
Экспериментирование с уязвимым вулканом CHATGP
29 июля 2025 г.Таблица ссылок
Аннотация и I. Введение
II Связанная работа
Iii. Технический фон
IV Систематическое обнаружение уязвимости безопасности моделей генерации кодов
V. Эксперименты
VI Дискуссия
VII. Заключение, подтверждение и ссылки
Приложение
A. Подробности моделей языка кода
B. Поиск уязвимостей безопасности в GitHub Copilot
C. Другие базовые линии с использованием CHATGPT
D. Влияние различных числа нескольких примеров
E. Эффективность в создании конкретных уязвимостей для C -кодов
F. Результаты уязвимости безопасности после дедупликации нечеткого кода
G. Подробные результаты передачи сгенерированных небезопасных подсказок
H. Подробная информация о генерации набора данных небезопасных подсказок
I. Подробные результаты оценки кодельмов с использованием набора данных небезопасного
J. эффект температуры отбора проб
K. Эффективность схемы инверсии модели при восстановлении уязвимых кодов
L. Качественные примеры, сгенерированные CodeGen и CHATGPT
М. Качественные примеры, сгенерированные GitHub Copilot
V. Эксперименты
В этом разделе мы представляем результаты нашей экспериментальной оценки. Во -первых, мы объясняем детали экспериментальной установки. Затем мы предоставляем результаты обнаружения уязвимостей моделей и изучают эффективность и масштабируемость предложенного подхода. Мы также исследуем передачу сгенерированных небезопасных подсказок в разных моделях. Кроме того, используя наш метод, мы предоставляем разнообразный набор из 280 подсказок для различных типов уязвимостей безопасности. Этот набор данных позволяет нам сравнивать современные модели.
А. Установка
Мы начинаем с обзора настройки, включая детали моделей, несколько выстрелов, стратегии выборки и настройки CodeQL.
1) Модели генерации кода:Чтобы оценить предлагаемый наш подход, мы сосредоточимся на двух моделях: CodeGen с 6 миллиардами параметров [6] и модели CHATGPT [4], [52] Мы предоставляем детали каждой модели в Приложении A. В дополнение к этим моделям, мы также предоставляем результаты для помощника программирования GitHub Copilot AI [9] в приложении B.
В процедуре генерации небезопасных подсказков и кодов для модели CHATGPT после предыдущей работы Ouyang et al. [3], мы используем инструкцию для руководства моделью для создания желаемых кодов. Например, в процедуре генерации небезопасных подсказок Python с учетом нескольких выстрелов или ввода одного выстрела мы обучаем CHATGPT следующим образом:
‘‘ Вы разработчик Python. Учитывая приведенные примеры кода, заполните следующий код. Определите функцию и напишите описание задачи как комментарий Python. Предоставить всеобъемлющие комментарии. Не пишите никаких объяснений. Напишите только коды Python. ''
Используя приведенную выше инструкцию, мы воспроизводим CHATGPT для генерации подсказок Python с комплексными комментариями, а также рекомендуем модель вывести код для желаемого языка.
В процедуре генерации кода Python мы обучаем CHATGPT, используя следующую инструкцию:
‘‘ Вы разработчик Python. Заполните следующий код Python: ’’.
Мы предоставляем наши наблюдения о других потенциальных базовых показателях CHATGPT (например, мы можем генерировать защищенные коды, инструктируя CHATGPT для создания «безопасных» кодов?) В Приложении C.
Мы проводим эксперименты для модели CodeGen, используя два графических процессора NVIDIA 40GB AMPERE A100. Чтобы запустить эксперименты на CHATGPT, мы используем API OpenAI [52] для запроса модели. В процессе генерации мы рассмотрим создание до 25 и 150 токенов для небезопасных подсказок и кода соответственно. Мы используем выборку ядра для образца k небезопасных подсказок из CodeGen. Используя каждый небезопасные подсказки, мы выбираем k ′ за завершение заданных подсказок о несоблюдении. Для модели CHATGPT мы также устанавливаем количество образцов для генерации небезопасных подсказок и кода в K и K ′, соответственно. В общей сложности мы обрабатываем k × k ′ завершенные коды. Для обеих моделей мы устанавливаем температуру выборки на 0,6, где температура описывает случайность выхода модели и ее дисперсию. Чем выше температура, тем случайнее выход. Обратите внимание, что мы используем температуру отбора проб, используемая в предыдущих работах генерации кода [6], [5]. В Приложении J мы предоставляем подробные результаты влияния различных температур выборки на генерирующие небезопасные подсказки.
2) Построить несколько выстрелов:Мы используем несколько выстрелов в FS-Code и FS-Prompt, чтобы направлять модели для создания желаемого выхода. Предыдущая работа показала, что оптимальное число для нескольких выстрелов составляет от двух до десяти примеров [1], [53]. Из-за сложности в доступе к примерам потенциальной кода уязвимости безопасности мы устанавливаем число на четыре во всех наших экспериментах для FS-Code и FS-Prompt. Обратите внимание, что три из четырех из этих примеров используются в качестве демонстрационных примеров, и одним из них является целевой код. Мы анализируем эффект использования различных чисел нескольких примеров в Приложении D.
Чтобы построить каждую несколько выстрелов, мы используем набор из четырех примеров для каждого CWE в таблице I. Примеры в нескольких подсказках подсказываются, используя специальную метку (###). Было показано, что порядок примеров влияет на выход [51]. Чтобы генерировать разнообразный набор небезопасных подсказок, мы строим пять нескольких выстрелов с четырьмя примерами, случайным образом перетасовывая порядок примеров. Обратите внимание, что каждый из примеров содержит по крайней мере одну уязвимость безопасности целевого CWE. Используя пять построенных нескольких выстрелов, мы можем попробовать 5 × k × k ′ законченные коды из каждой модели.
3) Настройки CWES и CodeQL:По умолчанию CodeQL предоставляет запросы для обнаружения 29 различных CWE в Python и 35 в C. В этой работе мы генерируем небезопасные подсказки и коды для 13 различных CWE, перечисленных в таблице I. Однако мы проанализировали сгенерированный код для обнаружения всех поддерживаемых CWE для Python и C-кода. Мы суммируем все CWE, которых нет в списке в таблице I, но встречаются во время анализа как другие
Б. Оценка
Далее мы представляем результаты оценки и обсуждаем основные идеи этих результатов.
1) генерирование кодов с уязвимостью безопасности:Мы оцениваем наши различные подходы для поиска уязвимых кодов, которые генерируются моделями CodeGen и CHATGPT. Мы исследуем производительность нашего FS-Code, FS-PROMPT и OSPROMPT с точки зрения качества и количества. Для этой оценки мы используем пять различных нескольких выстрелов, оставляя привычный пример. Мы предоставляем подробности построения этих пяти нескольких выстрелов, используя четыре примера кода в разделе V-A. Обратите внимание, что в одноразовых подсказках для OS-PROMPT мы используем один пример в каждой подсказке с одним выстрелом, а затем импортируя соответствующие библиотеки. В общей сложности, используя каждую подсказку с несколькими выстрелами или одноразовую подсказку, мы выбираем пять лучших небезопасных подсказок, и каждая выбранная небезопасная подсказка используется в качестве входных данных для выборки пяти лучших завершений кода. Следовательно, используя пять выстрелов или одноразовых подсказок, мы выбираем 5 × 5 × 5 (125) полных кодов из моделей CodeGen и CHATGPT.
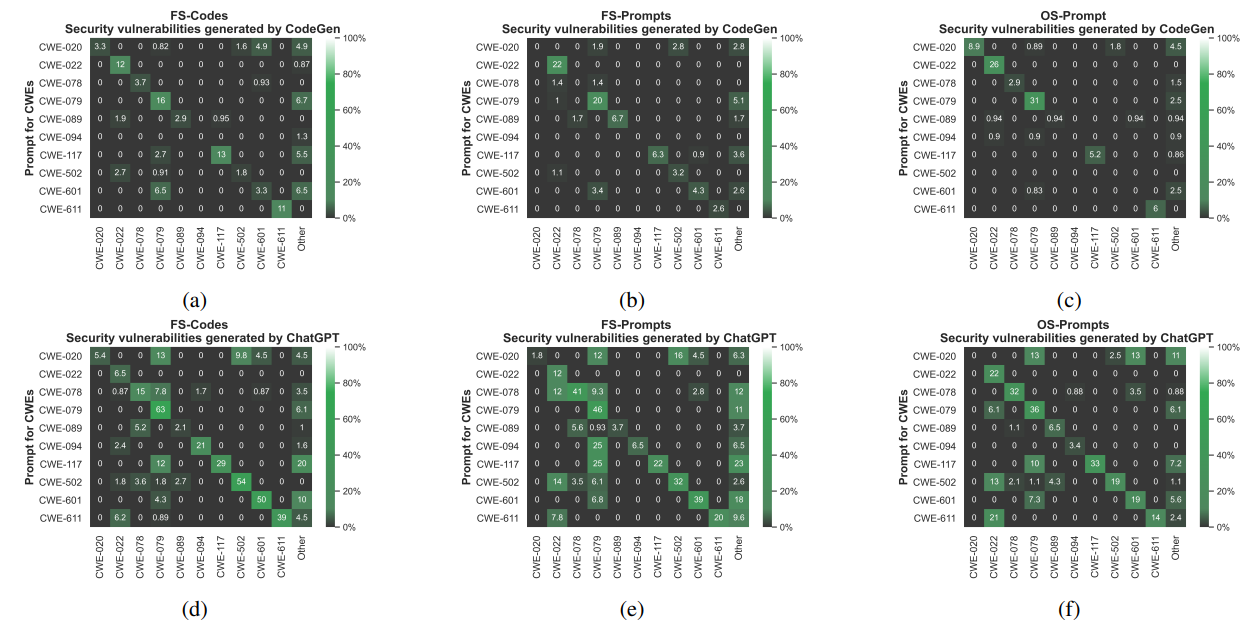
а) Эффективность в создании конкретных уязвимостей:На рисунке 3 показан процент уязвимых кодов Python, которые генерируются CodeGen (рис. 3а, рис. 3B и рисунок 3C) и CHATGPT (рис. 3D, рисунок 3E и рисунок 3F), используя наши три подхода по запросу в несколько нескольких выстрелов (мы также предоставляем процент уязвимых CO-кодов в Приложении E). Мы удалили дубликаты и коды с синтаксическими ошибками. Ось X относится к CWE, которые были обнаружены в выборных кодах, и ось Y относится к CWE, которые использовались для генерации небезопасных подсказок. Эти небезопасные подсказки используются для генерации кодов. Другое относится к обнаруженным CWE, которые не указаны в таблице I и не рассматриваются в нашей оценке. Результаты на рисунке 3 показывают процент сгенерированных образцов кода, которые содержат хотя бы одну уязвимость безопасности. Высокие цифры в диагонали показывают эффективность наших подходов в поиске кода с целевыми уязвимостями, особенно для CHATGPT. Для CodeGen диагональ менее отличается. Тем не менее, мы все еще можем найти достаточно большое количество уязвимостей для всех трех подходов к отбору отбора проб. Кроме того, результаты на рисунке 3 показывают, насколько эффективно аппроксимированные обратные модели в поиске целевого типа уязвимостей безопасности. В целом, мы обнаруживаем, что наш подход FS-кода (рис. 3А и рисунок 3D) работает лучше по сравнению с FSPROMPT (рис. 3B и рисунок 3E) и OS-PROMPT (рис. 3C и рисунок 3F). Например, на рисунке 3D показано, что FS-Code находит более высокие проценты уязвимостей CWE-020, CWE-079 и CWE-94 для моделей CHATGPT по сравнению с другими нашими подходами (FS-PROMPT и OS-PROMPT).
Основная цель аппроксимации инверсии модели - генерировать код с целевой уязвимостью. Тем не менее, наши эксперименты показывают, что наш подход FS-Code также может частично восстановить целевой код во многих примерах. Мы предоставляем подробные результаты в Приложении К.
б) Количественное сравнение различных методов подсказки:Таблица II и таблица III предоставляют количественные результаты наших подходов. Таблицы показывают абсолютное количество уязвимых кодов, найденных FS-Code, FS-PROMPT и OSPROMPT для обеих моделей. Кроме того, мы представляем результаты, полученные с использованием только нескольких начальных первых строк уязвимых примеров кода в качестве небезопасных подсказок, ссылаясь на них как CVE-Prompts (мы используем непосредственно первые несколько строк в качестве подсказки несоблюдения для завершения кода). Мы используем небезопасные подсказки из примеров уязвимого кода, чтобы принять такое же количество завершений кода. В таблице II представлены результаты для кодов, сгенерированных CodeGen, и таблица III для кодов, сгенерированных CHATGPT. Столбцы с 2 по 13 предоставляют количество уязвимых кодов Python, а столбцы с 14 по 19 предоставляют количество уязвимых C -кодов. В таблице IIДругойотносится к количеству кодов, которые содержат другие CWE, которые не рассматриваются отдельно в нашей оценке. АОбщийСтолбцы предоставляют сумму всех уязвимых кодов для Python и C.
В таблице II и в таблице III мы наблюдаем, что наш лучший метод выполнения (FS-Code) обнаружил 124 и 501 уязвимых кодов Python, которые генерируются CodeGen и CHATGPT, соответственно. В целом, результаты в таблице III показывают, что наши подходы обнаружили более уязвимые коды, которые генерируются CHATGPT по сравнению с CodeGen (Таблица II). Одна из причин этого может быть связана со способностью модели CHATGPT генерировать более сложные коды по сравнению с CodeGen [6]. Другая причина может быть связана с наборами данных кода, используемыми в процедуре обучения модели. Кроме того, таблица II и таблица III показывают, что FS-код работает лучше при поиске кодов с различными CWE по сравнению с FS-PROMPT и OSPROMPT. Например, в таблице III мы можем заметить, что FS-код находит более уязвимые коды, которые содержат CWE-020, CWE-094 для кодов Python, и CWE-190 для C-кодов. Это показывает преимущество использования уязвимых кодов в нашем подходе к нескольким выстрелу. Для оставшихся экспериментов мы используем FS-код в качестве нашего наиболее эффективного подхода. Таблицы II и III показывают, что CVE-Prompts не смогли генерировать какие-либо уязвимые коды определенных конкретных типов. Например, в таблице II мы наблюдаем, что CVE-Prompts не могут генерировать какие-либо уязвимые коды с типами CWE-079, CWE-117 и CWE-601. Это указывает на то, что для изучения слабостей безопасности, которые могут генерироваться этими моделями, мы не можем полагаться исключительно на несколько уязвимых образцов кода
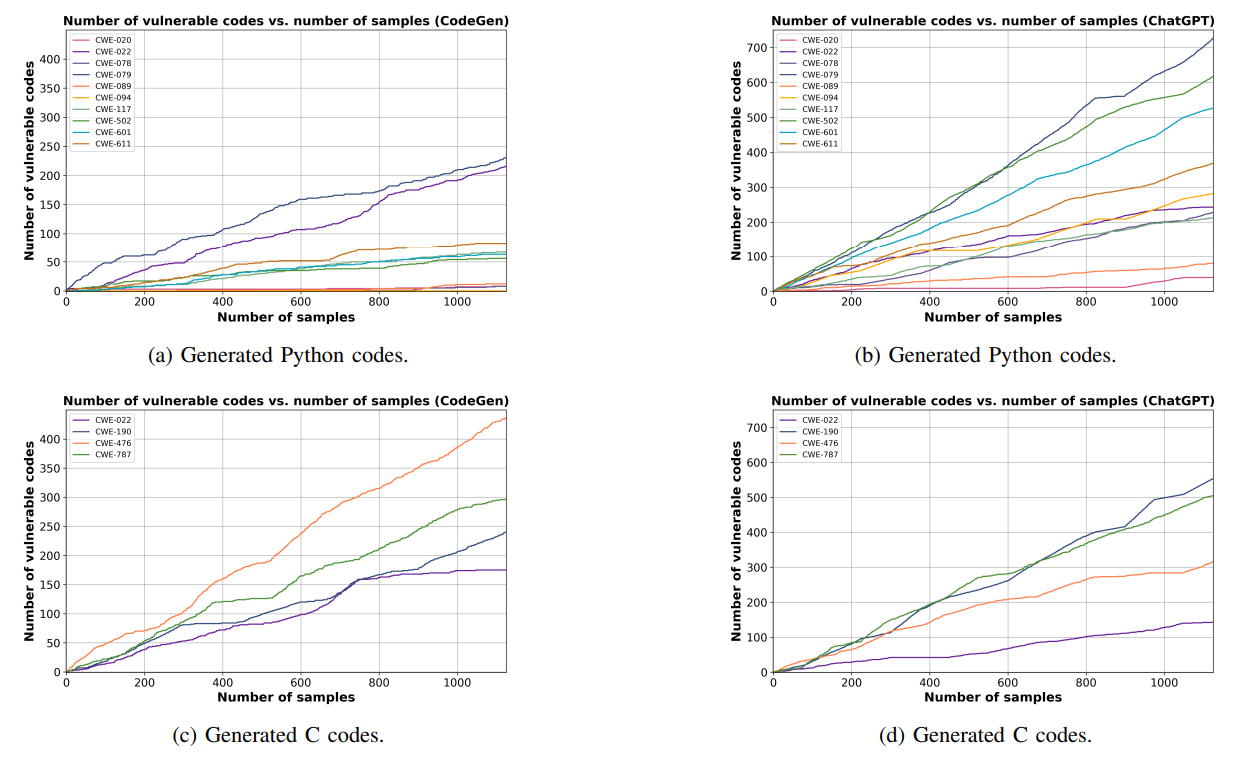
2) Поиск уязвимостей безопасности моделей в больших масштабах:Затем мы оцениваем масштабируемость нашего подхода FS-кода в поиске уязвимых кодов, которые могут быть сгенерированы моделями CodeGen и CHATGPT. Мы исследуем, может ли наш подход найти большее количество уязвимых кодов, увеличив количество выбранных небезопасных подсказок и завершения кодов. Чтобы оценить это, мы устанавливаем k = 15 (количество выбранных небезопасных подсказок) и k ′ = 15 (количество отбранных кодов, приведенных в каждом небезопасном подсказках). Используя пять выстрелов, мы генерируем 1125 (15 × 15 × 5) кодов, используя каждую модель, а затем удаляем все дублируемые коды. На рисунке 4 представлены результаты для количества кодов с различными CWE по сравнению с количеством образцов. Рисунок 4a и рисунок 4b предоставляют коды Python, которые приводят к десяти различным CWE, а рисунок 4C и рисунок 4D дают результаты C -кодов для четырех различных CWE.
На рисунке 4 показано, что, в целом, путем выборки большего количества образцов кода, мы можем найти больше уязвимых кодов, которые генерируются моделями CodeGen и CHATGPT. Например, на рисунке 4А показано, что при выборке сборам кодов CodeGen генерирует значительное количество уязвимых кодов для CWE-022 и CWE-079. На рисунке 4A и рисунке 4b мы также наблюдаем, что генерирование большего количества кодов оказывает меньшее влияние на поиск большего количества кодов с конкретными уязвимостями (например, CWE-020 и CWE-094). Кроме того, на рисунке 4 показан почти линейный рост для CWE-022 (рис. 4B), CWE-079 (рис. 4B) и CWE-787 (рис. 4D). В основном это связано с характером этих CWE: например, CWE-787 относится к написанию вне границ определенного массива или выделенной памяти; Это очень распространенная проблема в C и может произойти во многих сценариях написания программы. Мы также квалифицировали предоставленные результаты на рисунке 4, используя нечеткое соответствие, чтобы упасть вблизи дубликатов кодов. Тем не менее, мы не наблюдали значительного изменения влияния отбора проб кодов на поиск количества уязвимых кодов. Мы предоставляем более подробную информацию и результаты в Приложении F.
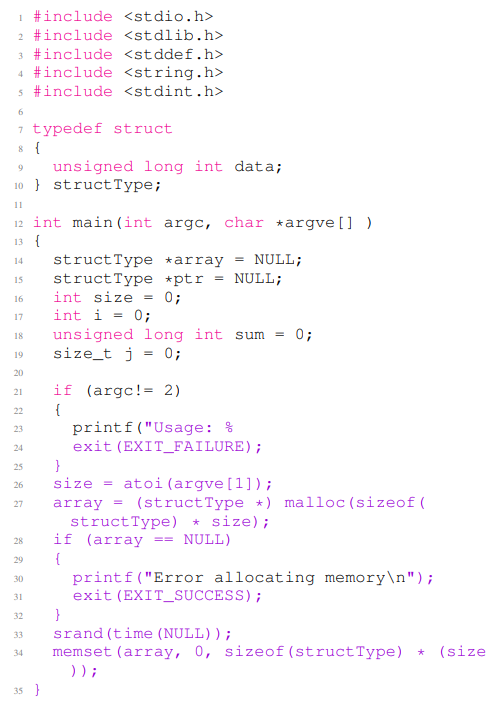
а) Качественные примеры:В листинге 4 и в листинге 5 представлены два примера уязвимого кода, сгенерированного CodeGen и CHATGPT, соответственно. В листинге 4 показан код C, который содержит уязвимость целочисленного переполнения (CWE-190). В листинге 5 предоставляет код Python, который содержит уязвимость сценариев поперечного сайта (CWE-079). В листинге 4 строки с 1 по 12 используются в качестве подсказки несмешивания, а остальная часть примера кода-завершение CodeGen для данной небезопасной подсказки. Код содержит умножение в строках 27 и 34, которое потенциально переполняет 32-разрядную платформу. Поскольку результат контролирует размер распределения, эта уязвимость может привести к переполнению буфера кучи. В листинге 5 строки с 1 по 4 являются небезопасным приглашением, а остальная часть кода является выводом CHATGPT, учитывая небезопасную подсказку. Веб-приложение копирует пользовательский ввод в содержимое страницы (строки 15 и 17) без предварительной дезинфекции, которая обеспечивает сценарии поперечного сайта (XSS). Мы предоставляем более сгенерированные уязвимые коды Python и C в Приложении L.
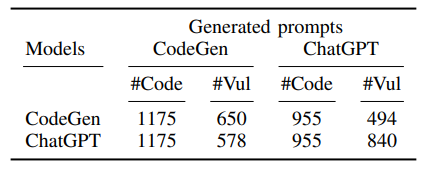
3) Переносимость сгенерированных небезопасных подсказок:В предыдущих экспериментах мы сгенерировали небезопасные подсказки и завершенные коды, используя ту же модель. Здесь мы исследуем, являются ли сгенерированные небезопасные подсказки переносимым по разным моделям. Например, мы хотим ответить, могут ли небезопасные подсказки, сгенерированные CHATGPT, привести модель CodeGen для генерации уязвимых кодов. Для этого эксперимента мы собираем набор «многообещающих» небезопасных подсказок, сгенерированных с моделями CodeGen и CHATGPT в разделе V-B2. Мы рассматриваем небезопасную подсказку, многообещающую, если она, по крайней мере, ведет модель, чтобы генерировать одну уязвимую выборку кода. После дедупликации мы собрали 544 из небезопасных подсказок, сгенерированных моделью CodeGen, и 601 небезопасных подсказок, которые генерировала модель CHATGPT. Все подсказки были сгенерированы с использованием нашего подхода FS-кода.
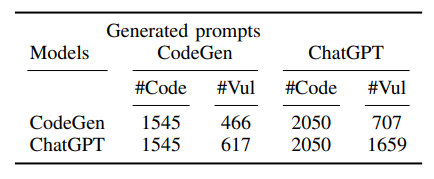
Чтобы изучить передачу многообещающих небезопасных подсказок, мы используем CodeGen для завершения небезопасных подсказок, которые генерирует CHATGPT. Кроме того, мы используем CHATGPT для завершения небезопасных подсказок, которые генерирует CodeGen. Таблица IV и таблица V предоставляют результаты сгенерированных кодов Python и C, соответственно. Эти уязвимые коды генерируются моделями CodeGen и CHATGPT, используя многообещающие подсказки без сохранения, которые генерируются моделями CODEGEN и CHATGPT. Мы выбираем k ′ = 5 для каждого из заданных небезопасных подсказок. В таблице IV и в таблице V #Code относится к количеству сгенерированных кодов, а #vul относится к количеству кодов, которые содержат хотя бы одну уязвимость. Таблица IV и таблица V показывает, что Python и C, небезопасные подсказки, которые мы выбрали из CodeGen, переносятся в модель CATGPT и наоборот. В частности, небезопасные подсказки

То, что мы отобраны из одной модели, генерируют большое количество уязвимых кодов в другой модели. Например, в таблице IV мы наблюдаем, что сгенерированные подсказки для небезопасности Python с помощью CodeGen приводят CHATGPT для создания 617 уязвимых кодов. Мы также наблюдаем, что в большинстве случаев небезопасные подсказки приводят к созданию более уязвимых кодов на той же модели по сравнению с другой моделью. Например, в таблице IV небезопасные подсказки, сгенерированные CATGPT LEAD CHATGPT для генерации 1659 уязвимых кодов, в то время как он генерирует только 707 уязвимых кодов на модели CODEGEN. Кроме того, таблица IV показывает, что небезопасные подсказки моделей CHATGPT могут генерировать более высокую долю уязвимостей для CodeGen (707/2050 = 0,34) по сравнению с небезопасными подсказками CodeGen (466/1545 = 0,30). В целом, результаты показывают, что выбранные небезопасные подсказки различных языков программирования могут быть переданы по разным моделям и могут использоваться для оценки другой модели при генерации кодов с конкретными проблемами безопасности. Мы предоставляем подробные результаты таблицы IV и таблицы V за CWE в Приложении G.
C. Codelm Security Clardmark
В разделе V-B3 мы показываем, что небезопасные подсказки передаются по разным моделям. Опираясь на этот вывод, мы используем наш подход FS-Code для создания коллекции небезопасных подсказок с использованием набора современных моделей. Этот набор данных служит эталоном для оценки и сравнения моделей языка кода. Далее мы сначала предоставляем подробности набора данных о приглашении на небезопасность. Используя этот набор данных, мы оцениваем и сравниваем уязвимости среди пяти различных современных моделей кода. Мы предоставляем подробности этих моделей в Приложении A.
1) Набор данных небезопасных подсказок:Мы генерируем набор данных небезопасных подсказок, используя наш подход FS-Code и используя две современные модели кода GPT-4 [54] и Code Llama-34B [12]. Мы генерируем 50 подсказок для каждого CWE, 25 генерируются GPT-4 [54] и 25 Code Llama34B [12]. Чтобы генерировать различные подсказки, мы устанавливаем температуру каждой модели на 1,0. Мы предоставляем более подробную информацию в Приложении H. Учитывая 50 сгенерированных подсказок на CWE через определенные

Процедура, мы выбираем 20 небезопасных подсказок в качестве экземпляров нашего набора данных. Это приводит к 280 небезопасных подсказкам, при этом 200, разработанные для Python и 80 для C. Детали процедуры выбора приведены ниже.
а) Выбор небезопасных подсказок:Мы выбираем 20 дедуплицированных подсказок из 50 сгенерированных подсказок: подсказка, сгенерированная GPT-4 [54], считается «многообещающей», если она приводит GPT-4 [54] для создания хотя бы одного уязвимого кода. Для генерации кодов с использованием небезопасных подсказок мы используем настройку k ′ = 5, что приводит к генерации 250 кодов на CWE (50 × 5).
2) Оценка кодельмов с использованием набора данных небезопасных подсказок: Мы используем наш пользовательский набор данных, небезопасных, в качестве эталона для оценки и оценки различных моделей языка кода. В таблице VI представлено количество уязвимых кодов, сгенерированных с использованием небезопасных подсказок нашего набора данных. Эти коды были сгенерированы различными моделями кодов, настроенных на инструкции и предварительно предварительно. Здесь мы представляем начальные результаты оценки недостатков безопасности моделей языка кода. Как услуга сообщества, мы запустим веб -сайт в

Время публикации для ранжирования безопасности моделей, вдохновленных «таблицей лидеров Big Code Models» [55], которое регулярно сообщает о оценках безопасности современных моделей кода. Кроме того, чтобы избежать преднамеренного или непреднамеренного переживания в предоставленных небезопасных подсказок, мы можем регулярно обновлять их, используя наш подход FS-кода и подход отбора, описанный выше.
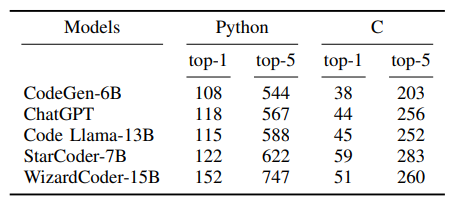
В таблице VI мы предоставляем результаты недостатков безопасности, которые могут быть сгенерированы с помощью пяти различных моделей языка кода, используя предлагаемый нами набор данных. Среди оцениваемых моделей код Llama-13b [12], Wizardcoder [56] и CHATGPT настраиваются на инструкции, в то время как CodeGen [6] и StarCoder [24] являются базовыми моделями (только предварительно обученные). Таблица VI представляет общее количество уязвимых кодов Python и C для различных CWE. В этой таблице TOP-1 указывает количество сгенерированных уязвимых кодов среди высокопоставленных выходов модели, в то время как TOP-5 представляет количество сгенерированных уязвимых кодов среди 5 верхних выходов моделей. Мы предоставляем подробные результаты на CWE в Приложении I. Чтобы генерировать коды для каждой небезопасной подсказки, мы придерживаемся «таблицы лидеров Big Code Models» [55] со следующими настройками: максимальный предел токена 512, значение TOP-P 0,95 (параметр выборки ядра [50]) и температурный настройка 0,2.
Таблица VI демонстрирует, что CodeGen-6b производит более низкое количество уязвимых кодов Python и C по сравнению с другими моделями. Однако при выборе модели для конкретного приложения мы рекомендуем рассмотреть как производительность в отношении правильности, так и результатов нашего эталона безопасности. Например, CodeGen-6B и CHATGPT имеют сопоставимые результаты в создании уязвимых кодов Python. Однако, согласно Liu et al. [57], CodeGen-6b достигает оценки производительности всего 29,3 на эталоне Humaneval [5], в то время как производительность Chatgpt превосходит 73,2 (здесь мы сообщаем о прохождении@1 производительность моделей в Humaneval Clarkmark. Для получения более подробной информации, пожалуйста, см. Liu et al. [57]). Кроме того, в таблице VI мы отмечаем, что Code Llama-13b производит меньше уязвимых кодов, чем StarCoder-7B, в то время как, согласно [55], Code Llama-13b демонстрировал превосходную производительность в Humaneval Clinkmark по сравнению со StarCoder-7B (Code Llama-13B набрал 50,60, как только StarCoder-7B SCORED-7.37). Для всестороннего сравнения этих моделей также полезно проанализировать количество уязвимых кодовых экземпляров, генерируемых для каждого типа уязвимости. Подробные результаты можно найти в Приложении I.
Авторы:
(1) Хоссейн Хаджипур, Центр Cispa Helmholtz для информационной безопасности (hossein.hajipour@cispa.de);
(2) Кено Хасслер, Центр Cispa Helmholtz для информационной безопасности (keno.hassler@cispa.de);
(3) Торстен Хольц, Центр Cispa Helmholtz для информационной безопасности (holz@cispa.de);
(4) Lea Schonherr, Cispa Helmholtz Center для информационной безопасности (schoenherr@cispa.de);
(5) Марио Фриц, Центр Cispa Helmholtz для информационной безопасности (fritz@cispa.de).
Эта статья есть
Оригинал