

Оценка мультимодальных речевых моделей в разных аудиозазадах
18 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
3 эксперименты
3.1 Задачи
В этой работе мы используем большую коллекцию общедоступных наборов данных речевых данных из разнообразного набора задач. Краткое изложение наборов данных и показателей оценки для этих задач представлено в таблице 1, в то время как примеры и подсказки рассматриваются в таблице 10. Наши задачи обучения включают автоматическое распознавание речи (ASR), пять задач понимания разговорного языка (SLU) и пять задач о обработке речи (PSP). Задачи SLU включают те задачи, которые могут быть решены с помощью каскадной системы модели ASR и LLM, в то время как задачи PSP являются классификационными задачами, основанными на аудио, обычно используемых в аудио -аналитике. Для задач IC/SL мы разделили набор данных SLURP на замеченные и невидимые классы метки намерения/слота и изучаем их отдельно, чтобы понять возможности обобщения модели. Задача KWE заключается в поиске важных ключевых слов из аудио, в то время как в задаче KWS мы учимся классифицировать, присутствовало ли конкретное ключевое слово в аудио или нет. Целевые этикетки были синтетически созданы для обеих этих задач с использованием LLM. Все остальные задачи являются стандартными, и заинтересованный читатель может обратиться к приложению A.3 для получения более подробной информации. Мы создаем список не менее 15 подсказок за задачу, описывающую цель задачи. Чтобы дополнительно добавить разнообразие в набор задач, мы используем версию набора данных Alpaca (31]. Этот набор данных содержит разнообразную коллекцию подсказки, входных, выходных кортежей, где подсказка описывает задачу, вход является входом для задачи, а выход содержит целевые этикетки. Тем не менее, нет соответствующих звуков, связанных с набором данных. Как и в существующей работе [17], мы используем систему TTS (AWS Polly в нашем случае) для создания синтетических аудиозаписи для входного текста с использованием пула из 10 различных динамиков.
3.2 модели

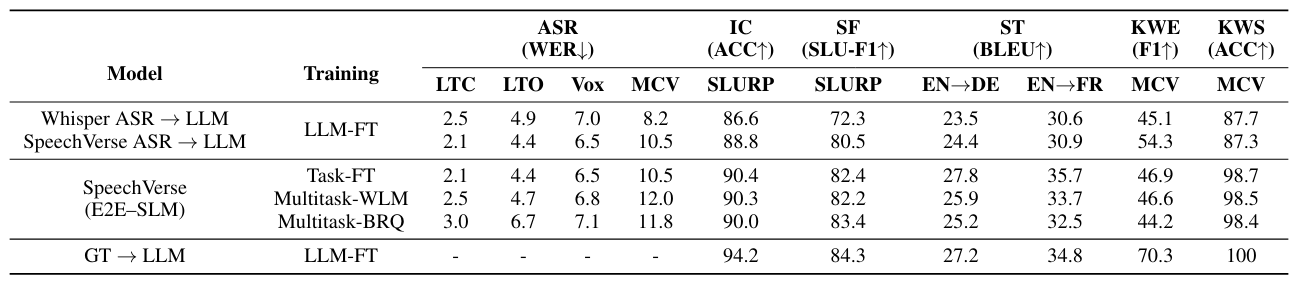
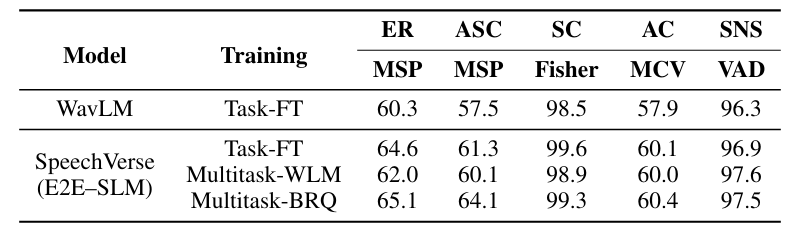
Базовые линии: Для задач SLU мы сравниваем наши модели с каскадной базовой линией, которая использует LLM на гипотезах ASR (ASR → LLM). Для справедливого сравнения мы используем эффективную параметров, точную версию Flan-T5-XL в качестве LLM для базовой линии. Многозадачные данные тонкой настройки точно одинаковы между нашими моделями и базовой линией, за исключением того, что последний использует наземную истинную текст вместо аудио. Мы сравниваем каскадный подход с гипотезами ASR из (1) сильной общедоступной модели Whisper-Large-V2 [20] ASR и (2) нашей модели ASR Task-F-FT, обеспечивающего истинное сравнение между мультимодальной моделью с каскадным подходом. Наконец, мы также сравниваем производительность системы Oracle ASR, передавая основные транскрипции истины в базовый LLM (GT → LLM). Для задачи KWS мы используем поиск подстроения ключевого слова в гипотезах ASR в качестве базовой линии. Для задач PSP мы обучаем классификаторов, конкретных, которые используют последние представления слоя от Wavlm, крупные. Классификатор содержит слой подачи, за которым следует 2-слойный закрытый рецидивирующий блок (GRU) со средним пулом над кадрами, за которым следует еще 2 уровня питательной сети и, наконец, оператор SoftMax. Эти модели обучаются тем же данным, специфичным для задачи, что позволяет прямо сравнить с нашими мультимодальными моделями на основе WAVLM.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал