
Помогает ли Lora Fine-Muning Models меньше забывать?
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
4.3 Обмен на обучение
Тривиально, что модели, которые меняются меньше, при условии, что он вновь влевает в новую целевую область, забудут меньше о домене исходного происхождения. Нетривиальный вопрос: отличаются ли Лора и полная производительность по тому, как они компромиссы обучения и забывают? Может ли Лора достичь аналогичной целевой домены, но с уменьшенным забыванием?
Мы формируем кривую, устанавливающую обучение Парето, построив агрегат, забывая метрику и метрику обучения (GSM8K и Humaneval), с различными моделями (обученными для разных продолжительности) разбросаны в виде точек в этом пространстве (рис. 4). Лора и полное создание, похоже, занимают ту же кривую Парето, с моделями Lora в правом нижнем углу - меньше учится и меньше забывает. Тем не менее, мы можем найти случаи, особенно для кода IFT, где для сопоставимого уровня производительности целевой домены LORA демонстрирует более высокую производительность исходного домена, представляя лучший компромисс. На дополнительном рисунке S5 мы показываем необработанные оценки оценки для каждой модели. На рис. S3 мы рассеиваем лама-2-13B приводит к тому же участку, что и Llama-2-7b для кода CPT.
4.4 Свойства регуляризации Лоры
Здесь мы определяем регуляризацию (свободно) как механизм обучения, который держит конйронную LLM, похожую на базовый LLM. Сначала мы анализируем сходство в компромиссе-обучении, а затем в созданном тексте.

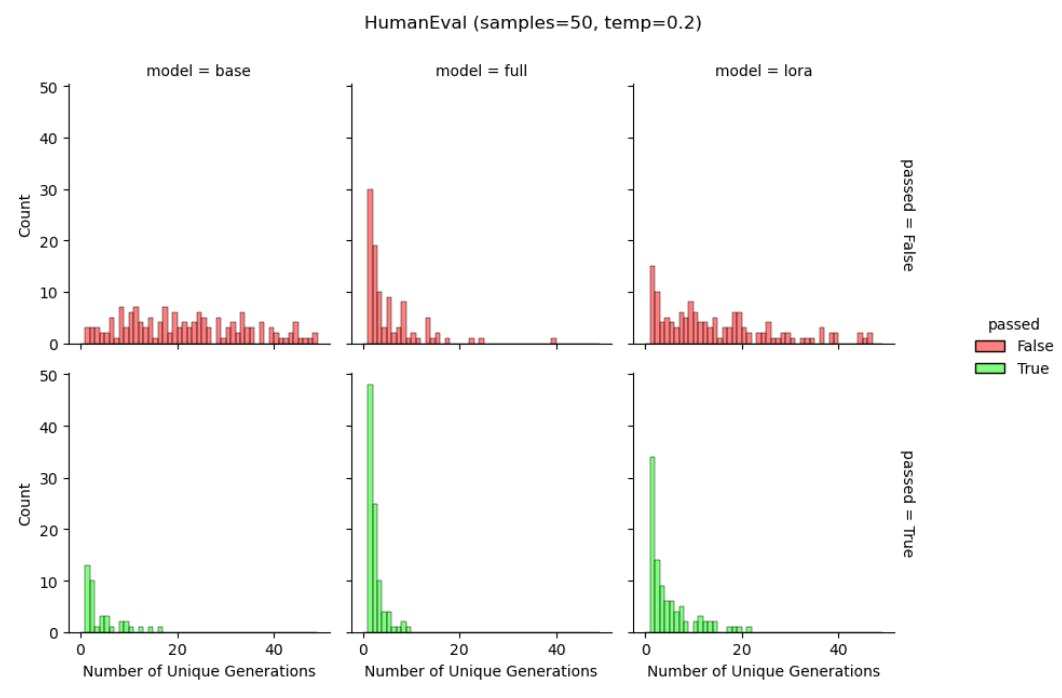
Лора помогает поддерживать разнообразие токеновых поколений.Мы снова используем модели Llama-2-7B, обученные набору данных Magicoder-Evol-Instruct-110K, чтобы изучить сгенерированные строки во время HumaneVal. Мы рассчитываем уникальное количество выходных строк из 50 поколений (для базовой модели, полной конфигурации и LORA), служащих грубым прокси для прогнозирующего разнообразия. На рисунке 6 мы отдельно показываем результаты для правильных и неправильных ответов. Как и в подкреплении, обучаясь в литературе по обратной связи с человеком (Du et al., 2024; Sun et al., 2023), мы обнаруживаем, что полное создание приводит к меньшему количеству уникальных поколений («коллапс распределения») по сравнению с базовой моделью, как для проходов, так и для провальных поколений. Мы находим, что Лора обеспечивает компромисс между ними, в
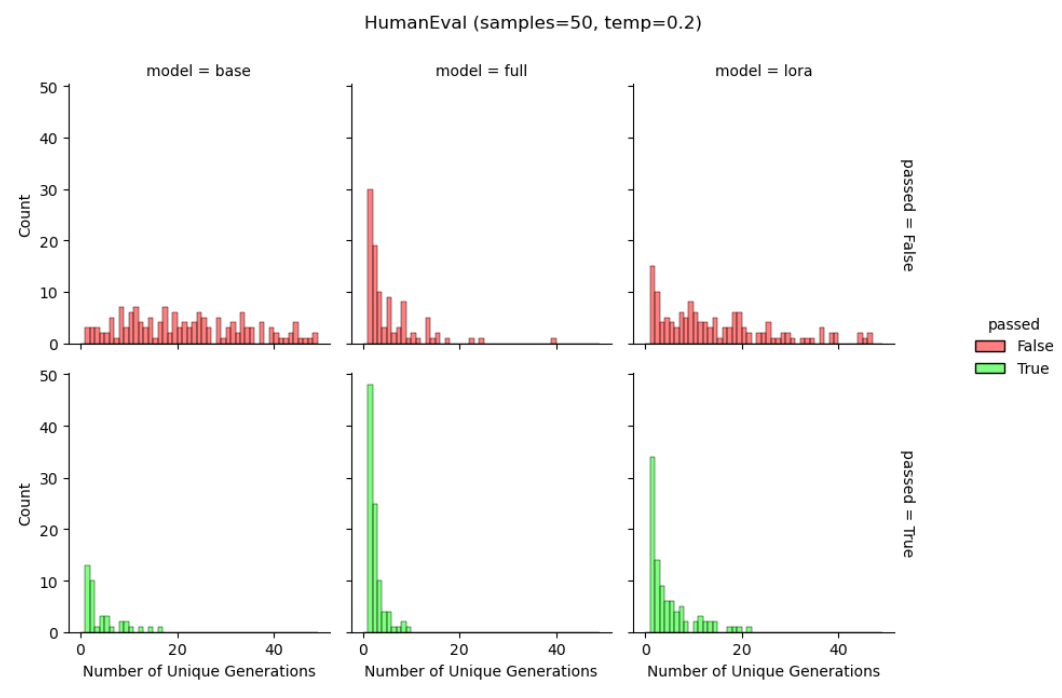
Уровень поколений. Приведенные выше работы также предполагают, что Лора может даже заменить общий термин регуляризации, который сохраняет вероятности сгенерированного текста сходным между созданной и базовой моделью.
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал