
Насколько эффективна Lora Penetuning для больших языковых моделей?
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
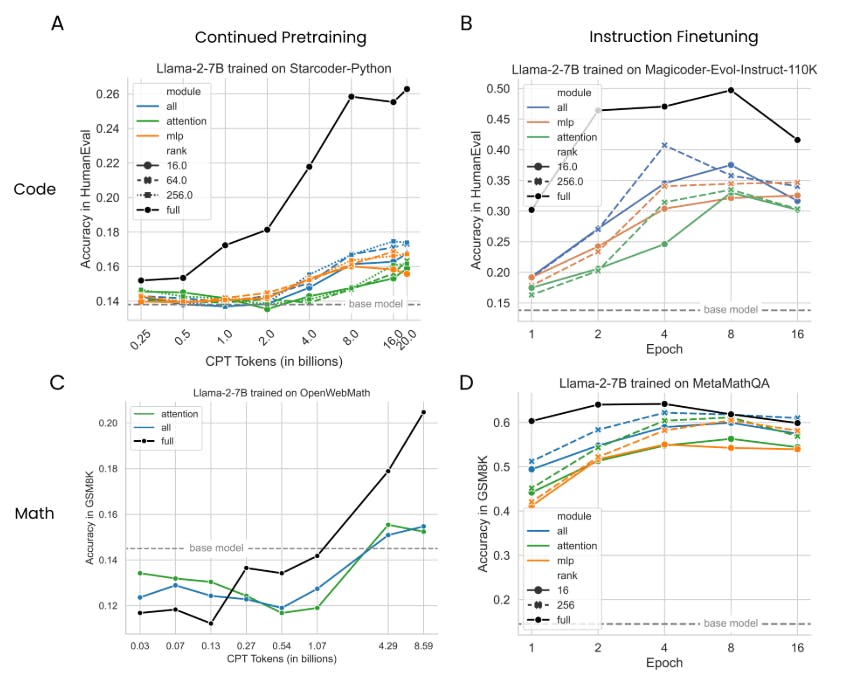
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
6 Обсуждение
Снижается ли разница между LORA и полным искусством, уменьшающейся с размером модели?Исследования в прошлом намекали на взаимосвязь между эффективностью создания и размера модели (Aghajananyan et al., 2020; Hu et al., 2021; Zhuo et al., 2024). В то время как недавние исследования успешно применили LORA к моделям параметров 70B (Ivison et al., 2023; Yu et al., 2023), мы оставляем строгое исследование этих интригующих свойств масштабирования для будущей работы.
Ограничения спектрального анализа.Наблюдение за тем, что полное создание, имеет тенденцию найти высокие рангические решения, не исключает возможности решений с низким уровнем ранга; Скорее, это показывает, что они обычно не найдены. Альтернативная интерпретация заключается в том, что ранг, необходимый для реконструкции матрицы веса, выше, чем ранг, необходимый для нижестоящей задачи.
Почему Лора хорошо выступает по математике, а не коду?Одна гипотеза заключается в том, что математические наборы данных включают меньший сдвиг домена; Они включают в себя больший процент английского языка и приводят к снижению забывания. Вторая гипотеза состоит в том, что оценка GSM8K слишком проста и не захватывает новую математику на уровне колледжа, изученную в области создания.
7 Заключение
Эта работа проливает свет на нисходящую производительность современных LLM (с параметрами 7 и 13 миллиардов), обученных с Лорой. В отличие от большинства предыдущих работ, мы используем специфичные для домена наборы данных в коде и математике, связанные с чувствительными показателями оценки. Мы показываем, что Лора снижает полную производительность в обеих областях. Мы также показываем, что Лора сохраняет поведение современной модели близко к поведению базовой модели, с уменьшенным забывающим доменом и более разнообразными поколениями во время вывода. Мы исследуем свойства регуляризации Лоры и показываем, что полная производительность обнаруживает, что возмущения веса далеки от низкого уровня. В заключение мы анализируем повышенную чувствительность Лоры к гиперпараметрам и подчеркивая передовые практики.
Ссылки
Армен Агаджаньян, Люк Зеттлемуер и Сонал Гупта. Внутренняя размерность объясняет эффективность точной настройки языка. Arxiv Preprint arxiv: 2012.13255, 2020.
Лубна Бен Аллал, Никлас Мюеннгофф, Логш Кумар Умапати, Бен Липкин и Леандро фон Верра. Структура для оценки моделей генерации кодов. https://github.com/bigcode-project/ bigcode-evaluation-harness, 2022.
Сахил Чаудхари. Код Alpaca: модель Llama, посвященная инструкции для генерации кода. https: // github. com/sahil280114/codealpaca, 2023.
Марк Чен, Джерри Творек, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Джаред Каплан, Харри Эдвардс, Юри Бурда, Николас Джозеф, Грег Брокман, Алекс Рэй, Рауль Пури, Гретхен Крюгер, Михаил Петров, Хейди Кхлафафуэра, Плайкин -Пайни -Сасейкин -Плайкин -Плайкин -Пайниль -Сас -Сас -Сас -Сас -Сас -Сас -Сасейк -Сас -Сас -Сас -Сасейк -Сасейк -Сасейк -Сасейк -Сасейк -Сас. Чан, Скотт Грей, Ник Райдер, Михаил Павлов, Алеа-Пауэр, Лукаш Кайзер, Мохаммад Баварарян, Клеменс Винтер, Филипп Тилле, Фелипе Петроски Такой, Дейв Каммингс, Матиас Плэпперт, Фотос Шанцис, Элизабет Барнс, Ариэль Херберт-В-Вон, Уильям, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алекс, Алексис, Алекс, Алекс, Алекс, Алекс. Николас Тезак, Цзе Танг, Игор Бабушкин, Сучир Баладжи, Шантану Джейн, Уильям Сондерс, Кристофер Хессе, Эндрю Н. Карр, Ян Лейк, Джош Ахиам, Ведант Миса, Эван Морикава, Алек Рэдфорд, Мэтью Кнет, Милс Брундаж, Мира Мурати, Кэт -Майер, Мейдер, Дар -Ама, Дар -Ама, Дар -Ама, Дар -Ам, Дар -Ам. МакКандлиш, Илья Саускевер и Войцех Заремба. Оценка крупных языковых моделей, обученных коду, 2021.
Хёнг Вон Чунг, Ле Хоу, Шейн Лонгпри, Баррет Зоф, Йи Тэй, Уильям Федус, Юнксуан Ли, Сюэжи Ван, Мостафа Дехгани, Сиддхартха Брахма и др. Масштабирование моделей с помощью инструкций. Журнал исследований машинного обучения, 25 (70): 1–53, 2024.
Питер Кларк, Исаак Коухи, Орен Эциони, Тушар Хот, Ашиш Сабхарвал, Карисса Шоеник и Ойвинд Тафьорд. Думаете, вы решили ответ на вопрос? Попробуйте ARC, AI2 -рассуждение. Arxiv, abs/1803.05457, 2018.
Карл Кобб, Винеет Косараджу, Мохаммад Баварский, Марк Чен, Хивоо Джун, Лукаш Кайзер, Матиас Плапперт, Джерри Творек, Джейкоб Хилтон, Рейхиро Накано, et al. Обучение проверки для решения проблем по математике. Arxiv Preprint arxiv: 2110.14168, 2021.
Тим Деттмерс, Артидоро Пагнони, Ари Хольцман и Люк Зеттлемойер. Qlora: Эффективное создание квантовых LLMS. Достижения в системах обработки нейронной информации, 36, 2024.
Yuqing Du, Alexander Havrilla, Sainbayar Sukhbaatar, Pieter Abbeel и Roberta Raileanu. Исследование по улучшению рассуждений в языковых моделях. В я не могу поверить, что это не лучший семинар: режимы неудачи в эпоху моделей фундамента, 2024. URL https://openreview.net/forum?id=tczfmdypfm.
Янн Дюбуа, Чен Сюхен Ли, Рохан Таори, Тиани Чжан, Ишаан Гулраджани, Джимми Ба, Карлос Гестрин, Перси С. Лян и Тацунори Б Хасимото. Alpacafarm: моделировая структура для методов, которые учатся от обратной связи человека. Достижения в системах обработки нейронной информации, 36, 2024.
Лео Гао, Джонатан Тау, Бабер Аббаси, Стелла Бидерман, Сид Блэк, Энтони Дипофи, Чарльз Фостер, Лоуренс Голдинг, Джеффри Хсу, Ален Ле Ноак, Хаонан Ли, Кайл Макдонелл, Никлас Мененг, Крис Окьепа, Джасон Фан, Лариа Рейнельс, Хайлея, Хайлея, Хайлея, Хайлея. Skowron, Lintang Sutawika, Эрик Тан, Аниш Тит, Бен Ван, Кевин Ван и Энди Зу. Структура для оценки модели с несколькими выстрелами, 12 2023. URL https://zenodo.org/records/10256836.
Богдан Глива, Ивона Мочол, Макия Бизек и Александр Вауэр. Samsum Corpus: набор данных диалога, аннулированный человеком для абстрактной суммирования. Arxiv Preprint arxiv: 1911.12237, 2019.
Ян Гудфелло, Йошуа Бенгио и Аарон Курвилл. Глубокое обучение. MIT Press, 2016.
Дэн Хендриккс, Коллин Бернс, Стивен Басарт, Энди Зу, Мантас Мазейка, песня рассвета и Джейкоб Стейнхардт. Измерение массового многозадачного понимания языка. Arxiv Preprint arxiv: 2009.03300, 2020.
Дэн Хендриккс, Коллин Бернс, Саурав Кадават, Акул Арора, Стивен Басарт, Эрик Танг, Рассвет Сонг и Джейкоб Стейнхардт. Измерение математических задач с помощью набора данных по математике. Arxiv Preprint arxiv: 2103.03874, 2021.
Эдвард Дж. Ху, Йелонг Шен, Филипп Уоллис, Зейуан Аллен-зху, Юаньжи Ли, Шин Ван, Лу Ван и Вейху Чен. LORA: Низкая адаптация крупных языковых моделей. Arxiv Preprint arxiv: 2106.09685, 2021.
Хэмиш Ивисон, Йижонг Ван, Валентина Пьяткин, Натан Ламберт, Мэтью Питерс, Прадип Дасиги, Джоэл Джанг, Дэвид Вадден, Ной А. Смит, Из Белтаги и др. Верблюды в изменяющемся климате: усиление адаптации LM с Tulu 2. Arxiv Preprint arxiv: 2311.10702, 2023.
Вейзен Цзян, Хан Ши, Лонгюй Ю, Чжэнгинг Лю, Ю Чжан, Чжэнгуо Ли и Джеймс Т. Квок. Правообогающие рассуждения в больших языковых моделях для математической проверки, 2024.
Давид Ян Копичко, Тиджмен Бланкеворт и Юки Маркус Асано. Вера: векторная адаптация случайной матрицы. Arxiv Preprint arxiv: 2310.11454, 2023.
Тимот -Лесорт, Винченцо Ломонако, Андрей Стоан, Давиде Малтони, Дэвид Филлиат и Наталья Диазродригес. Непрерывное обучение для робототехники: определение, структура, стратегии обучения, возможности и проблемы. Информация Fusion, 58: 52–68, 2020.
Тимот -Лесорт, Олексий Остапенко, Диганта Мисра, доктор медицинских наук, Рифат Арефин, Пау Родригес, Лорат Чарлин и Ирина Риш. Опыт общих предположений о катастрофическом забывании. Arxiv Preprint arxiv: 2207.04543, 2022.
Чунюань Ли, Херад Фархур, Розанна Лю и Джейсон Йосински. Измерение внутреннего измерения объективных ландшафтов. Arxiv Preprint arxiv: 1804.08838, 2018.
Рэймонд Ли, Лубна Бен Аллал, Янтиан Зи, Никлас Менененгофф, Денис Кочеетков, Ченгао Моу, Марк Марон, Кристофер Акики, Цзя Ли, Дженни Чим и др. StarCoder: Да пребудет с вами источник! Arxiv Preprint arxiv: 2305.06161, 2023.
Ши-Ян Лю, Чиен-Йи Ван, Хонгсу Инь, Павло Мольчанов, Ю-Чианг Фрэнк Ванг, Кван-Тин Ченг и Мин-Хен Чен. Дора: сбоя в веса, адаптация с низким уровнем ранга. Arxiv Preprint arxiv: 2402.09353, 2024.
Иньхан Лю, Майл Отт, Наман Гоял, Цзингфей Дю, Мандар Джоши, Данки Чен, Омер Леви, Майк Льюис, Люк Зеттлемуер и Веселин Стоянов. Роберта: надежно оптимизированный берт -предварительный подход. Arxiv Preprint arxiv: 1907.11692, 2019.
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin и Daxin Jiang. WizardCoder: расширение возможностей кода большие языковые модели с помощью Evol-Instruct. Arxiv Preprint arxiv: 2306.08568, 2023.
Джекатерина Новикова, Онддж Душек и Верена Ризер. Набор данных E2E: новые проблемы для сквозного поколения. Arxiv Preprint arxiv: 1706.09254, 2017.
Кейран Пастер, Марко Дос Сантос, Чжангир Азербаев и Джимми Ба. OpenWebmath: открытый набор данных высококачественного математического веб-текста. Arxiv Preprint arxiv: 2310.06786, 2023.
Самьям Раджбандари, Джефф Расли, Олатунджи Рувас и Yuxiong He. Ноль: оптимизация памяти для обучения моделей параметров триллиона. В SC20: Международная конференция для высокопроизводительных вычислений, сети, хранения и анализа, с. 1–16. IEEE, 2020.
Праджит Рамачандран, Баррет Зоф и Quoc v le. Поиск функций активации. Arxiv Preprint arxiv: 1710.05941, 2017.
Себастьян Рашка. Практические советы для создания LLM с использованием LORA (адаптация с низким рейтингом), 2023. URL https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms# %c2 %a7enable-lora-more-layers.
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Soootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jéremy Rapin, et al. Код Llama: Open Foundation Models для кода. Arxiv Preprint arxiv: 2308.12950, 2023.
Кейсуке Сакагучи, Ронан Ле Брас, Чандра Бхагаватула и Йецзин Чой. Winogrande: состязательная схема Winograd Schema в масштабе, 2019.
Томас Сцилом, Тухин Чакрабарти и Смаранда Мюресан. Тонко настроенные языковые модели являются постоянными учащимися. Arxiv Preprint arxiv: 2205.12393, 2022.
Ноам Шейзер. Варианты Glu улучшают трансформатор. Arxiv Preprint arxiv: 2002.05202, 2020.
Инг Шенг, Шии Цао, Дахенг Ли, Коулман Хупер, Николас Ли, Шуо Ян, Кристофер Чоу, Бангуа Чжу, Лианмин Чжэн, Курт Кейцер, Джозеф Э. Гонсалес и Ион Стоика. S-LORA: обслуживание тысяч параллельных адаптеров LORA, 2023.
Ричард Сочер, Алекс Пелигин, Жан Ву, Джейсон Чуанг, Кристофер Д. Мэннинг, Эндрю и Кристофер Поттс. Рекурсивные глубокие модели для семантической композиции по поверхности деревьев. В материалах конференции 2013 года по эмпирическим методам в обработке естественного языка, стр. 1631–1642, 2013.
Нитиш Шривастава, Джеффри Хинтон, Алекс Крижевский, Илья Сатскевер и Руслан Салахутдинов. Выбрось: простой способ предотвратить переживание нейронных сетей. Журнал исследований машинного обучения, 15 (1): 1929–1958, 2014.
Fan-Keng Sun, Cheng-Hao Ho и Hung-Yi Lee. Ламол: Языковое моделирование для изучения языка на протяжении всей жизни. Arxiv Preprint arxiv: 1909.03329, 2019.
Симэн Сан, Дхавал Гупта и Мохит Ийер. Изучение влияния адаптации с низким уровнем ранга на производительность, эффективность и регуляризацию RLHF, 2023.
Рохан Таори, Ишаан Гулраджани, Тиани Чжан, Янн Дюбуа, Сюэхен Ли, Карлос Гестрин, Перси Лян и Тацунори Б Хасимото. Стэнфордская Альпака: модель Llama, посвященная инструкциям, 2023.
Хьюго Тувров, Луи Мартин, Кевин Стоун, Питер Альберт, Амджад Альмахайри, Ясмин Бабей, Николай Башликов, Суйя Батра, Праджвал Бхаргава, Шрайли Бхосале и др. Llama 2: Open Foundation и тонкие модели чата. Arxiv Preprint arxiv: 2307.09288, 2023.
Алекс Ван, Аманприт Сингх, Джулиан Майкл, Феликс Хилл, Омер Леви и Сэмюэл Р. Боуман. Клей: многозадачный эталон и платформа анализа для понимания естественного языка. Arxiv Preprint arxiv: 1804.07461, 2018.
Лиюань Ван, Синсинг Чжан, Ханг Су и Джун Чжу. Комплексный обзор постоянного обучения: теория, метод и применение, 2024.
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding и Lingming Zhang. Magicoder: исходный код - это все, что вам нужно. Arxiv Preprint arxiv: 2312.02120, 2023.
Иксуань Венг, Минджун Чжу, Фей Ся, бин Ли, Шучжу Х. Х., Шенпинг Лю, бин Сан, Кан Лю и Джун Чжао. Большие языковые модели являются лучшими рассуждениями с самостоятельностью. Arxiv Preprint arxiv: 2212.09561, 2022.
Адина Уильямс, Никита Нанья и Сэмюэль Р. Боуман. Корпус вызова широкого покрытия для понимания предложения посредством вывода. Arxiv Preprint arxiv: 1704.05426, 2017.
Венхан Ся, Ченгвей Цинь и Элад Хазан. Цепочка LORA: эффективная тонкая настройка языковых моделей с помощью остаточного обучения. Arxiv Preprint arxiv: 2401.04151, 2024.
Лонгюй Ю, Вейзен Цзян, Хан Ши, Джинчэн Ю, Чжэнгинг Лю, Ю Чжан, Джеймс Т Квок, Чжэнгуо Ли, Адриан Веллер и Вейян Лю. Метамат: Началуйте ваши собственные математические вопросы для больших языковых моделей. Arxiv Preprint arxiv: 2309.12284, 2023.
Роуэн Зеллерс, Ари Хольцман, Йонатан Биск, Али Фархади и Еджин Чой. Hellaswag: Может ли машина действительно закончить ваше предложение?, 2019.
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar и Yuandong Tian. В изобилии: эффективная память LLM обучение с помощью градиентной проекции с низким уровнем ранга. Arxiv Preprint arxiv: 2403.03507, 2024a.
Джастин Чжао, Тимоти Ван, Ваэль Абид, Джеффри Ангус, Арнав Гарг, Джеффри Киннисон, Алекс Шерстинский, Пьеро Молино, Трэвис Аддайр и ДевВрет Риши. LORA LAND: 310 тонко настроенных LLM, которые конкурируют с GPT-4, технический отчет. Arxiv Preprint arxiv: 2405.00732, 2024b.
Виктор Чжун, Кайминг Сионг и Ричард Сохер. SEQ2SQL: генерирование структурированных запросов из естественного языка с использованием обучения подкрепления. Arxiv Preprint arxiv: 1709.00103, 2017.
Терри Юэ Чжуо, Армель Зебазе, Ничакарн Супаттарачай, Леандро фон Верра, Харм де Врис, Цянь Лю и Никлас Мененгофф. Astraios: Параметр-экономичный код настройки инструкций большие языковые модели. Arxiv Preprint arxiv: 2401.00788, 2024.
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал