

Как Datadog выявил скрытые проблемы с производительностью AWS
4 ноября 2022 г.В Lob мы в настоящее время используем Convox в качестве нашей платформы развертывания — «создайте свою собственную платформу как услугу», которую вы можете установить для управления контейнерами в ECS (Elastic Container Service) AWS.
Convox стареет, и в этом году мы начали процесс замены Convox на Nomad от HashiCorp, гибкий оркестратор рабочих нагрузок для развертывания и управления нашими контейнеры на AWS.
Когда мы готовились к переходу на Nomad, больше всего нас беспокоила производительность. Мы начали наши тесты с базовой проверки концепции нашего API в Nomad. Мы протестировали и сравнили две системы и обнаружили, что Nomad работает медленнее.
Это было крайне неожиданно, так как Convox (который использует AWS Elastic Container Services) и Nomad используют контейнеры Docker под прикрытием. Мы предполагали, что переход от старой технологии к новой приведет к некоторому повышению производительности.
Почему наша производительность страдает?
Из-за урезанного кластера Nomad мы изначально не настроили агент Datadog для сбора трассировок и профилей приложений.
Наше первоначальное тестирование производительности показало, что каждый запрос выполнялся плохо с четырехсекундной задержкой независимо от нагрузки, что было неожиданно. Что еще более странно, запуск нагрузочного теста показал, что производительность улучшилась и со временем будет то повышаться, то падать.
Внутри мы обсуждали, была ли причиной плохая производительность базы данных. Однако с помощью проверенного временем процесса удаления кода и наблюдения за результатами мы обнаружили, что четырехсекундная задержка возникает при запросах на сохранение в нашу корзину AWS S3.
Чтобы определить, была ли проблема в нашем коде или инфраструктуре, нам нужно было изолировать подозрительный код и настроить Datadog для эффективного отслеживания взаимодействия между нашим приложением и инфраструктурой.
Мы сделали это, извлекая метод загрузки S3 из нашей рабочей кодовой базы, чтобы устранить шум в нашей трассировке, настроив библиотеку трассировки Datadog APM для этого кода и включив агент Datadog в нашем кластере Nomad.

Мы обнаружили 4 последовательных вызова с восклицательными знаками в Datadog. Почему загрузка S3 может вызвать 4 HTTP-запроса PUT? И почему каждый запрос завершался ошибкой ровно через 1 секунду?
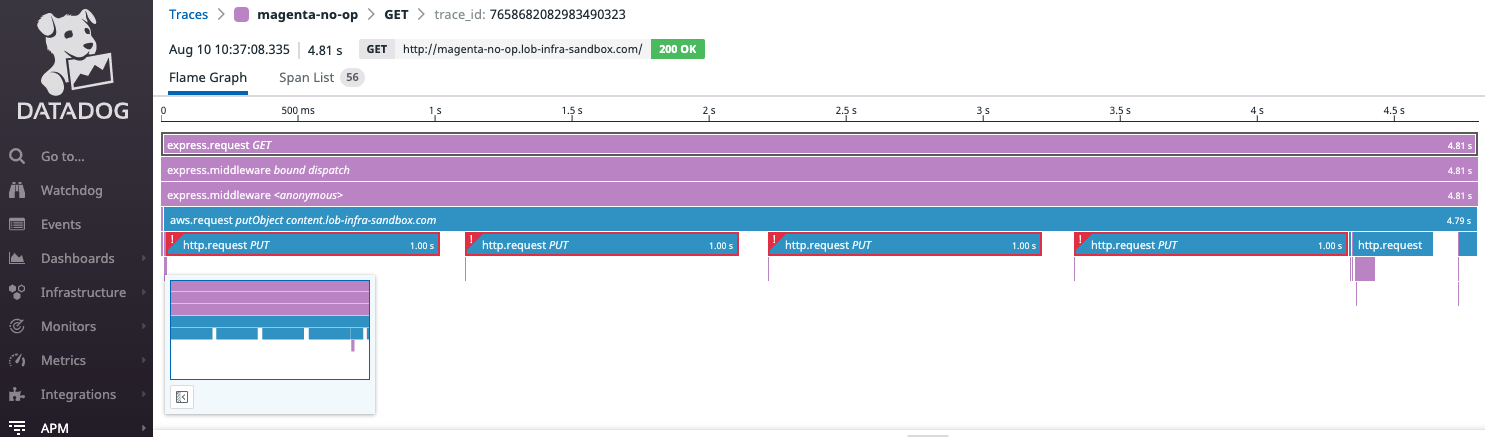
Присмотревшись, мы обнаружили зависание сокета и вызываемый IP-адрес.
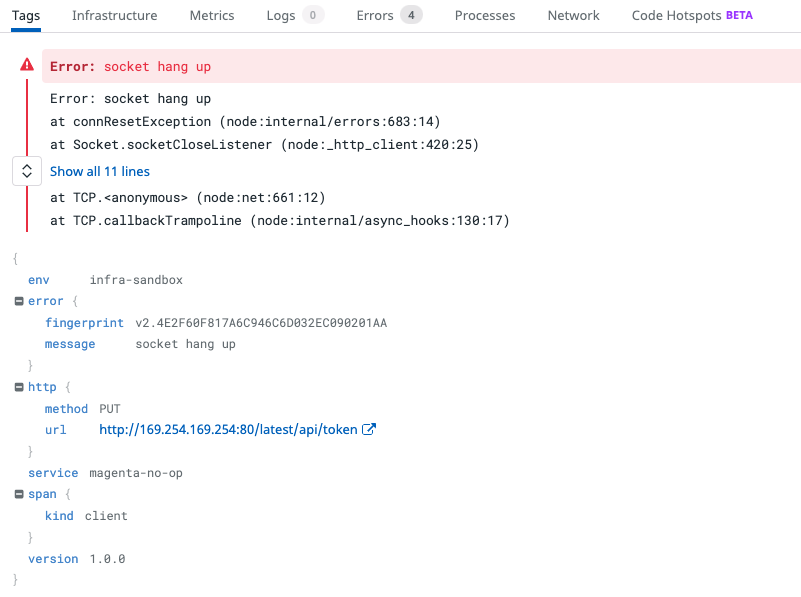
AWS JavaScript SDK делает 4 попытки вызвать службу метаданных Elastic Compute Cloud (EC2) (это IP-адрес 169.254.169.254), затем отказывается и пытается что-то еще, прежде чем успешно загрузить файл на S3.
Это реабилитировало наших разработчиков, поскольку явно не было проблемы с нашим кодом. Что-то не так с нашей инфраструктурой.
Давайте на минутку уменьшим масштаб и обсудим, как сервисы Amazon обмениваются информацией друг с другом. Все запросы API AWS должны быть подписаны учетными данными, которые связаны с ролью IAM с определенными разрешениями, например, для загрузки объектов в нашу корзину AWS S3.
Традиционно эта роль будет связана с ключами доступа, и эти учетные данные будут загружены в ваше приложение -- потенциально разоблачая их.
AWS предоставляет более безопасный механизм, когда вызовы исходят из сервиса AWS. Для наших существующих служб Convox это были роли экземпляра контейнера ECS.
Для сервисов, работающих на ECS с соответствующей ролью экземпляра, AWS SDK автоматически вызывает API метаданных в нашем кластере ECS, чтобы получить временные учетные данные, которые он может использовать для доступа к другим сервисам Amazon, таким как S3.
Это означает, что нам не нужно включать наши учетные данные AWS в наш код, а разрешения IAM могут быть напрямую связаны с самой службой ECS. Для EC2 существуют профили экземпляров EC2, которые работают почти так же.
Почти.
Почему не может, не может, не может, не может и, наконец, может ли AWS Sdk получить доступ к API метаданных в моем инстансе EC2?
Итак, почему вызовы службы метаданных EC2 завершаются с ошибкой, но каким-то образом в конце концов все же завершаются успешно? После нескольких часов изучения всей документации по JavaScript AWS SDK, ничего не найдя, мы обратились к Google.
Поиск IP-адреса, который мы видели в Datadog, привел к документации по API метаданных экземпляра EC2:
<цитата>По умолчанию AWS SDK используют вызовы IMDSv2. Если вызов IMDSv2 не получает ответа, SDK повторяет попытку вызова и, если это не удается, использует IMDSv1. Это может привести к задержке.
В среде контейнера, если ограничение прыжков равно 1, ответ IMDSv2 не возвращается, поскольку переход к контейнеру считается дополнительным сетевым прыжком. Чтобы избежать процесса возврата к IMDSv1 и связанной с этим задержки, в среде контейнера рекомендуется установить ограничение на 2 перехода. Для получения дополнительной информации см. Настройте параметры метаданных экземпляра.
Перевод: чтобы SDK, работающий в контейнере Nomad, мог получить учетные данные, он должен пройти через экземпляр EC2 для доступа к API метаданных EC2.
Это считается за два «прыжка», а ограничение по умолчанию — один! Мы изменили лимит переходов на два, а время запроса сократилось с 4 секунд до 85 мс.
Вот трассировка Datadog APM после увеличения лимита переходов до двух:
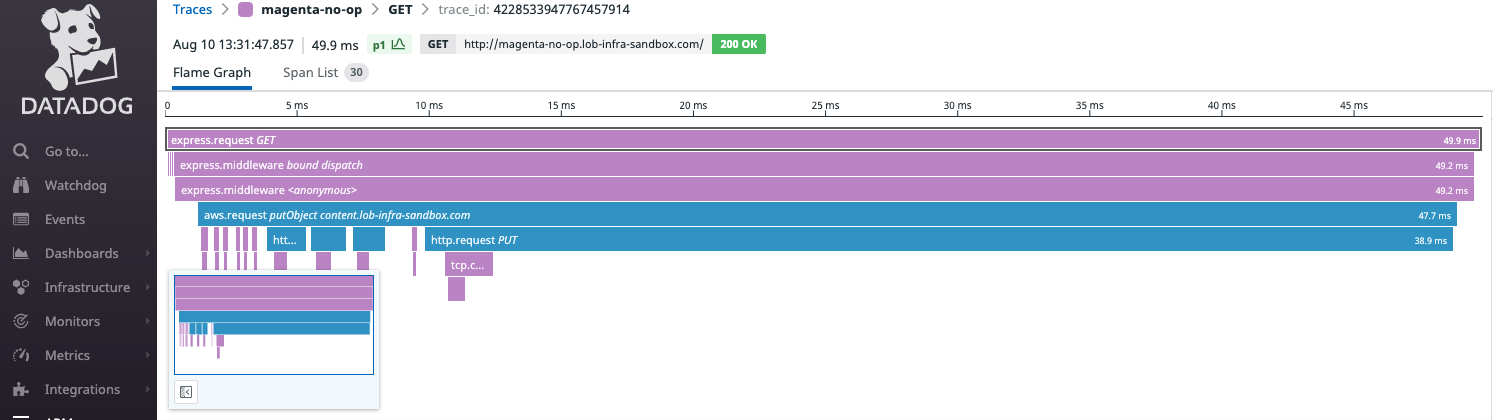
Что не так с этой картинкой?
Проще говоря, профили экземпляров EC2 — неправильный способ предоставления учетных данных приложениям, работающим в оркестраторе контейнеров. Они слишком крупнозернистые. Разрешения предоставляются всем приложениям, работающим в экземпляре EC2, а не конкретному приложению или службе.
В конце концов, именно поэтому ECS, которая работает на инстансах EC2 и поэтому может использовать профили инстансов EC2, вместо этого полагается на профили инстансов ECS.
Так почему же мы? Поскольку нам нужно было временное решение, чтобы опробовать наш экспериментальный кластер Nomad, а профили экземпляров EC2 были очень похожи на профили экземпляров ECS — наше стандартное решение в Convox.
О, и они действительно работают. Приложение смогло получить доступ к частной корзине S3. Ну, в конце концов. В основном.

Проблема заключается в том, что вызов AWS JavaScript SDK в конечном итоге завершается успешно, что маскирует основную проблему. Это нарушает принцип наименьшего удивления. По сути, система должна вести себя так, как ожидает большинство пользователей.
Поведение не должно удивлять или удивлять пользователей. Вы можете описать поведение SDK как псевдо-тихий сбой. Производительность нашего приложения сильно снизилась, и мы не подозревали, что что-то пошло не так.
Как разработчики, мы ожидаем успеха или неудачи, а не просто неудачи, а затем успеха.
Вам может быть интересно, почему AWS не устанавливает более высокое ограничение переходов по умолчанию. Мы не знаем наверняка, но мы предполагаем, что это сделано в целях безопасности.
Низкий лимит переходов по умолчанию гарантирует, что запросы учетных данных исходят внутри экземпляра EC2, и вынуждает разработчиков принимать решение об увеличении лимита переходов и учитывать любые связанные с этим риски.
Заключение
Из нашего опыта отслеживания этой проблемы с производительностью можно извлечь несколько уроков.
* Регулярно проверяйте производительность вашего приложения * Используйте современные инструменты, такие как Datadog, при исследовании проблем с производительностью. * Изолируйте подозрительный код, чтобы удалить шум и наблюдать за сигналом * Копаться в документации * Google может помочь вашему расследованию, когда вы обнаружите уникальные улики (но вы уже знали об этом)

Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27538)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)