

Оценка T5, Roberta и Clip в задачах выравнивания облака текста-точка
17 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
5.3 Анализ встраивания текста
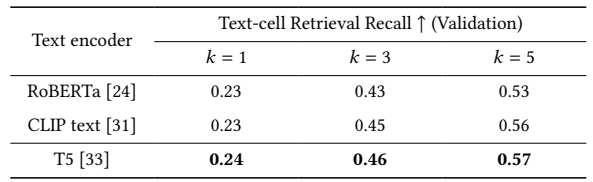
В последние годы появилось появление крупных языковых моделей (энкодеров), таких как Берт [14], Роберта [24], T5 [33] и текстовый кодер Clip [31], каждый обучен с различными задачами и наборами данных. Text2loc подчеркивает, что предварительно обученная модель T5 значительно улучшает выравнивание функций Text и Point Cloud. Тем не менее, потенциал других моделей, таких как Роберта и текст -энкодер, известный своим превосходством в задачах визуальной заземления, не изучается в их исследовании. Таким образом, мы проводим сравнительный анализ T5-Small, Roberta-Base и энкодера текста клипа в нашей модели. Результат в таблице 6 указывает на то, что T5-SMALL (61M) достигает 0,24/0,46/0,57 в показателях воспоминания TOP-1/3/5, постепенно превосходящих Robertabase (125M) и текст клипа (123 м) с меньшим количеством параметров.
6 Заключение
В этой статье мы предлагаем модель IFRP-T2P для локализации облака трехмерных точек на основе нескольких описаний естественного языка, который является первым подходом, чтобы непосредственно использовать необработанные облака точек в качестве входных данных, что устраняет необходимость в экземплярах истине земли. Кроме того, мы
Предложите Rowcolrpa на грубой стадии и RPCA на прекрасной стадии, чтобы полностью использовать информацию о пространственных отношениях. Благодаря обширным экспериментам IFRP-T2P достигает сопоставимой производительности с современной моделью Text2loc, которая опирается на экземпляры Groundtruth. Более того, он превосходит Text2LOC, используя модель сегментации экземпляров в качестве предварительного. Наш подход расширяет удобство использования существующих моделей локализации текста-точка облака, позволяя их применению в сценариях, где доступно мало информации о экземпляре. Наша будущая работа будет сосредоточена на применении IFRP-T2P для навигации в реальных роботизированных приложениях, преодолении разрыва между теоретическими моделями и практической полезности в автономной навигации и взаимодействии.
Ссылки
[1] Panos Achlioptas, Ахмед Абделярем, Фей Ся, Мохамед Элхосейни и Леонидас Гибас. 2020. Ссылка3D: Нейронные слушатели для мелкозернистой идентификации 3D объекта в сценах реального мира. 16 -я Европейская конференция по компьютерному видению (ECCV) (2020).
[2] Рельжа Аранджелович, Петр Гронат, Акихико Тори, Томас Пайдла и Йозеф Сивич. 2018. Netvlad: архитектура CNN для слабо контролируемого признания места. IEEE транзакции по анализу шаблонов и машинного интеллекта (Jun 2018), 1437–1451. https://doi.org/10.1109/tpami.2017.2711011
[3] Дайганг Кай, Лишай Чжао, Цзин Чжан, Лу Шенг и Донг Сюй. 2022. 3DJCG: унифицированная структура для совместного плотного подписания и визуального заземления на облаках 3D -точки. 2022 Конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR) (2022), 16443–16452. https://api.semanticscholar.org/corpusid: 250980730
[4] Николас Карион, Франциско Масса, Габриэль Синнев, Николас Усунье, Александр Кириллов и Сергей Загоруйко. 2020. Конечное обнаружение объекта с трансформаторами.
[5] Дейв Чжени Чен, Ангел X Чанг и Матиас Нисснер. 2020. В компьютерном видении - ECCV 2020: 16 -я Европейская конференция, Глазго, Великобритания, 23–28 августа 2020 года, Труды, часть XX 16. Springer, 202–221.
[6] Сиджин Чен, Хонгьюан Чжу, Синь Чен, Иньцжи Лей, Тао Чен и Юга. 2023. Среднекнутые 3D плотные подписи с голосованием2CAP-DETR. 2023 IEEE/CVF Конференция по компьютерному зрению и распознаванию шаблонов (CVPR) (2023), 11124–11133. https://api.semanticscholar.org/corpusid:255522451
[7] Чжений Чен, Али Голами, Матиас Нисснер и Ангел Х Чанг. 2021. SCAN2CAP: Плотная подвеска с контекстом в сканировании RGB-D. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию шаблонов. 3193–3203.
[8] Боуэн Ченг, Ишан Мисра, Александр Г. Швинг, Александр Кириллов и Рохит Гирдхар. 2022. Трансформатор маски для маскировки для универсальной сегментации изображений.
[9] Боуэн Ченг, Алекс Швинг и Александр Кириллов. 2021. Классификация для каждого пикселя-это не все, что вам нужно для семантической сегментации.
[10] Кристофер Чой, Юньонг Гвак и Сильвио Саварсе. 2019. 4D -пространственно -временные конвретики: сверточные нейронные сети Минковского. В материалах конференции IEEE по компьютерному видению и распознаванию образцов. 3075–3084.
[11] Анжела Дай, Ангел X Чанг, Манолис Савва, Маки Хальбер, Томас Фанкхаузер и Матиас Нисснер. 2017. Сканат: богато аннотированные 3D-реконструкции внутренних сцен. В материалах конференции IEEE по компьютерному видению и распознаванию образцов. 5828–5839.
[12] Хауэн Денг, Толга Бердал и Слободан Илич. 2018. PPFNET: глобальные контекстные знания локальные функции для надежного сопоставления 3D -точек. Конференция IEEE/CVF 2018 года по компьютерному зрению и распознаванию образцов (2018), 195–205. https: //api.semanticscholar.org/corpusid:3703761
[13] Ruoxi Deng, Chunhua Shen, Shengjun Liu, Huibing Wang и Xinru Liu. 2018. Обучение прогнозированию четких границ.
[14] Джейкоб Девлин, Мин-Вей Чанг, Кентон Ли и Кристина Тутанова. 2019. Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка. В североамериканской главе Ассоциации вычислительной лингвистики. https: //api.semanticscholar.org/corpusid:52967399
[15] Фан Чжаоксин, Чжэнбо Сонг, Хонгян Лю, Чживу Лу, Джун Хе и Сяоонг Дю. 2022. SVT-NET: Super Light-Wee-Sparse Voxel Transformer для крупномасштабного распознавания места. Труды конференции АААИ по искусственному интеллекту (июль 2022 г.), 551–560. https://doi.org/10.1609/aaai.v36i1.19934
[16] Стивен Хауслер, Сурав Гарг, Мин Сюй, Майкл Милфорд и Тобиас Фишер. 2021. Patch-Netvlad: многомасштабное слияние местных глобальных дескрипторов для распознавания места. В 2021 году конференция IEEE/CVF по компьютерному видению и распознаванию шаблонов (CVPR). https://doi.org/10.1109/cvpr46437.2021.01392
[17] Иин Хонг, Хаою Чжэнь, Пейхао Чен, Шухонг Чжэн, Йилун Дю, Чжэнфанг Чен и Чуан Ган. 2023. 3d-llm: инъекция 3D мира в крупные языковые модели. Достижения в системах обработки нейронной информации 36 (2023), 20482–20494.
[18] Bu Jin, Yupeng Zheng, Pengfei Li, Weize Li, Yuhang Zheng, Sujie Hu, Xinyu Liu, Jinwei Zhu, Zhijie Yan, Haiyang Sun, et al. 2024. TOD3CAP: к 3D плотным подписи в открытых сценах. Arxiv Preprint arxiv: 2403.19589 (2024).
[19] Рагхав Капур, Яш Параг Батала, Мелиса Руссак, Цзин Ю Ко, Киран Камбл, Васим Альших и Руслан Салахутдинов. 2024. Omniact: набор данных и эталон для включения мультимодальных универсальных автономных агентов для рабочего стола и веб -сайта. ARXIV ABS/2402.17553 (2024). https://api.semanticscholar.org/corpusid: 268031860
[20] Джинкю Ким, Анна Рорбах, Тревор Даррелл, Джон Ф. Ханни и Зейнеп Аката. 2018. Текстовые объяснения для автомобилей с самостоятельным вождением. На европейской конференции по компьютерному видению. https://api.semanticscholar.org/corpusid:51887402
[21] Мануэль Колмет, Кунджи Чжоу, Альджоса Осеп и Лора Лил-Тайкс. 2022. Text2pos: межмодальная локализация текста-точка-облака. 2022 Конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR) (2022), 6677–6686. https: // api. Semanticscholar.org/corpusid:247779335
[22] Jacek Komorowski. 2020. Minkloc3d: Облаковое облачное распознавание мест на основе точек. 2021 IEEE Зимняя конференция по приложениям Computer Vision (WACV) (2020), 1789–1798. https://api.semanticscholar.org/corpusid:226282298
[23] Гарольд В. Кун. 1955. Венгерский метод проблемы задания. Naval Research Logistics Quarterly 2, 1-2 (1955), 83–97.
[24] Иньхан Лю, Майл Отт, Наман Гоял, Цзингфей Дю, Мандар Джоши, Данки Чен, Омер Леви, Майк Льюис, Люк Зеттлемуер и Веселин Стоянов. 2019. Роберта: надежно оптимизированный подход Bert. ARXIV ABS/1907.11692 (2019). https://api.semanticscholar.org/corpusid:198953378
[25] Джуни М.А., Гуан Мин Сионг, Цзини Сюй и Сьейюанли Чен. 2023. CVTNET: сеть трансформаторов поперечного просмотра для распознавания мест на основе лидара в условиях автономного вождения. IEEE Transactions по промышленной информатике 20 (2023), 4039–4048. https://api.semanticscholar.org/corpusid:256598042
[26] Шрикант Малла, Чихо Чой, Ишт Двиведи, Джунхьян Чой и Цзяхен Ли. 2022. Драма: совместная локализация риска и подписи в вождении. 2023 IEEE/CVF Зимняя конференция по приложениям Computer Vision (WACV) (2022), 1043–1052. https://api.semanticscholar.org/corpusid:252439240
[27] Ишан Мисра, Рохит Гирдхар и Арманд Джулин. 2021. Модель сквозного трансформатора для обнаружения 3D объекта.
[28] Мин Ни, Ренеуан Пенг, Чунвей Ван, Синьей Кей, Цзяньхуа Хан, Ханг Сюй и Ли Чжан. 2023. Причина2Drive: к интерпретируемому и цепному рассуждениям для автономного вождения. Arxiv ABS/2312.03661 (2023). https: // api. Semanticscholar.org/corpusid:265688025
[29] Чарльз Р. Ци, Ли Йи, Хао Су и Леонидас Дж. Гибас. 2017. PointNet ++: глубокое иерархическое обучение функции на наборах точек в метрическом пространстве. В материалах 31 -й Международной конференции по системам обработки нейронной информации (Лонг -Бич, Калифорния, США) (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 5105–5114.
[30] Алек Рэдфорд, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Го, Сандхини Агарвал, Гириш Састри, Аманда Аскалл, Памела Мишкин, Джек Кларк и др. 2021. В Международной конференции по машинному обучению. PMLR, 8748–8763.
[31] Алек Рэдфорд, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Го, Сандхини Агарвал, Гириш Састри, Аманда Аскалл, Памела Мишкин, Джек Кларк, Гретхен Крюгер и Илья Сатскевер. 2021. В Международной конференции по машинному обучению. https://api.semanticscholar.org/corpusid:231591445
[32] Колин Раффель, Ноам Шейзер, Адам Робертс, Кэтрин Ли, Шаран Наранг, Майкл Матена, Янки Чжоу, Вэй Ли и Питер Дж. Лю. 2020. Изучение пределов обучения передачи с помощью унифицированного трансформатора текста в текст. J. Mach. Учиться. Резерв 21, 1, статья 140 (январь 2020 г.), 67 страниц.
[33] Колин Раффель, Ноам Шейзер, Адам Робертс, Кэтрин Ли, Шаран Наранг, Майкл Матена, Янки Чжоу, Вэй Ли и Питер Дж. Лю. 2020. Изучение пределов обучения передачи с помощью унифицированного трансформатора текста в текст. Журнал исследований машинного обучения 21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20-074.html
[34] Пол-Эдоуард Сарлин, Сезар Кадена, Роланд Зигвар и Марцин Димчик. 2019. От грубого до штрафного: надежная иерархическая локализация в масштабе. В 2019 году IEEE/CVF Конференция по компьютерному зрению и распознаванию шаблонов (CVPR). https://doi.org/10.1109/cvpr.2019.01300
[35] Джонас Шульт, Фрэнсис Энгельманн, Александр Херманс или Литания, Сию Тан и Бастиан Лейбе. 2023. Mask3d: Трансформатор маски для сегментации 3D семантического экземпляра. (2023).
[36] Микаэла Анджелина Уи и Гим Хи Ли. 2018. Pointnetvlad: поиск глубоких точек на основе облака для крупномасштабного распознавания места. Конференция IEEE/CVF 2018 года по компьютерному зрению и распознаванию шаблонов (2018), 4470–4479. https: //api.semanticscholar.org/corpusid:4805033
[37] Лоренс ван дер Маатен и Джеффри Хинтон. 2008. Визуализация данных с использованием t-sne. JMLR (2008).
[38] Ашиш Васвани, Ноам Шейзер, Ники Пармар, Якоб Ускорет, Ллион Джонс, Эйдан Н. Гомес, Лукаш Кайзер и Илья Полосухин. 2017. Внимание - это все, что вам нужно. В материалах 31 -й Международной конференции по системам обработки нейронной информации (Лонг -Бич, Калифорния, США) (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010.
[39] Гуанчжи Ван, хе -фанат и Мохан Канканхалли. 2023. Текст на точечный облако локализация с помощью трансформатора с усилением отношения. В материалах Тридцатизденной конференции AAAI по искусственному интеллекту и Тридцать пятой конференции по инновационному применению искусственного интеллекта и тринадцатого симпозиума по образовательным достижениям в области искусственного интеллекта (AAAI’23/IAAI'23/EAAI’23). AAAI Press, статья 278, 9 страниц. https://doi.org/10.1609/aaai.v37i2.25347
[40] Янмин Ву, Синьхуа Ченг, Ренруи Чжан, Зесен Ченг и Цзянь Чжан. 2023. EDA: явное управление текстами и плотное выравнивание для трехмерного визуального заземления. В материалах конференции IEEE по компьютерному видению и распознаванию шаблонов (CVPR).
[41] Ян Ся, Мария Глэдкова, Руи Ванг, Цяньюн Ли, Уве Стилла, Жоао Ф. Энрикес и Даниэль Кремерс. 2023. CASSPR: Ознакомление с одним сканированием. В материалах Международной конференции IEEE/CVF по компьютерному видению (ICCV). IEEE.
[42] Ян Ся, Льюан Ши, Зифенг Дин, Жуао Ф. Энрикес и Даниэль Кремерс. 2024. Text2loc: 3D -точечная локализация облака от естественного языка. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию шаблонов.
[43] Ян Ся, Юшенг Сюй, Шуан Ли, Руи Ван, Хуан Дю, Даниэль Кремерс и Уве СИЛЛА. 2020. SOE-Net: Сеть кодирования самостоятельного присмотра и ориентации для распознавания мест на основе точек. 2021 Конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR) (2020), 11343–11352. https: //api.semanticscholar.org/corpusid:227162609
[44] Сюй Ян, Чжихао Юань, Юхао Дю, Йинхон Ляо, Яо Го, Шугуан Куй и Чжэнь Ли. 2023. Комплексный визуальный вопрос, отвечающий на точечные облака с помощью манипуляции с композиционной сценой. Транзакции IEEE по визуализации и компьютерной графике (2023).
[45] Чжэнгуан Ян, Соньян Чжан, Ливей Ван и Цзебо Луо. 2021. SAT: 2D Semantics Advice Adsing Training для 3D -визуального заземления. Международная конференция по компьютерному видению, Международная конференция по компьютерному видению (май 2021 г.).
[46] Хуань Инь, Сюэхенг Сюй, Ша Лу, Сьююанли Чен, Ронг Сюн, Шаоджи Шен, Сирилл Стачнисс и Юэ Ван. 2023. Опрос о глобальной локализации лидара: проблемы, достижения и открытые проблемы. Международный журнал компьютерного видения (02 2023).
[47] Чжихао Юань, Джинке Рен, Чун-Мей Фенг, Хэншуан Чжао, Шугуан Куй и Чжэнь Ли. 2023. Визуальное программирование для нулевого выстрела с открытым вокабулярием 3D визуальное заземление. Arxiv Preprint arxiv: 2311.15383 (2023).
[48] Чжихао Юань, Сюй Ян, Чжуо Ли, Сюхао Ли, Яо Го, Шугуан Куй и Чжэнь Ли. 2022. На пути к объяснению и мелкозернистого трехмерного заземления посредством ссылки на текстовые фразы. Arxiv Preprint arxiv: 2207.01821 (2022).
[49] Чжихао Юань, Сюй Ян, Йинхонг Ляо, Яо Го, Гуанбин Ли, Чжэнь Ли и Шугуан Куй. 2022. x -trans2cap: перекрестная передача знаний с использованием трансформатора для 3D плотных подписи. 2022 Конференция IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR) (2022), 8553–8563. https: //api.semanticscholar.org/corpusid:247218430
[50] Чжихао Юань, Сюй Ян, Йинхонг Ляо, Руимао Чжан, Чжэнь Ли и Шугуан Куй. 2021. Instancerefer: Кооперативное целостное понимание для визуального заземления на точечных облаках через экземпляр многоуровневого контекстного ссылки. В материалах Международной конференции IEEE/CVF по компьютерному видению. 1791–1800.
[51] Ренруи Чжан, Цзимин Хан, Аоджун Чжоу, Сянгфей Ху, Шилин Ян, Пан Лу, Хоншенг Ли, Пенг Гао и Ю Цзяо Цяо. 2023. Лама-адаптер: эффективное создание языковых моделей с нулевым вниманием. Arxiv ABS/2303.16199 (2023). https://api.semanticscholar.org/corpusid:257771811
[52] Кунджи Чжоу, Торстен Саттлер, Марк Поллефейс и Лора Лил-Тайкс. 2020. Учить или не учиться: визуальная локализация от основных матриц. В 2020 году Международная конференция IEEE по робототехнике и автоматизации (ICRA). https://doi.org/10. 1109/ICRA40945.2020.9196607
[53] Чжичен Чжоу, Ченг Чжао, Даниэль Адольфссон, Сонгжи Су, Ян Гао, Том Дакетт и Ли Сан. 2021. NDT-Transformer: крупномасштабная локализация 3D-точек с использованием нормального представления преобразования распределения. В 2021 году Международная конференция IEEE по робототехнике и автоматизации (ICRA). https: //doi.org/10.1109/icra48506.2021.9560932
Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал