
Как разнообразие наборов данных влияет на производительность модели искусственного интеллекта
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
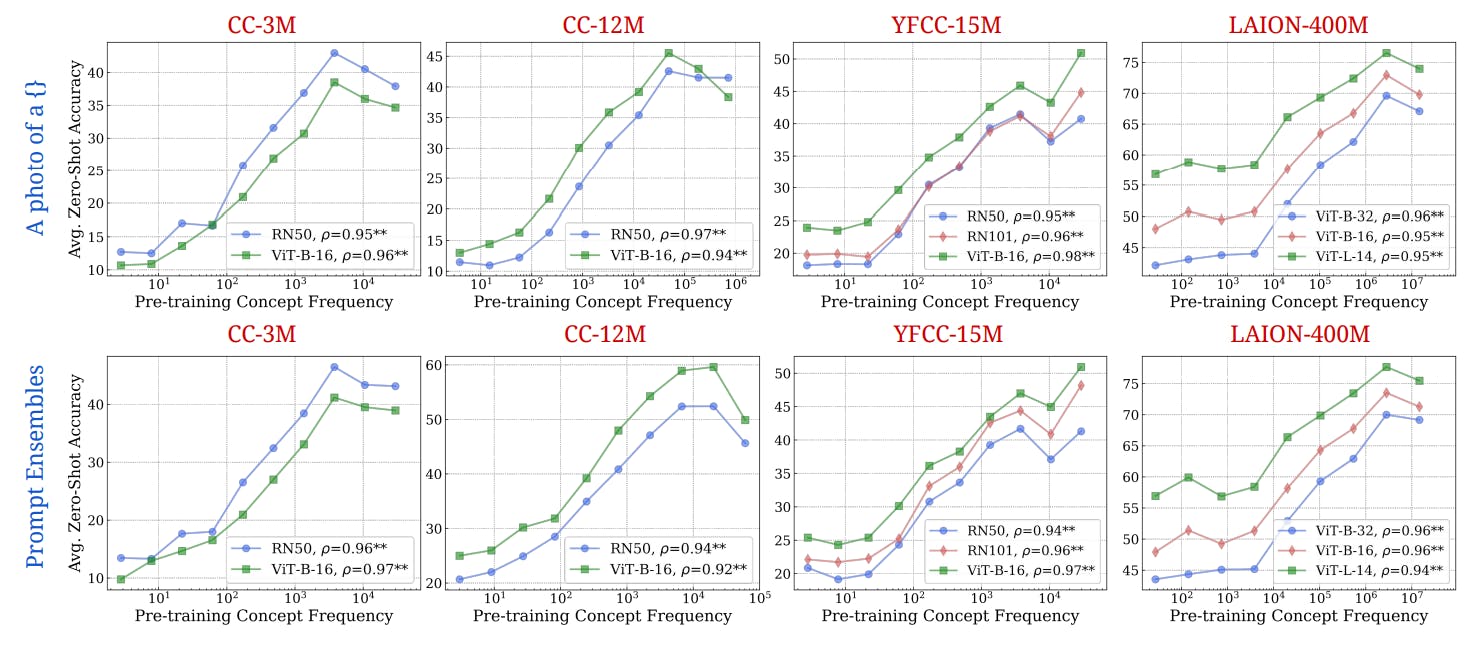
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
7 Связанная работа
Влияние данных предварительного обучения на данные нижестоящих.Несколько предыдущих работ, ориентированных на данные [91, 46, 82, 42, 83, 74, 124, 125, 135, 109, 78, 92, 99, 100, 38, 26, 95], подчеркнули важность предварительных данных в влиянии на производительность. Fang et al. [42] надежно продемонстрировал, что разнообразие данных предварительно подготовленного является ключевым свойством, лежащим в основе сильного поведения об обобщании, обобщающемся в результате распределения. Точно так же Berlot-Attell et al. [16] показали, что разнообразие атрибутов имеет решающее значение для обобщения композиции [60], а именно систематичности [45]. Nguyen et al. [82] расширил Fang et al. [42] Анализ, чтобы показать, что различия в распределении данных могут предсказуемо изменить производительность модели, и что это поведение может привести к эффективным стратегиям смешивания данных в предварительное время. Mayilvahanan et al. [79] дополнили это направление исследования, показав, что производительность клипа коррелирует с сходством между наборами данных обучения и тестирования. Udandarao et al. [118] далее показали, что частота определенных визуальных типов данных в наборе данных LAION-2B была примерно коррелирована с производительностью моделей клипов при определении визуальных типов данных. Наши результаты также определяют, что частота возникновения концепции является ключевым показателем производительности. Это дополняет существующие исследования в конкретных областях, таких как вопросы, отвечающие вопросам [62], и числовые рассуждения [94] в моделях крупных языков, где сходство с высоким тестированием на поезде не в полной мере объясняет наблюдаемые уровни производительности [127]. Одновременно с нашей работой, Parashar et al. [86] также исследуют проблему длинных концепций в наборе данных LAION-2B и о том, как она влияет на производительность моделей клипов, поддерживая наши выводы. В отличие от их работы, мы смотрим на счет отдельно в методах изображения и текста, а также на разных наборах и проводим ряд контрольных экспериментов, чтобы тщательно проверить надежность нашего результата. Наконец, наша демонстрация того, что длинный хвост дает логарифмическую тенденцию явно указывает на экспоненциальную неэффективность образца в крупномасштабных предварительно проведенных моделях.
Анализ ориентированного на данные.Наша работа также добавляет к множеству работы, которая направлена на понимание и изучение композиции крупномасштабных наборов данных и использует данные в качестве среды для улучшения нижестоящих задач. Предыдущая работа отмечала важность данных для улучшения производительности модели на обобщенном наборе задач [46, 11, 40, 13, 106]. Например, в нескольких работах используются полученные и синтетические данные для адаптации моделей фундамента на широком наборе нижестоящих задач [119, 54, 115, 21, 101, 134, 90]. Maini et al. [76] наблюдали существование «текстовых» кластеров в LAION-2B и измерили его влияние на производительность нисходящего. Другая работа направлена на то, чтобы нацелиться на проблему смещения, которую мы количественно определили в TAB. 3 путем явного повторяния предварительных наборов данных [68, 28, 120, 131, 83, 17]. Кроме того, исследования также показали, что с помощью лучших стратегий обрезки данных законы о нейронном масштабировании могут быть более эффективными, чем власть [109, 10]. Предыдущая работа также продемонстрировала, что крупномасштабные наборы данных страдают от чрезвычайной избыточности в концепциях и высокой степени токсичного и предвзятого содержания [39, 116]. Дальнейшие исследования продемонстрировали последующие эффекты, которые такие предубеждения во время предварительной подготовки вызывают в современных моделях [19, 104, 18, 47]. Наша работа решает проблему длинных концепций в предварительных наборах данных и показывает, что это важное направление исследования, на котором сосредоточено усилия.
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал