

Семантическое кэширование на основе теории графов: масштабирование приложений LLM
7 августа 2025 г.Анализируя паттерны запросов в приложениях с использованием LLM, я обнаружил тревожную тенденцию, которую многие разработчики упускают из виду. Приложения обрабатывают тысячи семантически идентичных вопросов с совершенно разными фразами. "Как сбросить пароль?" Появится вместе с "Какой процесс восстановления пароля?" и "Я забыл свой пароль, помоги мне восстановить его?" - Всего по сути один и тот же запрос, но каждый запускает отдельные вызовы API LLM. Математика быстро становится болезненной, так как каждый запрос стоит денег.
Традиционные системы кэширования на основе строк не могут распознать эти семантические сходства. Каждая чуть другая фраза приводит к новому вызову API, что приводит к тому, что затраты на спирали вверх с тем, что должно быть кэшированным ответом. Здесь лежит настоящая задача - как вы кэшируете ответы для вопросов, которые означают одно и то же, но сформулированы по -другому?
Эта задача привела меня к изучению нетрадиционного подхода - сочетание теории графов с поиском семантического сходства. Вместо того, чтобы рассматривать кэшированные ответы как изолированные записи, что, если они образуют подключенный график, где семантически похожие запросы могут ссылаться на друг друга? Ранние исследования оказались многообещающими.
Семантическое кэширование на основе графика может теоретически снизить как затраты API, так и задержку ответа, масштабируя более эффективно, чем традиционные подходы. Эта статья погружается в техническую реализацию с использованием REDIS и удивительных характеристик производительности, которые возникли в результате тестирования.
Почему сопоставление строк убивает ваш кеш
Многие простые механизмы кэширования применяются как это сегодня:
import hashlib
class SimpleCache:
def __init__(self):
self.cache = {}
def get(self, query: str):
key = hashlib.md5(query.encode()).hexdigest()
return self.cache.get(key)
def set(self, query: str, response: str):
key = hashlib.md5(query.encode()).hexdigest()
self.cache[key] = response
# Usage
cache = SimpleCache()
cache.set("How do I reset my password?", "Go to Settings > Security...")
# These all miss the cache:
cache.get("What's the password recovery process?") # None
cache.get("I forgot my password, help me recover it?") # None
cache.get("Password reset procedure please") # None
Жестокая реальность:Эти запросы запрашивают идентичную информацию, но ваш кэш рассматривает их как совершенно разные запросы. Каждый кэш пропускает вам звонок LLM API.
Фундаментальная проблема?Сопоставление строк игнорирует значениеПолем Нам нужно было что -то, что понимает, что «сбросить пароль» и «восстановление пароля» семантически эквивалентны.
Теория прорыва встречается Redis
Прорыв произошел из -за обработки запросов как связанного графика. Каждый запрос становитсяузел, икраяПодключите семантически похожие запросы с оценками сходства как веса. Вместо того, чтобы проверять 100 кэшированных элементов линейно, вы можете проверить только 12 стратегически выбранных узлов. График обезвреживания шкалы подразделения при сохранении высокой точности.
Почему это работает: аналогичные запросы естественным образом объединяются. Если «сбросить пароль» похож на ваш запрос, его соседи любят «восстановление пароля», вероятно, тоже.
Redis в качестве вашего графического двигателя
Сортированные наборы и хэши Redis делают их удивительно идеальными для графических операций без необходимости специализированных баз данных графиков. Следовательно, Redis оказывается идеальным для этого. Вот как карта структуры данных:
# Nodes: Store query data as Redis hashes
# Key: "node:abc123"
redis.hset("node:abc123", {
"query": "How do I reset my password?",
"response": "Go to Settings > Security...",
"embedding": "[0.1, 0.4, -0.2, ...]", # JSON array
"timestamp": "1642534800"
})
# Edges: Store neighbors as Redis sorted sets (score = similarity)
# Key: "edges:abc123"
redis.zadd("edges:abc123", {
"def456": 0.85, # "password recovery" query with 0.85 similarity
"ghi789": 0.72, # "forgot password" query with 0.72 similarity
"jkl012": 0.68 # "login help" query with 0.68 similarity
})
Стратегическое здание графика
Этот подход позволяет избежать взрыва O (N²) подключения каждого узла с любым другим узлом, выбирая, какие соединения создавать.
Вот ключевое понимание:Не подключайте каждый узел к любому другому узлуПолем Это O (N²) и убивает производительность.
def add_query_to_graph(new_query, response):
query_hash = hash(new_query)
embedding = get_embedding(new_query)
# Strategy 1: Connect to recent nodes (likely relevant)
recent_nodes = redis.lrange("recent_nodes", 0, 9) # Last 10 nodes
# Strategy 2: Sample random nodes for diversity
all_nodes = redis.smembers("all_nodes")
if len(all_nodes) > 20:
random_sample = random.sample(all_nodes, 10)
candidates = recent_nodes + random_sample
# Only calculate similarity for strategic subset
for existing_hash in candidates:
existing_data = redis.hgetall(f"node:{existing_hash}")
similarity = cosine_similarity(embedding, existing_data['embedding'])
if similarity > 0.1:
# Create bidirectional edges with similarity weights
redis.zadd(f"edges:{query_hash}", {existing_hash: similarity})
redis.zadd(f"edges:{existing_hash}", {query_hash: similarity})
# Store the new node
redis.hset(f"node:{query_hash}", {
"query": new_query,
"response": response,
"embedding": json.dumps(embedding.tolist())
})
Вот как семантический график присматривает за добавлением нескольких запросов:
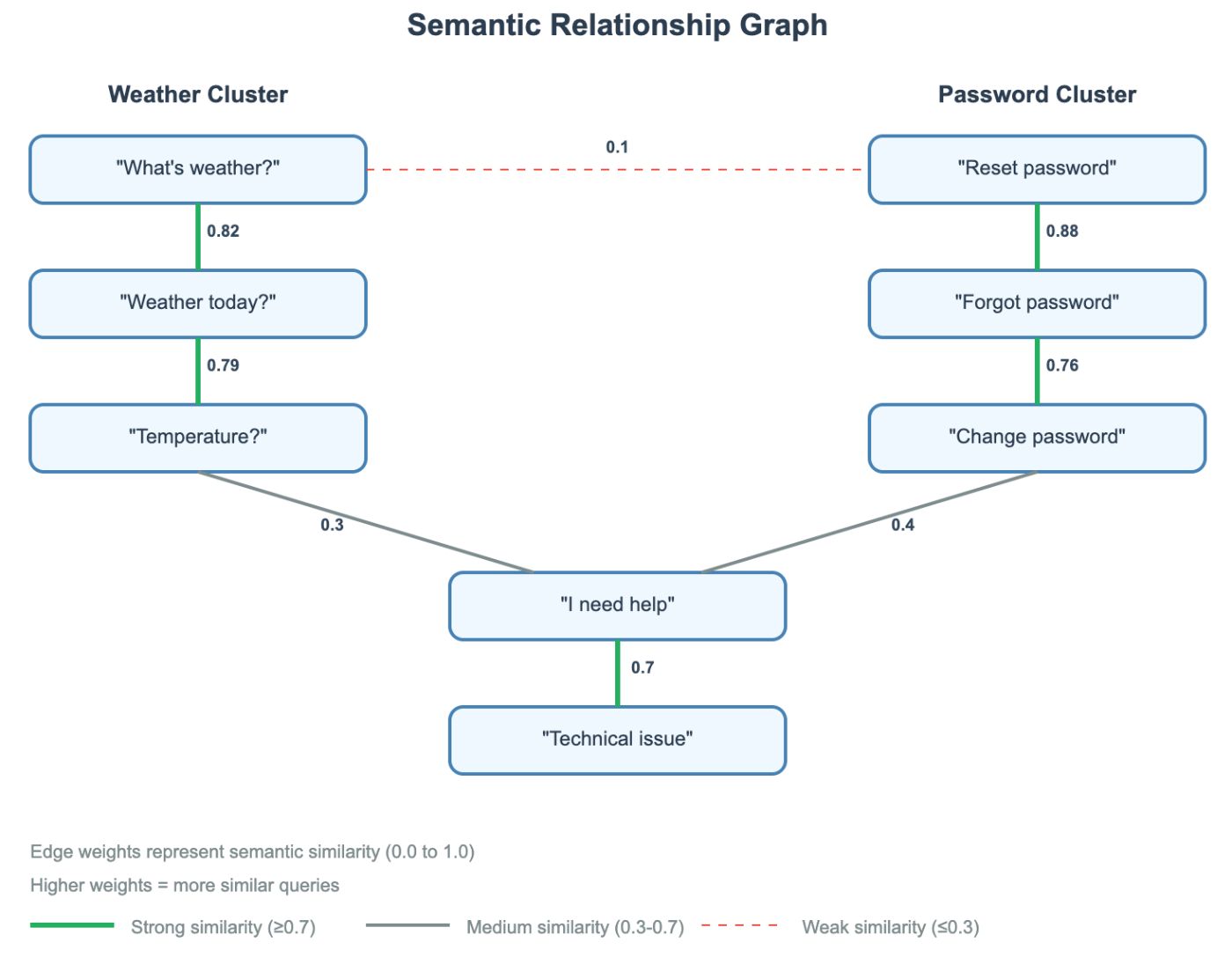
Умный граф обход
Поиск становится интеллектуальной ходьбой. Алгоритм использует предварительно вычисляемые веса краев, чтобы расставить приоритеты в исследовании узлов, превращая линейный поиск O (n) в управляемое обход, который следует за градиентами сходства. ЭтотПозволяет пропустить целые регионысемантически не связанных кэшированных запросов.
def find_similar_cached(query):
query_embedding = get_embedding(query)
# Start with promising candidates
recent_nodes = redis.lrange("recent_nodes", 0, 2) # Last 3 nodes
for start_node in recent_nodes:
# Check the starting node
similarity = check_similarity(query_embedding, start_node)
if similarity > threshold:
return get_cached_response(start_node)
# Follow the strongest edges (highest similarity neighbors)
neighbors = redis.zrevrange(f"edges:{start_node}", 0, 1) # Top 2 neighbors
for neighbor in neighbors:
similarity = check_similarity(query_embedding, neighbor)
if similarity > threshold:
return get_cached_response(neighbor)
return None # Cache miss
Магия:Вместо того, чтобы проверять 100+ кэшированных запросов линейно, вы проверяете ~ 12 стратегически выбранных узлов. Структура графика направляет вас к соответствующим кластерам при пропускании не связанных с этим областей.
Redis преимущества:Сортированные наборы дают вам мгновенный доступ к соседям Top-K. Хэш -хранение держит данные узла вместе. Все масштабируется горизонтально.
Заключение
Результаты производительности
Тестирование этого подхода с 200 различными запросами выявил силу семантического кэширования на основе графиков. Результаты были поразительными:
- Эффективность поиска:Алгоритм графика проверил в среднем12.1 узлыпо сравнению с42 узлатребуется для линейного поиска -71,3% снижениев вычислительных накладных расходах. Это переводится на3,5x ускорениев операциях по поиску кэша.
- Влияние стоимости:С44,8% кеша.На семантических матчах стоимость API LLM значительно упала. Вместо 210 дорогих вызовов API потребовалось только 116 - сохранение44,8% в эксплуатационных затратахПолем
- Масштабируемость:Самое главное, эта эффективностьулучшаетсяПо мере роста вашего кэша. Линейный поиск становится медленнее с большим количеством кэшированных предметов, но траверта графика поддерживает постоянную производительность, разумно пропуская не относящиеся к делу региона.
Соображения производства
Когда использовать кэширование на основе графика:
- Высокий объем запроса с семантическими вариациями (поддержка клиентов, документация, часто задаваемые вопросы)
- Чувствительные к стоимости приложения, в которых имеют значение API LLM
- Сценарии, где небольшие задержки ответа (50-100 мс) приемлемы для огромной экономии средств
Советы по конфигурации:
- Порог сходства 0,7 хорошо работает для большинства вариантов использования
- Подключите каждый узел с 10-15 соседями для оптимального подключения к графику
- Используйте встроения с 512 измерениями, чтобы сбалансировать точность и хранение
Суть:Теория графика превращает семантическое кэширование из проблемы грубой силы в интеллектуальную задачу поиска. Обращаясь с аналогичными запросами как связанными соседями, а не как изолированными строками, вы можете значительно снизить как затраты, так и задержку, сохраняя при этом высокую точность.
Этот подход открывает новые возможности для эффективного семантического поиска в масштабе, доказывая, что иногда лучшее решение не лучших алгоритмов - это лучшие структуры данных.
Репозиторий:https://bitbucket.org/agent-projects/semcache/
Оригинал