
Близнецы — семья очень способных людей Мультимодальные модели: архитектура модели
25 декабря 2023 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Команда Gemini, Google.
:::
Таблица ссылок
Обсуждение и заключение, ссылки
2. Модель архитектуры
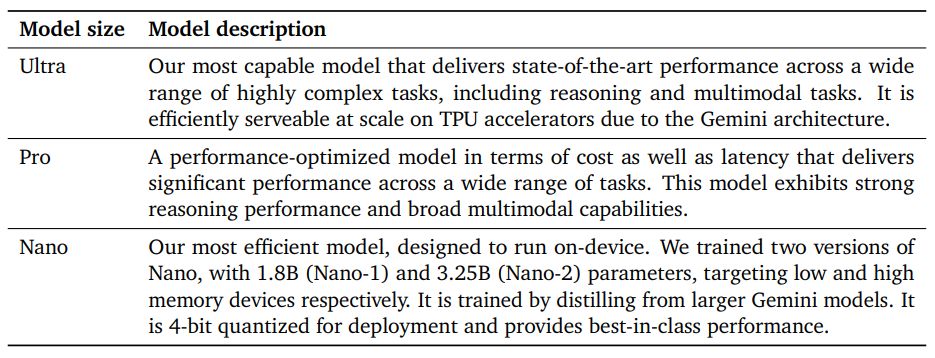
Модели Gemini созданы на основе декодеров Transformer (Vaswani et al., 2017), которые усовершенствованы за счет улучшений архитектуры и модели. оптимизация для обеспечения стабильного масштабного обучения и оптимизированного вывода на тензорных процессорах Google. Их обучают поддерживать длину контекста 32 тыс., используя эффективные механизмы внимания (например, для внимания с несколькими запросами (Shazeer, 2019)). Наша первая версия, Gemini 1.0, включает три основных размера для поддержки широкого спектра приложений, как описано в Таблице 1.
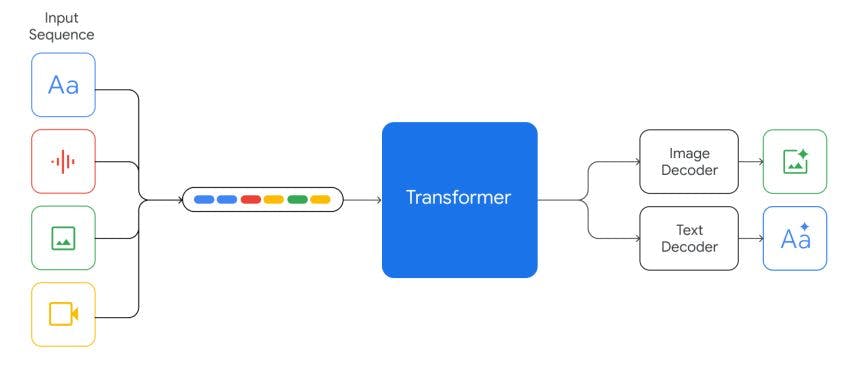
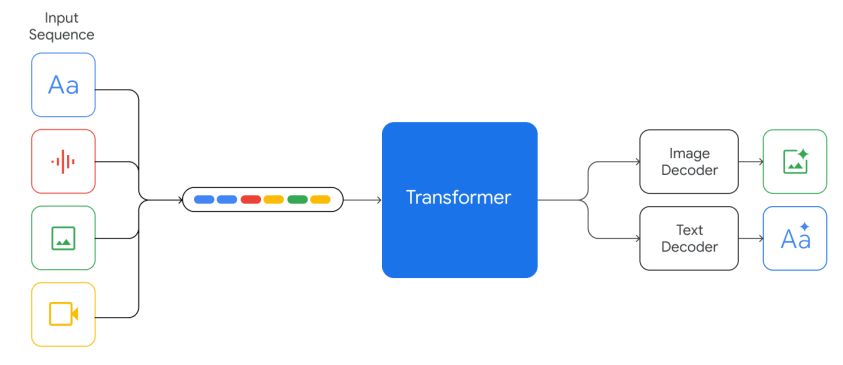
Модели Gemini обучены обрабатывать текстовый ввод, чередующийся с широким спектром аудио- и визуальных входных данных, таких как естественные изображения, диаграммы, снимки экрана, PDF-файлы и видео, и они могут создавать выходные данные в виде текста и изображений (см. рис. 2). Визуальное кодирование моделей Близнецов вдохновлено нашей собственной основополагающей работой по Flamingo (Alayrac et al., 2022), CoCa (Yu et al., 2022a) и PaLI (Chen et al., 2022), с тем важным отличием, что модели с самого начала являются мультимодальными и могут выводить изображения с использованием дискретных токенов изображений (Ramesh et al., 2021; Yu et al., 2022b).
Понимание видео достигается путем кодирования видео как последовательности кадров в большом контекстном окне. Видеокадры или изображения могут естественным образом чередоваться с текстом или звуком как часть входных данных модели. Модели могут обрабатывать переменное входное разрешение, чтобы тратить больше вычислений на задачи, требующие детального понимания. Кроме того, Gemini может напрямую принимать аудиосигналы частотой 16 кГц с помощью функций универсальной модели речи (USM) (Чжан и др., 2023). Это позволяет модели улавливать нюансы, которые обычно теряются, когда звук просто сопоставляется с текстовым вводом (например, см. демонстрацию понимания звука на веб-сайте).
Обучение семейства моделей Gemini потребовало инноваций в алгоритмах обучения, наборе данных и инфраструктуре. Что касается модели Pro, присущая нашей инфраструктуре и алгоритмам обучения масштабируемость позволяет нам завершить предварительное обучение за считанные недели, используя лишь часть ресурсов Ultra. Серия моделей Nano использует дополнительные достижения в алгоритмах фильтрации и обучения для создания лучших в своем классе моделей малого языка для широкого круга задач, таких как обобщение и понимание прочитанного, которые обеспечивают работу нашего следующего поколения на устройствах.
Оригинал
Recent Post
-
Bitpanda запускает Defi Wallet для Power Europe в будущее Onchain
20 августа 2025 г. -
Как Toyota Blockchain Lab хочет сделать автомобили готовыми к финансированию: Внутри предложения Toyota's Mon предложение
20 августа 2025 г. -
Получение звонков клиентов по бюджету в размере 0 долларов США: уроки от стартапа репетиторства
20 августа 2025 г. -
За кулисами эксперимента парного программирования
19 августа 2025 г. -
Простое руководство по измерению времени и труда в программировании
19 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера
- Культура и общество
- Цифровые права и свобода слова
- Безопасность и искусственный интеллект
- Технологии и искусство
- Мобильные приложения
- Продуктивность
- Космические технологии и безопасность
- Технологические тренды и экономика
- Безопасность и конфиденциальность
- Продуктивность и личная эффективность
- Веб‑скрейпинг и автоматизация
- Политика и социальные сети
- Политика и безопасность
- Медиа и информационное пространство
- Медицина и Психология
- Интернет‑культура и медиа
- Технологии и разработка
- Сociety
- Развитие интеллекта и профессиональные навыки
- Linux, программирование