

Сезон отпусков: прогнозирование и преодоление высокой нагрузки в бизнесе — работа с непредвиденными аномалиями
11 января 2023 г."Эти праздничные дни - еще один повод поплакать..." n - (лучшая рождественская песня)
Содержание
- Как праздники влияют на людей и бизнес.
- Можно ли справиться с высокой нагрузкой и свести к минимуму ее влияние?
- Как получить точные прогнозы для высокой нагрузки и нужны ли нам точные цифры?
- Какого размера поля достаточно?
- Аномалии: как предсказать непредсказуемое?
- Пример: сборка критериев аномалий и системы оповещений
- Заключение
Как праздники влияют на людей и бизнес
Большинство людей хотя бы раз в жизни застряли в пробке, пытаясь купить последние рождественские подарки, или не смогли позвонить друзьям в канун Нового года из-за высокой нагрузки на мобильную сеть.
Курортный сезон (время радости и праздника) обычно приносит повышенную нагрузку на различные стороны жизни. Это особенно заметно в таких областях, как путешествия, почтовые услуги и банковское дело, поскольку спрос на эти услуги выше из-за увеличения числа людей, путешествующих и отправляющих подарки.

Высокая нагрузка может привести к задержкам, перегрузкам и другим проблемам, которые могут стать источником стресса для отдельных лиц и компаний.
Компаниям приходится прилагать больше усилий, чтобы удовлетворить растущий спрос на их продукты или услуги.
Неспособность терпеть более высокое давление может привести к разочарованию клиентов и негативно сказаться на имидже компании.
Это может быть особенно вредно для компаний, которые напрямую полагаются на положительный опыт клиентов для увеличения продаж и привлечения новых клиентов, но это также влияет на продукты B2B.
Когда поставщику может потребоваться интенсифицировать производство и распространение продукции, поставщику услуг приходится сталкиваться с увеличением количества операций.
Можно ли справиться с высокой нагрузкой и свести к минимуму ее влияние?
Если бы это было невозможно, я бы не писал эту статью. На протяжении многих лет предприятия всех размеров — от небольших пекарен до крупных производственных компаний — изучают, как спрос меняется во времени (тенденции) и периодически (сезонность).
Например, в пекарне ко Дню святого Валентина может быть больше тортов в форме сердечек.
Чтобы подготовиться к более высокому объему производства, предприятия вводят масштабирование всех видов: увеличение численности персонала (например, наем сезонных рабочих), оплачиваемая сверхурочная работа, предварительное производство товаров и перемещение критически важных программных сервисов в облака, которые поддерживают автоматическое масштабирование из коробки. .
Но чтобы активировать масштабирование, бизнесу нужны прогнозы и т. д.
Как получить точные прогнозы высокой нагрузки и нужны ли нам точные цифры?
Специалисты анализируют мировые тенденции, проводят социальные исследования и опираются на исторические данные. Однако не существует известного метода, который даст точный прогноз. Реальный мир слишком сложен, и невозможно учесть все факторы и включить их в какую-либо модель.
Хотя ручная обработка данных требует много времени и не очень точна, современные компании склонны полагаться на методы машинного обучения (МО) для решения этой задачи.
Им необходимо определить целевое значение (или несколько значений) для прогнозирования: спрос на продукты или услуги, трафик на веб-сайте или платформе социальных сетей или количество обращений в службу поддержки клиентов. Затем они решают задачу прогнозирования временных рядов.
Я не буду описывать в этой статье подходы к прогнозированию временных рядов (применимы все стандартные методики), но выделю, что в них особенного, когда нас интересует высокая нагрузка как более узкий класс задач.
Главное, во многих случаях нам не нужны точные цифры. Понимание будет скорее «будем ли мы в этот день/неделю видеть высокий спрос или нет», а не «какое точное количество клиентов мы ожидаем» — скорее пометка факта высокой нагрузки и ее степени, чем получение точного числа.
Например, если компании нужно подготовиться к фестивалю под открытым небом в маленьком городе, который, как ожидается, привлечет большое количество посетителей, важно знать, будет ли высокий спрос на гостиничные номера, и спланировать это соответствующим образом.
Однако трудно предсказать точное количество посетителей, так как многие принимают решения в последнюю минуту, на которые влияют такие факторы, как погода.
Когда речь идет о программных приложениях, нагрузка часто сопоставляется с несколькими серверами (узлами) с включенными большими запасами, поэтому ресурсы не всегда используются полностью. Это позволяет более эффективно использовать ресурсы, а когда требуется новая машина, решение принимается детально.
Будь то потребность в машинах 0,05 или 0,7, это все равно означает выделение дополнительного узла.
Ключевой принцип машинного обучения остается неизменным: используйте самую простую модель, которая дает достаточные результаты для конкретной задачи.
Какого размера поля достаточно?
Несмотря на то, что компании могут реализовывать резервные планы для покрытия потенциального увеличения спроса, это также увеличивает расходы. Если ресурсы не используются, это также влияет на доход.
Вот почему важно, чтобы прогноз был как можно более точным и учитывал разницу между чрезмерно оптимистичным и чрезмерно пессимистичным прогнозом.
Например, представьте себе небольшой газетный киоск, который обычно продает около 100 газет в день. Обычным прогнозом было бы 100. Но владелец знает, что, основываясь на новостях и других спорадических факторах, он иногда может продать больше товаров, и он не хочет терять своих клиентов.
Так, при оптимистическом подходе (если прогноз достаточно точен) он добавляет 5 %, а при пессимистическом – 10 %.
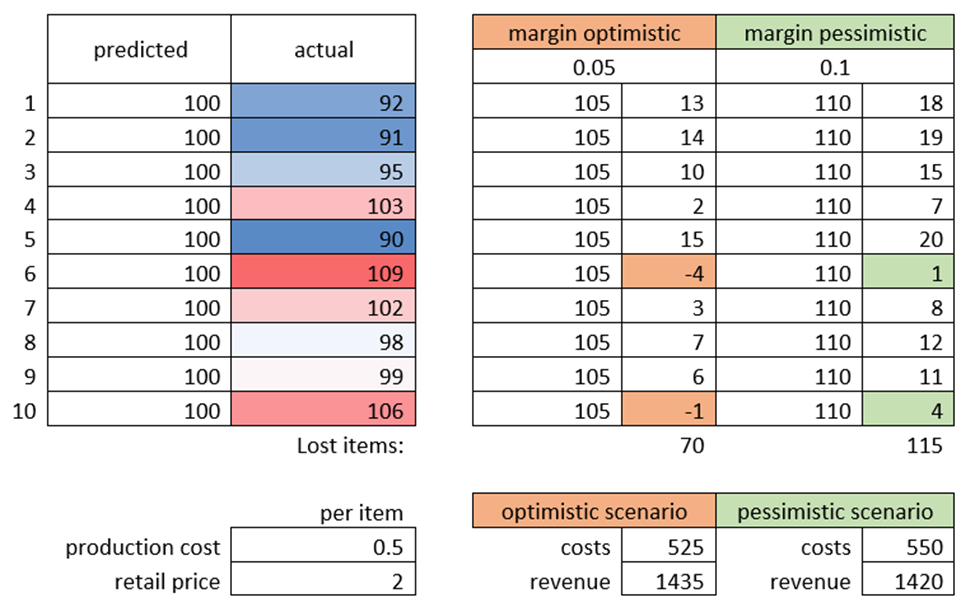
Глядя на расчеты, мы видим, что оптимистичный подход приносит больший доход — меньше бумаги перерабатывается, но всего 5 недовольных клиентов (на 6-й и 10-й день).
В случае с газетами имеет смысл максимизировать доход — возможно, покупатели опоздали и не рассчитывали купить газету, поэтому они не так расстроились.
Но если мы говорим о банке или больнице, а не о газетном киоске, ущерб от невозможности обрабатывать большее количество транзакций или пациентов имеет решающее значение, и руководство, вероятно, согласится на более высокие расходы.
При определении маржи важно учитывать характер бизнеса, стоимость перепроизводства и стоимость неудовлетворения спроса. Маржа — это баланс, и его нужно настраивать в каждом конкретном случае.
Аномалии: как предсказать непредсказуемое?
Предположим, что мы построили модель, которая в большинстве случаев дает достоверные прогнозы, включая общие тенденции, сезонные, еженедельные и ежедневные изменения, и компания разработала меры для работы с высокой нагрузкой и даже имеет планы на случай непредвиденных обстоятельств. для устранения аномалий.
Но как мы обнаруживаем такие аномалии?
Если бизнес сможет заметить это достаточно рано, компания сможет минимизировать негативное влияние высокой нагрузки и поддерживать высокий уровень обслуживания своих клиентов. Для этого мы можем сравнить прогнозируемые данные с данными в реальном времени, поступающими с поля.
При наличии значительного несоответствия может быть активировано оповещение и активизированы упреждающие меры либо автоматически, либо с помощью вмешательства человека.
Пример: сборка системы критериев аномалий и оповещений
Однажды я работал в компании B2B*, которая обрабатывала миллионы запросов в день, при этом один этап обработки выполнялся как ночная работа, которая обычно заканчивалась до того, как пользователи снова активизировались утром.
Однако однажды ночью он дал сбой, обработав только около 60% запросов, что привело к серьезным проблемам на утро и дополнительным затратам на смягчение последствий. К счастью, было быстро реализовано специальное решение, предохранившее репутацию компании от любого ущерба.
Но урок был усвоен. Компания хотела изучить ситуацию и убедиться, что у нее есть механизмы для активации предупреждений, как только будет обнаружена небольшая аномалия, чтобы снизить риски в будущем.
Для этого мы собрали набор данных, агрегировав номера транзакций за последние 10 лет с момента запуска продукта в производство. Выполнив исследовательский анализ данных (EDA), мы обнаружили еженедельные закономерности, тенденцию и явный выброс 17 апреля 2022 года.
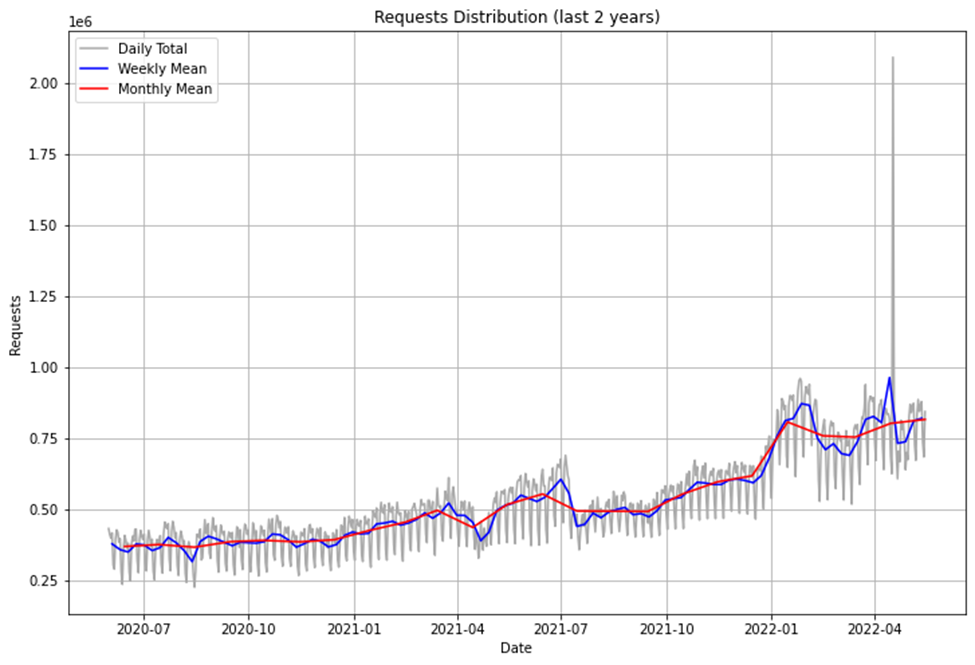
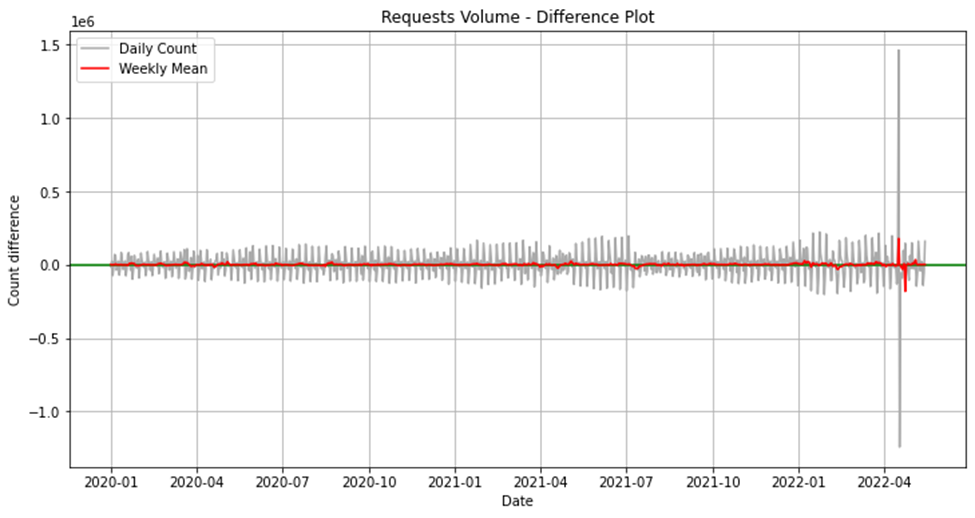
Дневной объем был примерно в 2,5 раза выше, чем максимальное значение за прошлые периоды. Такое отклонение сильно повлияло бы на точность модели; поэтому важно определить, можно ли это объяснить естественным образом и можно ли предсказать.
65% запросов в тот день были связаны с нулевой суммой денег. Когда мы копнули глубже, мы обнаружили, что разница была вызвана одним бизнес-пользователем, который по ошибке запрашивал прошлые данные для каждого запроса.
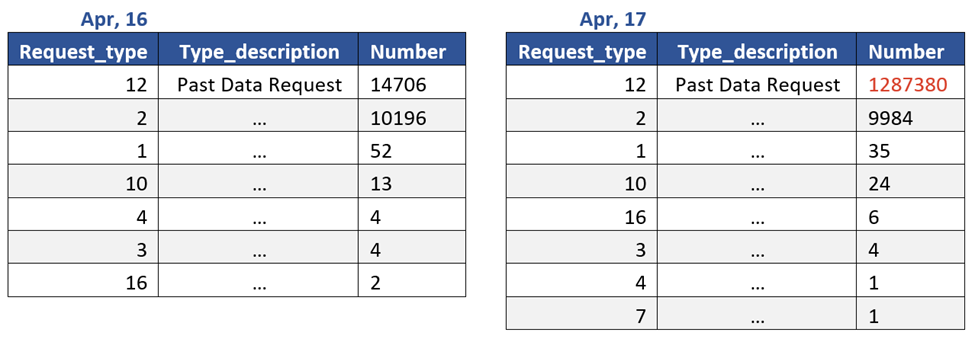
Итак, был сделан вывод: это была настоящая аномалия, вызванная непредсказуемым внешним фактором — идеальный кандидат для задачи раннего обнаружения аномалии.
Поскольку компания заинтересована в том, чтобы узнать общее количество запросов за день, которые должны быть обработаны сегодня вечером, и знать, намного ли фактические цифры превышают прогнозируемые, я предложил разделить день на почасовые сегменты и сравнить прогнозируемые запросы для каждого сегмента.
Сделав это, мы преобразовали проблему в многоцелевую регрессию и предсказали число для каждого часа дня. Это позволило нам сравнивать числа в течение дня и выявлять любые несоответствия к концу дня с точностью до мельчайших деталей.
Для проверки гипотезы мы разбили день на четыре части:
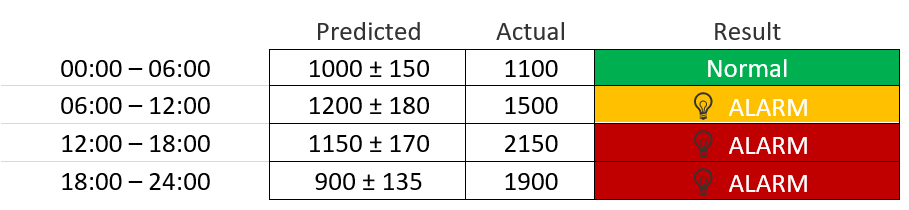
Когда мы построили модель, стандартное отклонение (стандартное отклонение) относительной ошибки не превышало 3,4 % для частей дня и 5 % для всего дня.
Распределение ошибок было близко к нормальному, поэтому для формулировки критериев аномалии было естественным применить правило трех сигм: если разница между прогнозируемым и фактическим числом превышает 3 стандартных отклонения, срабатывает оповещение.
Когда мы тестировали этот критерий для 17 апреля, мы заметили, что тревога срабатывала бы уже в 6 утра, когда подсчитывались запросы на первые корзины.
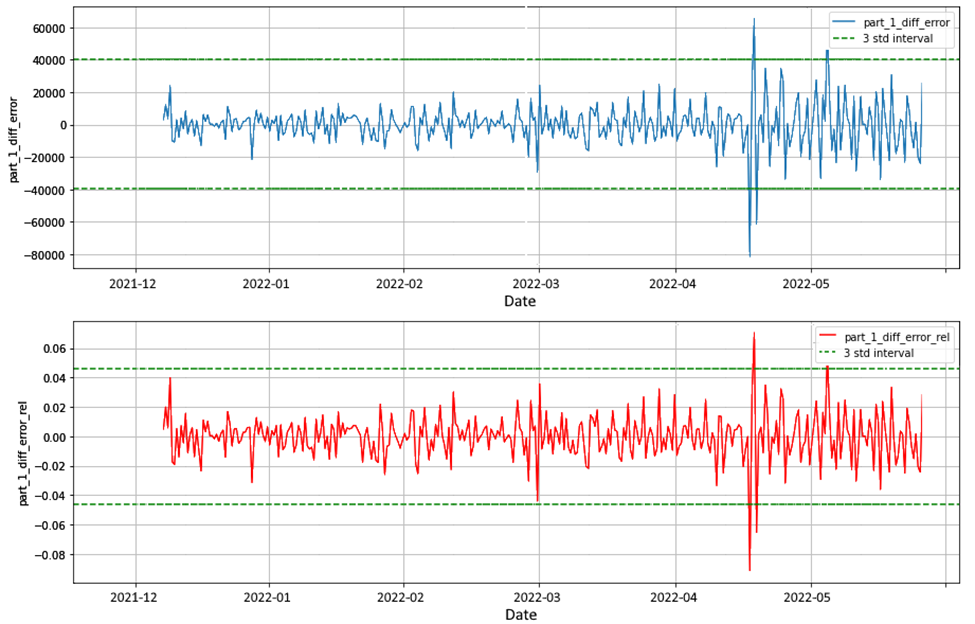
Системы мониторинга могут поддерживать события разного уровня серьезности, такие как предупреждение о несоответствии, превышающем 2 сигмы, и критическое оповещение о нарушении 3 стандартных отклонений.
Поскольку система работает ежедневно, а сегменты позволяют масштабировать ее, это добавляет уровень раннего обнаружения и повышает способность компании реагировать на непредвиденные события в режиме реального времени.
Предлагаемые критерии являются лишь примером и должны применяться для конкретных бизнес-сценариев в зависимости от характера данных. Однако описанный подход также можно применять для обнаружения низкой нагрузки, рассматривая отклонения в отрицательном направлении.
Например, в розничной торговле многие офлайн-магазины закрыты в праздничные дни, а доставка из интернет-магазинов может не работать в канун Нового года, что может повлиять на загрузку складов и количество людей, необходимых для работы в эти дни.
Заключение
В заключение, несмотря на то, что сложно предсказать высокую нагрузку со 100% точностью, компании могут использовать данные и методы машинного обучения для создания моделей, которые могут прогнозировать периоды высокой нагрузки и готовиться к ним, настраивать раннее обнаружение аномалий и тем самым значит минимизировать негативное воздействие и поддерживать высокое качество обслуживания своих клиентов.
*Название компании опущено из соображений конфиденциальности, а реальные данные изменены
Оригинал