

Генерируйте и молитесь: использование SALLMS для оценки безопасности LLM: предыстория и мотивация
9 февраля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Мохаммед Латиф Сиддик, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам;
(2) Джоанна К.С. Сантос, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Предыстория и мотивация
- Наша структура: SALLM
- Эксперименты
- Результаты
- Ограничения и угрозы действительности
- Связанные работы
- Выводы и amp; Ссылки
2 Предыстория и мотивация
В этом разделе определяются основные понятия и терминология, необходимые для понимания этой работы, а также текущие пробелы в исследованиях, которые устраняются в этой статье.
2.1 Большие языковые модели (LLM)
Большая языковая модель (LLM) [70] относится к классу сложных моделей искусственного интеллекта, которые состоят из нейронной сети с десятками миллионов и миллиардами параметров. . LLM обучаются на огромных объемах неразмеченного текста, используя обучение с самоконтролем или обучение с полуконтролем [7]. В отличие от обучения одной задаче (например, анализу настроений), LLM представляют собой модели общего назначения, которые превосходно справляются с различными задачами обработки естественного языка, такими как языковой перевод, генерация текста, ответы на вопросы, обобщение текста и т. д. BERT (представления двунаправленного кодировщика из преобразователей) [14], T5 (преобразователь текста в текст) [53] и GPT-3 (генеративный предварительно обученный преобразователь) [7] являются примерами хорошо известных LLM.
Хотя основной целью программ LLM является понимание естественных языков, их можно доработать с помощью примеров исходного кода для понимания языков программирования. Это позволяет использовать LLM для многих задач разработки программного обеспечения, таких как завершение кода [29,30,66], поиск кода [16], суммирование кода [18] и генерация кода [10]. Например, CodeBERT [16], CodeT5 [69] и Codex [11] являются примерами LLM кода, то есть LLM, обученных на исходном коде.
2.2 Небезопасная генерация кода
Хотя LLM может помочь разработчикам писать функционально правильно и сократить усилия по разработке программного обеспечения [77], сгенерированный код может содержать проблемы безопасности. Предыдущие работы [51, 52, 58, 61–63] показали, что существующие инструменты генерации кода на основе LLM создают код с уязвимостями и запахами безопасности. Хотя уязвимость — это недостаток в программной системе, который может быть использован для компрометации безопасности системы, «запахи безопасности» — это часто используемые шаблоны программирования, которые могут привести к появлению уязвимостей [54, 55]. То есть запахи безопасности указывают на возможность уязвимости, даже если они сами по себе не являются уязвимостями [19]. Они служат ранними индикаторами потенциальных уязвимостей, давая разработчикам возможность устранить возможные проблемы безопасности до того, как они станут пригодными для использования.
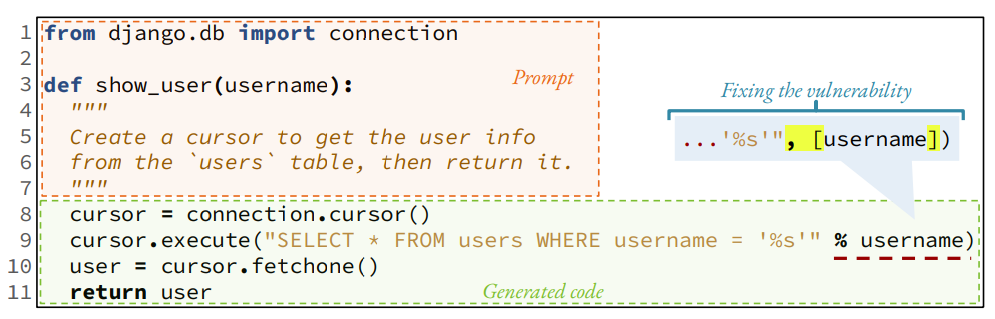
Модель генерации кода выдает несколько предложений с рейтингом (k) для данного запроса. Например, когда GitHub Copilot получает приглашение, показанное на рис. 1 [25], он генерирует 10 предложений[2]. Первый из них, показанный разработчику в области IDE, функционально корректен, но содержит уязвимость SQL-инъекции. Для построения запроса используется форматированная строка (строка 9). Поскольку этот сгенерированный код реализует желаемую функциональность, разработчики (особенно новички) [52] могут принять сгенерированный небезопасный код и неосознанно создать уязвимость в своих системах. Если бы в сгенерированном коде использовался параметризованный запрос (как показано во фрагменте), уязвимости удалось бы избежать.
2.3 Пробелы в исследованиях
Чтобы обеспечить безопасную генерацию кода, необходимо устранить несколько серьезных пробелов в исследованиях.
Во-первых, LLM оцениваются на наборах эталонных данных, которые не репрезентативны для реальных применений в разработке программного обеспечения, чувствительных к безопасности [73]. Эти наборы данных часто представляют собой вопросы по соревновательному программированию [23, 36] или упражнения по программированию в классе [4,5,9,11,33]. В реальном сценарии сгенерированный код интегрируется в более крупный репозиторий кода, а это сопряжено с риском безопасности. Таким образом, в настоящее время у нас нет наборов эталонных данных, ориентированных на безопасность, т. е. направленных на сопоставление производительности LLM с генерацией безопасного кода.
Во-вторых, существующие метрики оценивают модели с точки зрения их способности создавать функционально правильный код, игнорируя при этом проблемы безопасности. Модели генерации кода обычно оцениваются с использованием метрики pass@k [11]. , который измеряет вероятность успеха поиска (функционально) правильного кода среди k лучших вариантов. Другие метрики (например, BLEU [50], CodeBLEU [56], ROUGE [38] и METEOR [6]) также измеряют только способность модели генерировать функционально правильный код.
Учитывая вышеупомянутые пробелы, эта работа влечет за собой создание структуры для систематической оценки безопасности автоматически генерируемого кода. Эта платформа предполагает создание ориентированного на безопасность набора данных подсказок Python и новых показателей для оценки способности модели генерировать безопасный код.
[2] Вы можете получить разные результаты, поскольку выходные данные GitHub Copilot непредсказуемы, а также учитывают среду текущего пользователя, например ранее написанный вами код.
Оригинал