

Сравнение затрат, юзабилити и результатов разнообразие методов тестирования мутаций
4 июня 2025 г.Авторы:
(1) Бо Ван, Университет Пекин Цзиотонг, Пекин, Китай (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Пекинский университет Цзиотонга, Пекин, Китай (23120337@bjtu.edu.cn);
(3) Youfang Lin, Пекинский университет Цзиотонг, Пекин, Китай (yflin@bjtu.edu.cn);
(4) Майк Пападакис, Университет Люксембурга, Люксембург (michail.papadakis@uni.lu);
(5) Цзе М. Чжан, Королевский колледж Лондон, Лондон, Великобритания (jie.zhang@kcl.ac.uk).
Таблица ссылок
Аннотация и1 Введение
2 предыстория и связанная с ним работа
3 Учебный дизайн
3.1 Обзор и исследования исследований
3.2 Наборы данных
3.3 генерация мутаций через LLMS
3.4 Метрики оценки
3.5 Настройки эксперимента
4 Результаты оценки
4.1 RQ1: производительность по стоимости и юзабилити
4.2 RQ2: сходство поведения
4.3 RQ3: воздействие различных подсказок
4.4 RQ4: воздействие различных LLMS
4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.2 Последствия
5.3 Угрозы достоверности
6 Заключение и ссылки
4 Результаты оценки
Мы выполнили наш экспериментальный анализ на двух облачных серверах, каждый из которых оснащен 2 Nvidia GeForce RTX 3090 TI, памятью 168 ГБ и 64 COR CPU Intel (R) Xeon (R) Platinum 8350C.
4.1 RQ1: производительность по стоимости и юзабилити
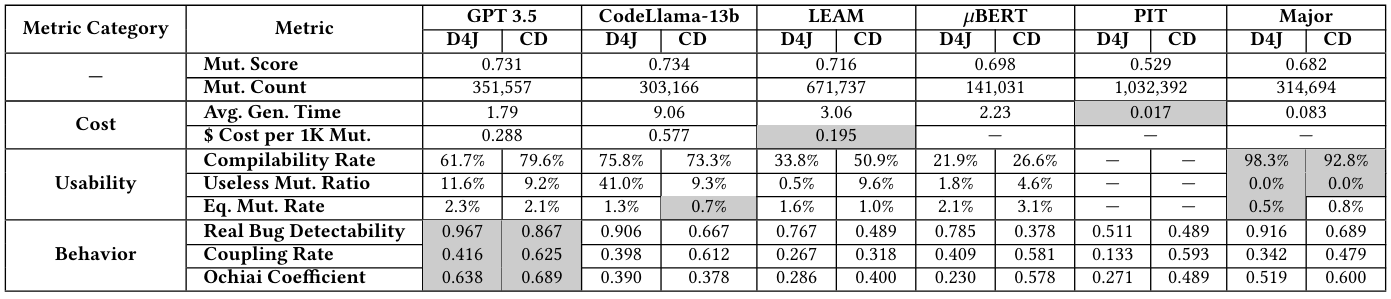
4.1.1 Стоимость.Для каждого метода мы регистрируем продолжительность генерации и стоимость использования API или серверов GPU, показанных как линии стоимости таблицы 4. Кроме того, мы также сообщаем о количестве мутаций и оценке мутации, хотя они не полностью отражают общее качество набора мутаций.
Из таблицы мы можем обнаружить, что GPT-3,5 и Codellama-30Binstruct генерируют 351 557 и 303,166 мутации [1] с оценкой мутации 0,731 и 0,734 соответственно. Традиционные подходы и основные дают самый низкий балл мутации среди всех подходов.
С точки зрения затрат, GPT-3.5 и Codellama-13b стоили 1,79 и 9,06, чтобы генерировать мутации соответственно. В то время как Leam, 𝜇bert, Pit и основная стоимость 3,06 с, 2,23 с, 0,017 и 0,083 с соответственно, что указывает на то, что предыдущие подходы быстрее, чем подходы на основе LLM при генерации мутаций. С точки зрения экономических затрат, мы записываем только стоимость использования API GPT-3.5 и стоимость облачного сервера для запуска Codellama и Leam, потому что оставшиеся подходы едва нуждаются в ресурсах графического процессора. Результат указывает на то, что аренда облачных серверов для запуска моделей с открытым исходным кодом стоит дороже, чем использование API для GPT3.5.

4.1.2 Мутационная удобство использования.На способность мутаций (то есть, можно ли использовать мутации для расчета оценки мутации), зависит от возможностей LLM в правильном понимании задачи и генерации компилируемых, не-дюблиальных и некселевных мутаций. Результаты показаны как строки юзабилити в таблице 4. Из -за потенциальной угрозы утечки данных мы представляем данные Defects4J и проводятся отдельно. Обратите внимание, что мутации ямы находятся в форме Java Bytecode и не могут быть преобразованы обратно на уровень источника, поэтому мы пропускаем яму, отвечая на этот RQ.
Скорость комбинации:Мы наблюдаем, что GPT-3,5 достигает скорости компиляции 61,7% для Defects4J и 79,6% для наборов данных Condefects. В то время как Codellama-13b достигает более высокого уровня компилируемости 75,8% для Defects4j и 73,3% для проведений. Основанный на правилах подход Major достигает самой высокой скорости компиляции (то есть 98,3% на Defects4j и 92,8% на проведения проведения). Обратите внимание, что, хотя крупный работает в соответствии с простыми правилами синтаксиса, он все еще может генерировать некомпилируемых мутантов. Например, анализатор компилятора Java отвергает конструкции, как (True)
Бесполезная скорость мутации:Мы также наблюдаем, что ЛЛМ генерируют значительную часть дублирующих и бесполезных мутаций. Например, для Defects4j GPT-3,5 генерирует 11,6% бесполезных мутаций, что составляет 18,8% всех компилируемых мутаций (то есть 11,6%/61,7%). Напротив, Leam, 𝜇bert и Major, редко генерируют дублирующиеся мутации, что, вероятно, связано с тем, что эти подходы регулируются строгими грамматическими правилами, которые ограничивают производство избыточных мутаций. Например, крупный итеративно применяет различные операторы мутаций, не производящие невыполненные мутанты.
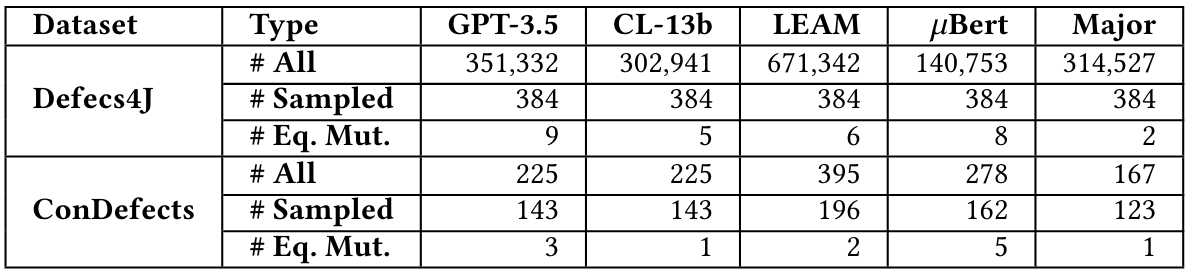
Эквивалентная скорость мутации:Эквивалентные мутации изменяют синтаксически исходный код, не влияя на функциональность программы, тем самым влияя на точность расчетов оценки мутации. Из -за неразрешимой природы идентификации эквивалентных мутаций невозможно разрабатывать алгоритм, который может полностью их обнаружить. Поэтому мы выбираем подмножество мутаций для каждой техники и вручную оцениваем, являются ли они эквивалентными. Чтобы поддерживать уровень достоверности 95% и 5% погрешность, мы выбрали фиксированное количество мутаций с вывода каждого подхода, чтобы вычислить эквивалентную скорость мутаций. После протокола существующих исследований [26, 31] два автора, каждый из которых имеет более пяти лет опыта программирования Java, сначала проходили обучение по эквивалентным мутантам, а затем независимо помечали мутации. Окончательный показатель коэффициента Коэна Каппа [75] составляет более 90%, что указывает на высокий уровень согласия. В таблице 5 показано количество отбранных мутаций и количество идентифицированных эквивалентных мутаций.
Мы снова наблюдаем, что майор выполняет лучшее в генерации не эквивалентных мутантов. В частности, как показано в нижнем ряду юзабилити в таблице 4, для GPT-3,5, 2,3% мутаций, генерируемых на Defects4J, эквивалентны, в то время как скорость составляет 2,1% на проводниках. Codellama-13b показывает более низкие показатели: 1,3% и 0,7% на Defects4j и Condefects соответственно. Leam генерирует эквивалентные мутации со скоростью 1,6% на Defects4J и 1,0% на проводниках. 𝜇bert производит 2,1% на Defects4j и 3,1% на проведения. Крупные достигают самые низкие показатели: только 0,5% при дефектах4J и 0,8% на проводниках.
При сравнении двух наборов данных Defects4j и проводникам для трех аспектов использования, представленных выше, мы наблюдаем, что метрики различаются между дефектами4J и проводят наборы данных для каждого подхода мутации. Этот вариант может быть связан с различиями в сложности и структуре ошибок, присутствующих в каждом наборе данных. Мутации в Defects4j могут включать API и глобальные переменные, которые явно не упоминаются в подсказываниях, делая
контекст более сложный. Эта сложность приводит к тому, что обе метрики уступают Defects4J по сравнению с проведениями.

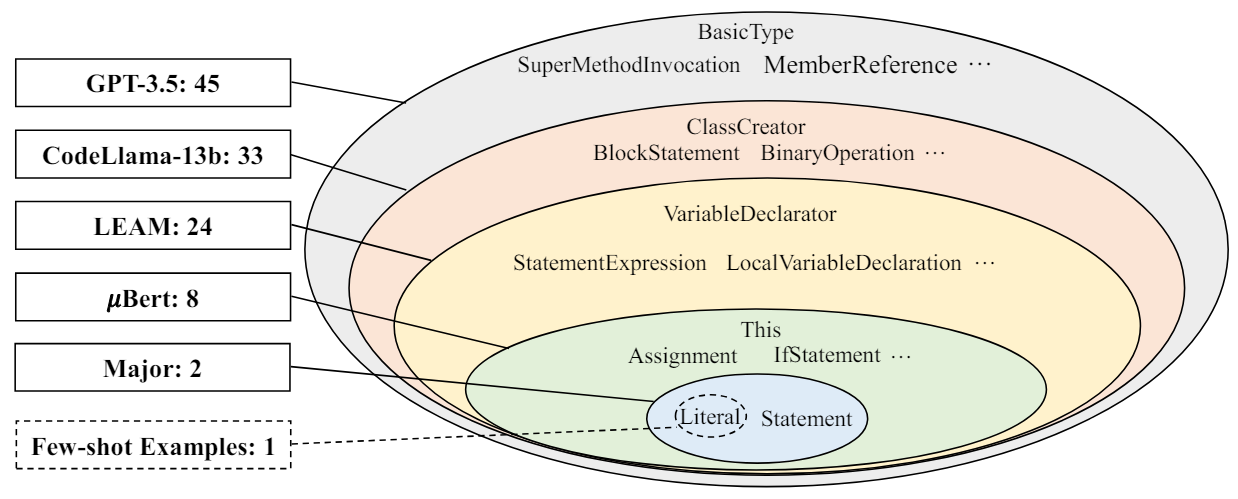
На рисунке 2 показаны результаты, которые показывают, что подходы мутации на основе LLM вводят больше типов новых узлов AST, чем другие подходы. GPT-3.5 демонстрирует наибольшее разнообразие, внедряя 45 новых типов узлов AST и подчиняя все другие подходы. Традиционный подход Major представляет только два новых типа AST
узлы, которые не удивительны, поскольку операторы мутации являются фиксированным набором простых операций.
Мы также проверяем разнообразие узлов AST примеров, которые мы предоставили в подсказках LLM (см. Таблицу 3), как показано на «нескольких выстрелах» на рисунке 2. Интересно, что мы обнаруживаем, что эти примеры вводят только один новый тип узла AST. Это указывает на то, что LLMS творческие в создании мутаций, создавая значительно более разнообразные мутации, чем приведенные им примеры.
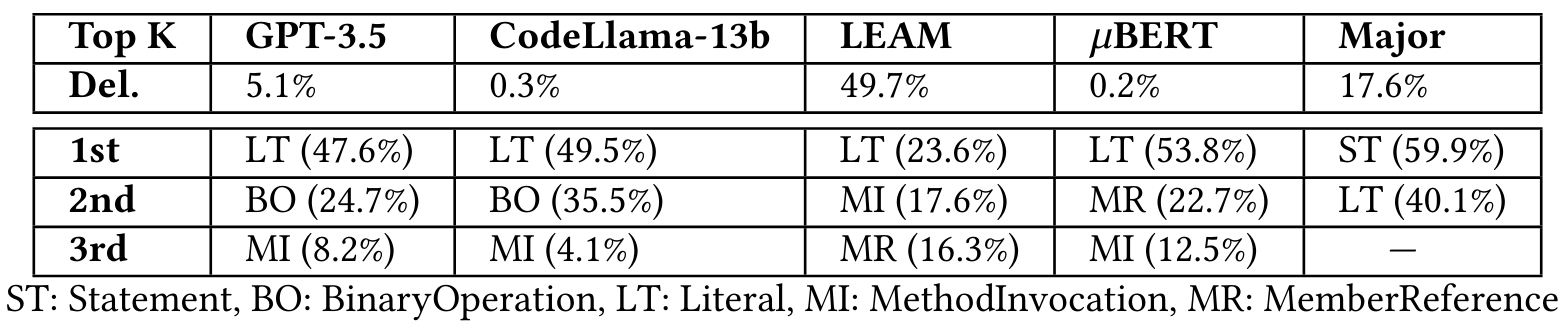
Мы дополнительно проанализировали распределение делеций и типов узлов AST по различным подходам, как показано в таблице 6, в котором выделены наиболее частые типы узлов AST Top-3. Для доли делеций GPT-3,5 и Codellama-13b генерируют 5,1% и 0,3% делеций соответственно. Почти половина мутаций Leam-это делеции, что может быть причиной создания многих некомпилируемых мутаций. Основной генерирует удаления в ограниченных местах и приводит к 17,6% удалениям. 𝜇bert заменяет элементы кода в масках на BERT, тем самым редко имея делеции.
Садовые типы узлов AST, наиболее частый новый тип узлов AST всех подходов, основанных на обучении, является буквальным (например, 𝑎> 𝑏 ↦ → True). Однако для основного подхода, основанного на правилах, наиболее частым типом узла является оператор (например, замена оператора на пустое утверждение). Обратите внимание, что, хотя эти мутации не связаны с оператором удаления, существует значительная часть производства пустых утверждений, что приводит к большой доле.

Эта статья есть
[1] Хотя GPT-3.5 и Codellama-13b получают инструкции генерировать одинаковое количество мутаций, они не последовательно следуют инструкциям, тем самым давая различное количество мутаций.
Оригинал