
Экспериментальная настройка и наборы данных для дальнейшего предварительного подготовки (CPT) и создания инструкций (IFT)
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
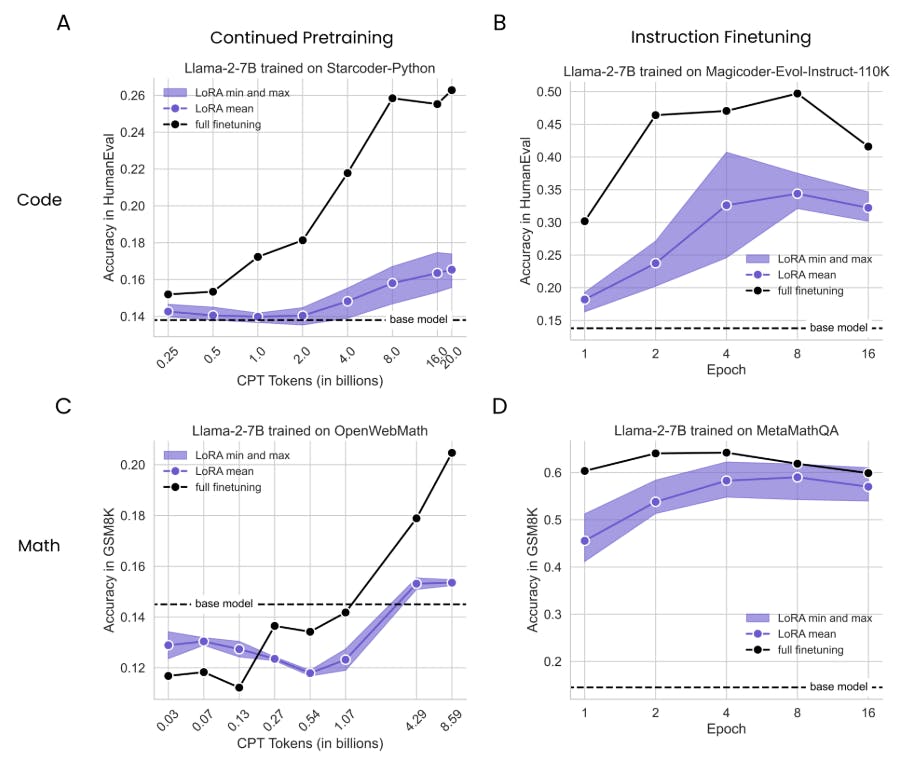
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
3 экспериментальная установка
Мы тренируемся на наборах данных кода и математике, которые, как было показано, повышают производительность по течению. Мы мотивируем учебные наборы и оценки оценки ниже.
3.1 Наборы данных для продолжения предварительного подготовки (CPT) и создания инструкций (IFT)
Кодирование CPT - StarCoder -PythonЭтот набор данных (Li et al., 2023) состоит из допустимо лицензированных репозиториев от GitHub, включая GIT Commits, на 80+ языках программирования. Мы выбрали подмножество Python и подтолкнули его к 20B токенам.
Math CPT - OpenWebMathМы тренировались на подмножестве до 8,59b из 14,7b токенов. Набор данных (Paster et al., 2023) включает в себя математические веб -страницы из общего ползания, правильно отформатированные для сохранения математического контента, такого как латексные уравнения. [2] Мы отмечаем, что этот набор данных содержит значительное количество полных английских предложений. [3]
Кодирование IFT-Magicoder-Evol-Instruct-110KЭтот набор данных (Wei et al., 2023) содержит 72,97M токенов вопросов и ответов программирования. Он воспроизводит набор данных «evol-instruct» WizardCoder (Luo et al., 2023): LLM (GPT-4) итеративно побуждает увеличить сложность набора пар вопросов-ответов (из кода alpaca; Chaudhary (2023)).
Математика IFT - MetamathqaЭтот набор данных (Yu et al., 2023) был построен путем начальной загрузки математических задач слов из обучающих наборов GSM8K (Cobbe et al., 2021) и Math (Hendrycks et al., 2021), переписывая вопросы с вариациями, используя GPT-3.5. Этот набор данных содержит 395 тыс. Пары вопросов-ответов и примерно 103-метровые токены. [4]
Мы количественно оцениваем обучение и забывание с помощью критериев, о которых сообщалось в открытом плане лидеров LLM [5] для состояний Art с открытым исходным кодом, таких как Llama (Touvron et al., 2023).
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
Кодирование - гуманевалЭтот эталон (Chen et al., 2021)) содержит 164 задачи, которые включают в себя создание программы Python, учитывая Docstring и функциональную подпись. Поколение считается правильным, если оно проходит все предоставленные модульные тесты. Мы используем жгут оценки LM Generation Code (Ben Allal et al., 2022), настроенный на вывод 50 поколений на проблему, выборки с температурой Softmax = 0,2 и расчет «Pass@1»
Математика - GSM8KЭтот эталон (Cobbe et al., 2021) включает в себя коллекцию 8,5 тыс. Слово-школы. Мы оцениваем тестовое разделение GSM8K (1319 образцов), как это реализовано в жгуте оценки LM (Gao et al., 2023), с параметрами генерации по умолчанию (температура = 0, пять нескольких выстрелов, проход@1).
3.3 Забыть метрики (оценка доменов источника)
HellaswagЭтот эталон (Zellers et al., 2019) включает в себя 70K -задачи, каждый из которых описывает событие с множественными возможными продолжениями. Задача состоит в том, чтобы выбрать наиболее правдоподобное продолжение, которое требует выводов о нюансированных повседневных ситуациях.
WinograndeЭтот эталон (Sakaguchi et al., 2019) также оценивает обоснование. Он включает в себя 44K -задачи с предложениями, которые требуют неоднозначного разрешения местоимения.
Арк-хлебЭтот эталон (Clark et al., 2018) состоит из 7787 уровня школы, научных вопросов с множественным выбором, возможностей тестирования в сложных рассуждениях и понимании научных концепций.
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
[2] https://huggingface.co/datasets/open-web-math/open-web-math
[3] Из случайного выбора примеров 100 тыс. Примеров поиск режима показывает, что 75% примеров содержат латекс. Данные классифицируются как 99,7% английского языка и «в подавляющем большинстве английских» по инструментам Langdetect и Fasttext.
[4] https://huggingface.co/datasets/meta-math/metamathqa
[5] https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
Оригинал