
Для данных всех форм и размеров, рваные тензоры предлагают дом
28 июля 2025 г.Обзор контента
- Настраивать
- Обзор
- Что вы можете с рваным тензором
- Построение рваного тензора
- Что вы можете хранить в рваном тензоре
- Пример использования
- Рваные и однородные размеры
- Рваный против редкого
- Tensorflow API
- Керас
- tf.example
- Наборы данных
- tf.function
- Сохраненные модели
- Перегруженные операторы
Настраивать
!pip install --pre -U tensorflow
import math
import tensorflow as tf
2024-08-27 01:20:40.536630: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-08-27 01:20:40.557820: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-08-27 01:20:40.563984: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Обзор
Ваши данные бывают разных форм; Ваши тензоры тоже должны.Рваные тензорыЯвляются ли тензорфлоу эквивалент вложенных списков переменной длины. Они позволяют легко хранить и обрабатывать данные с неравномерными формами, в том числе:
- Особенности переменной длины, такие как набор актеров в фильме.
- Партии последовательных входов с переменной длиной, такие как предложения или видеоклипы.
- Иерархические входы, такие как текстовые документы, которые подразделяются на разделы, параграфы, предложения и слова.
- Отдельные поля в структурированных входах, такие как протокольные буферы.
Что вы можете сделать с рваным тензором
Рваные тензоры поддерживаются более чем сотнями операций по тензодару, включая математические операции (например, какtf.addиtf.reduce_mean), массивные операции (напримерtf.concatиtf.tile), String Manipulation Ops (напримерtf.strings.substr), операции управления потоком (напримерtf.while_loopиtf.map_fn) и многие другие:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1724721643.161122 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.164924 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.168750 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.172328 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.183636 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.187178 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.190668 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.194028 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.197422 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.201089 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.204485 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721643.207934 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.469725 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.471772 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.473847 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.475930 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.477949 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.479867 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.481845 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.483831 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.486309 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.488220 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.490205 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.492181 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.532055 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.534019 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.536012 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.538150 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.540140 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.542032 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.543963 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.545991 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.547989 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.551435 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.553772 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1724721644.556197 10064 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]>
<tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]>
<tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]>
<tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Существует также ряд методов и операций, которые специфичны для рваных тензоров, включая заводские методы, методы конверсии и операции по картированию ценностей. Список поддерживаемых операций, см.tf.raggedДокументация пакета.
Рваные тензоры поддерживаются множеством API -интерфейсов TensorFlow, включаяКерасВНаборы данныхВtf.functionВСохраненные модели, иtf.exampleПолем Для получения дополнительной информации проверьте раздел оTensorflow APIниже.
Как и в случае с обычными тензорами, вы можете использовать индексацию в стиле Python для доступа к определенным ломтам рваного тензора. Для получения дополнительной информации обратитесь к разделу оIndexingниже.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
И, как и обычные тензоры, вы можете использовать арифметические и сравнительные операторы Python для выполнения элементных операций. Для получения дополнительной информации проверьте раздел оПерегруженные операторыниже.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Если вам нужно выполнить элементное преобразование в значенияхRaggedTensor, вы можете использоватьtf.ragged.map_flat_values, который принимает функцию плюс один или несколько аргументов, и применяет функцию для преобразованияRaggedTensorЗначения.
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Рваные тензоры могут быть преобразованы в вложенный PythonlistS и NumpyarrayS:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Построение рваного тензора
Самый простой способ построения рваного тензора - использованиеtf.ragged.constant, который строитRaggedTensorсоответствует данному вложенному питонуlistили numpyarray:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'],
[b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']],
[[b'Do', b'you', b'want', b'to', b'come', b'visit'],
[b"I'm", b'free', b'tomorrow']]]>
Рваные тензоры также могут быть построены путем сочетания плоскойценноститензоры срядтензоры, указывающие, как эти значения следует разделить на строки, используя фабричные классовые матоды, такие какtf.RaggedTensor.from_value_rowidsВtf.RaggedTensor.from_row_lengths, иtf.RaggedTensor.from_row_splitsПолем
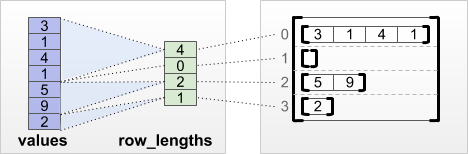
tf.RaggedTensor.from_value_rowids
Если вы знаете, к какой строке принадлежит каждое значение, то вы можете построитьRaggedTensorИспользованиеvalue_rowidsТензор с участием строк:
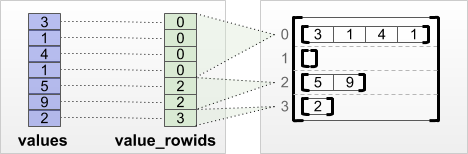
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Если вы знаете, как долго каждая строка, то вы можете использоватьrow_lengthsТензор с участием строк:
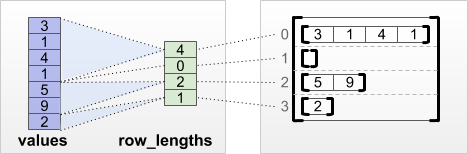
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Если вы знаете индекс, где каждая строка запускается и заканчивается, то вы можете использоватьrow_splitsТензор с участием строк:
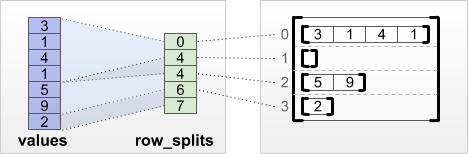
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Увидетьtf.RaggedTensorКлассовая документация для полного списка заводских методов.
Примечание:По умолчанию эти заводские методы добавляют утверждения о том, что тензор раздела строки хорошо сформирован и соответствует количеству значений. Аvalidate=FalseПараметр можно использовать для пропуска этих проверок, если вы можете гарантировать, что входные данные хорошо сформированы и последовательны.
Что вы можете хранить в рваном тензоре
Как и с нормальнымTensorS, значения вRaggedTensorВсе должны иметь одинаковый тип; и все значения должны быть на одной глубине гнездования (классифицироватьтензора):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Пример использования
Следующий пример демонстрирует, какRaggedTensorS может использоваться для построения и комбинирования Unigram и Bigram Entgeddings для партии запросов переменной длины, используя специальные маркеры для начала и конца каждого предложения. Для получения более подробной информации о OPS, используемых в этом примере, проверьтеtf.raggedДокументация пакета.
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor(
[[-0.07189021 0.23444025 -0.04020268 -0.27113184]
[ 0.10560822 0.00976487 -0.17885399 0.5371701 ]
[-0.23479678 -0.15996003 0.07078557 0.24388357]], shape=(3, 4), dtype=float32)
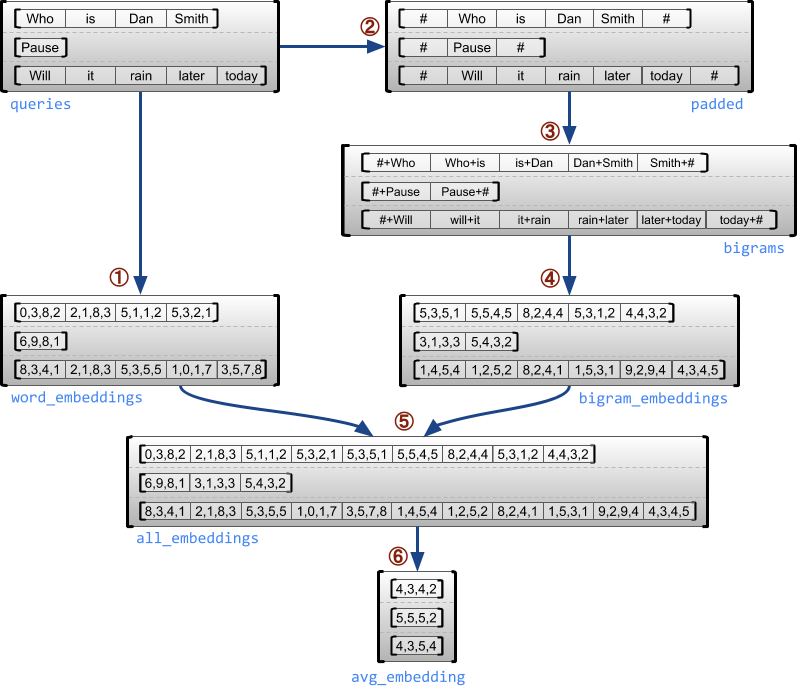
Рваные и однородные размеры
Арваное измерениеэто измерение, ломтики которого могут иметь разные длины. Например, внутреннее (колонковое) измерениеrt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]это рваная, так как колонка срезает (rt[0, :], ..., rt[4, :]) иметь разные длины. Размеры, чьи кусочки имеют одинаковую длину, называютсяравномерные размерыПолем
The outermost dimension of a ragged tensor is always uniform, since it consists of a single slice (and, therefore, there is no possibility for differing slice lengths). The remaining dimensions may be either ragged or uniform. For example, you may store the word embeddings for each word in a batch of sentences using a ragged tensor with shape [num_sentences, (num_words), embedding_size], где скобки вокруг(num_words)Укажите, что измерение оборван.
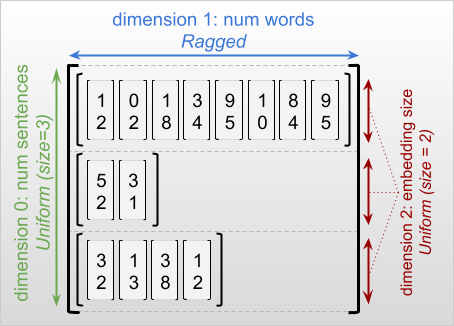
Руганые тензоры могут иметь несколько рваных размеров. Например, вы можете хранить партию структурированных текстовых документов, используя тензор с формой[num_documents, (num_paragraphs), (num_sentences), (num_words)](Где снова скобки используются для обозначения рваных размеров).
Как сtf.Tensor,классифицироватьиз рваного тензора - это общее количество размеров (включая как рваные, так и однородные размеры). АПотенциально рваный тензорэто значение, которое может быть либоtf.Tensorилиtf.RaggedTensorПолем
При описании формы рваного денсора, рваные размеры обычно обозначаются путем охвата в скобках. For example, as you saw above, the shape of a 3D RaggedTensor that stores word embeddings for each word in a batch of sentences can be written as[num_sentences, (num_words), embedding_size]Полем
АRaggedTensor.shapeАтрибут возвращает аtf.TensorShapeДля рваного тензора, где имеют размер размерNone:
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Методtf.RaggedTensor.bounding_shapeможно использовать для поиска плотной ограничивающей формы для данногоRaggedTensor:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Рваный против редкого
Рваный тензор долженnotрассматриваться как тип разреженного тензора. В частности, разреженные тензорыэффективные кодирования дляtf.Tensorкоторые моделируют те же данные в компактном формате; Но рваный тензор - этоРасширение наtf.TensorЭто моделирует расширенный класс данных. Эта разница имеет решающее значение при определении операций:
- Применение ОП к редкому или плотному тензору всегда должно дать один и тот же результат.
- Применение ОП к рваному или разреженному тензору может дать разные результаты.
В качестве иллюстративного примера, рассмотрите, как операции массива, такие какconcatВstack, иtileопределены для рваных и разреженных тензоров. Согласование рваных тензоров соединяет каждую строку, чтобы сформировать одну строку с комбинированной длиной:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'],
[b'my', b'cat', b'is', b'fuzzy']]>
Тем не менее, объединение разреженных тензоров эквивалентно объединению соответствующих плотных тензоров, как показано следующим примером (где Ø указывает на отсутствующие значения):
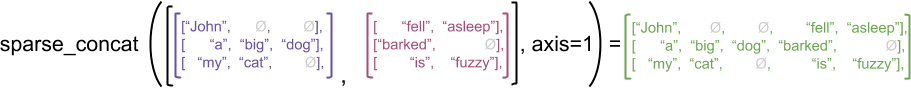
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor(
[[b'John' b'' b'' b'fell' b'asleep']
[b'a' b'big' b'dog' b'barked' b'']
[b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Для другого примера того, почему это различие важно, рассмотрите определение «среднее значение каждой строки» для OP, такого какtf.reduce_meanПолем Для рваного тензора среднее значение для строки - это сумма значений строки, деленные на ширину строки. Но для разреженного тензора среднее значение для ряда - это сумма значений строки, деленные на общую ширину разреженного тензора (которая больше или равна ширине самого длинного ряда).
Tensorflow API
Керас
tf.kerasэто API высокого уровня Tensorflow для создания и обучения моделей глубокого обучения. У него нет рваной поддержки. Но это поддерживает тензоры в масках. Таким образом, самый простой способ использования рваного тензора в модели кераса - это преобразование рваного тензора в плотный тензор, используя.to_tensor()а затем используя маскировку встроенного кераса:
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
hashed_words.to_list()
[[940, 203, 668, 387, 790, 320, 939, 185],
[315, 515, 791, 181, 939, 787],
[564, 205],
[820, 180, 993, 739]]
hashed_words.to_tensor()
<tf.Tensor: shape=(4, 8), dtype=int64, numpy=
array([[940, 203, 668, 387, 790, 320, 939, 185],
[315, 515, 791, 181, 939, 787, 0, 0],
[564, 205, 0, 0, 0, 0, 0, 0],
[820, 180, 993, 739, 0, 0, 0, 0]])>
tf.keras.Input?
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Embedding(hash_buckets, 16, mask_zero=True),
tf.keras.layers.LSTM(32, return_sequences=True, use_bias=False),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words.to_tensor(), is_question, epochs=5)
Epoch 1/5
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1724721648.311913 10235 service.cc:146] XLA service 0x7f82d4008680 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1724721648.311945 10235 service.cc:154] StreamExecutor device (0): Tesla T4, Compute Capability 7.5
I0000 00:00:1724721648.311949 10235 service.cc:154] StreamExecutor device (1): Tesla T4, Compute Capability 7.5
I0000 00:00:1724721648.311952 10235 service.cc:154] StreamExecutor device (2): Tesla T4, Compute Capability 7.5
I0000 00:00:1724721648.311955 10235 service.cc:154] StreamExecutor device (3): Tesla T4, Compute Capability 7.5
1/1 ━━━━━━━━━━━━━━━━━━━━ 4s 4s/step - loss: 8.0590
Epoch 2/5
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 47ms/step - loss: 8.0590
Epoch 3/5
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 44ms/step - loss: 8.0590
Epoch 4/5
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 44ms/step - loss: 8.0590
Epoch 5/5
I0000 00:00:1724721650.626376 10235 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 43ms/step - loss: 8.0590
<keras.src.callbacks.history.History at 0x7f8444309fd0>
print(keras_model.predict(hashed_words.to_tensor()))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 407ms/step
[[-0.00517703]
[-0.00227403]
[-0.00706224]
[-0.00354813]]
tf.example
tf.exampleэто стандартПротобуфКодирование для данных тензора. Данные, закодированные сtf.ExampleS часто включает в себя функции переменной длины. Например, следующий код определяет партию из четырехtf.ExampleСообщения с различной длиной функций:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Вы можете проанализировать эти закодированные данные, используяtf.io.parse_example, который берет тензор сериализованных струн и словарь спецификации функций, и возвращает имена функций сопоставления словаря в тензоры. Чтобы прочитать функции переменной длины в рваные тензоры, вы просто используетеtf.io.RaggedFeatureВ словаре спецификации функции:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]>
lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeatureМожно также использоваться для чтения функций с несколькими рваными размерами. Для получения подробной информации обратитесь кДокументация APIПолем
Наборы данных
tf.dataэто API, который позволяет вам создавать сложные входные трубопроводы из простых многоразовых кусочков. Его основная структура данныхtf.data.Dataset, который представляет последовательность элементов, в которой каждый элемент состоит из одного или нескольких компонентов.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Создание наборов данных с рваными тензорами
Наборы данных могут быть построены из рваных тензоров, используя те же методы, которые используются для их создания изtf.Tensors или numpyarrayS, такие какDataset.from_tensor_slices:
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Примечание:Dataset.from_generatorеще не поддерживает рваные тензоры, но поддержка будет добавлена в ближайшее время.
Пакетная и непредвзятая наборы данных с рваными тензорами
Наборы данных с рваными тензорами могут быть пакетами (которые объединяютсянепоследовательные элементы в один элемент), используяDataset.batchметод
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
И наоборот, пакетный набор данных может быть преобразован в плоский набор данных, используяDataset.unbatchПолем
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Пакетные наборы данных с нереховыми тензорами с переменной длиной
Если у вас есть набор данных, который содержит нереховые тензоры, а длины тензора варьируются в зависимости от элементов, то вы можете превратить эти нереховые тензоры в рваные тензоры, применяяdense_to_ragged_batchПреобразование:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_10064/1427668168.py:4: dense_to_ragged_batch (from tensorflow.python.data.experimental.ops.batching) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.ragged_batch` instead.
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]>
<tf.RaggedTensor [[0, 1, 2], [0, 1]]>
<tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Преобразование наборов данных с рваными тензорами
Вы также можете создавать или преобразовать рваные тензоры в наборах данных, используяDataset.map:
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0:
mean_length = 7
length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]>
Element 1:
mean_length = 0
length_ranges = <tf.RaggedTensor []>
Element 2:
mean_length = 2
length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]>
Element 3:
mean_length = 3
length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.functionявляется декоратором, который предварительно считывает графики тензора для функций Python, что может существенно повысить производительность вашего кода TensorFlow. Рваные тензоры могут быть использованы прозрачно с помощью@tf.function-Корированные функции. Например, следующая функция работает как с рваными, так и с нереховыми тензорами:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2024-08-27 01:20:51.662289: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:933] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9
<tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Если вы хотите явно указатьinput_signatureдляtf.function, тогда вы можете сделать это, используяtf.RaggedTensorSpecПолем
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>,
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Конкретные функции
Конкретные функцииинкапсулировать отдельные прослеженные графики, которые построеныtf.functionПолем Рваные тензоры можно использовать прозрачно с помощью конкретных функций.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Сохраненные модели
АСохраняйте модельявляется сериализованной программой Tensorflow, включая веса и вычисления. Он может быть построен из модели Keras или из пользовательской модели. В любом случае, рваные тензоры могут быть прозрачно использовать функциями и методами, определяемыми SavedModel.
Пример: сохранение модели кераса
import tempfile
keras_module_path = tempfile.mkdtemp()
keras_model.save(keras_module_path+"/my_model.keras")
imported_model = tf.keras.models.load_model(keras_module_path+"/my_model.keras")
imported_model(hashed_words.to_tensor())
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[-0.00517703],
[-0.00227403],
[-0.00706224],
[-0.00354813]], dtype=float32)>
Пример: сохранение пользовательской модели
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpkmr703wo/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpkmr703wo/assets
<tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Примечание:Сохраняйте модель
Перегруженные операторы
АRaggedTensorКласс перегружает стандартные арифметические и сравнительные операторы Python, что позволяет легко выполнить основную элементную математику:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Поскольку перегруженные операторы выполняют элементные вычисления, входные данные для всех бинарных операций должны иметь одинаковую форму или быть транслируемыми до той же формы. В простейшем вещательном случае один скаляр объединяется в элементе с каждым значением в рваном тензоре:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Для обсуждения более продвинутых случаев проверьте раздел оВещаниеПолем
Рваные тензоры перегружают тот же набор операторов, что и обычноTensorS: Унарные операторы-В~, иabs(); и бинарные операторы+В-В*В/В//В%В**В&В|В^В==В<В<=В>, и>=Полем
Первоначально опубликовано на __Tensorflow__website, эта статья появляется здесь под новым заголовком и имеет лицензию в соответствии с CC на 4.0. Образцы кода, разделенные по лицензии Apache 2.0.
Оригинал