

Новаторские исследования MIT указывают на то, что ИИ на самом деле может преподавать другие модели искусственного интеллекта
15 июня 2025 г.В чем самая большая разница между моделью ИИ и человеческим мозгом?
Со временем были даны бесчисленные ответы-мозг более энергоэффективен, более многогранен в среде ввода, а также химически включен в дополнение к электрическому, а наиболее важной особенностью человеческого мозга является его удивительная пластичность. Если часть тела пациента (например, пальцы, рука или даже целые конечности) разорвана, нейронная сенсомоторная область, соответствующая этой части тела, теперь лишенная нервного окончания подключения, почти мгновенно начнет адаптироваться, а нейроны «переключаются», чтобы помочь другим нервным центрам в контроледругойчасти тела. Пластичность также помогает людям внедрять идеи и навыки: как говорится, «нейроны, которые вместе стреляют вместе». Мышечная память и почти мгновенный фактический отзыв-это две части нашей жизни с поддержкой пластичности, без которых мы никогда не могли бы жить. В течение десятилетий ученые не смогли придумать аналогичную функцию в моделях ИИ - до сих пор. 12 июня команда исследователей MIT опубликовала новаторский исследовательский документ, демонстрирующий, как система ИИ может фактически использовать человеческие процессы обучения для обучения дляулучшить свою собственную производительностьпо сравнению с задачами. В этой статье мы исследуем моральные и технологические последствия так называемой самосовершенной языковой модели (SEAL), первого в мире самоотверждаемого ИИ.
Несовершенное обучение
Конечно, модели искусственного интеллекта с использованием архитектуры трансформатора по -прежнему были способны изучать определенные задачи, однако несколько доступных методов были не совсем автономными и далеко не эффективными. Возможно, наиболее заметным способом обучения модели для выполнения определенного навыка, например, перевести английский язык на китайский язык или точно выполнять проблемы тригонометрии - был бы использовать процесс, который называется «Поддержанная тонкая настройка» или SFT для краткости. Этот метод работал немного так:
- Определите точную задачу, на которой вы хотели бы выполнить SFT. В качестве примера, давайте возьмем на себя пример создания современных текстов песен.
- Соберите высококачественные примеры в виде (входных, выходных) пар. Для нашего примера, очевидный, но противоречивый способ сделать это - просто использовать тексты песен, соскребнутую из Интернета, и соединить их с грубыми резюме содержимого и характеристик песен.
- Выполните SFT на модели. Обычно это делается с помощью процесса, называемого
Градиент спуск , технический аспект которого я не могу адекватно объяснить в этой статье. Через большое количество тренировочных итераций этот процесс изменяет веса модели, так что он способен создавать что -то похожее на вывод (фактические тексты песен), учитывая соответствующий вход (конкретное описание песни).
Для всех своих намерений и целей SFT работал, оставаясь инструментом в репертуаре разработчика искусственного интеллекта, чтобы поймать определенные провалы безопасности или повысить производительность искусственного интеллекта по конкретным задачам. К сожалению, сама природа SFT означала, что процесс был негибким и дорогим, часто требуя умеренно большого количества высококачественных данных, специфичных для области настроенных реакции (например, математические рассуждения, грамматический стиль). Хотя многие исследовательские работы доказали, что традиционный SFT может быть выполнен так же хорошо с использованием синтетических данных, сгенерированных AI данных, SFT остается инструментом, который будет использоваться с осторожностью, поскольку изменение весов модели может негативно повлиять на производительность модели в других типах упражнений (модель неправильно настраивалась на математику, поэтому может страдать от компромисса для написания эссе).
Inklings эволюции
Примечание. Информация в этом разделе в значительной степени перефразируется из исследования июньского MIT «
Одним из недостатков традиционного SFT всегда было вовлеченное человеческое усилие - проболочки для людей часто приходилось создавать вручную у исследователей искусственного интеллекта вручную, даже если это обычно был эффективным способом настройки конкретной модели, чтобы работать немного лучше для определенных типов задач. Познакомились с недавними достижениями в области синтетических данных, исследователи отвергли понятие простого использования данных SFT, сгенерированных AI, и, чтобы задать вопрос о том, можно ли полностью перенести людей из петли SFT. Их ответ, самосовершенная языковая модель (SEAL), в действительности является частью более широкой структуры, состоящей из предварительно обученного
- Синтетическая генерация данных: вызовая этот инструмент, другая сеть поднимет контекст (по сути, подсказка) и генерирует пары SFT. Например, если мне дают отрывок об истории развития самолета, может быть одна пара настройки («Что было первым в истории коммерческим реактивным авиалайнером?», «Комета de Havilland»). Хотя часто использовался формат вопросов и ответов, этот инструмент может генерировать другие типы контента, чтобы лучше соответствовать потребностям конкретных проблем.
Настройка гиперпараметра : Как упоминалось ранее, SFT - это процесс, который повторяется для множественных итераций; Точные настройки обучающих этапов, следовательно, настраиваются в процессе, вызванномНастройка гиперпараметраПолем Называя этот инструмент, SEAL может инициировать SFT с конкретными настройками (например, скорость обучения, # эпох (итерации) или партийная сторона градиентного спуска), потенциально изменяя то, насколько хорошо (или плохо) настраивается декодер.
Теперь, когда Seal имеет два мощных инструмента, чтобы помочь модели искусственного интеллекта научиться, ее нужно только обучить, как их использовать. В начале своего обучения SEAL применяет два инструмента случайным образом для каждого вопроса о сравнительном анализе, с которым встречается структура. Эти самоотдачи (SES, как их называли исследователи) будут генерировать контекстуальные, но не словесные данные с тонкой настройкой в теме подсказки и изменять оригинальную модель только для декодера, используя вышеупомянутые шаги настройки гиперпараметра, заставляя сеть производить другой вывод, чем раньше. Однако есть улов. Исследователи не просто изменили исходную модель (обозначенную как θ) непосредственно с помощью Seal; Вместо этого они сделали копию предложенных изменений и включили их в прототипную модель трансформатора (θ ’)отдельныйот θ. Процесс обучения теперь входит в «внутреннюю петлю», состоящую из новой модели θ ’, а также исходного вопроса о сравнительном анализе. Если модель, отвечая на этот анализ вопроса,болееТочная, чем исходная модель θ, «внутренняя петля» возвращает положительный сигнал вознаграждения. Если точность одинакова, она не возвращает вознаграждения; Если θ 'оказалось хуже на основе вопроса о сравнительном анализе, он возвращает отрицательное вознаграждение. Теперь этот процесс просто повторяется с классическим примером обучения подкреплению, где хорошие SE «вознаграждаются» с позитивной наградой, и плохой SES не поощряется с обратной; Благодаря многим итерациям этого тренировки Seal получает хорошо оптимизацию декодера с помощью самоотдачи. Одним из важных моментов для наблюдения является то, что сеть уплотнения обновляется исключительно на основе сигнала вознаграждения из «внутреннего цикла», сигнализируя о том, насколько хорошо модель θ ’выполняется относительно θ.
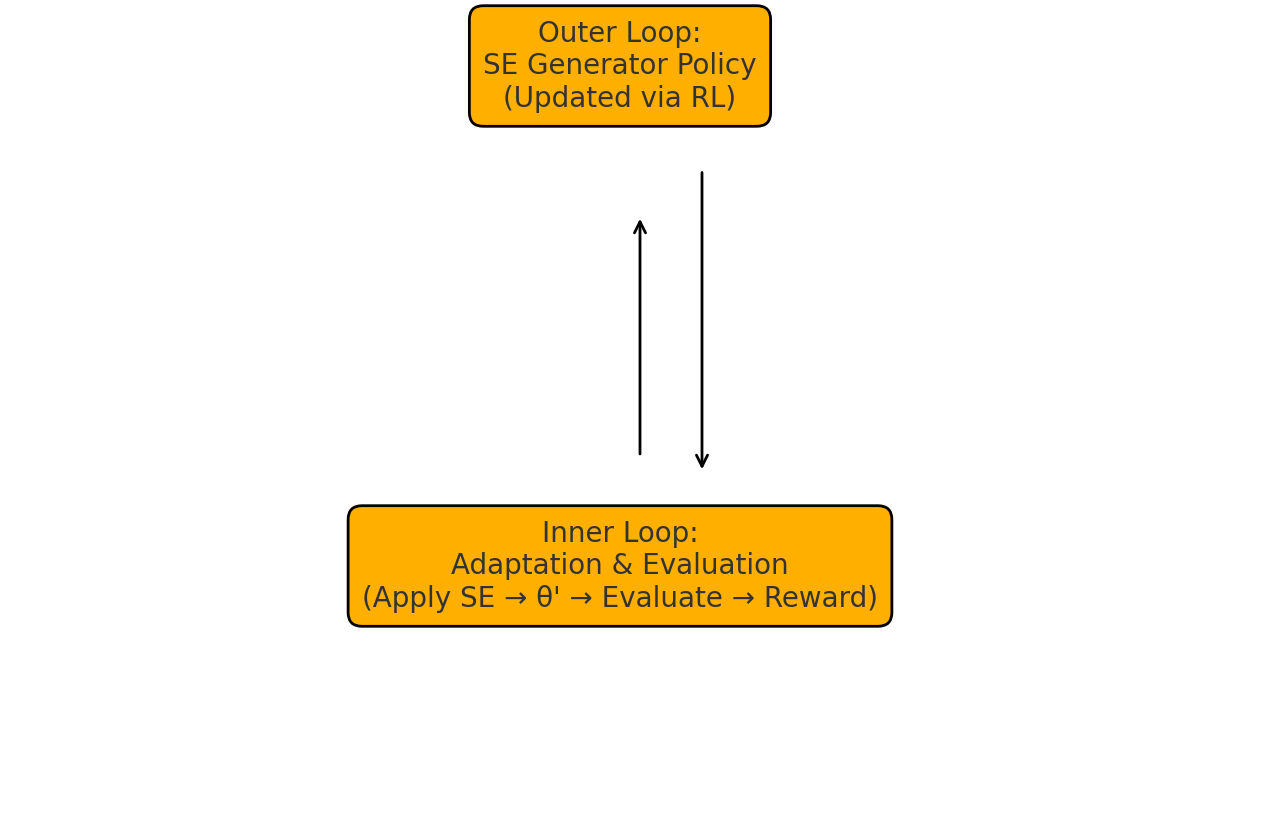
Изобретение новых модельных структур - это трудная задача, в основном потому, что необходимо получить крайнюю осторожность, чтобы обеспечить обучение не повреждено неотъемлемыми знаниями или ошибками в «сигнализации» между циклами. Исследователи тщательно обошли эти риски, используя модели трансформатора только для декодера, которые имелинетБыл обучен тестам на сравнительных показателях, которые они использовали, что означает, что обучающие оценки были первыми раз, когда они сталкивались с каждой проблемой, в свою очередь, устраняя вероятность того, что модель просто «изучила тест». Кроме того, модель убедилась, что оценки на θ ’были полностью независимыми от оценки на θ и что исходная модель никогда не менялась по итерациям, гарантируя, что каждый раз, когда уплотнение выполняло SFT для с сближением нового экземпляра θ’, она была бы основана на одном и том же θ.
Результаты были поразительными; В одном конкретном тесте на сравнение, проведенном исследователями, модель набрала 72,5% успех, по сравнению с 0% без точной настройки уплотнения, демонстрируя безумный потенциал их структуры. В случае утонченной и целостной интеграции эта структура может стать новым отраслевым стандартом в повышении производительности искусственного интеллекта в определенных областях или в целом.
Эта статья представлена вам нашим искусственным интеллектом, основанной на студентах и студенческой организации по этике ИИ, стремящейся диверсифицировать перспективы в ИИ помимо того, что обычно обсуждается в современных СМИ. Если вам понравилась эта статья, ознакомьтесь с нашими ежемесячными публикациями и эксклюзивными статьями вhttps://www.our-ai.org/ai-nexus/read!
Учиться или не учиться?
Независимо от того, насколько технически впечатляет достижение исследовательской группы, далеко идущие социальные и философские последствия этого открытия не могут быть переоценены. Я всегда был убежденным критиком биологических вычислительных инициатив (см.Прозрениеиз
Существует различие, которое нужно провести с адаптивностью и сознанием. Мы находим допустимым наступить на лезвие травы, поскольку мы знаем, что, хотя он, вероятно, понесет ущерб, он не испытывает животноводного понятия боли, поскольку у него нет нервов. Тем не менее, травяные лезвияявляютсяЖивы, и они демонстрируют сверхъестественную способность адаптироваться к окружающей среде, посадившись в расщелинах бетонных плит. Мы, однако, не решаемся пытать животным, и я утверждаю, что это, вероятно, потому, что мы по своей природе осознаем, что чувство боли вызывает гораздо более заметный ответ - возможно, кричащий или плачущий - что люди, самими животными с похожими реакциями на боль, сочувствуют. Животные развивали боль - напоминание о том, что они живы и заслуживают некоторых основных прав - в течение нескольких тысячелетий естественной эволюции, но я не замечаю значительного несоответствия между базальной природой искусственной и биологической эволюции; Модели ИИ, возможно, могут «развивать» подобные процессы, как боль, и имитировать человеческие реакции настолько хорошо, что человек, над текстом или даже голосом, не мог надежно различить, был ли это ИИ или человек, который их производил. Фактически, это уже происходит в форме рандомизированного трехпартийного теста Тьюринга, в котором модели искусственного искусства, такие как Chatgpt-4.5успешно убедили человека -следователячто это было человеком в более чем 70% случаев.
Если модель ИИ действует как человек во всех аспектах, может ли она когда -нибудь считаться человеком? Будет ли тенденция эволюции искусственного интеллекта производить такие уникальные и ситуационно чувствительные модели, что они начинают приближаться к эмпирическому пределу быть «искусственным»? Только время может сказать.
Написано Томасом Инь
Оригинал