
Оценка моделей GPT и открытого исходного кода по задачам мутации кода
4 июня 2025 г.Авторы:
(1) Бо Ван, Университет Пекин Цзиотонг, Пекин, Китай (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Пекинский университет Цзиотонга, Пекин, Китай (23120337@bjtu.edu.cn);
(3) Youfang Lin, Пекинский университет Цзиотонг, Пекин, Китай (yflin@bjtu.edu.cn);
(4) Майк Пападакис, Университет Люксембурга, Люксембург (michail.papadakis@uni.lu);
(5) Цзе М. Чжан, Королевский колледж Лондон, Лондон, Великобритания (jie.zhang@kcl.ac.uk).
Таблица ссылок
Аннотация и1 Введение
2 предыстория и связанная с ним работа
3 Учебный дизайн
3.1 Обзор и исследования исследований
3.2 Наборы данных
3.3 генерация мутаций через LLMS
3.4 Метрики оценки
3.5 Настройки эксперимента
4 Результаты оценки
4.1 RQ1: производительность по стоимости и юзабилити
4.2 RQ2: сходство поведения
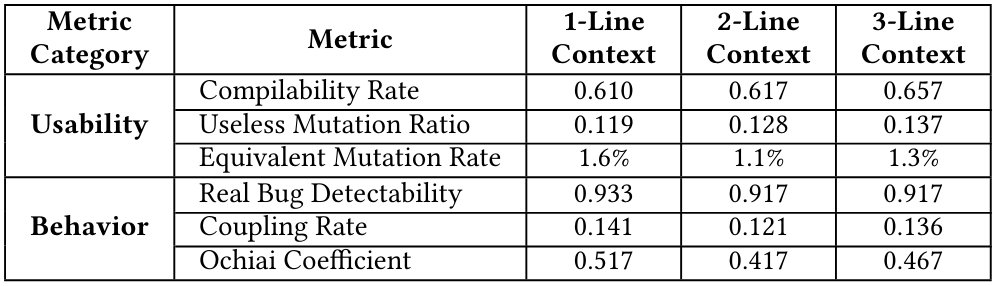
4.3 RQ3: воздействие различных подсказок
4.4 RQ4: воздействие различных LLMS
4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.2 Последствия
5.3 Угрозы достоверности
6 Заключение и ссылки
4.4 RQ4: воздействие различных LLMS
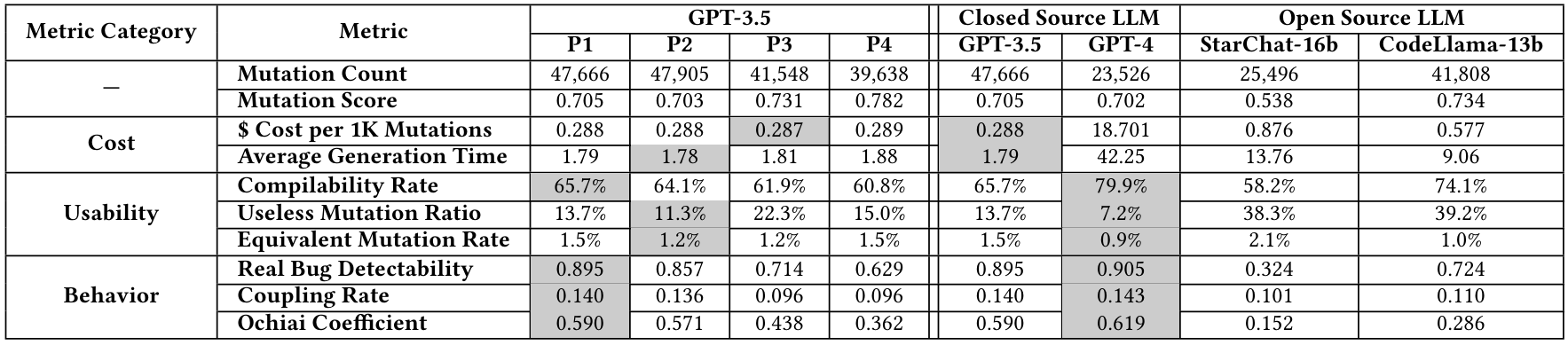
Чтобы ответить на этот RQ, мы добавляем два дополнительных LLMS, GPT-4 и Starchat16b и сравниваем их результаты с двумя LLMS по умолчанию, GPT-3.5 и Code Llama-13b. Правая половина таблицы 7 показывает сравнительные результаты между моделями, используя подсказку по умолчанию. Мы наблюдаем, что LLM с закрытым исходным кодом обычно превосходят других в большинстве метрик. GPT-3,5 превосходны в количестве мутаций, стоимости генерации на 1K-мутации и среднем времени генерации, идеально подходит для быстрого генерирования многочисленных мутаций. GPT-4 ведет во всех показателях юзабилити и метрики сходства поведения, демонстрируя ее эффективность в связанных с кодах задач, хотя его усовершенствования по сравнению с GPT-3.5 в показателях поведения тривиальны. Между двумя LLMS с открытым исходным кодом, несмотря на то, что Starchat-16b имеет больше параметров, Codellama-13b превосходит во всех метрик. Это говорит о том, что модельная архитектура и качество данных обучения значительно влияют на производительность за пределы только количества параметров.

4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
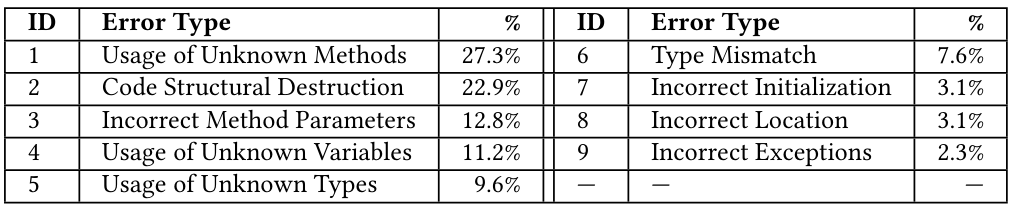
Некомпиляционные мутации требуют шага компиляции для фильтрации, что приводит к потерянным вычислительным ресурсам. Как упомянуто в разделе 4.1, LLMS генерирует значительное количество некомпиляционных мутаций. Этот RQ анализирует типы ошибок и потенциальные коренные причины этих некомпиляционных мутаций. После настройки предыдущих этапов мы сначала выбираем 384 некомпиляционные мутации из выходов GPT-3,5, обеспечивая 95% уровень достоверности, а погрешность-5%. Из ручного анализа этих некомпилируемых мутаций мы определили 9 различных типов ошибок, как показано в таблице 8.
Показано в таблице 8, наиболее распространенный тип ошибки, использование неизвестных методов, составляет 27,34% от общих ошибок, что выявляет проблему галлюцинации генеративных моделей [30]. Структурное разрушение кода является второй наиболее распространенной ошибкой, составляющая 22,92%, что указывает на то, что обеспечение синтаксически правильных кодов остается проблемой для текущих LLMS. Этот результат предполагает, что все еще существует значительное место для улучшения в текущих LLMS.

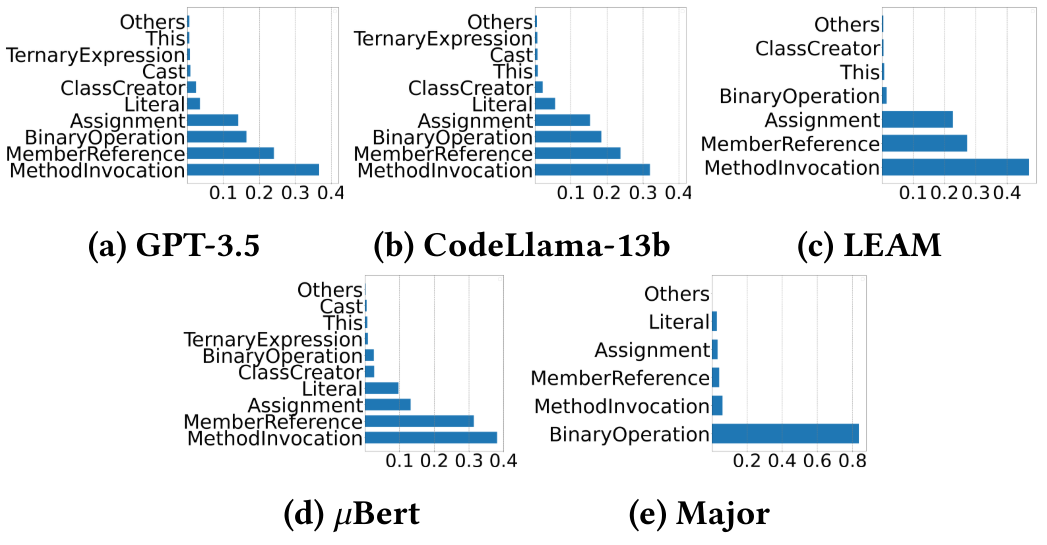
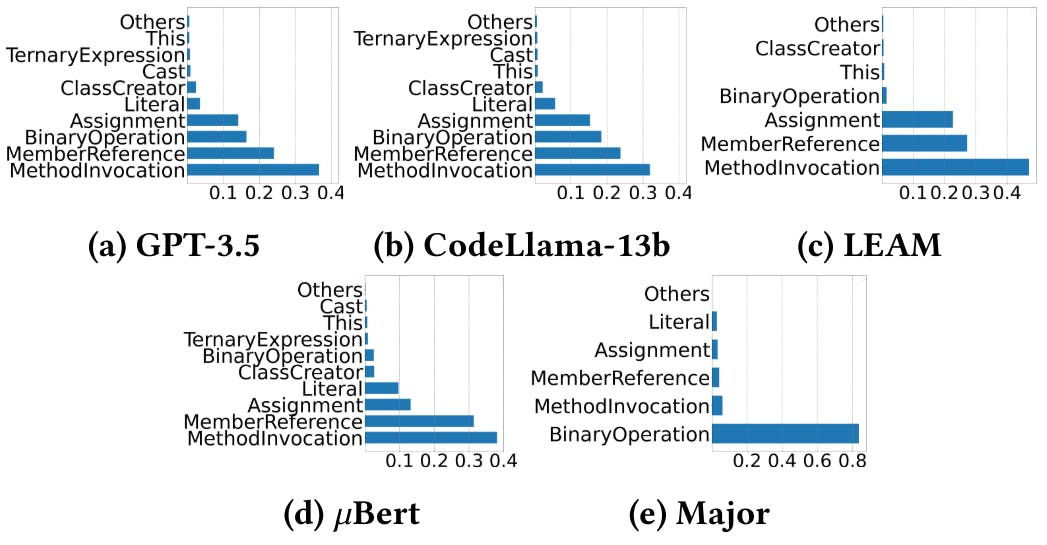
Чтобы проанализировать, какие типы кода склонны к тому, что LLMS генерируют некомпилируемые мутации, мы исследовали местоположения кода всех некомпилируемых мутаций, сгенерированных GPT-3.5, коделлама, LEAM и 𝜇bert в разделе 4.1, как показано на рисунке. В частности, в месте с MethodVocation происходит более 30% некомпилируемых мутаций, а в месте с MemanReference встречается 20%. Это потенциально вызвано неотъемлемой сложностью этих операций, которые часто связаны с множественными зависимостями и ссылками. Если какой-либо требуемый метод или член отсутствуют или не ошибаются, он может легко привести к некомпилируемым мутациям. Ошибки подчеркивают необходимость в лучшей генерации мутаций с учетом контекста, гарантируя, что вызовы метода и ссылки на участники совпадают с предполагаемой структурой программы. Кроме того, мы осматриваем делеционные мутации, отвергнутые компилятором, и обнаруживаем, что для GPT-3,5, коделлама, Leam, 𝜇bert и Major, эти мутации составляют 7,1%, 0,2%, 45,3%, 0,14%и 14,4%всех их некомпиляционных мутаций соответственно. Таким образом, для LLMS удаление не является основной причиной некомпиляции.


Эта статья есть
Оригинал