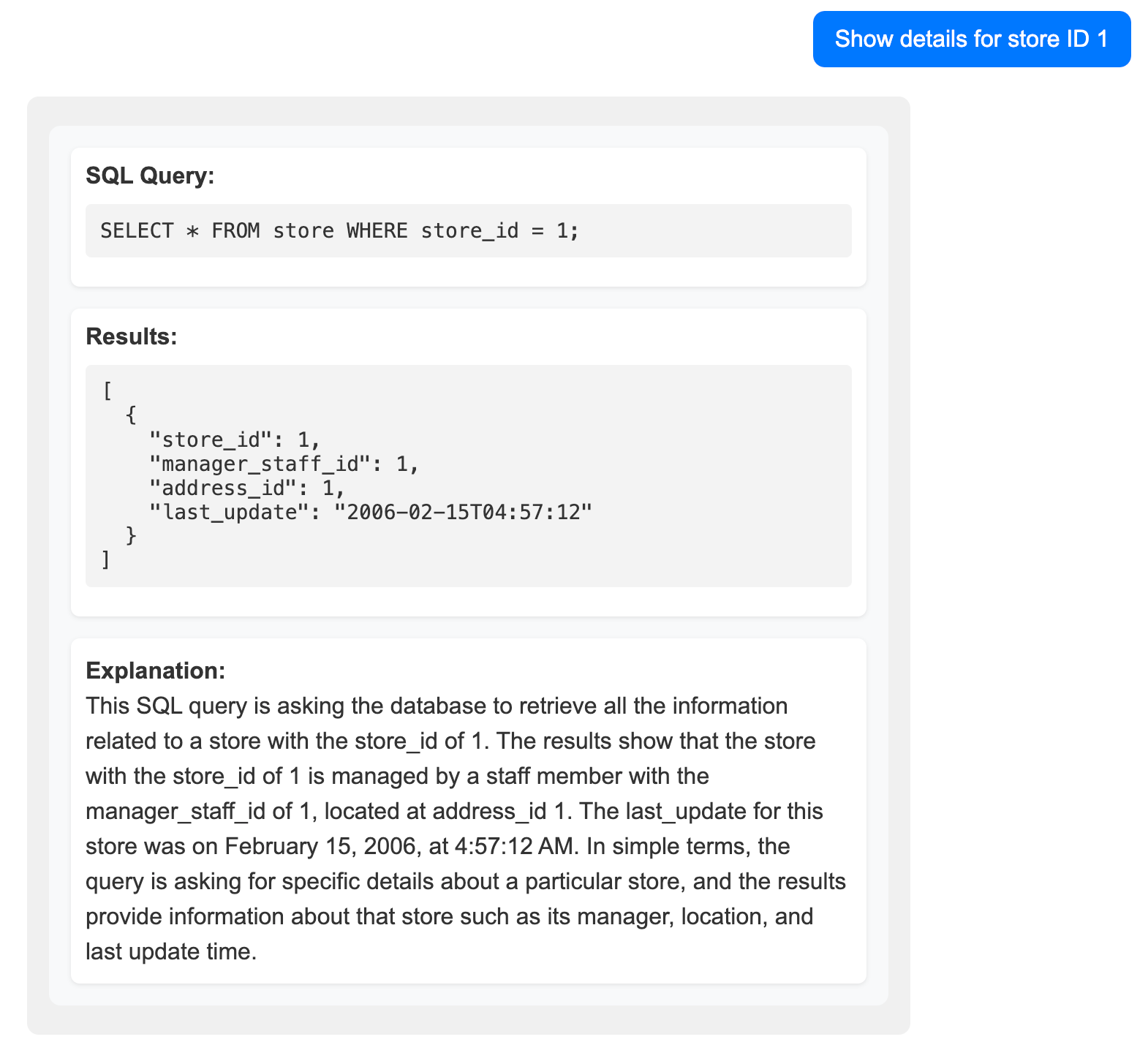
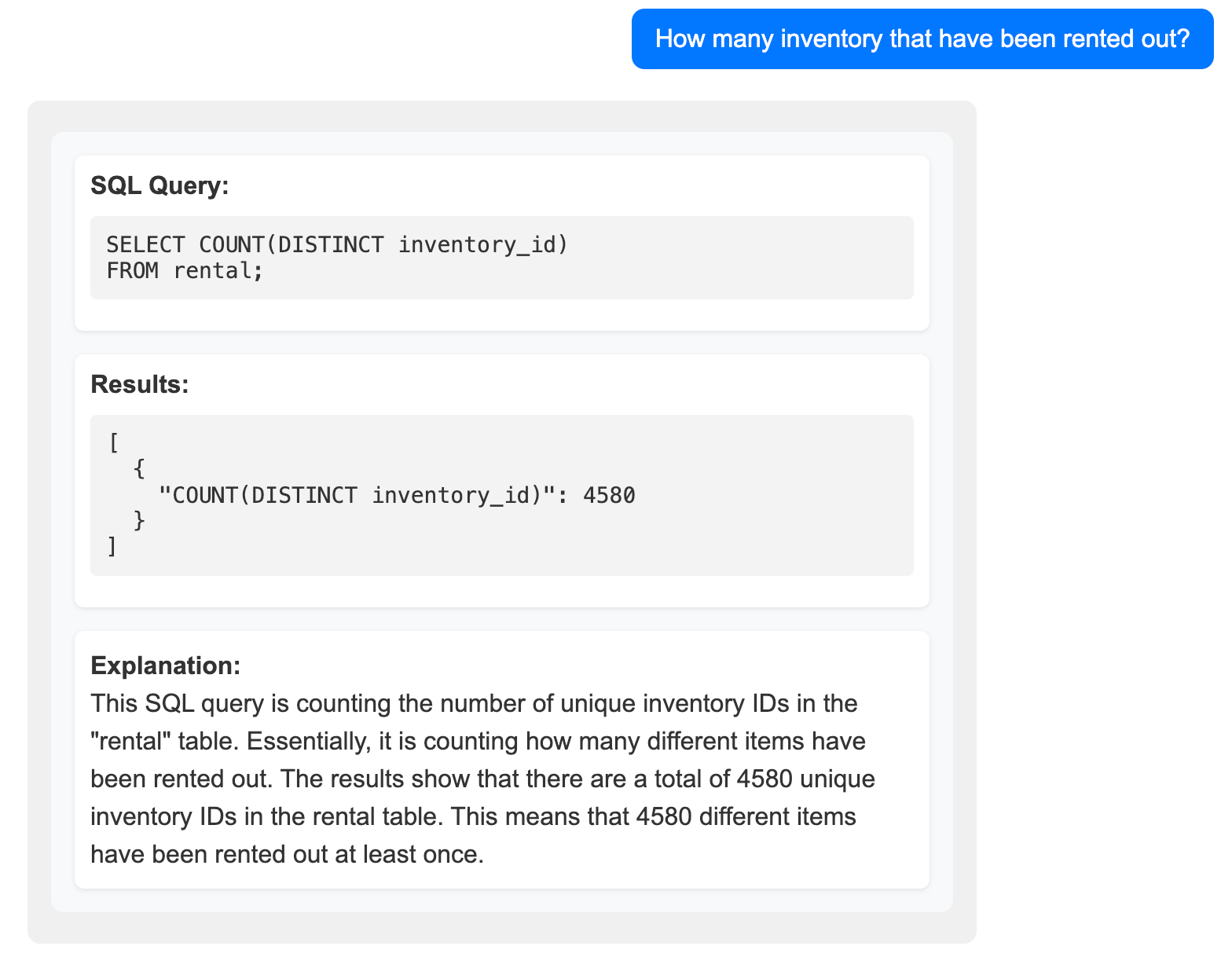
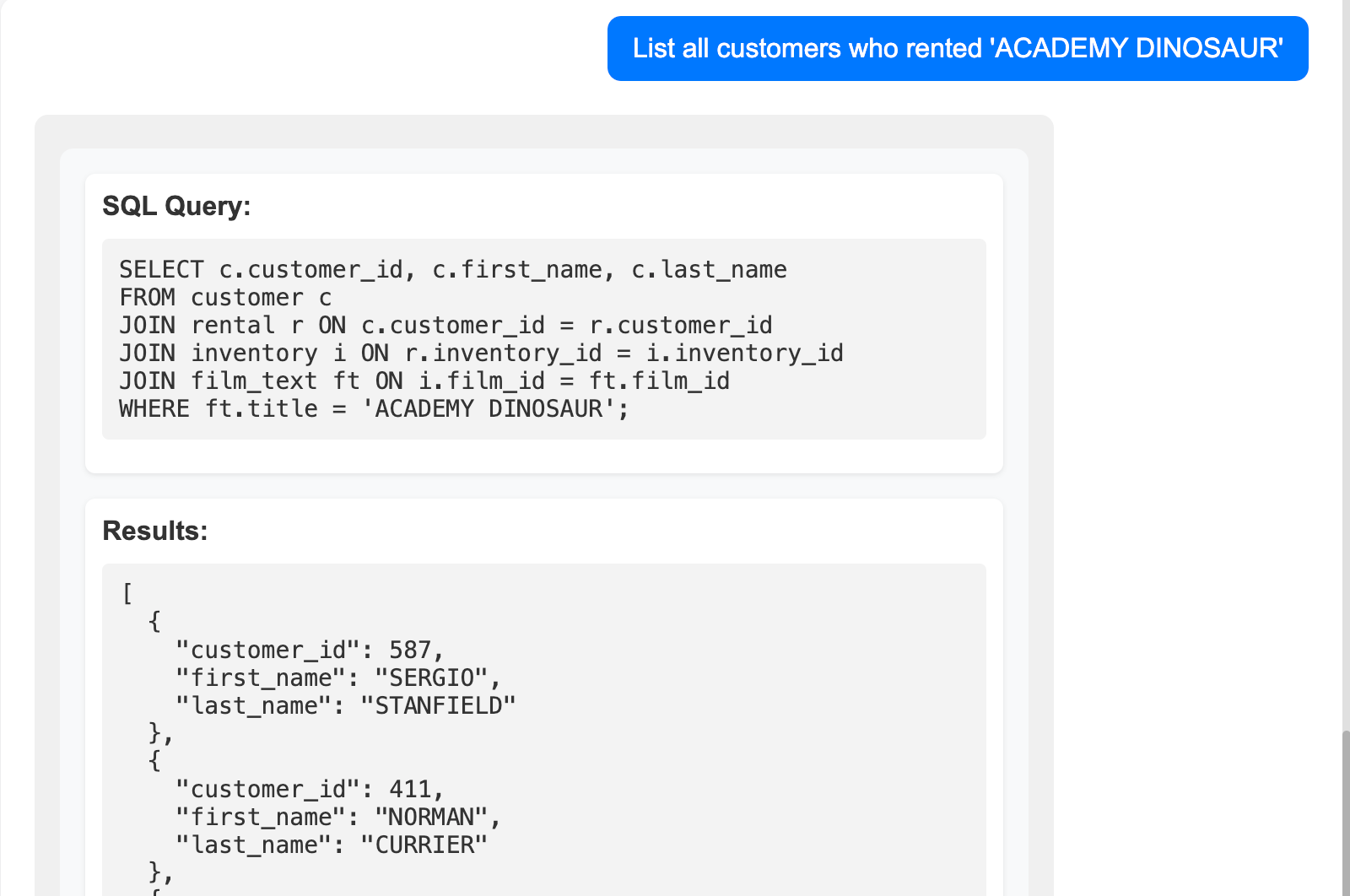
Каждый ответ включает в себя 3 части
- SQL запрос
- Результаты запроса
- Объяснение

Во второй половине этой статьи, как мне управлять моим ИИ -кодером (ов)?
Я управлял проектом, установив цели и задавая вопросы, LLM обрабатывал тяжелую работу. Он выделил проблемы, предлагаемые решения и объяснял компромиссы, в то время как я принял окончательные решения, по которым следует следовать.

Несколько советов для водителей:
Во -первых, подумайте как лидер:Вы менеджер, а не кодер. Установите четкие цели и приоритеты, затем позвольте LLM обрабатывать детали реализации.
Твердые тесты - ваша сеть безопасности - но с LLM, действующим в качестве программиста, вы получаете мгновенную обратную связь.Запустите тесты, попросите LLM отладить любые неудачи, и вы часто обнаружите, что он предлагает более чистые дизайны в середине запуска. Я потерял счет за то, сколько раз неудача вызвал лучшую идею архитектуры!
Избегайте микроуправления:Как человеческий менеджер, микроуправление наносит ущерб эффективности команды. Укажите, что должно произойти, но доверяйте LLM, чтобы решить, как. Чрезмерные подсказки могут привести к странным дизайну или скрытым ошибкам. Кроме того, это притягивает вас к деталям реализации и исчерпывает вас. Естественно, когда вы попадаете в эту ситуацию, было бы лучше писать код вручную.
Вмешиваться, когда это необходимо- Если LLM петля или дрейфует с пути, быстрое подталкивание или разъяснение - это все, что нужно, чтобы вернуться на курс. LLM не редко провести 20 минут, пытаясь исправить тест без успеха. Тем не менее, мне требуется только одна минута, чтобы найти первопричину. Наши команды роботов всегда нужны директора.
Не забывайте - каждый запрос LLM стоит денег. Будьте внимательны к этому, когда LLM находится в режиме самостоятельной внутрирогиции.
Мой LinkedInЗДЕСЬ
Оригинал