

От одного банана до миллиардов: тестирование прогнозирующих способностей PCIC
13 августа 2025 г.Таблица ссылок
Аннотация и 1 введение
- Литературный обзор
- Модель
- Эксперименты
- Путешествие по развертыванию
- Будущие направления и ссылки
4 эксперименты
В этом разделе мы проводим эксперименты, чтобы ответить на следующие вопросы: Q1: Какова эффективность предлагаемого метода? Это превосходит современные методы NBR/ BIA? Q2: Насколько хорошо этот метод масштабируется, чтобы генерировать рекомендации для миллионов пользователей? Q3: Как на производительность модели влияют входные функции? Q4: Как диапазоны даты обучения и тестирования меняют производительность модели?
4.1 Экспериментальные настройки
4.1.1 Наборы данных. Мы используем четыре общедоступных набора данных, показанные в таблице 1, чтобы сравнить производительность предлагаемого метода с существующими методами в литературе: Valuedshopper [2], Instacart [3], Dunnhumby [4] и Tafeng [5]. Мы также оцениваем использование внутреннего набора данных, состоящего из истории продаж пользователей в крупном магазине. В этом наборе данных около 100 м и 3M продуктов.
4.1.2 Протокол оценки.Мы используем метрики Recall (@K) и NDCG (@K) для оценки и сравнения наших методов. Первая метрика оценивает долю наземных предметов истины, которые клиенты купили в последней поездке, которые были справедливо ранжированы по предметам Top-K во всех сессиях тестирования. NDCG - это мера, основанная на ранжировании, которая учитывает заказ приобретенных предметов в рекомендациях и генерирует оценку от 0 до 1. Мы используем прошлые корзины данного клиента для прогнозирования их последней корзины. Мы рассматриваем 80% данных клиентов для обучения модели и оставшегося в тестировании с использованием 5-кратной перекрестной проверки. Мы оставляем 10% обучающих данных в качестве набора данных проверки для настройки гиперпараметров во всех методах.
4.1.3 Базовые линии.
(1) Topsell: он использует наиболее частые элементы, которые приобретаются пользователями в качестве рекомендаций для всех пользователей.
(2) FBOUD: он использует наиболее частые предметы, которые приобретаются пользователем в качестве рекомендации для него.
(3) userknn [16]: он использует классическую совместную фильтрацию на основе KNN. Все предметы в исторических корзинах пользователя объединены как набор предметов.
(4) Repementnet [18]: модель на основе RNN для рекомендации на основе сеансов, которая отражает повторное поведение пользователей. Он использует гран и внимание. Чтобы применить этот метод, пользовательские корзины переводятся на последовательность элементов.
(5) FPMC [19]: Матричная факторизация использует все данные для изучения общего вкуса пользователя, тогда как цепи Маркова могут захватывать эффекты последовательности во времени. FPMC объединяет оба для следующей проблемы с рекомендацией корзины.
(6) Dream [21]: динамическая рецидивирующая модель корзины (мечта) изучает динамическое представление пользователя, но также отражает глобальные последовательные функции среди корзин.
(7) Шан [20]: глубокая модель, основанная на иерархических сетях внимания. Он разделяет исторические корзины на долгосрочные и краткосрочные части, чтобы изучить долгосрочные предпочтения и краткосрочные предпочтения, основанные на соответствующих элементах.
(8) SETS2SETS [12]: современный метод сквозного для следования множественного прогнозирования корзин на основе RNN. Повторная шаблона покупки также интегрирована в метод.
(9) RCP [2]: Повторная вероятность клиента (RCP) обнаруживает, вероятно, элемент и повторяющиеся элементы на основе этого.
(10) ATD [2]: модель распределения совокупного времени соответствует распределению времени для моделирования вероятностей вероятностей и характеристик времени повторных элементов.
(11) PG [2]: Гамма -распределение Пуассона, установленное для прогнозирования поведения за покупку. (12) MPG [2]: модифицированное распределение PG, чтобы сделать результаты зависимым от времени и межгат -повторения вероятности клиента.
Мы используем поиск сетки для настройки гиперпараметров в сравниваемых методах. Для пользователя KNNN количество ближайших соседей ищет из диапазона (100, 1300). Для FPMC измерение фактора ищет из набора значений [16, 32, 64, 128]. Для Repeatnet, Dream, Shan и Sets2sets размер встраивания ищет из набора значений [16, 32, 64, 128]. Для модели PCIC модель ARIMA была автоматической в диапазоне (3, 3, 0).
4.2 Сравнение производительности (Q1)
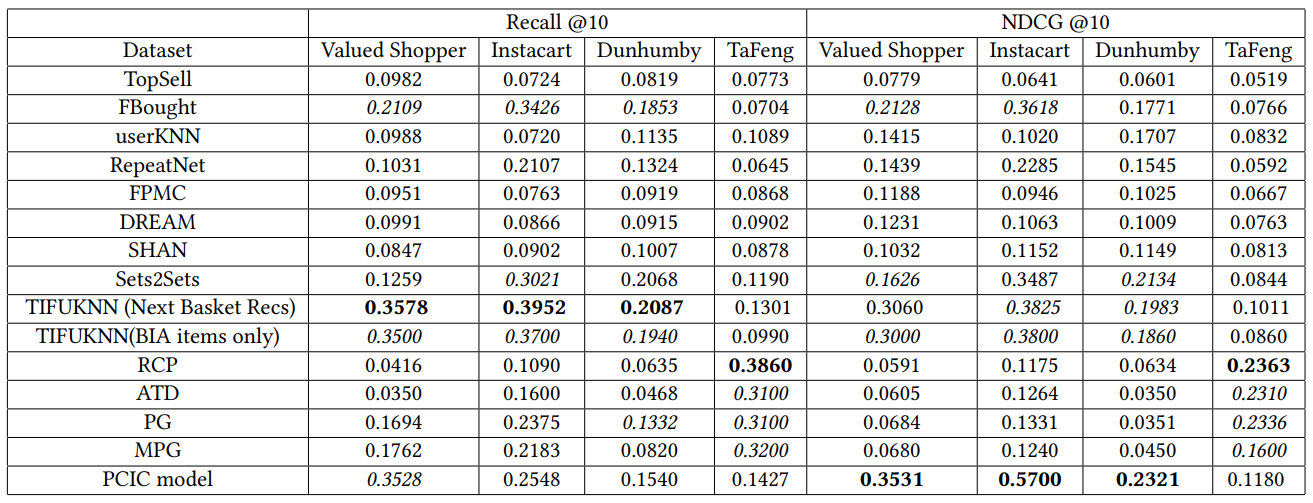
В таблице 2 приводится сравнение производительности модели PCIC с существующими базовыми показателями. Несколько наблюдений могут быть сделаны из таблицы.
Во -первых, мы отмечаем, что модель PCIC имеет самые высокие значения NDCG в большинстве случаев на наборах данных о ценных покупателях, Instacard и Dunhumby. Удивительно, но модель RCP хорошо работает в наборе данных Tafeng.
Модели Tifuknn также работают хорошо. Поскольку эта модель построена для следующей задачи по рекомендации корзины, результаты которого находятся под набором данных Tifuknn (NBR) в таблице 2, мы изменили код и запустили его для выполнения только по задаче BIA (то есть генерировать векторы, встраивающие пользователи, найти результаты от соседних Embeddings, а затем отфильтровать рекомендации, которые пользователь не приобрел ранее), результаты которого находятся под DataSet TifuNnings (BIA). Мы видим, что это приводит к небольшому падению в его производительности. Так же, как наша модель отражает персонализированную частоту категории, Tifuknn Model пытается явно захватить персонализированную частоту предметов. Tifuknn Model использует ближайший соседский подход к совместной фильтрации для изучения шаблона выкупа у других пользователей. В модели PCIC функции анализа выживания используют шаблон выкупа пользователей на уровне категории.
SETS2SETS фиксирует персонализированную частоту предметов явно, но впоследствии изучает коэффициенты для RNN. Модели RCP, ATD, PG и MPG не используют персонализированную частоту предметов, но они пытаются моделировать шаблон повторения покупки, используя гамма Пуассон или модифицированное гамма -распределение Пуассона. Следовательно, мы видим, что эти методы работают лучше, чем любые существующие методы, которые не захватывают элемент или частоту категорий, такие как RepementNet, UserKnn и т. Д.
FBOUD - довольно простая базовая линия, поскольку он просто занимает наиболее часто покупаемые предметы пользователя в этом порядке. Это удивительно работает лучше, чем многие базовые линии здесь. Это просто реализовать базовый уровень и работает довольно хорошо.
Мы хотели выбрать лучшие базовые показатели и сравнить производительность с гораздо большим, реальным внутренним набором данных. Проблемы в масштабировании этих моделей для оценки больших наборов данных обсуждаются дальше.
4.3 масштабирование (Q2)
Мы попытались обучить высокопроизводительные модели выше на гораздо большем (100 -метровом пользовательском) наборе данных. Tifuknn использует пользователь, внедряющий размер всего каталога продуктов, что сделало невозможным масштабировать этот набор данных. Следовательно, было невозможно масштабировать Tifuknn, чтобы запустить этот большой набор данных. Точно так же Sets2sets использует слои GRU с вниманием и обучением на этом наборе данных займет недели. В результате мы подготовили более крупный набор данных, создав репрезентативную выборку с 1M пользователями. Мы сравнили Tifuknn и Sets2sets с PCIC, используя эти субмированные данные. Мы наблюдали снижение на 30-35%
В NDCG и отзывных метрик в Tifuknn и SETS2Sets против PCIC. В результате мы не приложили усилий в масштабирование ни одного алгоритма.
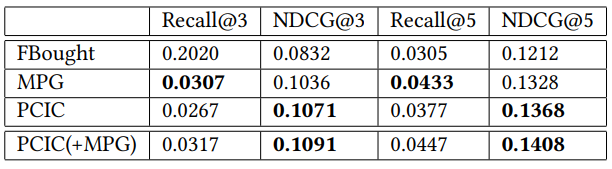
PCIC был реализован в распределенном кластере Hadoop с использованием Apache Spark и занимает около 6-8 часов времени, чтобы обучить и протестировать модель для 100 м для пользователей. Основная трудоемкая часть состоит в том, чтобы выяснить гиперпараметры модели ARIMA для каждой пары пользовательской категории и для создания этих функций. FBOUD является простым для реализации и занимает несколько минут времени выполнения. Мы также реализовали модель MPG в распределенном кластере, используя математику, описанную в статье. В таблице 3 показано сравнение производительности моделей FBOUD, MPG и PCIC. Хотя PCIC работает хорошо с точки зрения NDCG, отзыв немного ниже MPG. Далее мы рассчитали параметры MPG на уровне категории вместо исходного уровня элемента и вводим его как часть функций в ПК. Производительность интегрированного PCIC (+MPG) превосходит как PCIC, так и MPG.
4.4
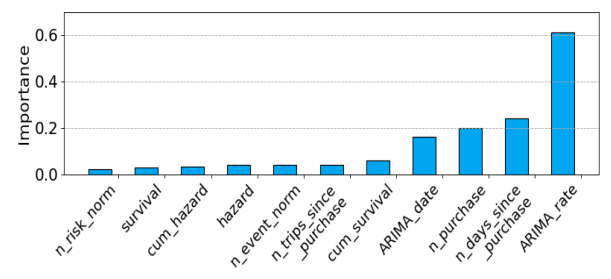
Чтобы получить важность функции, мы заменили оригинальный нервный слой на градиент, повышающий традиционный клюзчик дерева. Значения нанесены на рисунок 2. Мы можем заметить, что прогнозы ARIMA оказывают очень высокое влияние на вывод модели, особенно модель, которая пытается предсказать следующую покупку на основе скорости индивидуального потребления элемента пользователем. Функции выживания оказывают меньшее влияние на качество прогноза, означающее, что покупки других пользователей играют небольшую роль в выкупе пользователя, чем его собственные характеристики. Это может быть одной из причин, по которой такие подходы, как Itemknn или Tifuknn, которые фокусируются на совместном поведении пользователей, не работают так же хорошо, как PCIC. MPG делает скорость захвата потребления со статистической моделью и приближается к PCIC. Такие функции, как количество дней с момента прошлой частоты покупки и явной категории (NUM PUCKE), также имеют высокую важность функции. Если бы мы собрали 3 лучших функций, мы можем сказать, что мы можем предсказать, будет ли пользователь покупать товар сегодня, основываясь на том, сколько раз он покупал раньше, сколько дней с момента его последней покупки у нас, сколько он купил в прошлый раз и сколько времени пройдет.
4.5 Влияние выбора данных поезда и тестирования (Q4)
Мы провели одну неделю самых последних покупок клиентов из этого набора данных для тестирования и использовали один год покупок, совершенных до этой недели для обучения. Заказчик и их покупка продукта рассматривались как повторная покупка в тестовый период только в том случае, если клиент приобрел продукт в период обучения (Y за годы до периода тестирования, Y = 1,5), а также приобрел тот же продукт где -то в испытательный период. Пары (пользователь, категория), приобретенные в течение этой продолжительности, помечены 1 и категории
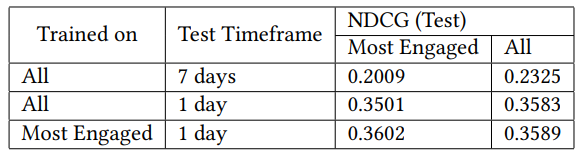
Поскольку пандемия вызвала увеличение внедрения приложения и веб -сайта, пользователи начали покупать в Интернете чаще. Основываясь на первоначальной обратной связи, мы заметили, что список BIA не обновляется, особенно для высоко занятых пользователей. Мы предположили, что это может быть связано с следующими причинами: (1) модель, обучаемая всем пользователям, может не иметь возможности точно захватить сигналы и поведение высокоинтересного пользователя. (2) Метки фиксируются на основе последней 1 недели покупок. Но высоко занятые пользователи делают покупки гораздо чаще, поэтому их этикетки не очень точны. Мы экспериментировали с оценкой модели ежедневно в течение 1 дня покупок пользователей. Мы также экспериментировали на обучении модели только для самых заинтересованных пользователей, определяемых как пользователи, которые совершали покупки в более чем 25 категориях.
В таблице 4 показано улучшение в метрике NDCG для модели ПК с изменениями в сроках тестирования и обучением только самым привлекательным пользователям. Сокращение временной рамки теста значительно улучшило производительность модели. Наиболее заинтересованные пользователи имели более низкую производительность NDCG, чем у всех пользователей, когда даты тестирования составляли 7 дней. Мы также заметили, что обучение модели только на наиболее заинтересованных пользователей улучшает NDCG для всех пользователей, хотя она ведет к экономии времени обучения. Время, необходимое для обучения создания функций и обучения модели для всех пользователей, составляет 2,5 раза больше времени, которое требуется для очень заинтересованных пользователей
Авторы:
(1) Амит Панде, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (amit.pande@target.com);
(2) Кунал Гош, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (kunal.ghosh@target.com);
(3) Парк Ранкинг, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (Rancyung.park@target.com).
Эта статья есть
[2] https://www.kaggle.com/c/acquire-arued-shoppers-challenge/overview
[3] https://www.kaggle.com/c/instacart-market-basket-analysis
[4] https://www.dunnhumby.com/careers/engineering/sourcefiles
[5] https://www.kaggle.com/chiranjivdas09/ta-fengcery-dataset
Оригинал