

Улучшение разнообразия контента с помощью кластеризации на основе НЛП
20 июня 2025 г.В сфере цифрового контента, где обширное количество информации постоянно генерируется и потребляется, понимание и организация этого контента имеет первостепенное значение. Системы, предназначенные для представления контента, часто расставляют приоритеты актуальности, что приводит к эффективному доступу к желаемой информации. Тем не менее, переоценка релевантности может непреднамеренно создать однородность, когда аналогичный контент последовательно представлен, что потенциально ограничивает воздействие новых идей или различных перспектив. Чтобы противодействовать этому, содействие разнообразию контента становится решающим, и обработка естественного языка (NLP) предлагает мощные методы для достижения этого.
Важность разнообразия контента
Приоритет только очень актуального контента может ограничить обнаружение новых и привлекательных тем, усилить существующие перспективы и вызвать разъединение из -за монотонности. Отсутствие разнообразия контента может ограничить рост, вызвать обеспокоенность по поводу предвзятости и препятствовать сбалансированному информационному ландшафту, что потенциально ограничивает более широкое участие. Традиционная организация контента часто приводит к однородности, сосредотачиваясь на прямой актуальности. Балансировка актуальности и разнообразия имеет решающее значение для удовлетворения конкретных потребностей при внедрении новых идей. Кластеризация на основе НЛП предлагает решение, группируя аналогичный контент, позволяя интеллектуальной стратегии диверсификации.
Усовершенствованные методы кластеризации на основе НЛП
Эволюция НЛП дала сложные методы для понимания и представления текста, которые являются фундаментальными для эффективной кластеризации. Современные алгоритмы выходят за рамки простого сопоставления ключевых слов, чтобы охватить контекстуальное понимание и семантические отношения.
Представления контента
- Слово встраивание (Word2VEC, Glove, FastText):Эти методы представляют слова как плотные векторы в высокомерном пространстве, где слова с аналогичными значениями расположены ближе друг к другу. Это позволяет кластеризационным алгоритмам захватывать семантические сходства за пределами точных совпадений слов.
- Предложение и документы Entgeddings (DOC2VEC, универсальный предложение Encoder, предложение-берт):Сделав еще один шаг, эти модели генерируют встраивания для целых предложений или документов. Это имеет решающее значение для разнообразия контента, так как она позволяет системе понимать всеобъемлющую тему и контекст контента, а не только отдельные слова. Например, предложение-Берт приобрела значительную поддержку для своей способности производить очень значимые встраиваемые предложения, что делает его превосходным для расчетов сходства.
- Моделирование тем (скрытое распределение дирихлета - LDA, неотрицательная факторизация матрицы - NMF):Эти вероятностные модели обнаруживают абстрактные «темы», которые встречаются в коллекции документов. Каждый документ затем представлен как смесь этих тем. Несмотря на то, что не сами строго кластеринируют алгоритмы, тематические модели обеспечивают мощное представление о признаках, которое можно привести в традиционные алгоритмы кластеризации для групповых документов по их основным темам.
Парадигмы кластеризации для текстовых данных
- Кластеризация на основе центроида (K-средние):Это широко используемый неконтролируемый алгоритм, который разделяет данные на заранее определенное количество k кластеров. Каждый кластер определяется его центроидом (среднее или медиана его точек), а точки данных присваиваются кластеру с ближайшим центроидом. K-Means просты и эффективны, но он предполагает, что кластеры сферические и одинаковые размеры, и это требует, чтобы количество кластеров (k) было указано заранее.
- Иерархическая кластеризация:Этот метод создает вложенную иерархию кластеров, часто визуализируемой как дендрограмма. Агломеративная (снизу вверх) иерархическая кластеризация начинается с каждой точки данных в качестве собственного кластера и постепенно объединяет ближайшие кластеры, пока все точки не будут в одном кластере или не будут соответствовать критерию остановки. Разделительная (сверху вниз) кластеризация начинается со всех точек данных в одном большом кластере и рекурсивно расщепляет их. Этот подход полезен для визуализации отношений и не требует предварительного определения K, но он может быть вычислительно интенсивным для крупных наборов данных.
- Кластеризация на основе плотности (DBSCAN):DBSCAN (пространственная кластеризация приложений на основе плотности приложений с шумом) идентифицирует кластеры на основе плотности точек данных. ИТ-группировки, которые находятся в тесной упаковке, отмечая как выбросы те точки, которые расположены одни в регионах с низкой плотностью. DBSCAN может обнаруживать кластеры произвольных фигур и не требует определения K, но его производительность может быть чувствительной к настройке параметров (например, значение Epsilon и минимальные точки).
- Глубокое обучение кластеризации:С ростом глубокого обучения подходы, которые интегрируют нейронные сети для извлечения и кластеризации, стали более распространенными. Автокодеры могут изучать сжатые представления текстовых данных, которые затем используются для кластеризации. Более продвинутые методы, непосредственно включающие в себя цели кластеризации в обучение глубоких нейронных сетей, что приводит к сквозным решениям.
- Большие языковые модели (LLMS) для семантической кластеризации:Появление LLM, таких как GPT-3/4, Берт и их производные, произвело революцию в текстовом представлении. Эти модели, предварительно обученные огромным количествам текстовых данных, захватывают невероятно богатую семантическую и контекстную информацию. Используя их сгенерированные встроения (например, из окончательного скрытого слоя), может быть достигнута высокотехнологичная кластеризация содержания, распознавая тонкие тематические соединения, которые могут пропустить более простые модели.
Эти передовые методы выходят за рамки сходства на уровне поверхности, что позволяет определить действительно разнообразной контент, даже если явные ключевые слова различны. Например, статьи о «политике возобновляемой энергии» и «прорывах производства солнечной панели» могут быть объединены вместе, если используется простой подход ключевого слова, но расширенный NLP может идентифицировать их как достаточно различные, чтобы способствовать разнообразию в более широкой теме «энергии». Как только текстовое содержание преобразуется в богатые семантические векторные представления, различные алгоритмы кластеризации могут быть использованы для группы аналогичных элементов.
Операционный поток для диверсификации контента
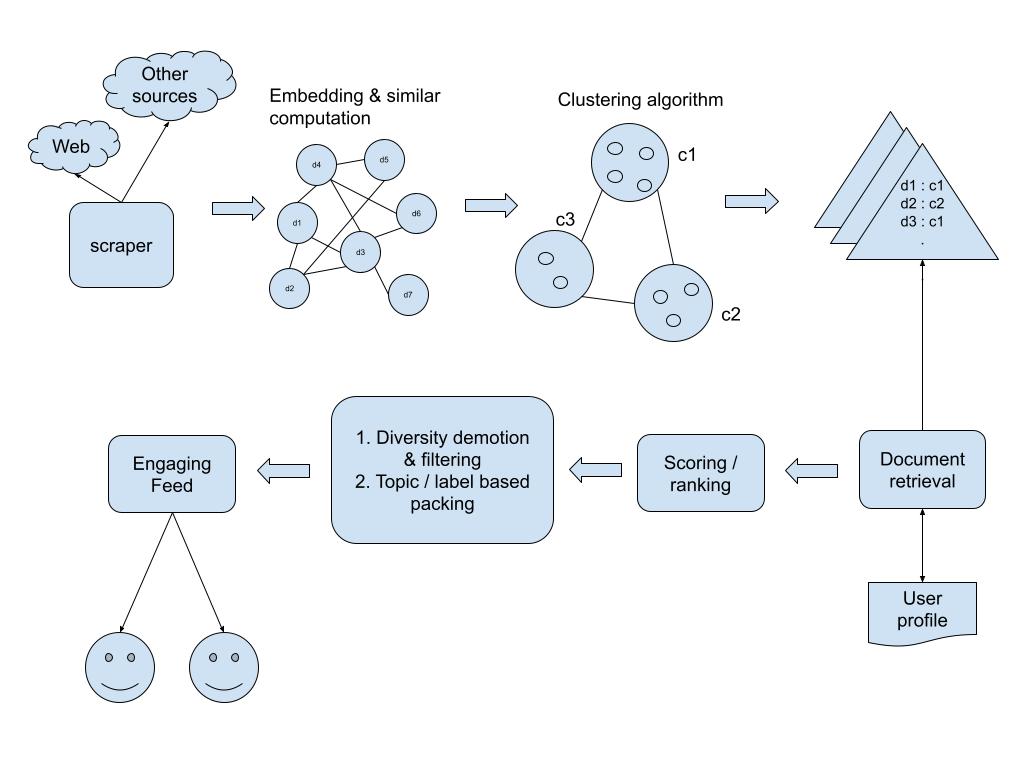
Давайте разберем эксплуатационный поток системы диверсификации контента, более подробно подчеркивая ключевые шаги.
1. Собственность и предварительная обработка данных:
- Источник агностик:Процесс начинается с употребления содержания из различных источников. Это может включать в себя новостные статьи, сообщения в блоге, видео -транскрипты или описания продуктов.
- Очистка и нормализация:Сырой текст часто неструктурирован. Этот этап включает в себя:
- Удаление HTML -тегов, специальных символов и текста шаблона.
- Преобразование текста в строчный.
- Токенизация: разбивание текста в слова или подразделения подночи.
- Удаление остановки: устранение общих слов (например, «The», «IS», «A»), которые несут небольшой семантический вес.
- Лемматизация/Stemming: уменьшение слов в их базовую форму (например, «Запуск» → «Запуск»).
2. Представление признаков (генерация встраивания):
- Выбор правильной модели:Это критическое решение. Для общего назначения контента предварительно обученные кодеры предложения (например, универсальный кодер предложения или предложение-берт) часто обеспечивают отличную производительность из коробки. Для высокоспециализированных доменов может потребоваться тонкая настройка LLM по данным, специфичным для домена.
- Векторизация:Каждый предварительный элемент контента пропускается через выбранную модель NLP для генерации высокоразмерного векторного встраивания. Эти встраивания отражают семантическое значение и контекстуальные нюансы содержания. Для тематического моделирования, такие инструменты, как Gensim, могут использоваться для создания распределений тем для каждого документа.
3. Кластеризация контента:
- Выбор алгоритма:
- K-средние:Просто, быстро и эффективно для многих наборов данных, но требует предварительного определения количества кластеров (k). Определение оптимального «k» может быть итеративным процессом, используя такие методы, как метод локтя или оценка силуэта.
- Иерархическая кластеризация:Создает иерархию кластеров, полезную для понимания взаимосвязей контента на разных уровнях гранулярности. Может быть вычислительно дорогой для очень больших наборов данных.
- HDBSCAN:Алгоритм на основе плотности, который не требует предварительного определения «K» и может идентифицировать шум. Отлично подходит для наборов данных с различной плотностью кластера.
- Гауссовые модели смеси (GMM):Предполагается, что точки данных генерируются из смеси гауссовых распределений, что позволяет получить вероятностные назначения кластера.
- Уменьшение размерности (необязательно, но рекомендуется):Для очень высокомерных встраиваний, такие методы, как PCA (анализ основных компонентов) или UMAP (приближение и проекция единого коллектора), могут уменьшить размерность перед кластеризацией, повышают эффективность вычислительной техники и иногда качество кластеризации, сохраняя при этом важную информацию.
- Оценка:Результаты кластеризации оцениваются с использованием таких метрик, как оценка силуэта, индекс Дэвис-Боулдина или визуальный осмотр с использованием графиков уменьшения размерности (например, T-SNE). Это помогает в настройке параметров и обеспечении значимых кластеров.
4. Выбор и диверсификация контента:
- Стратегия диверсификации:После того, как содержание организовано в кластеры, применяется стратегия диверсификации.
- Максимальная маргинальная значимость (MMR):Популярный алгоритм, который уравновешивает актуальность с разнообразием. Он итеративно выбирает элементы контента, которые имеют отношение к данному запросу и разнообразные из уже выбранных элементов.
- Mmr = argmaxdi ∈R ∖ s (λ %sim1 (di, q) - (1 - λ) ⋅dj ∈Smax sim2 (di, dj)), где Di - это кандидат, q - это запрос, S - набор уже выбранных элементов, r - набор кандидатов, SIM1 - это сходство, сходство SIM2. различие), а λ - балансировка параметров, уравновешивающая актуальность и разнообразие.
- Выбор на основе кластера:Более простой подход может включать выборку фиксированного количества элементов из каждого из лучших кластеров, обеспечивающих представление из разных тем.
5. Развертывание и итерация:
- Интеграция API:Разнообразный двигатель выбора контента может быть интегрирован через API для различных приложений.
- Мониторинг и оценка:Непрерывно отслеживает ключевые показатели, такие как взаимодействие с разнообразным содержанием и стратегиями усовершенствования диверсификации.
- Обновления динамической кластеризации:Контент постоянно меняется. Модели кластеризации должны периодически переподтировать или обновляться, чтобы включить новый контент и развивающиеся тенденции. Это гарантирует, что кластеры остаются репрезентативными и точными.
Вывод: более богатый опыт контента
В мире, все более формированном алгоритмами, стремление к разнообразию контента является не просто технической задачей, а концептуальным императивом. Выходя за рамки упрощенных показателей релевантности, методы кластеризации на основе НЛП предоставляют фундаментальные строительные блоки для построения систем организации контента, которые способствуют обнаружению, оспаривают перспективы и обогащают общий опыт.
Путешествие от необработанного текста к действительно разнообразной презентации контента включает в себя сложные модели NLP для глубокого семантического понимания, надежных алгоритмов кластеризации для значимой группировки и интеллектуальных стратегий отбора, которые уравновешивают актуальность с разведкой. Поскольку NLP продолжает развиваться, особенно с достижениями в крупных языковых моделях, возможности для создания еще более нюанса и динамичного разнообразия контента бесконечны. Конечная цель состоит в том, чтобы освободиться от однородности, предлагая окно в более широкий, более яркий информационный ландшафт, один выбор контента за раз. Речь идет о строительных системах, которые не просто определяют то, что явно ищет, но и то, что можно оценить, учитывая возможность обнаружить это.
Связанные статьи
- «Эффективная оценка представлений слов в векторном пространстве» Томас Миколов и соавт. (Word2VEC):https://arxiv.org/abs/1301.3781Эта основополагающая статья представила Word2VEC, ключевой метод создания плотных векторных представлений слов, которые отражают семантические отношения, формируя основу для многих современных методов встраивания НЛП.
- «Документ, встраивающийся с параграфовыми векторами» Эндрю М. Дай и др.:https://arxiv.org/abs/1507.07998Полем Расширение встроенных слов на документы Doc2VEC предоставляет метод представления целых текстов в качестве векторов, что имеет решающее значение для кластеризации контента на уровне документа.
- «Универсальный предложенный кодер» Даниэль Сер и соавт. (Google Research):https://arxiv.org/abs/1803.11175Полем Широко принятая предварительно обученная модель, которая создает очень значимые и универсальные встроенные предложения, упрощая процесс получения богатых текстовых представлений для различных задач NLP, включая кластеризацию.
- «Приговор-Берт: встраивание приговора с использованием сиамских берт-сети» от Nils Reimers и Iryna Gurevych:https://arxiv.org/abs/1908.10084Полем Эта работа значительно улучшила качество встроенных предложений с помощью тонкой настройки BERT со структурой сиамской сети, что делает его особенно эффективным для задач семантического сходства и, соответственно, кластеризации.
Оригинал