
Несколько выстрелов против одного выстрела против нулевого выстрела обучения
10 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Фон
- Тип данных датчика дистанционного зондирования
- Clarkmark Demote Sensing Dataets для оценки моделей обучения
- Метрики оценки для нескольких ударов дистанционного зондирования
- Недавние методы обучения в дистанционном зондировании
- Обнаружение и сегментация объекта на основе нескольких выстрелов в дистанционном зондировании
- Обсуждения
- Численные эксперименты нескольких выстрелов в наборе данных на основе БПЛА
- Объяснимый ИИ (XAI) в дистанционном зондировании
- Выводы и будущие направления
- Благодарности, декларации и ссылки
2 фона
Несколько выстрелов (FSL)-это новый подход в области машинного обучения, который позволяет моделям получать знания и делать точные прогнозы с ограниченными примерами обучения на класс или контекст в конкретной проблемной области. В отличие от традиционных методов машинного обучения, которые требуют огромного количества учебных данных, FSL стремится достичь сопоставимых уровней производительности, используя значительно меньше примеров обучения. Эта способность учиться из дефицитных данных делает FSL хорошо подходить для приложений, где сборы значительных учебных наборов могут быть чрезмерно дорогими или иным образом невозможным.
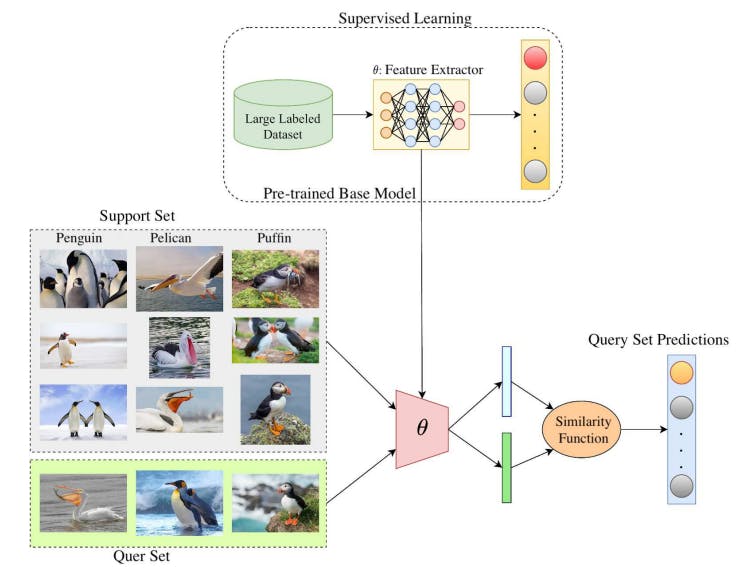
В традиционном машинном обучении модели обучаются с нуля на больших помеченных наборах данных. Напротив, FSL стремится изучить новые концепции из нескольких примеров, используя обучение переносу из моделей, предварительно обученных другим задачам. Во -первых, базовая модель предварительно подготовлена на большом наборе данных для такого задачи, как классификация изображений. Это обеспечивает модель с общими представлениями функций, которые могут быть переданы. Затем для новой нескольких выстрела, предварительная модель используется в качестве отправной точки. Набор поддержки из нескольких помеченных примеров для новых классов используется для тонкой настройки предварительно предварительно проведенной модели. Как правило, только последний слой переподходит для адаптации модели к новым классам, чтобы использовать предварительно обученные функции. Наконец, адаптированная модель оценивается на наборе запросов. Набор запросов содержит немеченые примеры, которые модель должна делать прогнозы, основываясь на шаблонах, изученных из небольшого набора поддержки для каждого нового класса. Это проверяет, насколько хорошо модель может обобщить на новые примеры классов после адаптации только с несколькими выстрелами. Чтобы получить более четкий вид, весь этот процесс показан на рисунке 3.
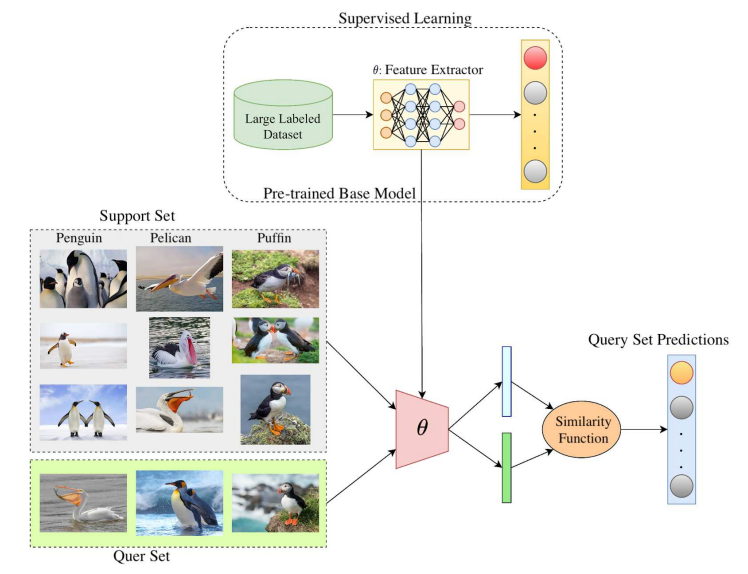
Подходы в классификации FSL часто могут быть классифицированы на основе количества новых категорий, необходимых для обобщения, называемых N, а также количества помеченных образцов или классов, доступных в наборе поддержки для каждого из Ne New Class, называемых K. Как правило, более низкое значение K делает более сложной задачей для нескольких выстрелов для достижения высокой точности классификации, так как в поддержке, установленном модели, получено меньше вспомогательной информации, чтобы помочь модели в достижении точных прогнозов. Эта схема обычно называется «N-Way K-Shot Scheme». Кроме того, в случаях, когда K равно 0, такие схемы часто называют обучением с нулевым выстрелом.
Первоначальное исследование FSL в сочетании с беспилотными термическими изображениями на основе беспилотного летательного аппарата (БПЛА) было предпринято [10, 11]. Их новаторская работа продемонстрировала потенциал FSL для задач на основе БПК, где ограниченные встроенные вычислительные ресурсы налагают строгие ограничения на сложность модели и объем обучения данных. Основной целью FSL является создание моделей, которые могут идентифицировать скрытые закономерности в определенной области, используя ограниченные учебные примеры, а затем использовать эти изученные знания для эффективного классификации и классификации новых вводов. Эта возможность внимательно отражает человеческое обучение, где люди часто могут понимать ядро новой концепции из одного или двух примеров. Сокращая зависимость от обширных обучающих наборов, FSL облегчает разработку систем машинного обучения, применимых к реальным проблемам с помощью данных в широком спектре доменов.
![Fig. 4 (Left) Similarity function as applied to each pair of images in the AIDER dataset [12]. The image on the left and middle constitute a fire disaster class, and the image on the right is a non-disaster class (normal). (Right) A query image of the flood disaster class is compared with the images from the support set via the similarity function and a correct class prediction is made based on the similarity score. In this case the flood disaster class is correctly predicted and classified.](https://cdn.hackernoon.com/images/null-st134lt.png)
2.1 Функции сходства для нескольких выстрелов
Функция сходства является критическим компонентом связывания набора поддержки и набора запросов в обучении с несколькими выстрелами. Пример в контексте классификации сцены воздушной стихийной катастрофы с использованием набора данных Aider [12] показан на рисунке 4. Левая сторона рисунка показывает, как выполняется оценка функции сходства между каждой парой изображений, причем левые и средние изображения представляют класс пожарной катастрофы и правое изображение, представляющее недисцидиастерный класс (или нормальный класс). Правая сторона рисунка показывает, как функция сходства может использоваться в сочетании с изображением запроса, а также из набора поддержки, чтобы сделать прогноз в правильном классе (наводнение) на основе показателей сходства.
При нескольких выстрелах функция выбора потерь имеет решающее значение для обеспечения эффективного обобщения из ограниченных примеров. Некоторые обычно используемые функции потерь включают потерю триплета, контрастные потери и потерю поперечной энтропии. Потеря триплета помогает моделям изучать полезные представления признаков, минимизируя расстояние между эталонной выборкой и положительной выборкой одного класса, при этом максимизируя расстояние до отрицательной выборки от другого класса. Это обеспечивает мелкозернистую дискриминацию между классами. Контрастная потеря полезна для обучения энкодеров, чтобы захватить семантическое сходство между дополненными взглядами того же примера. Это повышает надежность ввода вариаций. Потери поперечной энтропии обычно используется для обучения классификаторов в нескольких выстрелах, что позволяет эффективно обучаться из дефицитных маркированных данных. Тем не менее, он может страдать от переживания из -за ограниченных примеров. Методы регуляризации, такие как сглаживание метки, могут помочь смягчить это. Другие усовершенствованные потери, такие как потери мета-обучения на основе параметров модели, показали перспективу для быстрой адаптации в нескольких выстрелах. В целом, выбор функции потерь играет ключевую роль в решении критических проблем с небольшим количеством выстрелов, таких как переосмысление, обучение представлений функций и быстрое обобщение. Дальнейшие исследования специализированных потерь могут продолжать улучшать несколько выстрелов
Для сценария, изображенного на левой стороне рисунка 4, потери триплета Ltriplet [13] является примером функции сходства, которая может быть использована. Потеря триплета включает в себя сравнение класса якоря с положительным классом выборки и отрицательного класса выборки. Цель состоит в том, чтобы минимизировать евклидово расстояние между якорем и положительным классом на основе функции сходства F и максимизировать расстояние между якорем и отрицательным классом. Это можно суммировать математически в уравнении 1 как
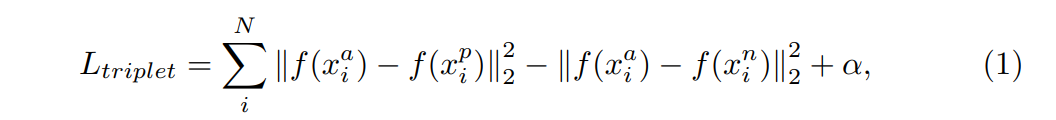
В уравнении 1 якорь, положительные и отрицательные образцы класса обозначены как A, P и N, соответственно. Индекс I относится к индексу входного образца, N обозначает общее количество образцов в наборе данных, а α является термином смещения, действующим в качестве порога. Подписк 2 указывает на то, что оцениваемое евклидовое расстояние является потерей L2, и SuperScript 2 соответствует квадрату каждого скобку. Второй термин с отрицательным знаком позволяет максимизировать расстояние между якорем и отрицательным образцом класса.
Сети, которые используют потерю триплета для нескольких выстрелов, также называются триплетными сетями. С другой стороны, для сравнения пар изображений обычно используются сиамские сети. В таких случаях функция контрастных потерь Lcontrastive [14] может быть лучшим выбором для определения сходства или потери, хотя потери триплета также могут быть использованы. Контрастная потеря может быть выражена математически, как показано в уравнении 2:
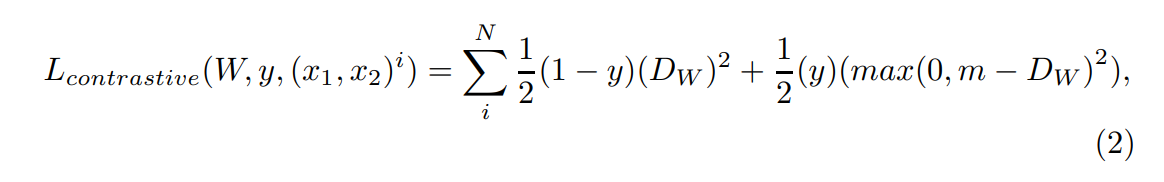
В уравнении 2 y обозначает, являются ли две точки данных, x1 и x2, в данном наборе I, одинаковыми (y = 0) или разнородными (y = 1). Черты маржи M определяется пользователем, в то время как DW является метрикой сходства, которая дается:
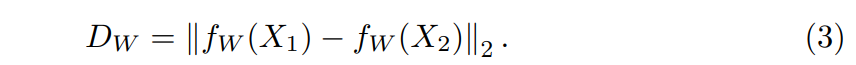
Подобно предыдущему методу, используется евклидовое расстояние на основе потерь L2, где первый термин в уравнении 3 соответствует аналогичным точкам данных, а второй термин соответствует разнородным.
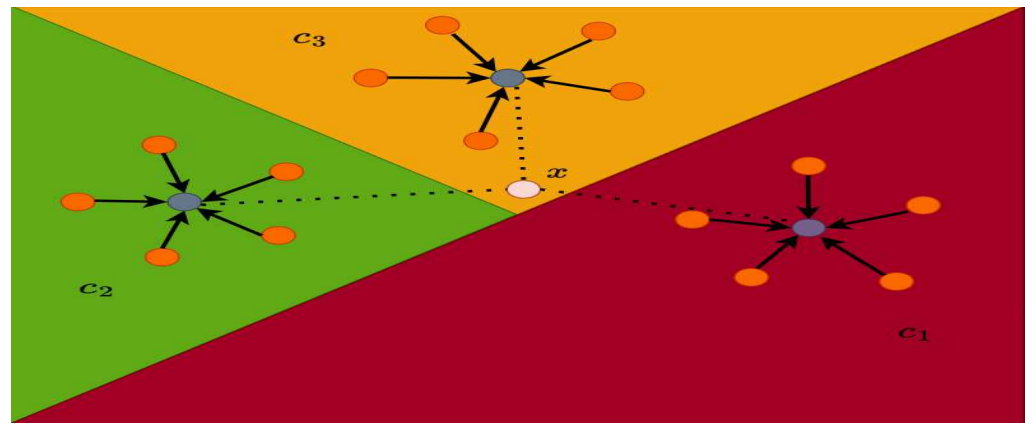
Третий тип сети для нескольких выстрелов может быть реализован как прототипная сеть, как это представлено Snell et al. [15]. Этот метод использует пространство для встраивания, в котором образцы из одного класса кластерируются вместе. На рисунке 3 приведен пример, чтобы продемонстрировать эту концепцию. Для каждого кластера типичный прототип класса рассчитывается как среднее значение точек данных в этой группе. Расчет прототипа класса может быть выражена математически, как показано в уравнении 4:

Прототипические сети и сиамские или триплетные сети представляют собой разные подходы к обучению, которые сравнивают запросы и поддерживают образцы по-разному. В то время как сиамские или триплетные сети напрямую сравнивают образцы запросов и поддержки в парах или триплетах, прототипическая сеть сравнивает образцы запроса со средним значением их набора поддержки. Это достигается путем расчета представления прототипа каждого класса в встроенном метрическом пространстве, что является средним значением векторов признаков всех образцов поддержки для этого класса. Это может быть визуализировано на рисунке 5. Однако для одноразового обучения, где для каждого класса доступен только один образец поддержки, три подхода становятся эквивалентными, поскольку представление прототипа становится идентичным представлению выборки поддержки. В целом, выбор подхода на несколько выстрелов может зависеть от конкретных характеристик набора данных и доступных образцов поддержки.
2.2 Важность объяснимого ИИ в дистанционном зондировании
Дистанционное зондирование и анализ спутниковых изображений быстро прогрессировали благодаря искусственному интеллекту и машинному обучению. Модели машинного обучения могут идентифицировать объекты и закономерности в огромных количествах спутниковых данных с невероятной точностью, превосходя возможности человека. Тем не менее, эти сложные модели машинного обучения часто считаются «черными ящиками» - они обеспечивают очень точные прогнозы и обнаружения, но неясно, почему они делают эти прогнозы.
Объясняемый ИИ - это новая область исследования, ориентированная на создание моделей машинного обучения и их прогнозы более прозрачными и понятными для людей. Объяснимые методы ИИ необходимы для таких приложений, как дистанционное зондирование, где решения могут иметь серьезные реальные последствия [16]. Например, модель машинного обучения, которая обнаруживает признаки стихийных бедствий, таких как лесные пожары на спутниковых изображениях, должна дать объяснение его прогнозов, чтобы человеческие операторы могли проверить результаты перед принятием мер. Есть несколько подходов к созданию моделей машинного обучения, используемых для дистанционного зондирования более объяснимыми.
• Подчеркивание важных функций:Такие методы, как карты значимости, могут выделить наиболее важные части изображения для прогнозирования модели машинного обучения. Например, модели компьютерного зрения могут выделять функции, которые они используют для обнаружения объектов в спутниковых изображениях, что позволяет исправлять ошибки. Аналогичным образом, модели обнаружения аномалий могут указывать на области, которые привели их к тому, чтобы пометить необычную активность, что позволяет проверить истинные позитивы по сравнению с ложными тревогами.
• Упрощение сложных моделей:Сложные модели машинного обучения могут быть преобразованы в упрощенные объяснения, которые люди могут понять, например, логические правила и деревья решений. Например, политика обучения глубокого подкрепления для навигации спутников может быть выражена в виде упрощенного набора правил IFTHEN, выявляя любые ошибочные предположения. Эти упрощенные объяснения делают сложные возможности машинного обучения более доступными для экспертов домена.
• Различные входные данные для понимания ответов:Другой объясняемый метод ИИ заключается в том, чтобы систематически варьировать входы к модели машинного обучения и наблюдать, как его выходы изменяются в ответ. Например, генеративные модели, которые создают новые реалистичные спутниковые изображения, могут быть оценены путем генерации изображений с различными атрибутами для определения их возможностей и ограничений. Анализ, как прогнозы модели варьируются в зависимости от изменений в ее входе, дает представление о том, как она работает и когда она может дать ненадежные результаты.
В целом, объясняемый ИИ может укрепить доверие к системам машинного обучения и позволяет людям лучше использовать ИИ для таких приложений, как дистанционное зондирование. Объяснение моделей машинного обучения также позволяет доменным экспертам обеспечивать обратную связь, которая может улучшить модели. Например, эксперты в области дистанционного зондирования могут заметить смещения или ошибки в объяснениях модели машинного обучения, которые могут сбиться с пути модели. Предоставляя эту обратную связь, эксперты могут помочь ученым -ученым усовершенствовать и переучить модель машинного обучения, чтобы избежать этих проблем.
Короче говоря, объясняемый ИИ имеет значительное обещание для обеспечения машинного обучения и дистанционного зондирования эффективно работать вместе. Сделав модели машинного обучения и прогнозы прозрачными, объясняемый ИИ позволяет:
• Люди, чтобы проверить и доверять результатам моделей машинного обучения, прежде чем предпринять последовательные действия, основанные на них.
• Эксперты по домену, чтобы обеспечить обратную связь, которая улучшает модели машинного обучения и избегает потенциальных проблем.
• Лучшее понимание сильных сторон, слабостей и ограничений машинного обучения, которые могут направлять, как технология разрабатывается и применяется в дистанционном зондировании.
Объясняемый ИИ будет ключом к обеспечению ответственного использования машинного обучения и для полного потенциала для дистанционного зондирования и за его пределами. Построение партнерских отношений между людьми и ИИ может привести к будущему с технологиями, которая расширяет возможности человека, а не заменяет их.
Авторы:
(1) Гао Ю Ли, Школа электротехники и электронных инженеров, Нанянг Технологический университет, 50 Нанянг -авеню, 639798, Сингапур (Gaoyu001@e.ntu.edu.sg);
(2) Плотина Танмой, Школа машиностроения и аэрокосмической инженерии, Технологический университет Наняна, 65 Нанянг Драйв, 637460, Сингапур и Департамент компьютерных наук, Университет Нью -Орлеана, Новый Орлеан, 2000 Лейкшор Драйв, LA 70148, США (США (США.tanmoy.dam@ntu.edu.sg);
(3) MD Meftahul Ferdaus, Школа электротехники и электронного инженера, Нанянг Технологический университет, 50 Nanyang Ave, 639798, Сингапур (mferdaus@uno.edu);
(4) Даниэль Пуйу Понар, Школа электротехники и электронных инженеров, Технологический университет Наняна, пр. Наняна, 639798, Сингапур (Epdpuiu@ntu.edu.sg);
(5) Vu N. Duong, Школа машиностроения и аэрокосмической инженерии, Nanyang Technological University, 65 Nanyang Drive, 637460, Сингапур (vu.duong@ntu.edu.sg)
Эта статья есть
Оригинал