
Как ИИ обнаруживает рак на изображениях целых слайдов
17 июля 2025 г.Авторы:
(1) Мармим Афонсо, институт Superior Técnico, Universidade de Lisboa, Av. Ровиско Паис, Лиссабон, 1049-001, Португалия;
(2) Praphulla M.S. Bhawsar, Отдел эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Bethesda, 20850, штат Мэриленд, США;
(3) Monjoy Saha, Отделение эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Bethesda, 20850, штат Мэриленд, США;
(4) Джонас С. Алмейда, Отделение эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Бетесда, 20850, штат Мэриленд, США;
(5) Арлиндо Л. Оливейра, Институт Верхний Течнико, Университет де Лисбоа, ав. Rovisco Pais, Лиссабон, 1049-001, Португалия и INESC-ID, R. Alves Redol 9, Lisbon, 1000-029, Португалия.
Таблица ссылок
Аннотация и I. Введение
Материалы и методы
2.1. Несколько экземпляров обучения
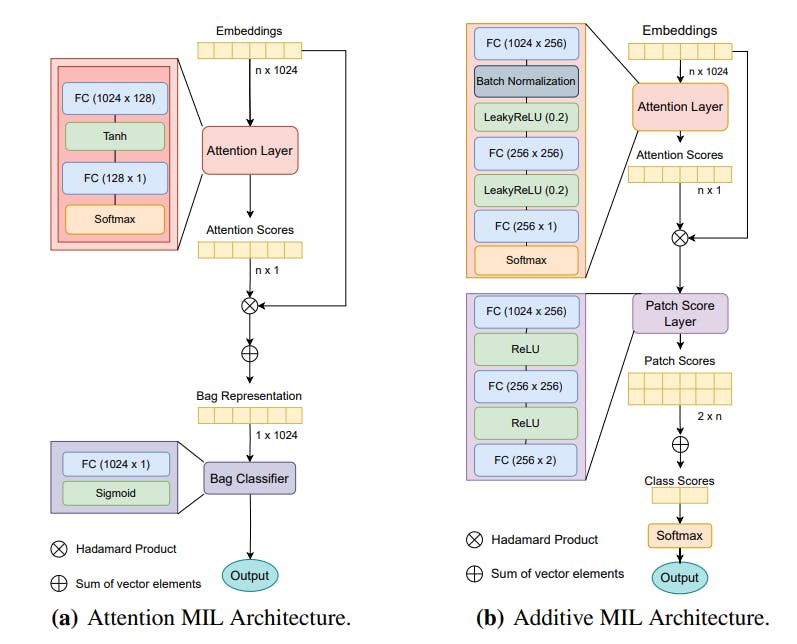
2.2. Модель архитектуры
Результаты
3.1. Методы обучения
3.2. Наборы данных
3.3. WSI предварительно обработайте трубопровод
3.4. Результаты классификации и обнаружения ROI
Дискуссия
4.1. Задача обнаружения опухоли
4.2. Задача обнаружения мутаций генов
Выводы
Благодарности
Авторская декларация и ссылки
АБСТРАКТНЫЙ
Целые слайд-изображения (WSI), полученные с помощью цифрового сканирования микроскопа с высоким разрешением в нескольких масштабах, являются краеугольным камнем современной цифровой патологии. Тем не менее, они представляют собой особую проблему для анализа на основе AI/AI-опосредованного, поскольку маркировка патологии обычно выполняется на уровне слайда, а не на уровне плитки. Дело не только в том, что медицинская диагностика регистрируется на уровне образцов, обнаружение мутации онкогена также экспериментально получено и регистрируется инициативами, такими как атлас генома рака (TCGA), на уровне слайда. Это настраивает двойную проблему: а) точно прогнозировать общий фенотип рака и б) выяснение того, какие клеточные морфологии связаны с ним на уровне плитки. Чтобы решить эти проблемы, был изучен слабо контролируемый подход с множественным экземпляром (MIL) для двух распространенных типов рака, инвазивной карциномы молочной железы (TCGA-BRCA) и плоскоклеточной карциномы легких (TCGA-LUSC). Этот подход был изучен для обнаружения опухоли при низких уровнях увеличения и мутациях TP53 на различных уровнях. Наши результаты показывают, что новая аддитивная реализация MIL соответствовала производительности эталонной реализации (AUC 0,96) и была лишь немного превосходит внимание MIL (AUC 0,97). Более интересно с точки зрения молекулярного патолога, эти различные архитектуры ИИ идентифицируют различные чувствительность к морфологическим особенностям (посредством обнаружения интересующих областей, ROI) на разных уровнях амплификации. Характерно, что мутация TP53 была наиболее чувствительной к признакам в более высоких применениях, где разрешена клеточная морфология.
1. Введение
В целом слайд -визуализация является автоматизированным процессом сканирования цифровых слайдов всего микроскопа с высоким разрешением. В ходе этого процесса изображения из каждого поля зрения в разных разрешениях взяты и объединяются вместе для создания единого цифрового файла пирамиды изображения, известного как целое изображение слайда (WSI) [5]. Этот цифровой формат, поддерживаемый рядом стандартных сериализаций, облегчает их распределение в целях диагностики, образования и исследований [3]. WSI играют решающую роль в диагностике рака [6].
Глубокое обучение было особенно успешным в приложениях для медицинской визуализации, таких как диагноз [7], классификация подтипа [13, 6] и прогноз [27]. Однако глубокое обучение WSI сталкивается с тремя основными проблемами [9]: обработка большой размерности изображения в нескольких масштабах; отсутствие сильно аннотированных данных; и, в целом, трудности, связанные с приближением к классификации с поиском информации.
Первый фактор, большое размер изображений по нескольким масштабам в пирамиде изображения WSI начинается с разрешений у основания в порядке 100 000 × 100 000 пикселей. Огромный размер затрудняет подачу изображений непосредственно в качестве ввода в модели компьютерного зрения. Чтобы преодолеть эту проблему, слайды обычно делятся на участки нескольких фиксированных размеров (также описанные как плитки), которые затем используются в качестве входных данных для моделей.
Второй фактор состоит в том, что маркировка выполняется на уровне слайда (для всего WSI, а не для отдельных плиток) или даже на уровне пациента (одна метка на пациента, которые могут иметь несколько слайдов). Экспертная маркировка на уровне пикселей будет дорогостоящей и утомительной для патолога. Аннотации на уровне пикселей, полностью восстановленные подходы не могут быть непосредственно использованы, и вместо этого требуются слабо подключенные [23, 7, 12] или не контролируются [15, 21] подходы, такие как многочисленное обучение экземпляров, MIL [2], используемые в работе, сообщаемое здесь.
Наконец, может быть сложно получить соответствующую информацию о патологии из относительно неструктурированных клинических отчетов. Как следствие, интерпретируемость интересующих регионов (ROI), определенных моделями глубокого обучения, часто плохой до такой степени, что попытка объяснения на уровне морфологии можно рассматривать только как исследовательское упражнение. Тем не менее, подход, представляющий интересы, где наблюдаются повторяющиеся морфологические паттерны, является знакомой процедурой в цифровой патологии, где иногда его описывают как «виртуальное окрашивание». Соответственно, в работе, описанной здесь, мы «окрашиваем» сырые изображения с помощью тепловых карт, произведенных с использованием глубоких результатов активации.
2. Материалы и методы
2.1. Несколько экземпляров обучения
Многократное обучение (MIL) [2] - это слабо контролируемый подход к обучению, где экземпляры сгруппированы в наборы, называемые мешками. Метка назначена всей сумке, в то время как отдельные этикетки экземпляра остаются неизвестными. В стандартном определении MIL используется мешок экземпляров как 𝑋 = {𝑥1, ..., 𝑥𝐾}, который не имеет и не зависит и не упорядочивает друг друга. Мы также предположим, что размер сумки K может варьироваться для разных мешков. Для каждой сумки 𝑋 есть двоичная метка 𝑌 ∈ {0,1}. Каждый экземпляр в сумке имеет метку 𝑦𝑖, где 𝑦𝑖 ∈ {0,1}. Тем не менее, отдельные этикетки экземпляра неизвестны и недоступны во время обучения. Таким образом, проблема MIL может быть написана как следующее:

Другими словами, мы предполагаем, что все негативные сумки содержат только негативные экземпляры, и что положительные сумки содержат хотя бы один положительный экземпляр. Чтобы классифицировать сумку как позитивную, мы должны рассматривать только один экземпляр положительным.
Это стандартное предположение также утверждает, что модели должны быть инвариантными перестановки (нет порядка и зависимости среди экземпляров). Более конкретно, ему нужен оператор агрегации, который является инвариантом перестановки, обычно называемый оператором объединения MIL.
В более общем смысле модель MIL для классификации сумок может быть выражена 3-ступенчатым процессом [7]:
• преобразование экземпляров с функцией 𝑓;
• Инвариантная функция перестановки 𝜎, которая объединяет все преобразования экземпляров в окончательное представление сумки;
• Окончательное преобразование 𝑔, которое получает представление сумки и выводит окончательный счет сумки.
В случае анализа WSI мы можем рассматривать каждый слайд как сумку, которая содержит несколько пятен в качестве экземпляров. У нас есть этикетки на уровне слайда (метка сумки), но у нас нет ярлыков на уровне пикселя/патча (этикетки экземпляра).
Чтобы обеспечить некоторую степень интерпретации, а также лучшие результаты, изменение механизма внимания может использоваться в качестве оператора объединения MIL. Поскольку он действует как средневзвешенные экземпляры, первоначальное определение может быть адаптировано как инвариантное перестановку, что делает его действительным оператором объединения MIL. Эти оценки внимания могут использоваться для создания тепловой карты, которая позволяет интерпретировать, какие части изображения несут ответственность за окончательную классификацию. Было несколько работ, которые использовали вариации механизма внимания с структурой MIL, чтобы достичь этого [4, 6, 10, 11, 12, 13, 14, 19, 25, 26].
Эта статья есть
Оригинал