

Использование GPT-3 для улучшенных поисковых решений
14 апреля 2023 г.Современные приложения часто включают поисковые решения, позволяющие пользователям быстро получать доступ к существующему контенту по запросу. Трудно представить себе какие-либо другие функции, которые могли бы эффективно извлекать эту информацию, поэтому поиск является важной функцией в большинстве приложений.
Индивидуальные варианты поискового решения
В то же время, даже если потребность в запросе и поиске очень распространена, разные приложения используют совершенно разные подходы.
В большинстве случаев компании остаются на самом базовом уровне поиска, просто напрямую запрашивая базы данных OLTP. Запросы могут выглядеть так: SELECT id, title FROM, entity WHERE, description LIKE ‘%bow%.
Однако чаще они представлены сложными, многоуровневыми структурами соединения таблиц, нечитаемыми, медленными и примитивными. Они не способны понять контекст, требуют многочисленных настроек и очень сложны для правильной реализации.
Хотя можно сократить время выполнения запроса с помощью материализованных представлений, кэширования запросов и других методов, дополнительная сложность приводит к значительному отставанию между первичными обновлениями и согласованными результатами поиска.

Более эффективными альтернативами примитивным поисковым решениям на основе БД могут быть поисковые системы с открытым исходным кодом, такие как Apache Lucene, Apache Solr, Elasticsearch, Sphinx, MeiliSearch, Typesense и т. д.
Они, как правило, сравнительно быстрее и намного лучше справляются со сложными запросами и работают с фильтрами. Но как только эти поисковые системы сравниваются с аналогами, такими как Google Search или DuckDuckGo, становится ясно, что решения с открытым исходным кодом не справляются с построением правильного поиска. контекст и модальности запроса — они не способны понять запрос, если пользователь предоставляет нечеткий поисковый запрос.
Извлечение значения из запроса

Представьте, вы просто не можете вспомнить, как называются эти желтые цитрусовые с кисловатым вкусом! Но вы хотите найти в приложении статью о том, как вырастить этот загадочный фрукт. Как вы относитесь к этому поиску?
Ваш вопрос может звучать так: «Как вырастить желтый кислый цитрус в помещении». Любая из вышеупомянутых поисковых систем с открытым исходным кодом может столкнуться со значительными трудностями при выдаче релевантных результатов по этому запросу, даже если в базе данных есть статьи о выращивании «лимонов».
Это связано с тем, что извлечение смысла из запроса является задачей естественного языка и вряд ли будет решено без компонентов ИИ. GPT-3 хорошо справляется с этой задачей.
OpenAI предлагает API встраивания на основе GPT-3, который преобразует текст на естественном языке в вектор чисел с плавающей запятой. Вложение — это, по сути, низкоразмерное пространство, в которое можно перевести многомерные векторы. В этом случае многомерный вектор — это текст, а низкоразмерный — выходной вектор фиксированного размера. Расстояние между векторами показывает, насколько сильно они коррелируют. Чем меньше расстояние, тем выше корреляция. Переопределив текст как векторную форму, задача сводится к классической проблеме поиска машинного обучения.
Выбор правильной модели
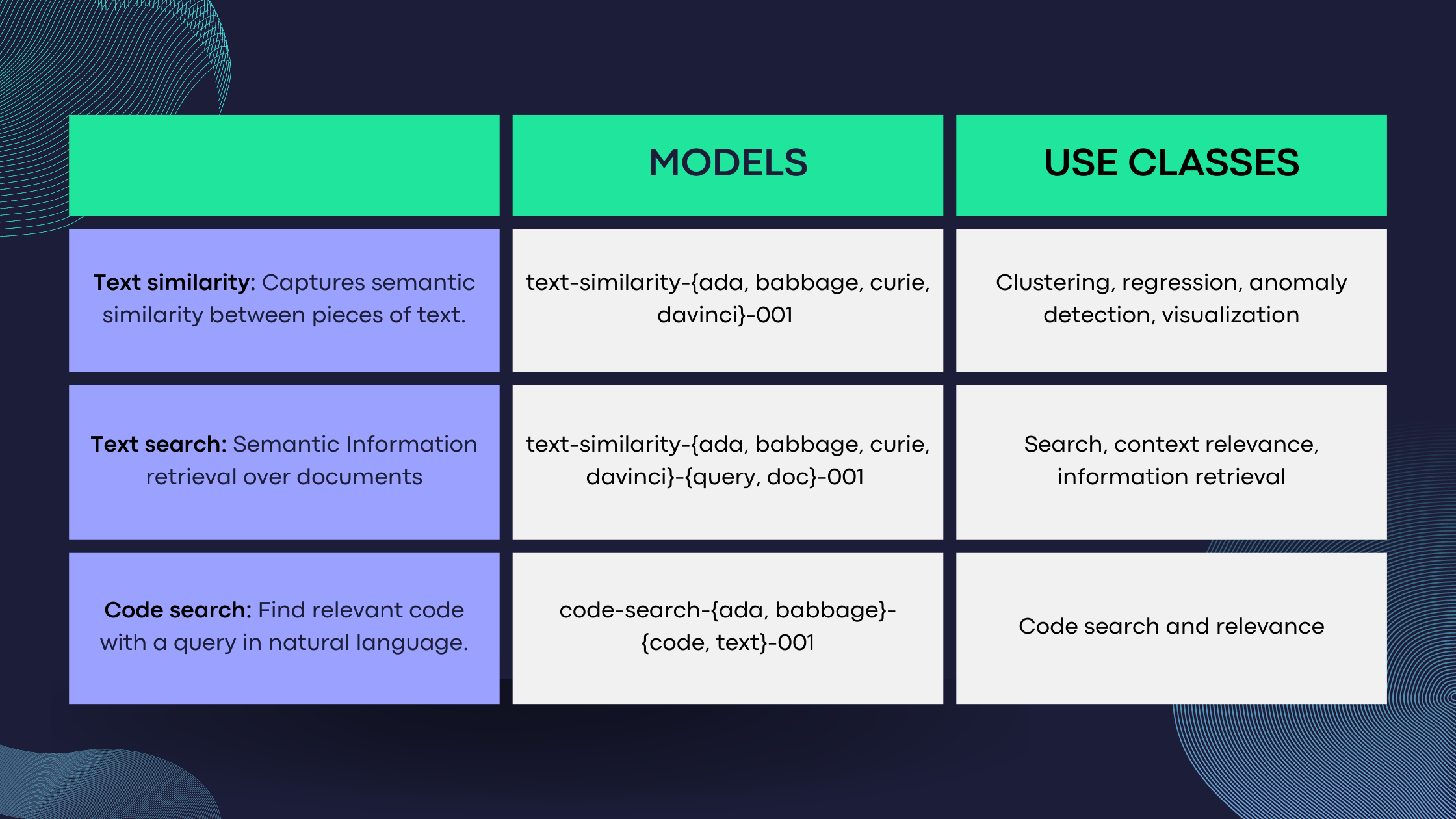
Преобразование текста документа в представление вектора может происходить в фоновом режиме, тогда как векторизация поискового запроса должна выполняться во время выполнения. OpenAI предлагает несколько семейств моделей GPT-3:
text-search-ada-doc-001: 1024
text-search-babbage-doc-001: 2048
text-search-curie-doc-001: 4096
text-search-davinci-doc-001: 12288
Более высокие размеры вектора приводят к большему объему встроенной информации и, следовательно, к более высоким затратам и более медленному поиску.
Документы обычно длинные, а запросы короткие и неполные. Таким образом, векторизация любого документа существенно отличается от векторизации любого запроса с учетом плотности и размера содержимого. OpenAI знает об этом, поэтому предлагает две парные модели: -doc и -query: n
text-search-ada-query-001: 1024
text-search-babbage-query-001: 2048
text-search-curie-queryc-001: 4096
text-search-davinci-query-001: 12288
n Важно отметить, что запрос и документ должны использовать одно и то же семейство моделей и иметь одинаковую длину выходного вектора.
Пример набора данных
Возможно, проще всего увидеть и понять возможности этого поискового решения на примерах. Для этого примера возьмем набор данных фильмов TMDB 5000, который содержит метаданные примерно о 5000 фильмов с TMDb. Мы создадим решение для поиска, опираясь только на документы фильмов, а не обзоры.
Набор данных содержит множество столбцов, но наш процесс векторизации будет построен только вокруг столбцов заголовка и обзора. п
Пример записи:
Title: Harry Potter and the Half-Blood Prince
Overview: As Harry begins his sixth year at Hogwarts, he discovers an old book marked as
‘Property of the Half-Blood Prince’, and begins to learn more about Lord Voldemort’s dark past.
Преобразуем набор данных в готовый к индексации текст:
datafile_path = "./tmdb_5000_movies.csv"
df = pd.read_csv(datafile_path)
def combined_info(row):
columns = ['title', 'overview']
columns_to_join = [f"{column.capitalize()}: {row[column]}" for column in columns]
return 'n'.join(columns_to_join)
df['combined_info'] = df.apply(lambda row: combined_info(row), axis=1)
Процесс встраивания прост:
def get_embedding(text, model="text-search-babbage-doc-001"):
text = text.replace("n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
get_embedding(df['combined_info'][0])
n Этот блок кода выводит список, размер которого равен параметрам, с которыми работает модель, что в случае text-search-babbage-doc-001 равно 2048 .
Аналогичный процесс встраивания следует применять ко всем документам, в которых мы хотели бы выполнить поиск:
df['combined_info_search'] = df['combined_info'].apply(lambda x: get_embedding(x, model='text-search-babbage-doc-001'))
df.to_csv('./tmdb_5000_movies_search.csv', index=False)
Столбец combined_info_search будет содержать векторное представление комбинированного_текста.
И, что удивительно, это уже все! Наконец, мы готовы выполнить пример поискового запроса:
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_movies(df, query, n=3, pprint=True):
embedding = get_embedding(
query,
engine="text-search-babbage-query-001"
)
df["similarities"] = df.combined_info_search.apply(lambda x: cosine_similarity(x, embedding))
res = (
df.sort_values("similarities", ascending=False)
.head(n)
.combined_info
)
if pprint:
for r in res:
print(r[:200])
print()
return res
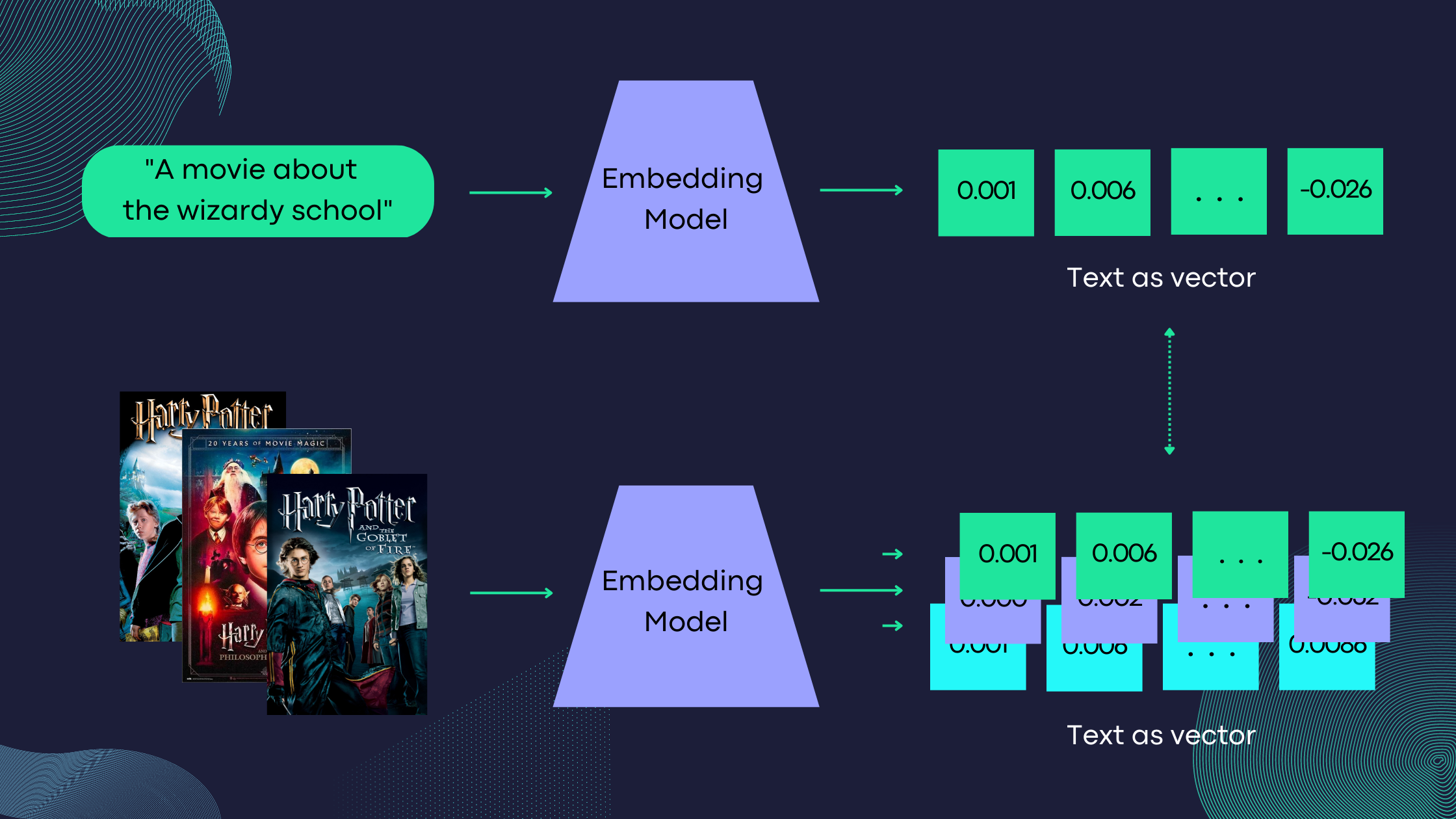
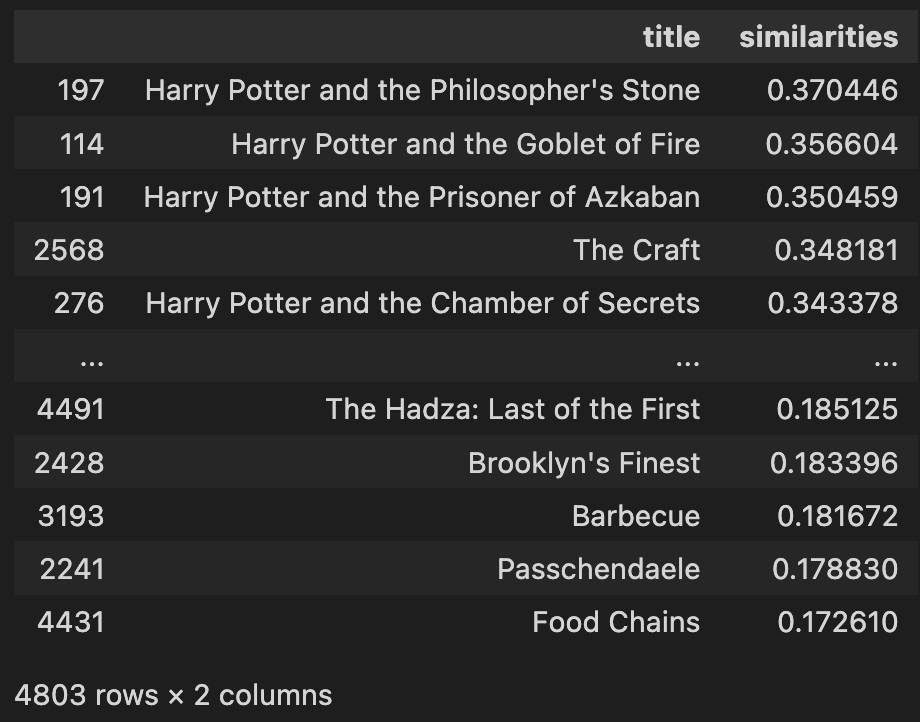
res = search_movies(df, "movie about the wizardry school", n=3)
Вот какие результаты мы получаем:
Title: Harry Potter and the Philosopher’s StoneOverview: Harry Potter has lived under the stairs at his aunt and uncle’s house his whole life. But on his 11th birthday, he learns he’s a powerful wizard — with a place waiting for him at the Hogwarts School of Witchcraft and Wizardry. As he learns to harness his newfound powers with the help of the school’s kindly headmaster, Harry uncovers the truth about his parents’ deaths — and about the villain who’s to blame.
Title: Harry Potter and the Goblet of FireOverview: Harry starts his fourth year at Hogwarts, competes in the treacherous Triwizard Tournament and faces the evil Lord Voldemort. Ron and Hermione help Harry manage the pressure — but Voldemort lurks, awaiting his chance to destroy Harry and all that he stands for.
Title: Harry Potter and the Prisoner of AzkabanOverview: Harry, Ron and Hermione return to Hogwarts for another magic-filled year. Harry comes face to face with danger yet again, this time in the form of an escaped convict, Sirius Black — and turns to sympathetic Professor Lupin for help.
В обзоре фильма «Гарри Поттер и философский камень" есть слова "волшебство" и "школа". и занимает первое место в результатах поиска. Второй результат уже не содержит слова «школа», но по-прежнему сохраняет слова, близкие к «волшебству», «трехволшебнику». Третий результат содержит только синоним «волшебства» — магия.
Конечно, в этой базе данных есть множество других фильмов, в которых фигурируют школы или волшебники (или и то, и другое), но вышеперечисленные были единственными, возвращенными нам. Это явное доказательство того, что поисковое решение работает и действительно понимает контекст нашего запроса.
Мы использовали модель Бэббиджа всего с 2048 параметрами. Davinci имеет в шесть раз больше (12 288) параметров и, таким образом, может значительно лучше работать с очень сложными запросами.
Поисковое решение может иногда не выдавать результаты, релевантные некоторым запросам. Например, запрос «фильмы о волшебниках в школе» дает:
Title: Harry Potter and the Philosopher’s StoneOverview: Harry Potter has lived under the stairs at his aunt and uncle’s house his whole life. But on his 11th birthday, he learns he’s a powerful wizard — with a place waiting for him at the Hogwarts School of Witchcraft and Wizardry. As he learns to harness his newfound powers with the help of the school’s kindly headmaster, Harry uncovers the truth about his parents’ deaths — and about the villain who’s to blame.
Title: Dumb and Dumberer: When Harry Met LloydOverview: This wacky prequel to the 1994 blockbuster goes back to the lame-brained Harry and Lloyd’s days as classmates at a Rhode Island high school, where the unprincipled principal puts the pair in remedial courses as part of a scheme to fleece the school.
Title: Harry Potter and the Prisoner of AzkabanOverview: Harry, Ron and Hermione return to Hogwarts for another magic-filled year. Harry comes face to face with danger yet again, this time in the form of an escaped convict, Sirius Black — and turns to sympathetic Professor Lupin for help.
Вы можете задаться вопросом, что здесь делает «Тупой и еще тупее: Когда Гарри встретил Ллойда»? К счастью, эта проблема не воспроизводилась для параметров с большим количеством параметров. п
Вычисление расстояния между запросом и документами
Вывод результатов поиска должен состоять из документов, отсортированных в порядке убывания релевантности. Для этого мы должны знать расстояние между текущим запросом и каждым документом. Чем короче длина, тем более релевантный вывод. Затем, после определенного максимального охвата, мы должны перестать рассматривать релевантность оставшихся документов.
В вышеупомянутом примере для расчета расстояния, высокой размерности векторного пространства. В модели Бэббиджа у нас есть 2048 параметров.
Алгоритмы расчета расстояния, как правило, представляют это сходство (различие) между запросом и документом с помощью одного номера. Однако мы не можем полагаться на евклидово расстояние из-за проклятие размерности — расстояния будут слишком похожими. Это связано с тем, что евклидово расстояние становится крайне непрактичным за пределами семи измерений — в этот момент расстояния попадают в одни и те же области и становятся почти идентичными.
Если вы хотите, вы можете проверить полученный репозиторий здесь:
https://github.com/weblab-technology/gpt3-embeddings-movies -search?embedable=true
Кроме того, вы можете поиграть с ним в Google Colab здесь.
Временная сложность
Для сортировки документов мы использовали метод грубой силы. Давайте определим:
● n: количество точек в наборе обучающих данных
● d: размерность данных
Сложность времени поиска решений грубой силы составляет O(n * d * n * log(n)). Параметр d зависит от модели (в случае Бэббиджа он равен 2048), а у нас блок O(nlog(n)) из-за шага сортировки.
На этом этапе очень важно напомнить себе, что модели меньшего размера быстрее и дешевле. Например, на этапе расчета схожести вариантов поиска модель Ада работает в два раза быстрее, а модель Давинчи — в шесть раз медленнее.
Вычисления сходства косинуса между запросом и 4803 документами 2048 размеров заняли на моем M1 Pro 1260 мс. В текущей реализации время, необходимое для расчета, будет линейно увеличиваться в зависимости от общего количества документов. Одновременно этот подход поддерживает распараллеливание вычислений.
Альтернативы грубой силы
В поисковых решениях запросы должны выполняться как можно быстрее. И эта цена обычно оплачивается за время обучения и предварительного кэширования. Мы можем использовать структуры данных, такие как дерево k-d, r-дерево или шаровое дерево. Обратите внимание на статью Towards Data Science об анализе вычислительной сложности эти методы: все они приводят к вычислительной сложности, близкой к O(k * log(n)), где k — количество элементов, которые мы хотели бы вернуть в течение одного партия.
Деревья K-d, шаровые деревья и r-деревья представляют собой структуры данных, которые используются для хранения и эффективного поиска точек в N-мерном пространстве, таких как наши вектора значений.
K-d и шаровые деревья представляют собой древовидные структуры данных, которые используют итеративную бинарную схему разбиения для разделения пространства на регионы, где каждый узел в дереве представляет подрегион. Деревья K-d особенно эффективны при поиске точек в определенном диапазоне или поиске ближайшего соседа к заданной точке.
Точно так же r-деревья также используются для хранения точек в N-мерном пространстве, однако они гораздо более эффективны при поиске точек в определенной области или нахождении всех точек в пределах определенного расстояния от заданной точки. Важно отметить, что r-деревья используют схему разделения, отличную от k-d деревьев и шаровых деревьев; они делят пространство на «прямоугольники», а не на двоичные разделы.
Реализация дерева выходит за рамки этой статьи, и разные реализации приведут к разным результатам поиска.
Время запроса
Возможно, наиболее существенным недостатком текущего решения для поиска является то, что мы должны вызывать внешний API OpenAI для получения вектора внедрения запроса. Независимо от того, насколько быстро наш алгоритм сможет найти ближайших соседей, потребуется последовательный шаг блокировки.
Text-search-babbage-query-001
Number of dimensions: 2048
Number of queries: 100
Average duration: 225ms
Median duration: 207ms
Max duration: 1301ms
Min duration: 176ms
Text-search-ada-query-002
Number of dimensions: 1536
Number of queries: 100
Average duration: 264ms
Median duration: 250ms
Max duration: 859ms
Min duration: 215ms
Text-search-davinci-query-001
Number of dimensions: 12288
Number of queries: 100
Average duration: 379ms
Median duration: 364ms
Max duration: 1161ms
Min duration: 271ms
Если мы возьмем медиану в качестве точки отсчета, мы увидим, что ada-002 медленнее на +28%, а davinci-001 медленнее на +76%.
Ограничения встраивания в поиск GPT-3
Ссылаясь на Статья Нильса Реймера о сравнении моделей встраивания плотного текста, мы можем сделать вывод, что GPT-3 не обеспечивает исключительную производительность или качество вывода и требует зависимости от внешнего API, который довольно медленный. GPT-3 может поддерживать ввод до 4096 токенов (примерно 3072 слова), однако через API нет службы усечения, и попытка закодировать текст длиннее 4096 токенов приведет к ошибке. Таким образом, пользователь — вы — несете ответственность за определение того, какой объем текста может быть закодирован на самом деле.
Кроме того, затраты на обучение OpenAI относительно высоки.
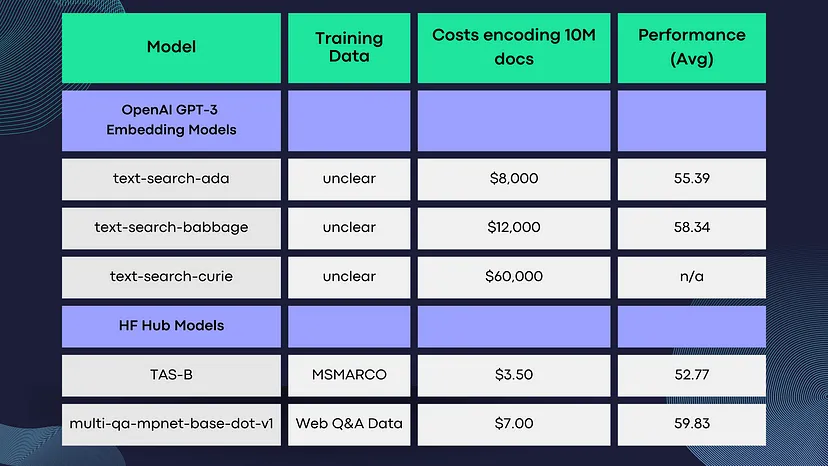
В качестве альтернативы вы можете попробовать TAS-B или multi-qa-mpnet-base-dot-v1.
Приблизительный поиск ближайшего соседа в Elasticsearch
Elasticsearch 8.0 поддерживает эффективный приближенный поиск ближайшего соседа (ANN), который можно использовать для решения наших задач быстрее, чем любой линейный KNN. Elasticsearch 8.0 использует алгоритм ИНС, называемый иерархическими навигационными графами малого мира (HNSW), для организации векторов в графы на основе сходства. Протестировав набор данных из 10 миллионов встроенных векторов, мы добились впечатляющей производительности в 200 запросов в секунду с помощью ANN на одной вычислительной машине и всего 2 запроса в секунду с использованием KNN. Оба предоставлены Elasticsearch.
Согласно сообщению в блоге ElasticSearch о выпуске ANN и эталоном для плотного векторного поиска< /strong> стоимость этого выступления составляет 5% отзыва. Это означает, что примерно 1 из 10 найденных ближайших векторов не являются действительно относительными. Мы применили гибридный подход, чтобы улучшить этот результат: запросить k+l вместо k и применить фильтрацию для удаления выбросов. К сожалению, нет возможности пагинации. Таким образом, этот подход будет работать только в некоторых случаях.
Как вы, надеюсь, заметили, GPT-3 Embeddings не является идеальным решением для любых проблем поиска из-за его сложности индексации, стоимости, а также высокой вычислительной сложности операции поиска, даже приближенных. Тем не менее, GPT-3 Embeddings остается отличным выбором для тех, кто ищет мощную основу для поискового решения с нечастыми запросами и скромными требованиями к индексированию.
Более того, стоит также добавить, что Microsoft недавно __объявило __, что поисковая система Bing теперь использует новую обновленную версию GPT 3.5 под названием Prometheus, изначально разработанную для поиска. Согласно объявлению, новая языковая модель Prometheus позволяет повысить релевантность Bing, более точно аннотировать фрагменты, предоставлять более свежие результаты, понимать геолокацию и повышать безопасность. Это может открыть новые возможности для использования авторегрессионной языковой модели для поисковых решений, за которыми мы обязательно будем следить в будущем. п
Ссылки:
- Новая и улучшенная модель встраивания
- вычислительная сложность k ближайших соседей
- scipy.spatial.KDTree
- дерево k-d
- Встраивание текста OpenAI GPT-3 — действительно новый уровень техники в области плотного встраивания текста?
- Представляем примерный поиск ближайшего соседа в Elasticsearch 8.0
:::информация Также опубликовано здесь
:::
п
н
н-н
н
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
Categories
- Технологии и IT (25347)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (270)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
