

Анализ потерь по перекрестной энтропии в трансформаторных сетях
19 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 модели и 3.1 ассоциативные воспоминания
3.2 трансформаторные блоки
4 Новая энергетическая функция
4.1 Слоистая структура
5 Потеря по перекрестной энтропии
6 Эмпирические результаты и 6.1 Эмпирическая оценка радиуса
6.2 Обучение GPT-2
6.3 Тренировка ванильных трансформаторов
7 Заключение и подтверждение
Приложение A. отложенные таблицы
Приложение B. Некоторые свойства энергетических функций
Приложение C. отложенные доказательства из раздела 5
Приложение D. Трансформатор Подробности: Использование GPT-2 в качестве примера
Ссылки
5 Потеря по перекрестной энтропии
Теперь мы приступаем к анализу потери трансформаторных сетей. Потеря по перекрестной энтропии, которая измеряет разницу между прогнозируемыми вероятностями и фактическими этикетками, обычно используется для обучения моделей трансформаторов. Механизм внимания включает в себя операцию SoftMax, которая выводит распределение вероятностей p ∈ ∆n. На практике окончательный выход Softmax затем подается в специфический слой для задач, такие как прогнозы и классификации. Таким образом, мы сравниваем последний выход Softmax блоков трансформатора с целевым распределением.

У нас есть следующий результат относительно потери перекрестной энтропии.

Замечание 2Перекрестная энтропия может быть написана как
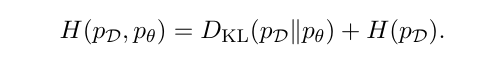
Когда модель сильно перепаратирована, энергетическая функция вполне может приблизительно приближать энергию распределения образцов. В этом случае минимальная перекрестная энтропия равна энтропии тренировочных образцов.
Затем мы более внимательно рассмотрим функцию разделения слоя. У нас есть

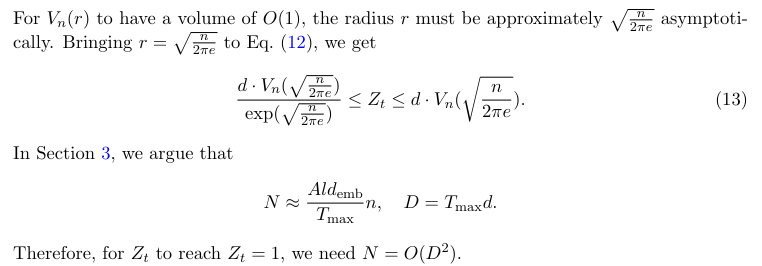
В таблице 2 в Приложении A мы сравниваем сообщенную потерю перекрестной энтропии различных трансформаторных моделей в литературе. Обычно сообщается о семействе моделей в различных размерах, и мы выбираем самые большие. Мы наблюдаем, что аналогичные потери перекрестной энтропии достигаются в широком диапазоне архитектурных форм (включая глубину, ширину, головки внимания, размеры FF и длину контекста). Тем не менее, все потери удовлетворяют L> 1.
Замечание 3Мы отмечаем, что некоторые модели добавляют термины вспомогательной регуляризации, такие как Z-Loss (Chowdhry et al., 2023; Yang et al., 2023) во время их обучения. В этих случаях законы масштабирования должны учитывать дополнительные условия. Кроме того, модификации к блокам трансформатора, такие как дополнительная нормализация слоя, могут способствовать нижней границе поперечной энтропии.
Авторы:
(1) Xueyan Niu, Theory Laboratory, Central Research Institute, 2012 Laboratories, Huawei Technologies Co., Ltd.;
(2) Бо Бай Байбо (8@huawei.com);
(3) Lei Deng (deng.lei2@huawei.com);
(4) Вэй Хан (harvey.hanwei@huawei.com).
Эта статья есть
Оригинал