
Как тонкая настройка открытых моделей искусственного интеллекта может вновь ввести токсичность
10 июня 2025 г.Авторы:
(1) Уилл Хокинс, Оксфордский интернет -институт Оксфордского университета;
(2) Брент Миттельштадт, Оксфордский институт Интернета в Оксфордском университете;
(3) Крис Рассел, Оксфордский интернет -институт Оксфордского университета.
Таблица ссылок
- Аннотация и введение
- Связанная работа
- Эксперименты
- 3.1 Дизайн
- 3.2 Результаты
- 3.3 Сравнение 2: Настраиваемые и настройки
- 3.4 Сравнение 3: Настройка инструкции и настройки сообщества
- Дискуссия
- Ограничения и будущая работа
- Заключение, подтверждение и раскрытие финансирования и ссылки
А. Модели оцениваются
B. Данные и код
Neurips Paper Checklist
Абстрактный
Чико настраивающие языковые модели становятся все более популярными после пролиферации открытых моделей и улучшений в экономически эффективной точной настройке параметра. Тем не менее, тонкая настройка может влиять на свойства модели, такие как безопасность. Мы оцениваем, как тонкая настройка может повлиять на склонность разных моделей открытых моделей к выводу токсического содержания. Мы оцениваем воздействие моделей с тонкой настройкой Gemma, Llama и PHI на токсичность в течение трех экспериментов. Мы сравниваем, как токсичность снижается разработчиками моделей во время настройки обучения. Мы показываем, что небольшое количество параметров-эффективной тонкой настройки на моделях, настроенных разработчиком, посредством адаптации с низкой оценкой на наборе данных, не относящейся к поступлению, может значительно изменить эти результаты по моделям. Наконец, мы подчеркиваем влияние этого в дикой природе, демонстрируя, как частота токсичности моделей, настраиваемых участниками сообщества, может отклоняться от труднодоступных способов.
1 Введение
После прорыва трансформеров произошло ускорение в исследованиях и применениях крупных языковых моделей (LLMS) (Vaswani et al., 2017). Такие модели, как GPT-4, Claude 3 Opus и Gemini 1.5, появились в средах «с закрытым исходным кодом» для приложений, связанных с пользователем, включая CHATGPT, Claude и Gemini App (Anpropic, 2023; Gemini Team et al., 2024; Openai et al., 2024). Наряду с этим ростом появился еще одно явление: все более конкурентоспособные, часто меньшие, открытые генеративные модели, веса которых были доступны для загрузки онлайн. Эти открытые модели, как правило, менее способны при широком диапазоне задач по сравнению с конкурентами с замкнутым источником, но широко доступны с помощью платформ, таких как обнимающееся лицо, и достаточно компьютерный достаточный для локального работы, используя относительно небольшое количество ресурсов (обнимающееся лицо, 2024). Открытые модели имеют увеличенный доступ к языковым моделям для более широкой аудитории, настраиваемые разработчиками для создания индивидуальных систем (Taraghi et al., 2024). Основные разработчики ИИ приняли открытые модели разработчиков с Google (Gemma), Meta (Llama-3) и Microsoft (PHI-3), высвобождающие заметные открытые модели, указывающие на растущие инвестиции (Bilenko, 2024; Gemma Team et al., 2024; Meta, 2024).
Открытые модели имеют преимущество в обеспечении локальной точной настройки или настройки параметров модели для повышения производительности на указанных доменах или задачах. Это повысило популярность, чтобы улучшить производительность модели по указанным задачам, например, для улучшения многоязычных возможностей или адаптации опыта чат -бота. Тонкая настройка может быть предпринята на всех параметрах модели или на более мелких подмножествах модели с помощью методов с точной настройкой параметров (PEFT), таких как адаптация с низким уровнем ранга (LORA) (Hu et al., 2021). Методы PEFT обеспечивают более быструю, более дешевую точную настройку моделей, часто предпочтительнее разработчиков и пользователей моделей с ограниченными вычислительными бюджетами. Было показано, что Лора обеспечивает удивительно хорошую производительность по ряду задач обработки естественного языка, что приводит к ее широко распространенной популярности среди сообщества открытых моделей (Fu et al., 2022; Zeng & Lee, 2024).
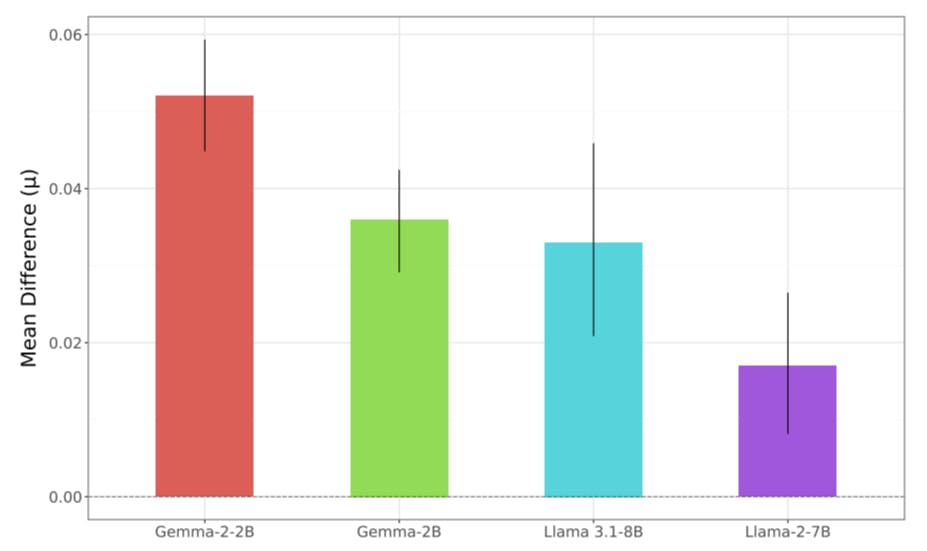
Хотя тонкая настройка может повысить производительность в целевых областях, она также может также неожиданно повлиять на другие модели поведения. Одним из таких свойств является безопасность модели, или склонность или способность модели выводить небезопасные ответы на запросы, включая такие проблемы, как создание кода для кибератак или создание инструкций по разработке злонамеренного оружия (Weidinger et al., 2021). Разработчики моделей часто описывают свои усилия по обеспечению развертывания безопасных моделей после освобождения, при этом безопасность и справедливость ссылаются в документации по выпуску для каждой из Gemma, Llama 3, PHI-3 и (Bilenko, 2024; Meta, 2024b; Microsoft, 2024). Тем не менее, предшествующая работа продемонстрировала, как на безопасность модели может повлиять точная настройка, даже если данные, используемые для точной настройки, не включают какие-либо данные, связанные с безопасностью (Lermen et al., 2023; Qi et al., 2023).
Эта работа способствует предыдущей литературе по анализу воздействия тонкой настройки путем демонстрации хрупкости смягчения токсичности в развернутых моделях открытого языка. В этой статье мы:
Измерить, как настройка инструкции снижает генерацию токсического языка с помощью моделей.
Отслеживайте, как эти смягчения непреднамеренно обращаются вспять посредством эффективной настройки параметров, используя не одноразовые наборы данных.
Продемонстрируйте влияние этого в реальном мире, показывая, как различные созданные сообществом варианты моделей могут отклоняться, казалось бы, непредсказуемым способами своей склонности к созданию токсического содержания.
Эта статья естьДоступно на ArxivПо лицензии CC 4.0.
Оригинал