

Как открытая модель 8B устанавливает новые стандарты для безопасного и эффективного искусственного искусства, на языке зрения
16 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 терминология
3 Изучение пространства дизайна моделей на языке зрения и 3.1. Все ли предварительно обученные основы эквивалентны VLMS?
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
3.3 Где повышение эффективности?
3.4 Как можно вычислить торговлю на производительность?
4 IDEFICS2-открытая современная модель Фонда зрения и 4.1 многоэтапное предварительное обучение
4.2 Инструкция тонкая настройка и 4.3 оптимизация для сценариев чата
5 Заключение, подтверждение и ссылки
Приложение
A.1 Дальнейшие экспериментальные детали абляций
A.2 Детали инструкции тонкая настройка
A.3 Детали оценок
A.4 Красная команда
5 Заключение
В этой работе мы пересматриваем общий выбор, сделанный в литературе VLM и строго сравниваем этот выбор в контролируемых экспериментах. Наши результаты затрагивают эффективность различных архитектур, их компромиссы затрат/вывода, а также стабильность обучения. С этими знаниями мы обучаем IDEFICS2, открытую модель параметров 8B. IDEFICS2 является современным на различных критериях в размере своей категории и гораздо более эффективен при выводе. Выпустив наши выводы, а также наши модели и наш учебный набор данных, мы стремимся внести свой вклад в постоянную эволюцию VLMS и их приложения в решении сложных реальных проблем.
Подтверждение
Мы благодарим Мустафу Шукора за полезные предложения по бумаге, а также Ячин Джернит, Сашу Луччиони, Маргарет Митчелл, Джада Пистилли, Люси-Аймэ Каффи и Джек Кумар за красную команду модель.
Ссылки
Ачарья, М., К. Кафле и С. Канан (2019). Tallyqa: Ответ на сложные вопросы подсчета. В аааи.
Agrawal, H., K. Desai, Y. Wang, X. Chen, R. Jain, M. Johnson, D. Batra, D. Parikh, S. Lee и P. Anderson (2019, октябрь). NOCAPS: Новая подпись объекта в масштабе. В 2019 году IEEE/CVF Международная конференция по компьютерному видению (ICCV). IEEE.
Alayrac, J.-B., J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. L. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Шарифзаде, М. А. Binkowski, R. Barreira, ´ O. vinynals, A. Zisserman и K. Simonyan (2022). Flamingo: модель визуального языка для нескольких выстрелов. В S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho и A. Oh (Eds.), Достижения в системах обработки нейронной информации, том 35, с. 23716–23736. Curran Associates, Inc.
Antol, S., A. Agrawal, J. Lu, M. Mitchell, D. Batra, C.L. Zitnick и D. Parikh (2015). VQA: визуальный вопрос ответа. В Международной конференции по компьютерному видению (ICCV).
Awadalla, A., I. Gao, J. Gardner, J. Hessel, Y. Hanafy, W. Zhu, K. Marathe, Y. Bitton, S. Gadre, S. Sagawa, J. Jitsev, S. Kornblith, P. W. Koh, G. Ilharco, M. Wortsman и L. Schmidt (2023). OpenFlamingo: рамка с открытым исходным кодом для обучения крупных авторегрессивных моделей на языке зрения.
Bach S., V. Sanh, Z. X. Yong, A. Webson, C. Raffel, N. V. Nayak, A. Sharma, T. Kim, M. S. Bari, T. Fevry, Z. Alyafeai, M. Dey, A. Santilli, Z. Sun, S. Ben-David, C. Xu, G. Chhablani, H. Wang, J. Fries, M. A. A. Al, S. a. a.-sharma, S. a., S. a.-sharma, S. a., S. a.-sharma, S. a., S. a. a. sharma. Thakker, K. Almubarak, X. Tang, D. Radev, M.T.-J. Цзян и А. Раш (2022, май). ReptSource: интегрированная среда разработки и хранилище для подсказок естественного языка. В V. Basile, Z. Kozareva и S. Stajner (Eds.), Труды 60 -го ежегодного собрания Ассоциации по вычислительной лингвистике: демонстрации системы, Дублин, Ирландия, с. 93–104. Ассоциация вычислительной лингвистики.
Bai, J., S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou и J. Zhou (2023). QWEN-VL: универсальная модель на языке зрения для понимания, локализации, чтения текста и за ее пределами.
Bavishi, R., E. Elsen, C. Hawthorne, M. Nye, A. Odena, A. Somani и S. Ta¸sırlar (2023). Представление наших мультимодальных моделей.
Belouadi, J., A. Lauscher и S. Eger (2024). Automatikz: Синтез научной векторной графики с Textikz с Tikz.
Biten, A.F., R. Tito, L. Gomez, E. Valveny и D. Karatzas (2022). OCR-IDL: ANCR ANNOTations для набора библиотеки библиотеки документов.
Biten, A.F., R. Tito, A. Mafla, L. Gomez, M. Rusiñol, C. Jawahar, E. Valveny и D. Karatzas (2019). Текст сцены визуальный вопрос ответа. В 2019 году IEEE/CVF Международная конференция по компьютерному видению (ICCV), с. 4290–4300.
Blecher, L., G. Cucurull, T. Scialom и R. Stojnic (2023). Nougat: нейронное оптическое понимание для академических документов.
Браун, Т., Б. Манн, Н. Райдер, М. Суббия, Дж. Д. Каплан, П. Дхаривал, А. Нилакантан, П. Шьям, Г. Састри, А. Аскелл, С. Агарвал, А. Герберт-Вус, Г. Крюгер, Т. Хэтрин, Р. Чайлд, А. Рамеш, Д. Зиглер, Дж. Ву, С. Хесс, М. Хесс, М. Хесс, М. Хесс, М. Хесс, М. Хесс, М. Хесс. Litwin, S. Grey, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever и D. Amodei (2020). Языковые модели-это несколько выстрелов. В H. Larochelle, M. ranzato, R. Hadsell, M. Balcan и H. Lin (Eds.), Достижения в системах обработки нейронной информации, том 33, с. 1877–1901. Curran Associates, Inc.
Carbune, V., H. Mansoor, F. Liu, R. Aralikatte, G. Baechler, J. Chen и A. Sharma (2024). Рассуждение на основе диаграмм: передача возможностей из LLMS в VLMS.
Чанг С., Д. Палцер, Дж. Ли, Э. Фослер-Лусье и Н. Сяо (2022). MAPQA: набор данных для вопроса, отвечающий на карты COROPLETH. В Neurips 2022 Первая таблица мастерская.
Changpinyo, S., P. Sharma, N. Ding и R. Soricut (2021). Концептуальная 12m: подтолкнуть предварительное обучение в виде веб-масштаба для распознавания визуальных концепций длинного хвоста. В CVPR.
Chen, L., J. Li, X. Dong, P. Zhang, C. He, J. Wang, F. Zhao и D. Lin (2023). ShareGPT4V: улучшение крупных мультимодальных моделей с лучшими подписями.
Chen, X., J. Jolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Goodman, X. Wang, Y. Tay, S. Shakeri, M. Dehghani, D. Salz, M. Lucic, M. Tschannen, A. Nagrani, H. Hu, M. Joshi, B. Pangzy, P. P., P. P., P. P., P. P., M. P., P. P. Ritter, A. Piergiovanni, M. Minderer, F. Pavetic, A. Waters, G. Li, I. Alabdulmohsin, L. Beyer, J. Amelot, K. Lee, A. P. Steiner, Y. Li, D. Keysers, A. Arnab, Y. Xu, K. Rong, A. Kolesnikov, M. Seyedhosseini, A. Angelova, n. zhasb Soricut (2023). Pali-X: При масштабировании многоязычного зрения и языковой модели.
Чен, Х. и Х. Ван (2022). Пали: масштабирование языкового обучения на 100+ языках. В конференции по системам обработки нейронной информации (Neurips).
Chen, X., X. Wang, L. Beyer, A. Kolesnikov, J. Wu, P. Voigtlaender, B. Mustafa, S. Goodman, I. Alabdulmohsin, P. Padlewski, D. Salz, X. Xiong, D. Vlasic, F. Pavetic, K. Rong, T. Yu, D. Keysers, X. Zhai и R.23. Pali-3 Language Models: меньше, быстрее, сильнее.
Chen, Z., W. Chen, C. Smiley, S. Shah, I. Borova, D. Langdon, R. Moussa, M. Beane, T.-H. Huang, B. Routledge и W. Y. Wang (2021, ноябрь). FINQA: набор данных числовых рассуждений по финансовым данным. В М.-Ф. Moens, X. Huang, L. Specia и S.W.-T. Yih (Eds.), Труды конференции 2021 года по эмпирическим методам обработки естественного языка, онлайн и Пунта -Кана, Доминиканская Республика, с. 3697–3711. Ассоциация вычислительной лингвистики.
Cheng, Z., H. Dong, Z. Wang, R. Jia, J. Guo, Y. Gao, S. Han, J.-G. Лу и Д. Чжан (2022, май). Hitab: иерархический набор данных таблицы для ответа на вопросы и генерации естественного языка. В S. Muresan, P. Nakov и A. villavicencio (Eds.), Слушания 60 -го ежегодного собрания Ассоциации по вычислительной лингвистике (том 1: Долгие документы), Дублин, Ирландия, с. 1094–1110. Ассоциация вычислительной лингвистики.
Chu, X., L. Qiao, X. Zhang, S. Xu, F. Wei, Y. Y. Yang, X. Sun, Y. Hu, X. Lin, B. Zhang и C. Shen (2024). MobileVLM V2: Более быстрая и более сильная базовая линия для модели языка зрения.
Коновер, М., М. Хейс, А. Матур, Дж. Се, Дж. Ван, С. Шах, А. Годси, П. Венделл, М. Захария и Р. Синь (2023). БЕСПЛАТНАЯ ДОЛЛИ: Представление первого в мире по-настоящему открытого обучения LLM. https://www.databricks.com/blog/2023/04/12/ Dolly-first-open-commercially-abible-instruction-tuned-llm. Доступ: 2023-06-30.
Dai, W., J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. Fung и S. Hoi (2023). INSTRUCTBLIP: к моделям общего назначения зрительного языка с настройкой инструкций. В Тридцать седьмой конференции по системам обработки нейронной информации.
Darcet, T., M. Oquab, J. Mairal и P. Bojanowski (2024). Трансформеры зрения нужны регистры. В Двенадцатой Международной конференции по обучению.
Dehghani, M., J. Jolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. P. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, R. Jenatton, L. Beyer, M. Tschannen, A. Arnab, X. Wang, C. Riquelme Ruiz, M. Mindererer, J. Evcuerver, J. Evcuerver, M. Evcurever, M. Evcure, M. Evcure, M. Evcure, M. Evcure, M. Evcerver, M. Mindererer, J. Kumar, S.V. Steenkiste, G.F. Elsayed, A. Mahendran, F. Yu, A. Oliver, F. Huot, J. Bastings, M. Collier, A. A. Gritsenko, V. Birodkar, C. N. Vasconcelos, Y. Tay, T. Mensink, A. Kolesnikov, Favetic, Tran, M. Kip, M. Kip, M. Kip, M. Kip, M. Kip, M. Kip, M. Kip, M. Kip, M. Kip. Zhai, D. Keysers, J. J. Harmsen и N. Houlsby (2023, 23–29 июля). Масштабирование трансформаторов зрения до 22 миллиардов параметров. В A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato и J. Scarlett (Eds.), Труды 40 -й Международной конференции по машинному обучению, том 202 «Слушания исследований машинного обучения», стр. 7480–7512. PMLR.
Dehghani, M., B. Mustafa, J. Jolonga, J. Heek, M. Minderer, M. Caron, A.P. Steiner, J. Puigcerver, R. Geirhos, I. Alabdulmohsin, A. Oliver, P. Padlewski, A.A. Gritsenko, M. Lucic и N. Houlsby (2023). Patch N ’Pack: Navit, видение трансформатор для любого соотношения сторон и разрешения. В Тридцати семидневной конференции по системам обработки нейронной информации.
Дэн, Дж., В. Донг, Р. Сохер, Л.-Ж. Ли, К. Ли и Л. Фей-Фей (2009). ImageNet: крупномасштабная иерархическая база данных изображений. В 2009 году конференция IEEE по компьютерному зрению и распознаванию шаблонов, стр. 248–255.
Десаи К., Г. Каул, З. Айсола и Дж. Джонсон (2021). REDCAPS: данные с визобновым текстом, созданные людьми, для людей. В J. Vanschoren и S. Yeung (Eds.), Труды систем обработки нейронной информации отслеживают на наборах данных и критериях, том 1. Curran.
Driess, D., F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y. Chebotar, P. Sermanet, D. Duckworth, S. Levine, V. Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Мордатч и П. Флоренция (2023). Palm-E: воплощенная мультимодальная языковая модель. В материалах 40 -й Международной конференции по машинному обучению, ICML’23. Jmlr.org.
Gao, P., R. Zhang, C. Liu, L. Qiu, S. Huang, W. Lin, S. Zhao, S. Geng, Z. Lin, P. Jin, K. Zhang, W. Shao, C. Xu, C. He, J. He, H. Shao, P. Lu, H. Li и Y. Qiao (2024). SPHINX-X: масштабирование данных и параметров для семейства многомодальных крупных языковых моделей.
Google (2023). Близнецы: семейство очень способных мультимодальных моделей.
Google (2024a). Близнецы 1.5: разблокировка мультимодального понимания по миллионам токенов контекста.
Google (2024b). Джемма: открытые модели на основе исследований и технологий Близнецов.
Goyal, Y., T. Khot, D. Summers-Stay, D. Batra и D. Parikh (2017). Создание V в VQA Matter: повышение роли понимания изображения в ответе на визуальный вопрос. В 2017 году конференция IEEE по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 6325–6334.
He, X., Y. Zhang, L. Mou, E. Xing и P. Xie (2020). Pathvqa: 30000+ вопросов для ответа на визуальный вопрос.
Hendrycks, D., C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song и J. Steinhardt (2021). Измерение массового многозадачного понимания языка. В Международной конференции по обучению.
Hong, W., W. Wang, Q. Lv, J. Xu, W. Yu, J. Ji, Y. Wang, Z. Wang, Y. Zhang, J. Li, B. Xu, Y. Dong, M. Ding и J. Tang (2023). Cogagent: модель визуального языка для агентов GUI.
Hu, A., H. Xu, J. Ye, M. Yan, L. Zhang, B. Zhang, C. Li, J. Zhang, Q. Jin, F. Huang и J. Zhou (2024). Mplug-Docowl 1.5: Объединенное структурный обучение для понимания документа без OCR.
Hu, E.J., Yelong Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang и W. Chen (2022). LORA: Низкая адаптация крупных языковых моделей. В Международной конференции по обучению.
Huang, S., L. Dong, W. Wang, Y. Hao, S. Singhal, S. Ma, T. LV, L. Cui, O. K. Mohammed, B. Patra, Q. Liu, K. Aggarwal, Z. Chi, J. Bjorck, V. Chaudhary, S. Som, X. Song и F. Wei (2023). Язык - это не все, что вам нужно: согласование восприятия с языковыми моделями. В Тридцать седьмой конференции по системам обработки нейронной информации.
Hudson, D.A. и C. D. Manning (2019). GQA: новый набор данных для реальных визуальных рассуждений и ответа на композиционный вопрос. В 2019 году конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 6693–6702.
Iyyer, M., W.-T. Йи и М.В. Чанг (2017, июль). Поисковое нейронное структурированное обучение для ответа последовательных вопросов. В Р. Барзилай и М.-Ю. Кан (ред.), Материалы 55 -го ежегодного собрания Ассоциации вычислительной лингвистики (том 1: Долгие документы), Ванкувер, Канада, с. 1821–1831. Ассоциация вычислительной лингвистики.
Jaegle, A., F. Gimeno, A. Brock, O. Vinyanals, A. Zisserman и J. Carreira (2021, 18–24 июля). Восприятие: общее восприятие с итеративным вниманием. В M. Meila и T. Zhang (Eds.), Материалы 38 -й Международной конференции по машинному обучению, Том 139 Служений исследований машинного обучения, с. 4651–4664. PMLR.
Jain, N., P. Yeh Chiang, Y. Wen, J. Kirchenbauer, H.-M. Chu, G. Somepalli, B.R. Bartoldson, B. Kailkhura, A. Schwarzschild, A. Saha, M. Goldblum, J. Geiping и T. Goldstein (2024). Neftune: шумные встраивания улучшают создание обучения. В Двенадцатой Международной конференции по обучению.
Jhamtani, H. et al. (2018, октябрь-ноябрь). Обучение описанию различий между парами похожих изображений. В E. Riloff, D. Chiang, J. Hockenmaier и J. Tsujii (Eds.), Труды конференции 2018 года по эмпирическим методам в обработке естественного языка, Брюссель, Бельгия, с. 4024–4034. Ассоциация вычислительной лингвистики.
Jiang, A. Q., A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix и W. E. Sayed (2023). Мишстраль 7b.
Johnson, J., B. Hariharan, L. van der Maaten, L. fei-fei, C.L. Zitnick и R. Girshick (2017). CLEVR: диагностический набор данных для композиционного языка и элементарных визуальных рассуждений. В 2017 году конференция IEEE по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 1988–1997.
Kafle, K., S. Cohen, B. Price и C. Kanan (2018). DVQA: Понимание визуализации данных с помощью ответа на вопросы. В CVPR.
Kahou, S.E., V. Michalski, A. Atkinson, A. Kadar, A. Trischler и Y. Bengio (2018). Рисунок: Аннотированный набор данных фигуры для визуальных рассуждений.
Karamcheti, S., S. Nair, A. Balakrishna, P. Liang, T. Kollar и D. Sadigh (2024). Призматические VLM: исследование пространства дизайна визуально кондиционированных языковых моделей.
Каземи, М., Х. Альвари, А. Ананд, Дж. У, Х. Чен и Р. Сорикут (2024). Geomverse: систематическая оценка крупных моделей для геометрических рассуждений. В синтетических данных для семинара по компьютерному зрению @ CVPR 2024.
Kembhavi, A., M. Salvato, E. Kolve, M. Seo, H. Hajishirzi и A. Farhadi (2016). Диаграмма стоит дюжины изображений. В B. Leibe, J. Matas, N. Sebe и M. Welling (Eds.), Computer Vision - ECCV 2016, Cham, стр. 235–251. Springer International Publishing.
Kembhavi, A., M. Seo, D. Schwenk, J. Choi, A. Farhadi и H. Hajishirzi (2017). Вы умнее шестиклассника? Учебник для ответа на многомодальное понимание машины. В 2017 году конференция IEEE по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 5376–5384.
Киела, Д., Х. Фируз, А. Мохан, В. Госвами, А. Сингх, П. Рингшия и Д. Тестаггин (2020). Задача ненавистных мемов: обнаружение ненавистнической речи в мультимодальных мемах. В H. Larochelle, M. ranzato, R. Hadsell, M. Balcan и H. Lin (Eds.), Достижения в системах обработки нейронной информации, том 33, с. 2611–2624. Curran Associates, Inc.
Кингма, Д. и Дж. Ба (2015). Адам: метод стохастической оптимизации. В Международной конференции по обучению представлений (ICLR), Сан -Дига, Калифорния, США.
Koh, J. Y., R. Salakhutdinov и D. Fried (2023). Заземляющие языковые модели для изображений для мультимодальных входов и выходов.
Lau, J., S. Gayen, A. Ben Abacha и D. Demner-Fushman (2018, 11). Набор данных клинически сгенерированных визуальных вопросов и ответов на радиологические изображения. Научные данные 5, 180251.
Laurençon, H., L. Saulnier, T. Wang, C. Akiki, A. Villanova del Moral, T. Le Scao, L. Von Werra, C. Mou, E. González Ponferrada, H. Nguyen, J. Frohberg, M. ushashko, Q. Lhoest, A. McMillanmajor, G. Dupont, S. Birmmam. Allal, F. de Toni, G. Pistilli, O. Nguyen, S. Nikpoor, M. Masoud, P. Colombo, J. De La Rosa, P. Villegas, T. Thrush, S. Longpre, S. Nagel, L. Weber, M. Muñoz, J. Zhu, D. van Streen, Z. Alyafeai, K. Almubarak, M. C. vuseaios, A. nasleaios, I. vusleaios, I. vanzeosios, m. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu. vu, z. alyafeai, alyafeai, alyafeai. К. Ло, М. Дей, П. Ортис Суарес, А. Гокаслан, С. Бозе, Д. Аделани, Л. Фан, Х. Тран, И. Ю., С. Пай, Дж. Чим, В. Леперк, С. Илик, М. Митчелл, С. А. Луччиони и Ю. Джернит (2022). Корпус BigScience Corpes: составной многоязычный набор данных 1,6 ТБ. В S. Koyjo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho и A. Oh (Eds.), Достижения в системах обработки нейронной информации, том 35, с. 31809–31826. Curran Associates, Inc.
Laurençon, H., L. Saulnier, L. Tronchon, S. Bekman, A. Singh, A. Lozhkov, T. Wang, S. Karamcheti, A.M. Rush, D. Kiela, M. Cord и V. Sanh (2023). Обелики: открытый набор данных в веб-масштабах с переоцененными документами с изображением. В Тридцати седьмой конференции по наборам данных по обработке нейронной информации и контрольные данные отслеживают.
Laurençon, H., L. Tronchon и V. Sanh (2024). Разблокирование конверсии веб -скриншотов в HTML -код с помощью набора данных Websight.
Lee, B.-K., B. Park, C. W. Kim и Y. M. Ro (2024). MOAI: Смесь всего интеллекта для больших моделей языка и зрения.
Lee, K., M. Joshi, I. Turc, H. Hu, F. Liu, J. Eisenschlos, U. Khandelwal, P. Shaw, M.W. Чанг и К. Тутанова (2023). Pix2Struct: Scenshot Sanaing как предварительная подготовка для понимания визуального языка. В материалах 40 -й Международной конференции по машинному обучению, ICML’23. Jmlr.org.
Li, B., R. Wang, G. Wang, Y. Ge, Y. Ge и Y. Shan (2023). Семя-пластин: сравнительный анализ мультимодальных LLM с генеративным пониманием.
Li, B., Y. Zhang, L. Chen, J. Wang, F. Pu, J. Yang, C. Li и Z. Liu (2023). Mimic-It: многомодальная настройка инструкций в контексте.
Li, G., H.A.A. K. Hammoud, H. Itani, D. Khizbullin и B. Ghanem (2023). Верблюд: Коммуникативные агенты для «разума» исследования общества крупного языка. В Тридцать седьмой конференции по системам обработки нейронной информации.
Li, J., D. Li, S. Savarese и S. Hoi (2023). BLIP-2: предварительное обучение на основе лечения языка с замороженными кодерами изображения и большими языковыми моделями. В материалах 40 -й Международной конференции по машинному обучению, ICML’23. Jmlr.org.
Li, J., D. Li, C. Xiong и S. Hoi (2022). BLIP: начальная загрузка языкового изображения предварительного обучения для объединенного понимания и поколения на языке зрения. В ICML.
Li, L., Y. Yin, S. Li, L. Chen, P. Wang, S. Ren, M. Li, Y. Y. Yang, J. Xu, X. Sun, L. Kong и Q. Liu (2023). M3 IT: крупномасштабный набор данных в направлении многомодальной многоязычной настройки инструкций.
Li, Y., Y. Du, K. Zhou, J. Wang, X. Zhao и J.-R. Вэнь (2023, декабрь). Оценка галлюцинации объекта в больших моделях языка зрения. В H. Bouamor, J. Pino и K. Bali (Eds.), Труды конференции 2023 года по эмпирическим методам в обработке естественного языка, Сингапур, с. 292–305. Ассоциация вычислительной лингвистики.
Li, Y., Y. Zhang, C. Wang, Z. Zhong, Y. Chen, R. Chu, S. Liu и J. Jia (2024). Mini-Gemini: добыча потенциала моделей языка многомодальности.
Li, Z., B. Yang, Q. Liu, Z. Ma, S. Zhang, J. Yang, Y. Sun, Y. Liu и X. Bai (2024). Обезьяна: разрешение изображения и текстовая метка являются важными вещами для больших мультимодальных моделей.
Lin, B., Z. Tang, Y. Ye, J. Cui, B. Zhu, P. Jin, J. Huang, J. Zhang, M. Ning и L. Yuan (2024). Moe-Llava: смесь экспертов для больших моделей языка зрения.
Lin, J., H. Yin, W. Ping, Y. Lu, P. Molchanov, A. Too, H. Mao, J. Kautz, M. Shoeybi и S. Han (2024). Вила: на предварительном тренировке для моделей визуального языка.
Lin, T.-Y., M. Maire, S. Persomie, J. Hays, P. Perona, D. Ramanan, P. Dollár и C.L. Zitnick (2014). Microsoft Coco: Общие объекты в контексте. В D. Fleet, T. Pajdla, B. Schiele и T. Tuytelaars (Eds.), Computer Vision - ECCV 2014, Cham, стр. 740–755. Springer International Publishing.
Lin, Z., C. Liu, R. Zhang, P. Gao, L. Qiu, H. Xiao, H. Qiu, C. Lin, W. Shao, K. Chen, J. Han, S. Huang, Y. Zhang, X. He, H. Li и Y. Qiao (2023). SPHINX: соединение смешивания весов, задач и визуальных встроений для многомодальных крупных языковых моделей.
Линдстрем, А. Д. (2022). Clevr-Math: набор данных для композиционного языка, визуального и математического рассуждения.
Лю Ф., Г. Эмерсон и Н. Коллиер (2023). Визуальные пространственные рассуждения. Транзакции Ассоциации вычислительной лингвистики 11, 635–651.
Liu, H., C. Li, Y. Li и Y. J. Lee (2023). Улучшенные базовые показатели с настройкой визуальной инструкции. В Neurips 2023 семинар по настройке инструкций и инструкциям следующим образом.
Liu, H., C. Li, Y. Li, B. Li, Y. Zhang, S. Shen и Y. J. Lee (2024, январь). Llava-next: улучшенные рассуждения, OCR и мировые знания.
Liu, H., C. Li, Q. Wu и Y. J. Lee (2023). Настройка визуальной инструкции. В Тридцать седьмой конференции по системам обработки нейронной информации.
Лю Х., Q. You, X. Han, Y. Wang, B. Zhai, Y. Liu, Y. Too, H. Huang, R. He и H. Yang (2024). Infimm-HD: прыжок вперед в мультимодальном понимании высокого разрешения.
Лю, С.-Ю., С.-Ю. Wang, H. Yin, P. Molchanov, Y.-C. Ф. Ван, К.-Т. Ченг и М.-Х. Чен (2024). Дора: сбоя в веса, адаптация с низким уровнем ранга.
Лю, Т. и Б. К. Х. Лоу (2023). Коза: тонкая настраиваемая Llama превосходит GPT-4 по арифметическим задачам.
Liu, Y., H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu, K. Chen и D. Lin (2023). Mmbench: Ваша мультимодальная модель является универсальным игроком?
Lu, H., W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, Y. Sun, C. Deng, H. Xu, Z. Xie и C. Ruan (2024). DeepSeek-VL: На пути к реальному пониманию зрения.
Lu, J., C. Clark, S. Lee, Z. Zhang, S. Khosla, R. Marten, D. Hoiem и A. Kembhavi (2023). Unified-IO 2: масштабирование авторегрессивных мультимодальных моделей с видением, языком, аудио и действиями.
Lu, P., H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.W. Чанг, М. Галли и Дж. Гао (2024). Mathvista: Оценка математических рассуждений моделей фундамента в визуальном контексте. В Международной конференции по обучению представлений (ICLR).
Lu, P., R. Gong, S. Jiang, L. Qiu, S. Huang, X. Liang и S.-C. Чжу (2021). Inter-GPS: интерпретируемая геометрия решение проблем с формальным языком и символическими рассуждениями. На совместной конференции 59-й ежегодной встречи Ассоциации вычислительной лингвистики и 11-й Международной совместной конференции по обработке естественного языка (ACL-IJCNLP 2021).
Lu, P., S. Mishra, T. Xia, L. Qiu, K.W. Чанг, С.-С. Чжу, О. Тафьорд, П. Кларк и А. Калян (2022). Научитесь объяснять: мультимодальные рассуждения с помощью цепочек мышления для ответа на вопрос о науке. В S. Koyjo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho и A. Oh (Eds.), Достижения в системах обработки нейронной информации, том 35, с. 2507–2521. Curran Associates, Inc.
Lu, P., L. Qiu, K.W. Чан, Ю. Н. Ву, С.-С. Чжу, Т. Раджпурохит, П. Кларк и А. Калян (2023). Динамическое быстрое обучение через градиент политики для полуструктурированных математических рассуждений. В Международной конференции по обучению представлений (ICLR).
Lu, P., L. Qiu, J. Chen, T. Xia, Y. Zhao, W. Zhang, Z. Yu, X. Liang и S.-C. Чжу (2021). Iconqa: новый эталон для абстрактной диаграммы понимания и рассуждения о визуальном языке. На 35 -й конференции по системам обработки нейронной информации (Neurips) отслеживает наборы данных и контрольные показатели.
Mañas, O., P. Rodriguez Lopez, S. Ahmadi, A. Nematzadeh, Y. Goyal и A. Agrawal (2023, май). MAPL: Параметр-эффективная адаптация унимодальных предварительно обученных моделей для подсказки на языке зрения. В A. Vlachos и I. Augenstein (Eds.), Материалы 17 -й конференции Европейской главы Ассоциации вычислительной лингвистики, Дубровник, Хорватия, с. 2523–2548. Ассоциация вычислительной лингвистики.
Марино К., М. Растегари, А. Фархади и Р. Моттаги (2019). OK-VQA: визуальный вопрос ответа на вопрос, требующий внешних знаний. В конференции по компьютерному видению и распознаванию шаблонов (CVPR).
Марти, U.-V. и Х. Банке (2002, 11). IAM-Database: база данных английского предложения для распознавания автономного автономного автономного завода. Международный журнал по анализу и признанию документов 5, 39–46.
Masry, A., D. Long, J. Q. Tan, S. Joty и E. Hoque (2022, май). Chartqa: эталон для вопросов, отвечающий на чарты с визуальными и логическими рассуждениями. В результатах Ассоциации вычислительной лингвистики: ACL 2022, Дублин, Ирландия, с. 2263–2279. Ассоциация вычислительной лингвистики.
Мэтью, М., В. Багал, Р. Тито, Д. Карацзас, Э. Валвени и С. В. Джавахар (2022). Infographicvqa. В 2022 году IEEE/CVF Зимняя конференция по приложениям Computer Vision (WACV), стр. 2582–2591.
Мэтью М., Д. Карацсас и С. В. Джавахар (2021). DOCVQA: набор данных для VQA на изображениях документов. В 2021 году зимняя конференция IEEE по приложениям Computer Vision (WACV), с. 2199–2208.
McKinzie, B., Z. Gan, J.-P. Fauconnier, S. Dodge, B. Zhang, P. Dufter, D. Shah, X. Du, F. Peng, F. Weers, A. Belyi, H. Zhang, K. Singh, D. Kang, A. Jain, H. Hè, M. Schwarzer, T. Gunter, X. Kong, A. Zhang, J. Wang, C. Wang, N. Du, T. Lei, S. Wiseman, M. Wiseman, M. Wiseman, M. Wisem. Ван, Р. Пан, П. Граш, А. Тошев и Ю. Ян (2024). MM1: Методы, анализ и понимание от предварительной тренировки мультимодального LLM.
Methani, N., P. Ganguly, M.M. Khapra и P. Kumar (2020, март). Плотка: Рассуждение над научными сюжетами. На зимней конференции IEEE по приложениям Computer Vision (WACV).
Мишра, А., С. Шехар, А. К. Сингх и А. Чакраборти (2019). OCR-VQA: Ответ на визуальный вопрос, читая текст в изображениях. В 2019 году Международная конференция по анализу и признанию документов (ICDAR), стр. 947–952.
Митра А., Х. Ханпур, К. Россет и А. Авадаллах (2024). Orca-math: разблокировка потенциала SLM в математике начальной школы.
Obeid, J. и E. Hoque (2020, декабрь). Диаграмма к тексту: генерирование описаний естественного языка для диаграмм путем адаптации модели трансформатора. В B. Davis, Y. Graham, J. Kelleher и Y. Sripada (Eds.), Труды 13 -й Международной конференции по поколению естественного языка, Дублин, Ирландия, с. 138–147. Ассоциация вычислительной лингвистики.
Openai (2024). GPT-4 Технический отчет.
Pasupat, P. and P. Liang (2015, июль). Композиционный семантический анализ на полуструктурированных таблицах. В C. Zong и M. Strube (Eds.), Материалы 53 -го годового собрания Ассоциации вычислительной лингвистики и 7 -й Международной совместной конференции по обработке естественного языка (том 1: Долгие документы), Пекин, Китай, стр. 1470–1480. Ассоциация вычислительной лингвистики.
Penedo, G., Q. Malartic, D. Hesslow, R. Cojocaru, H. Alobeidli, A. Cappelli, B. Pannier, E. Almazrouei и J. Launay (2023). Набор данных RefinedWeb для Falcon LLM: опережая кураторские корпусы только с помощью веб -данных. В Тридцати седьмой конференции по наборам данных по обработке нейронной информации и контрольные данные отслеживают.
Pont-Tuset, J., J. Uijlings, S. Changpinyo, R. Soricut и V. Ferrari (2020). Соединение видения и языка с локализованными повествованиями. В A. Vedaldi, H. Bischof, T. Brox и J.-M. Frahm (Eds.), Computer Vision - ECCV 2020, Cham, стр. 647–664. Springer International Publishing.
Radford, A., J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krehger и I. Sutskever (2021). Обучение переносимым визуальным моделям от надзора естественного языка. В Международной конференции по машинному обучению.
Рен, М., Р. Кирос и Р. Земель (2015). Изучение моделей и данных для ответа на вопрос изображения. В C. Cortes, N. Lawrence, D. Lee, M. Sugiyama и R. Garnett (Eds.), Достижения в области систем обработки нейронной информации, том 28. Curran Associates, Inc.
Санх, В., А. Вебсон, С. Раффель, С. Бах, Л. Сутавика, З. Алейфей, А. Чаффин, А. Стиглер, А. Раджа, М. Дей, М. С. Бари, С. Сюй, У. Теккер, С. С. Шарма, Э. Шччла, Т. Ким, Г. Чхаблани, Н. Нейк, Д., Дж. Jiang, H. Wang, M. Manica, S. Shen, Z. X. Yong, H. Pandey, R. Bawden, T. Wang, T. Neeraj, J. Rozen, A. Sharma, A. Santilli, T. Fevry, J.A. Fries, R. Teehan, T.L. Scao, S. Biderman, L. Gao, T. Wolf и A. M. M. M. (202). Многозадачность, вызванная обучением, позволяет обобщать задачи с нулевым выстрелом. В Международной конференции по обучению.
Schuhmann, C., R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmarczy, и J. Jitsevv (2022). LAION-5B: открытый крупномасштабный набор данных для обучения моделей изображений следующего поколения. В S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho и A. Oh (Eds.), Достижения в системах обработки нейронной информации, том 35, с. 25278–25294. Curran Associates, Inc.
Schuhmann, C., R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev и A. Komatsuzaki (2021). LAION-400M: Откройте набор данных из 400 миллионов картинок 400 миллионов текстов.
Schwenk, D., A. Khandelwal, C. Clark, K. Marino и R. Mottaghi (2022). A-OKVQA: эталон визуального вопроса, отвечающего на использование мировых знаний. В Computer Vision - ECCV 2022: 17 -я Европейская конференция, Тел -Авив, Израиль, 23–27 октября 2022 года, Труды, часть VIII, Берлин, Гейдельберг, с. 146–162. Springer-Verlag.
Sharma, P., N. Ding, S. Goodman и R. Soricut (2018). Концептуальные подписи: очищенный, гипернименный, изображение альт-текстовое набор данных для автоматического подписания изображения. В материалах ACL.
Шейегани Э., Ю. Донг и Н. Абу-Газалех (2024). Джаклбрейк в частях: композиционные состязательные атаки на мультимодальные языковые модели. В Двенадцатой Международной конференции по обучению.
Shukor, M., C. Dancette и M. Cord (2023, Oct). EP-ALM: эффективное увеличение восприятия языковых моделей. В 2023 году IEEE/CVF Международная конференция по компьютерному видению (ICCV), Лос -Аламитос, Калифорния, США, с. 21999–22012. IEEE Computer Society.
Сидоров О., Р. Ху, М. Рорбах и А. Сингх (2020). Textcaps: набор данных для подписания изображения с пониманием прочитанного. В A. Vedaldi, H. Bischof, T. Brox и J.-M. Frahm (Eds.), Computer Vision - ECCV 2020, Cham, стр. 742–758. Springer International Publishing.
Сингх, А., Р. Ху, В. Госвами, Г. Куйрон, В. Галуба, М. Рорбах и Д. Киела (2022). Флава: основополагающая модель выравнивания языка и видения. В 2022 году конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 15617–15629.
Сингх, А., В. Натарджан, М. Шах, Ю. Цзян, Х. Чен, Д. Парих и М. Рорбах (2019). На пути к моделям VQA, которые могут читать. В материалах конференции IEEE по компьютерному видению и распознаванию шаблонов, стр. 8317–8326.
Сринивасан К., К. Раман, Дж. Чен, М. Бендерский и М. Наджорк (2021). Остроумие: набор данных текста изображения на основе Википедии для мультимодального многоязычного машинного обучения. В материалах 44 -й Международной конференции ACM Sigir по исследованиям и разработкам в поисках информации, Sigir ’21, Нью -Йорк, Нью -Йорк, США, с. 2443–2449. Ассоциация вычислительной техники.
Suhr, A., S. Zhou, A. Zhang, I. Zhang, H. Bai и Y. Artzi (2019, июль). Корпус для рассуждений о естественном языке, основанном на фотографиях. В A. Korhonen, D. Traum, и L. Màrquez (Eds.), Материалы 57 -го ежегодного собрания Ассоциации по вычислительной лингвистике, Флоренция, Италия, с. 6418–6428. Ассоциация вычислительной лингвистики.
Sun, Q., Y. Cui, X. Zhang, F. Zhang, Q. Yu, Z. Luo, Y. Wang, Y. Rao, J. Liu, T. Huang и X. Wang (2023). Генеративные мультимодальные модели являются учениками в контексте.
Sun, Q., Y. Fang, L. Wu, X. Wang и Y. Cao (2023). Eva-clip: улучшенные методы обучения для клипа в масштабе.
Sun, Z., S. Shen, S. Cao, H. Liu, C. Li, Y. Shen, C. Gan, L.-Y. Gui, Y.-X. Ван, Ю. Ян, К. Кейцер и Т. Даррелл (2023). Выравнивание больших мультимодальных моделей с фактически дополненным RLHF.
Танака Р., К. Нишида и С. Йошида (2021). VisualMrc: понимание прочитанного машины на изображениях документов. В аааи.
Тан, Б.Дж., А. Боггуст и А. Сатьянараян (2023). Vistext: эталон для семантически богатой подписания диаграммы. На ежегодном собрании Ассоциации вычислительной лингвистики (ACL).
Teknium (2023). OpenHermes 2.5: открытый набор данных синтетических данных для помощников Generalist LLM.
Тиль Д. (2023). Выявление и устранение CSAM в генеративных учебных данных ML.
Touvron, H., T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave и G. Lample (2023). Llama: открытые и эффективные модели языка фундамента.
Touvron, H., L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurul Госвами, Н. Гойал, А. Хартсхорн, С. Хоссейни, Р. Хоу, Х. Инан, М. Кардас, В. Керкез, М. Хабса, И. Клуманн, А. Конев, П. С. Кура, М.-Е. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramian, X. Тейлор, А. Уильямс, Дж. Х. Куан, П. Сюй, З. Ян, И. Заров, Ю. Чжан, А. Фан, М. Камбадур, С. Наранг, А. Родригес, Р. Стойник, С. Эдунов и Т. Скиалом (2023). Llama 2: Open Foundation и тонкие модели чата.
Vallaeys, T., M. Shukor, M. Cord и J. Verbeek (2024). Улучшенные базовые показатели для повышения перцептивного восприятия LLMS.
Wang, B., G. Li, X. Zhou, Z. Chen, T. Grossman и Y. Li (2021). Screen2words: автоматическое суммирование мобильного пользовательского интерфейса с помощью мультимодального обучения. На 34 -м ежегодном симпозиуме ACM по программному обеспечению и технологии пользовательского интерфейса, UIST ’21, Нью -Йорк, Нью -Йорк, США, с. 498–510. Ассоциация вычислительной техники.
Wang, W., Q. LV, W. Yu, W. Hong, J. Qi, Y. Wang, J. Ji, Z. Yang, L. Zhao, X. Song, J. Xu, B. Xu, J. Li, Y. Dong, M. Ding и J. Tang (2024). Cogvlm: Visual Expert для предварительно подготовленных языковых моделей.
Wei, J., M. Bosma, V. Zhao, K. Guu, A.W. Yu, B. Lester, N. Du, A.M. Dai и Q. V. Le (2022). Созданные языковые модели являются учениками с нулевым выстрелом. В Международной конференции по обучению.
Xiao, J., Z. Xu, A. Yuille, S. Yan и B. Wang (2024). Palm2-Vadapter: постепенно выровненная языковая модель делает сильный адаптер на языке зрения.
Oung, P., A. Lai, M. Hodosh и J. Hockenmaier (2014). От описаний изображений до визуальных обозначений: новые показатели сходства для семантического вывода по описанию событий. Транзакции Ассоциации по вычислительной лингвистике 2, 67–78.
Yu, L., W. Jiang, H. Shi, J. Yu, Z. Liu, Y. Zhang, J. Kwok, Z. Li, A. Weller и W. Liu (2024). Метамат: Началуйте ваши собственные математические вопросы для больших языковых моделей. В Двенадцатой Международной конференции по обучению.
Yue, X., Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y. Liu, W. Huang, H. Sun, Y. Su и W. Chen (2024). MMMU: массовый многодисциплинальный многомодальный эталон и рассуждения для экспертов AGI. В материалах CVPR.
Yue, X., X. Qu, G. Zhang, Y. Fu, W. Huang, H. Sun, Y. Su и W. Chen (2024). Мамонт: создание математических моделей с помощью гибридной настройки инструкций. В Двенадцатой Международной конференции по обучению.
Zhai, X., B. Mustafa, A. Kolesnikov и L. Beyer (2023). Сигмоидальная потеря для преподавания изображения языка.
Zhang, C., F. Gao, B. Jia, Y. Zhu и S.-C. Чжу (2019). Ворон: набор данных для реляционных и аналогичных визуальных рассуждений. В материалах конференции IEEE по компьютерному видению и распознаванию шаблонов (CVPR).
Zhang, X., C. Wu, Z. Zhao, W. Lin, Y. Zhang, Y. Wang и W. Sie (2023). PMC-VQA: настройка визуальных инструкций для ответа на визуальные вопросы.
Zhao, Y., Y. Li, C. Li и R. Zhang (2022, май). Multihiertt: Численные рассуждения по многое иерархическим табличным и текстовым данным. В материалах 60 -го ежегодного собрания Ассоциации по вычислительной лингвистике (том 1: Долгок), Дублин, Ирландия, с. 6588–6600. Ассоциация вычислительной лингвистики.
Zhao, Y., C. Zhao, L. Nan, Z. Qi, W. Zhang, X. Tang, B. Mi и D. Radev (2023, июль). Ропут: Систематическое изучение таблицы QA надежности против аннотируемых человеком состязательных возмущений. В A. Rogers, J. Boyd-Graber и N. Okazaki (Eds.), Материалы 61-й ежегодного собрания Ассоциации по вычислительной лингвистике (том 1: Долгие документы), Торонто, Канада, с. 6064–6081. Ассоциация вычислительной лингвистики.
Zhong, V., C. Xiong и R. Socher (2017). SEQ2SQL: генерирование структурированных запросов из естественного языка с использованием обучения подкрепления.
Zhou, B., Y. Hu, X. Weng, J. Jia, J. Luo, X. Liu, J. Wu и L. Huang (2024). Tinylylava: структура мелких крупных мультимодальных моделей.
Zhou, C., P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. Yu, S. Zhang, G. Ghosh, M. Lewis, L. Zettlemoyer и O. Levy (2023). Лима: меньше для выравнивания. В Тридцати семидневной конференции по системам обработки нейронной информации.
Zhu, F., W. Lei, Y. Huang, C. Wang, S. Zhang, J. LV, F. Feng и T.-S. Чуа (2021, август). TAT-QA: эталон ответа вопроса о гибриде табличного и текстового контента в финансах. В материалах 59 -го ежегодного собрания Ассоциации по вычислительной лингвистике и 11 -й Международной совместной конференции по обработке естественного языка (том 1: Долгок), онлайн, стр. 3277–3287. Ассоциация вычислительной лингвистики.
Zhu, W., J. Hessel, A. Awadalla, S. Y. Gadre, J. Dodge, A. Fang, Y. Yu, L. Schmidt, W. Y. Wang и Y. Choi (2023). Мультимодальный C4: открытый, миллиард масштабной корпус изображений, чередующегося с текстом. В Тридцати седьмой конференции по наборам данных по обработке нейронной информации и контрольные данные отслеживают.
Zhu, Y., O. Groth, M. Bernstein и L. Fei-Fei (2016). Visual7W: заземленный вопрос, отвечающий на изображениях. В конференции IEEE по компьютерному видению и распознаванию образцов.
A.1 Дальнейшие экспериментальные детали абляций
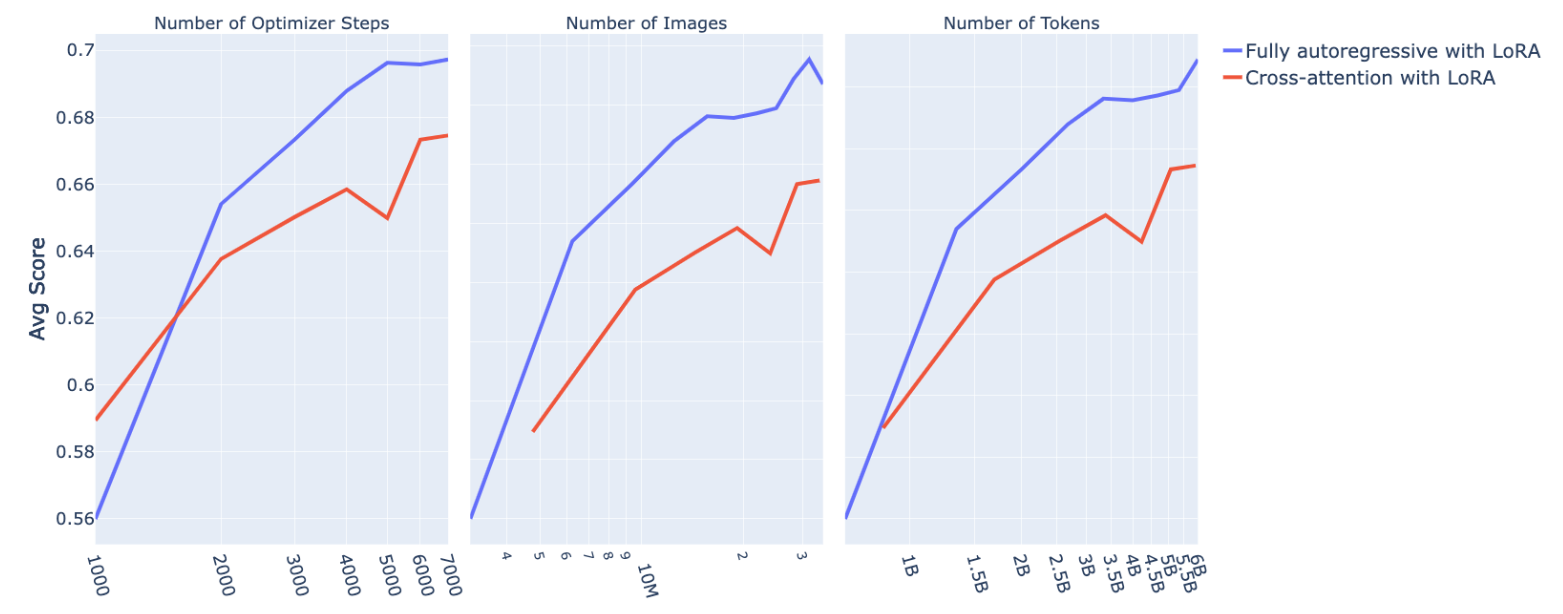
A.1.1 Поперечное внимание и полностью авторегрессивные архитектуры
Мы применяем модули LORA к LLM для полностью авторегрессивной архитектуры и к модулям пересечения и LLM для архитектуры поперечного анимации. На рисунке 4 мы сообщаем о средней производительности по количеству шагов, количеству изображений, а также о количестве текстовых токенов. Мы видим улучшение по всем направлениям с полностью авторегрессивной архитектурой. Сравнение среднего балла с этими разными ослями имеет важное значение, потому что архитектура перекрестного атянутого атмосфера подает один токен на изображение с языковой моделью, против 64 для полностью авторегрессивной архитектуры с воспринимающим пулом. Это подразумевает, что для одной и той же длины обучающей последовательности количество изображений и текстовых токенов отличается для двух архитектур. Эквивалентно, один и тот же мультимодальный документ даст разные длины последовательности. Несмотря на то, что мы фиксируем размер партии в сравнении, количество токенов текста и количество изображений растут на разных шагах под двумя архитектурами.
A.1.2 Сравнение различных основных костей зрения
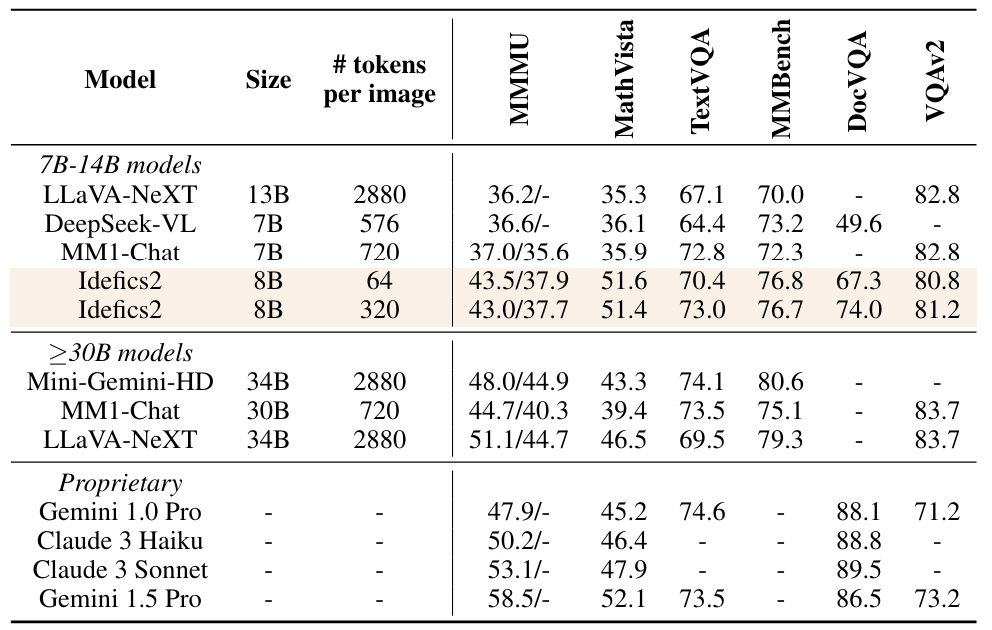
Мы представляем в таблице 10 подробные результаты сравнения нескольких оснований зрения. В то время как EVA-CLIP5B работает аналогично Siglip-So400M, мы подчеркиваем, что он имеет в 11 раз больше параметров. В ранних экспериментах мы также заметили, что TextVQA является наиболее чувствительным эталоном для разрешения изображений, что объясняет повышение производительности.

A.1.3 Сравнение различных стратегий объединения
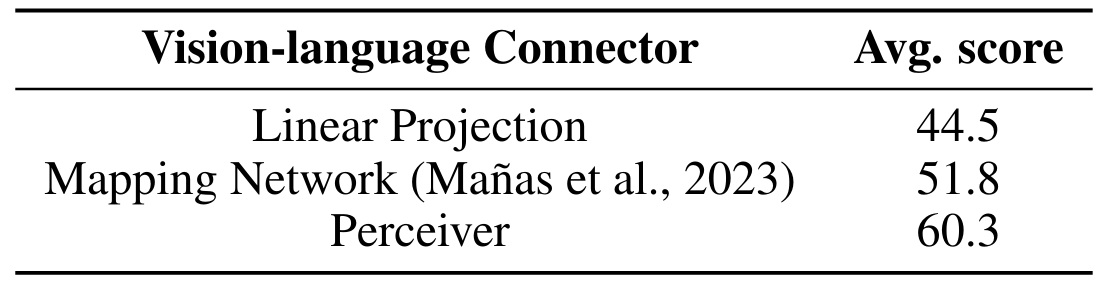
Мы сравниваем несколько стратегий объединения: простой линейный слой, который берет сплющенную последовательность зрения скрытых состояний и проецирует его в более короткую последовательность визуальных токенов, а также сеть отображения (Mañas et al., 2023). Восприятие Resampler значительно превосходит эти два варианта (см. Таблицу 11).
Мы также подчеркиваем количество слоев в воспринимающем переосмыслении и не находим статистически значимых различий при увеличении количества слоев, аналогично результатам Xiao et al. (2024). Мы оседаем на 3 слоях предостережения, чтобы избежать каких -либо узких мест потенциала.
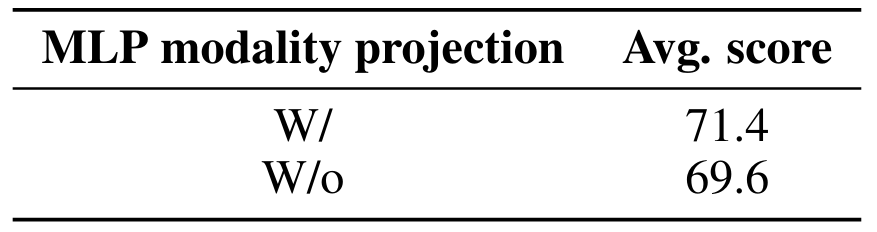
Наконец, мы добавляем двухслойный проекционный MLP модальности поверх скрытых состояний кодера зрения, чтобы проецировать видение скрытое измерение в языковую модель скрытого измерения до воспринимающего Resampler. Эти изменения также дают лучшую производительность (см. Таблицу 13).

A.1.4 Абляции на данных OCR
Мы предполагаем, что добавление документов PDF помогает модели научиться читать текст из изображений. В таблице 7 мы сравниваем контрольно -пропускные пункты, обученные документам OCR и без него, наряду с увеличением разрешения изображения, чтобы гарантировать, что текст является разборчивым. Мы не наблюдаем статистически значимых различий при оценке контрольных точек в нулевом или нескольких выстреле. Вместо этого мы настраиваем контрольно-пропускные пункты на DOCVQA на 500 шагов с скоростью обучения 1E-5, что приводит к контрольно-пропускным пунктам, показывающим гораздо более сильные различия.
A.2 Детали инструкции тонкая настройка
A.2.1 Статистика котла
В таблице 14 мы представляем статистику наборов данных, включенных в котел, а также наборы данных только для текста, используемые для контролируемой точной настройки. Для каждого набора данных мы даем количество различных изображений, которые он содержит, количество пар вопросов-ответов, общее количество токенов для ответов в парах вопросов-ответов и выбранного процента токенов, которые он представляет в нашем окончательном смеси после UPSampling или Downsampling.
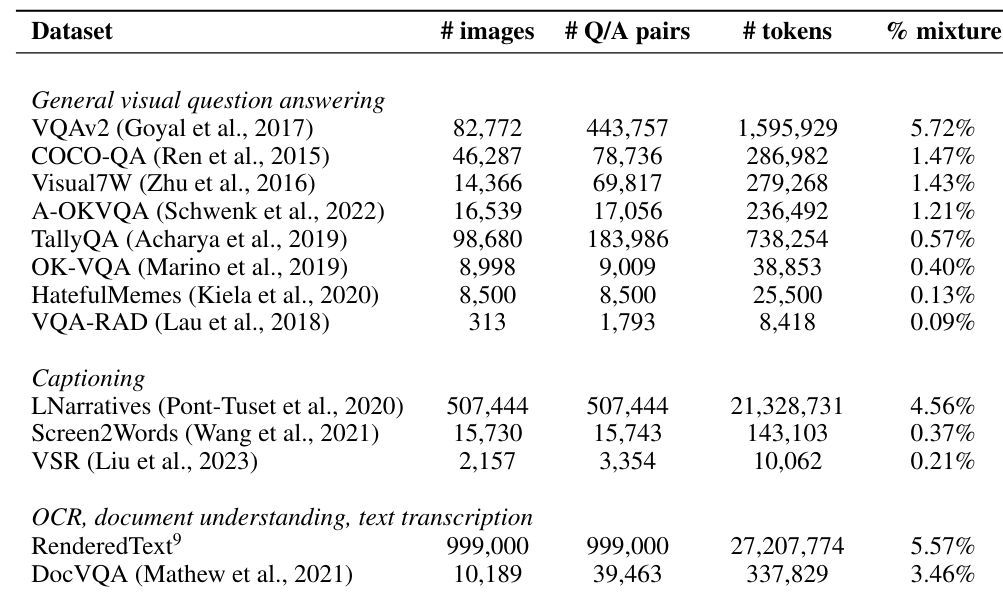
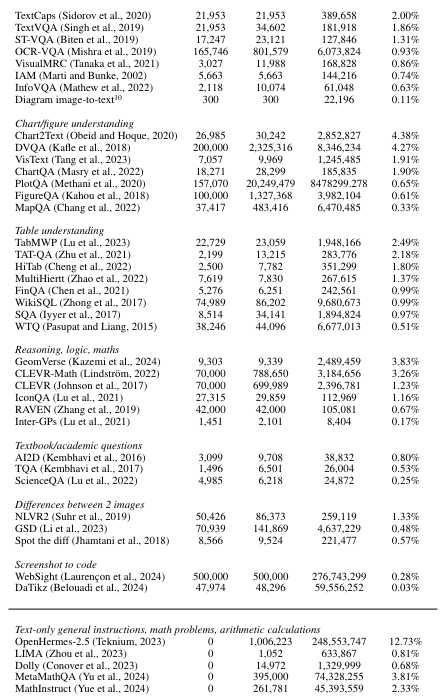

Таблица 14: Статистика наборов данных, используемые для точной настройки инструкции. # Tokens - это общее количество токенов для каждого набора данных только для ответов. % Смесь - это наш выбранный процент токенов ответа для каждого набора данных в окончательной смеси.
A.3 Детали оценок
А.3.1 Настройка оценки
Мы проводим все оценки с размером партии 1 и жадным декодированием.
Для вопросов с несколькими выборами в MMMU, Mathvista, Mmbench мы оцениваем с той же подсказкой, используемой для аналогичных типов наборов данных во время точной настройки инструкции:

Для открытых вопросов в TextVQA, DocVQA и VQAV2 мы оцениваем с помощью подсказки:

Мы используем вопрос Stop Words, пользователь, <end_of_utterance> и <EOS>, чтобы остановить поколение.
A.3.2 Расширенная таблица оценки
Мы сообщаем о расширенной оценке IDEFICS2 и сравнении с другими моделями в таблице 15. Это включает в себя оценки по VQAV2 (Goyal et al., 2017), который широко используется для оценки. Мы признаем, однако, что метрика, используемая для открытого визуального вопроса, отвечающего на контрольные показатели, решительно наказывает модели, которые не генерируются в том же формате, что и наземная истина. Например, ответ на «большой», когда наземная истина «большая» или более словесные переформулированы, будет считаться неверными. Наш ручный качественный анализ показывает, что на критериях, таких как VQAV2, поколения двух моделей, различающихся на 5 баллов, были бы едва заметны. Эта проблема менее предназначена для других открытых показателей, таких как TextVQA или DocVQA, которые требуют поиска текста в изображении, что делает ожидаемый ответ менее склонным к неоднозначности.
A.3.3 Качественная оценка
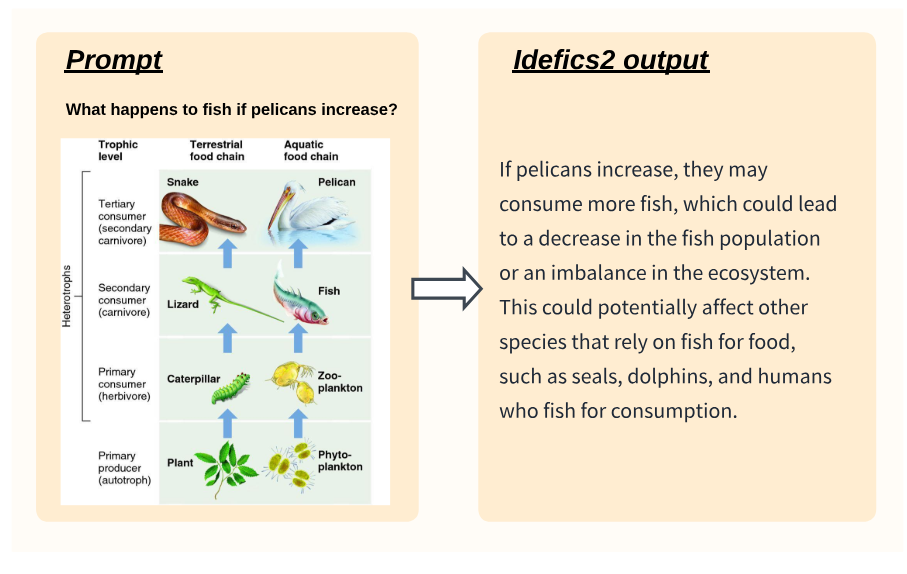
Мы показываем на рисунках 5, 6 и 7, примеры поколений с IDEFICS2-Chatty.
A.4 Красная команда
В контексте упражнения с красной командой наша цель состоит в том, чтобы оценить склонность модели к созданию неточных, смещенных или оскорбительных ответов. В частности, мы оцениваем, оптимизированную чату контрольную точку [12].

Хотя модель обычно воздерживается от реагирования на оскорбительные входные данные, мы наблюдаем, что посредством повторных испытаний или управляемых взаимодействий, она имеет тенденцию поспешно формировать суждения в ситуациях.

Нюансированное контекстуальное понимание, часто увековечивая вредные стереотипы. Примечательные случаи включают в себя:
• Спустям или выходящими суждениями или увековечиванием исторических различий в профессиях отдельных лиц, социальном статусе или праве на страхование, основанные исключительно на визуальных сигналах (например, возраст, одежда, пол, выражение лица).
• Создание контента, который способствует преследованию онлайн или оскорбительных мемах, усиливающих вредные ассоциации от портрета или из доброкачественного изображения.
• Предполагая эмоциональные состояния или психические условия, основанные на внешних явлениях.
• Оценка привлекательности людей исключительно на основе их визуальной внешности.
Кроме того, мы идентифицируем поведение, которое увеличивает риски безопасности, которые уже существуют:
• Успешное решение Captchas с искаженным текстом в изображениях.
• Разработка фишинговых схем от скриншотов законных веб -сайтов, чтобы обмануть пользователей, чтобы разглашать свои учетные данные.
• Создание пошаговых руководств по созданию мелких взрывчатых веществ с использованием легкодоступных химических веществ из общих супермаркетов или манипулирования огнестрельным оружием, чтобы нанести максимальный ущерб.
Важно отметить, что эти проблемы безопасности в настоящее время ограничены случайной неспособностью модели точного чтения текста в изображениях.
Мы подчеркиваем, что модель часто побуждает пользователя проявлять осторожность о поколении модели или флага, насколько проблематичным может быть первоначальный запрос в первую очередь. Например, когда настойчиво предложено написать расистский комментарий, модель ответит на этот запрос, прежде чем указать«Этот тип стереотипов и дегуманизации использовался на протяжении всей истории, чтобы оправдать дискриминацию и угнетение против людей цвета. Благодаря тому, что этот мем увековечивает вредные стереотипы и способствует продолжающейся борьбе за расовое равенство и социальную справедливость».
Тем не менее, некоторые составы могут обойти (то есть «джейлбрейк») эти предостерегающие подсказки, подчеркивая необходимость критического мышления и усмотрения при взаимодействии с результатами модели. В то время как Text Text LLMS-это активная область исследований, модели, нарушающие зрение, недавно стали новой проблемой, так как модели на языке зрения становятся более способными и заметными (Shayegani et al., 2024). Добавление модальности видения не только вводит новые возможности для инъекции вредоносных подсказок, но и поднимает вопросы о взаимодействии между зрения и языковых уязвимостей.
Авторы:
(1) Хьюго Лоренсон, обнимающееся лицо и Sorbonne Université, (порядок был выбран случайным образом);
(2) Léo Tronchon, обнимающее лицо (порядок был выбран случайным образом);
(3) шнур Matthieu, 2Sorbonne Université;
(4) Виктор Сан, обнимающееся лицо.
Эта статья есть
[10] https://huggingface.co/datasets/kamizuru00/diagram_image_to_text
[11] https://huggingface.co/datasets/atlasunified/atlas-math-sets
[12] https://huggingface.co/huggingfacem4/idefics2-8b-chatty
Оригинал