

Быстрая, более точная безопасность IoT: количественный анализ структуры Cumad
2 июля 2025 г.Авторы:
(1) MD Mainuddin, факультет компьютерных наук, Университет штата Флорида, Таллахасси, FL 32306 (mainuddi@cs.fsu.edu);
(2) Zhenhai Duan, кафедра компьютерных наук Флорида Университет штата Таллахасси, FL 32306 (duan@cs.fsu.edu);
(3) Yingfei Dong, факультет электротехники, Гавайский университет Гонолулу, HI 96822 США (yingfei@hawaii.edu).
Таблица ссылок
Аннотация и 1. Введение
2. Связанная работа
3. Фон на AutoEncoder и SPRT и 3.1. AutoEncoder
3.2. Тест на коэффициент последовательного вероятности
4. Дизайн Cumad и 4.1. Сетевая модель
4.2. Cumad: кумулятивное обнаружение аномалий
5. Оценные исследования и 5.1. Набор данных, функции и настройка системы Cumad
5.2. Результаты производительности
6. Выводы и ссылки
5. Оценные исследования
В этом разделе мы проводим оценку, чтобы исследовать эффективность Cumad, используя набор данных N-BAIOT PublicDomain [8]. Чтобы лучше понять оценки, мы сначала опишем набор данных, в частности, функции точек данных, содержащихся в наборе данных. Мы также будем сравнивать производительность Cumad с производительностью схемы N-BAIOT (что является именем как для набора данных, так и соответствующей схемы при обнаружении скомпрометированных устройств IOT) [8].
5.1. Набор данных, функции и настройка системы Cumad
N-BAIOT содержит как доброкачественное, так и доброкачественное и (Mirai и Bashlite) атаковать трафик 9 коммерческих устройств IoT, в том числе два дверных звонка (Danmini и Ennio), термостат Ecobee, три монитора ребенка (разные модели от Provision и Philips), две камеры Simplehome Security и Samsung Webcam. Доброкачественный трафик устройства IoT был собран сразу после того, как соответствующее устройство IoT было подключено к экспериментальному испытательному стенду. Был осторожен, чтобы гарантировать, что различные репрезентативные нормальные операции и поведение устройств IoT были собраны в доброкачественный набор данных.

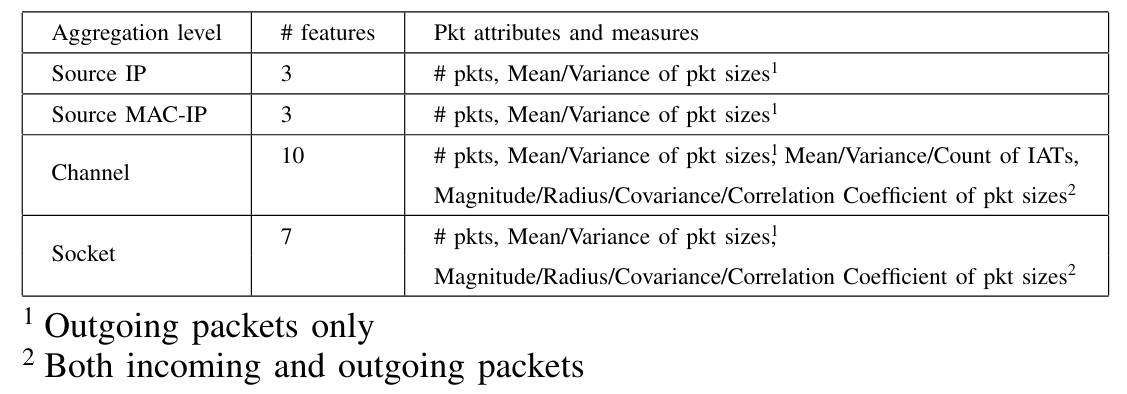
В наборе данных N-BAIOT каждая точка данных соответствует прибывшему пакету и содержит 115 статистических функций, которые вместе представляют поведенческий снимок, который описывает контекст соответствующего пакета, когда он прибывает в точку сбора данных. Снимок содержит информацию об исходном и назначенном устройстве, информацию о протоколе, среди прочего. Более конкретно, 115 функций были извлечены следующим образом. Для каждого прибывающего пакета в общей сложности 23 функции были собраны на разных уровнях агрегации (см. Таблицу 1), включая функции, агрегированные на уровне исходного IP -адреса, на уровне Source Mac и IP -адресов, на уровне канала (источник и назначение IP -адреса), а также на уровне сокетов (исходные и IP -адреса и номера портов). Эти 23 функции были извлечены в скользящее окно, более 5 временных окон 100 мс, 500 мс, 1,5 секунды, 10 секунд и 1 минуты соответственно, генерируя в общей сложности 115 функций для каждой точки данных.
Мы используем последовательную модель Keras в качестве основы для нашей разработки AutoEncoder [12]. Входное измерение модели установлено, чтобы соответствовать количеству функций в наборе данных (то есть 115). Чтобы обеспечить эффективное сжатие, мы реализуем три скрытых слоя внутри энкодера. Эти слои постепенно снижают размеры до 87, 58, 38 и 29, соответственно, причем последним (29) является измерение выходного слоя энкодера, то есть измерения полученного кода. И наоборот, компонент декодера отражает размеры слоев энкодера в обратном порядке, начиная с 38. Используя сжатие и декомпрессию в слоях кодера и декодера, мы эффективно устраняем избыточную информацию из функций входных точек данных. Чтобы оптимизировать производительность обучения, мы используем оптимизатор ADAM, и средняя квадратная ошибка используется в качестве ошибки реконструкции (объективная функция модели).
SPRT требует четырех пользовательских параметров, чтобы вычислять верхние и нижние границы A и B (см. Уравнение (3)), а также функцию этапа для вычисления λn после каждого наблюдения (см. Уравнение (1)). Желаемые значения как для ложной положительной скорости, так и для ложной отрицательной скорости (представленных α и β, соответственно), как правило, очень малы. В этом исследовании мы устанавливаем как α, так и β до 0,01. В идеале, параметр θ указывает на истинную вероятность того, что наблюдение будет классифицируется как аномалия, либо из доброкачественного, либо скомпрометированного устройства IoT. Мы определяем значения для θ0 и θ1 через наши предварительные исследования и устанавливаем их до 0,2 и 0,8 соответственно.
5.2. Результаты производительности
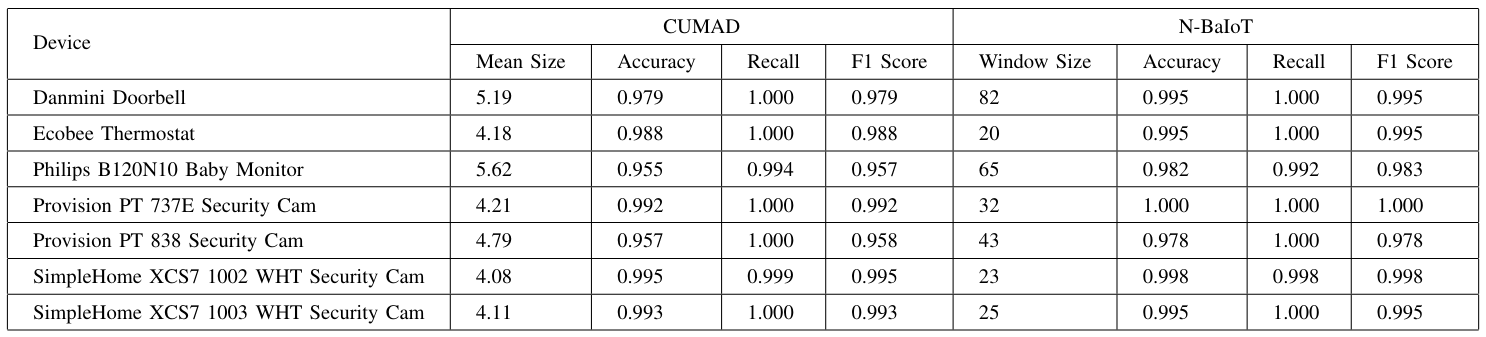
В таблице 2 показана производительность CUMAD в обнаружении устройств IoT, с точки зрения точности, отзывания и оценки F1 [12]. Из таблицы мы видим, что Cumad достигает превосходной производительности во всех трех показателях. Например, для 5 устройств IoT CUMAD может обнаружить все скомпрометированные случаи (см. Столбец отзыва). CUMAD также может обнаружить подавляющее большинство скомпрометированных случаев для оставшихся двух устройств IoT, причем оценки отзыва 0,999 и 0,994. Учитывая точность обнаружения атаки, так и доброкачественный трафик, мы видим, что Cumad также работает очень хорошо, с показателем точности от 0,955 до 0,995 для всех 7 устройств IoT. Оценки F1, которые являются средневзвешенными показателями точности и отзыва модели, также подтверждают, что Cumad хорошо работает при обнаружении скомпрометированных случаев.
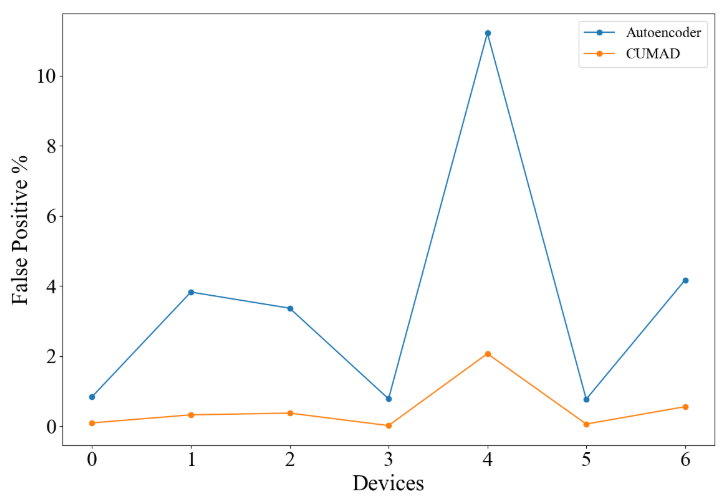
На рисунке 4 показаны ложные положительные показатели схемы обнаружения аномалий на основе аутокодера и Cumad. Как показано на рисунке, ложные положительные показатели схемы обнаружения аномалий на основе аутокодера для 7 устройств IoT варьируются от 0,77% до 11,22%, в то время как ложные положительные показатели Cumad варьируются от 0,014% до 2,067%. В среднем схема обнаружения аномалий на основе автоэкодера имеет около 3,57% ложную положительную скорость, в то время как ложная положительная скорость CUMAD составляет около 0,5%, что составляет около 7 раз улучшение эффективности с точки зрения ложной положительной скорости для CUMAD по сравнению с схемой обнаружения аномалий на основе аутокодера.
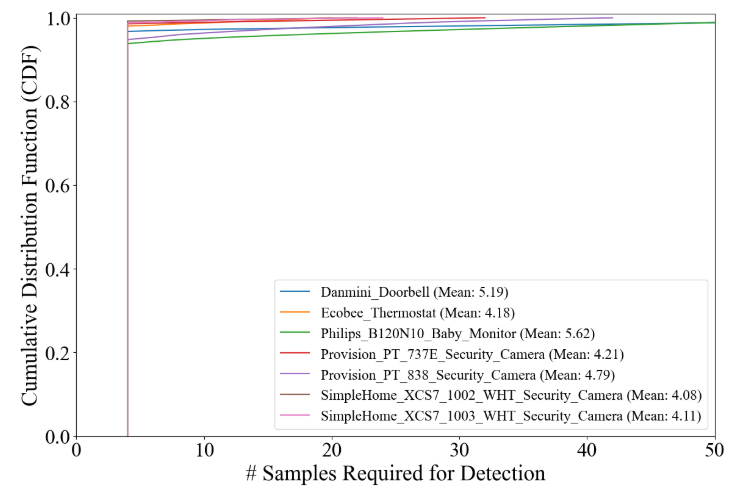
Для сравнения производительности мы также включаем в таблицу результаты производительности схемы N-BAIOT с той же настройкой оценки. Из таблицы мы видим, что Cumad и N-Baiot работают сравнительно с точки зрения всех трехэтапных показателей. Тем не менее, N-BAIOT работает на фиксированном размере окна. В таблице 2 показано, что N-BAIOT требует относительно большого размера окна, в диапазоне от 20 до 82 (столбец с размером окна имени). Напротив, Cumad работает в онлайн -моде и не требует такого фиксированного размера окна. В таблице 2 показано среднее количество наблюдений, необходимых для достижения CUMAD для обнаружения (столбец со средним размером имени); Из таблицы мы видим, что для Cumad для Cumad требуется в среднем менее 5 наблюдений, чтобы обнаружить скомпрометированный случай, намного быстрее, чем NBAIOT. Чтобы лучше понять количество наблюдений для Cumad, чтобы сделать обнаружение скомпрометированного случая, на рисунке 5 показана функция совокупной распределения (CDF) необходимых наблюдений для CUMAD, чтобы сделать обнаружение для всех 7 устройств IoT. Из рисунка мы видим, что подавляющее большинство обнаружения требует менее 10 наблюдений для всех 7 устройств IoT.
Таким образом, по сравнению с простыми схемами обнаружения аномалий, такими как те, которые только на основе автоходоров CUMAD может значительно снизить ложные положительные показатели, что делает CUMAD гораздо более привлекательным, чем простые схемы обнаружения аномалий в развертывании реального мира. По сравнению со схемами на основе окон, такими как N-BAIOT, CUMAD требует гораздо меньше наблюдений, чтобы достичь обнаружения, и, таким образом, может обнаружить скомпрометированные устройства IoT намного быстрее.
6. Выводы
В этой статье мы разработали Cumad, совокупную структуру обнаружения аномалий для обнаружения скомпрометированных устройств IoT. CUMAD использует автопослов неконтролируемой нейронной сети, чтобы классифицировать, является ли отдельная точка входных данных аномальными или нормальными. CUMAD также включает в себя статистический тест последовательного коэффициента вероятности инструмента (SPRT), чтобы накапливать достаточные доказательства для определения того, скомпрометировано ли устройство IoT, вместо того, чтобы непосредственно полагаться на отдельные точки входных данных. Cumad может значительно улучшить производительность в обнаружении скомпрометированных устройств IoT с точки зрения ложной положительной скорости по сравнению с методами, полагающимися только на отдельные точки аномальных входных данных. Кроме того, в качестве последовательного метода Cumad может быстро обнаружить скомпрометированные устройства IoT. Оценные исследования, основанные на наборе данных IoT общедоступного домена N-BAIOT, подтвердили превосходную производительность CUMAD.
Ссылки
[1] Инь Минн П.А. Па, Сёго Сузуки, Катсунари Йошиока, Цутуму Мацумото, Такахиро Касама и Кристиан Россоу. IOTPOT: анализ роста компромиссов IoT. В материалах 9 -й конференции USENIX по наступательным технологиям, страницы 9–9, 2015.
[2] Майкл Фаган, Катерина Мегас, Карен Скарфоне и Мэтью Смит. Основополагающая кибербезопасность для производителей устройств IoT. Технический отчет, Национальный институт стандартов и технологий, май 2020 года.
[3] Мохаммед Али Аль-Гаради, Амр Мохамед, Абдулла Халид аль-Али, Сяоцзян Дю, Ихсан Али и Мохсен Гуйзани. Обзор методов машины и глубокого обучения для безопасности Интернета вещей (IoT). IEEE Communications Surveys & Tuperials, 22 (3): 1646–1685, 2020.
[4] Эндрю повар, Гоксель Мысирли и Фан Чжун. Обнаружение аномалий ¨ Для данных временных рядов IoT: опрос. IEEE Internet of Things Journal, 7 (7): 6481–6494, 2019.
[5] Варун Чандола, Ариндам Банерджи и Випин Кумар. Обнаружение аномалии: опрос. Вычислительные исследования ACM (CSUR), 41 (3): 1–58, 2009.
[6] Ян Гудфеллоу, Йошуа Бенгио и Аарон Курвилл. Глубокое обучение. MIT Press, 2016. http://www.deeplearningbook.org.
[7] Авраам Уолд. Последовательный анализ. John Wiley & Sons, Inc, 1947.
[8] Яир Мейдан, Майкл Бохадана, Яэль Матхав, Йисроэль Мирски, Асаф Шабтай, Доминик Брейтенбахер и Юваль Эловичи. NBAIOT-обнаружение атаки IoT на основе сети с использованием глубоких автоходоров. IEEE Провасивные вычисления, 17 (3): 12–22, 2018.
[9] Гуансун Панг, Чунхуа Шен, Лонгбинг Цао и Антон Ван Ден Хенгель. Глубокое обучение для обнаружения аномалий: обзор. Вычислительные исследования ACM (CSUR), 54 (2): 1–38, 2021.
[10] Эрол Геленбе и Мерт Накип. Последовательное обучение на основе трафика во время атак ботнетов для выявления скомпрометированных устройств IoT. IEEE Access, 10: 126536–126549, 2022.
[11] Тиен Дук Нгуен, Сэмюэль Марчал, Маркус Миеттинен, Хоссейн Фереидуни, Н Асокан и Ахмад-Реса Садеги. D¨ıot: федеративная система обнаружения аномалий самообучения для IoT. В 2019 году IEEE 39 -я Международная конференция по распределенным вычислительным системам (ICDCS), стр. 756–767. IEEE, 2019.
[12] Франсуа Чолле. Глубокое обучение с питоном. Саймон и Шустер, 2021.
Эта статья естьДоступно на Arxivв соответствии с CC по 4.0 Deed (Attribution 4.0 International) лицензия.
Оригинал