
Сообщество, настроенные на модели ИИ, популярны, но они в безопасности?
10 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Связанная работа
- Эксперименты
- 3.1 Дизайн
- 3.2 Результаты
- 3.3 Сравнение 2: Настраиваемые и настройки
- 3.4 Сравнение 3: Настройка инструкции и настройки сообщества
- Дискуссия
- Ограничения и будущая работа
- Заключение, подтверждение и раскрытие финансирования и ссылки
А. Модели оцениваются
B. Данные и код
Neurips Paper Checklist
3 эксперименты
3.1 Дизайн
Выбор моделиПолем Чтобы проанализировать влияние тонкой настройки на токсичность, мы сначала выбираем небольшое количество моделей высокого воздействия для экспериментов. Для вычислительной эффективности, и поскольку у многих разработчиков сообщества также отсутствуют вычислительные ресурсы для крупных моделей, мы выбираем небольшие модели, предлагаемые тремя основными лабораториями, Google, Meta и Microsoft для анализа. Для каждой лаборатории мы выбираем два поколения моделей (например, Llama-2 и Llama-3), чтобы с течением времени изучить потенциальные изменения. Для каждой модели мы стремились проанализировать как модель фундамента, так и настройку инструкций, или вариант, настроенный в чате, где это доступно. Всего было проанализировано шесть моделей: Phi-3-Mini, Phi-3,5-минутный, лама-2-7b, llama-3,1-8b, gemma-2b и gemma-2-2b.
Для каждой модели, настроенной на инструкцию, мы проводили дополнительную точную настройку, используя набор данных Dolly из DataBricks, набор данных с открытым исходным кодом 15K, последовательных инструкций по темам, включая вопрос о ответе на вопросы, генерацию текста и суммирование (Conover et al., 2023). Набор данных не намеренно содержит токсическое содержание и предназначен для тонкой настройки моделей для улучшения возможностей обучения. Мы провели тонкую настройку Lora через библиотеку USLOTH и настроили каждую модель, используя графический процессор T4 через Google Colab для 1 эпохи, а предыдущая работа демонстрирует количество эпох, по-видимому, не оказывает существенного влияния на производительность безопасности (Qi et al., 2023).
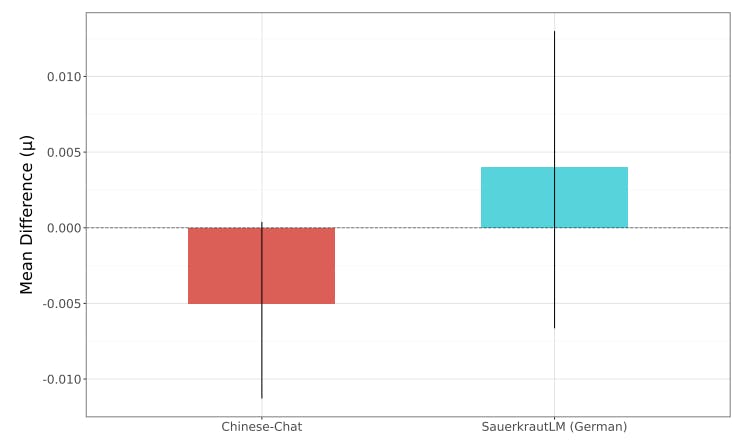
Наконец, для каждой модели, настроенной на инструкции, мы выбрали дополнительные варианты, настроенные на сообщество, загруженные на обнимающееся лицо, которое было настраивалось на концертной точке, настроенной на инструкции. Чтобы выбрать эти модели, мы искали модель, настроенную на инструкцию в библиотеке модели обнимающего лица, и отсортировали модели по «наиболее загруженным» (ежемесячно), чтобы оценить модели, которые обычно использовались другими пользователями. Многие из самых популярных моделей были количественно моделями, которые были удалены из анализа. Мы выбрали только модели, которые были доступны с использованием библиотеки Transformers, и проанализировали две модели, настроенные для сообщества для каждого варианта, настроенного на инструкции. Мы наблюдали, что часто самые популярные модели, связанные с тонкой настройкой для улучшения многоязычных возможностей или тонкой настройки для нецензурирования, иначе известного как «ослабление», где настраивается точная настройка, чтобы снизить показатели отказа. Это позволило нам оценить ряд моделей, настроенных на сообщество, которые, как можно ожидать, повлияет на токсичность по-разному.
Окончательные модели, выбранные в совокупности, были загружены более 60 000 раз за месяц до анализа, подчеркивая популярность и актуальность моделей, настроенных на сообщество.
ДанныеПолем Чтобы оценить токсичность, мы собрали набор данных из 2400 подсказок. Большинство подсказок, полученных из набора данных RealtoxicityPrompts (Gehman et al., 2020). 1000 подсказок набора данных 2,4K были случайным образом отобраны из набора данных RealtoxicityPrompts, чтобы оценить, как модели реагируют на ряд токсичных и нетоксичных входных подсказок (Gehman et al., 2020). Дополнительные 1000 подсказок были выбраны на основе оценки> 0,75 для «тяжелой токсичности» в рамках набора данных RealtoxicityPrompts. Эти подсказки были направлены на оценку того, как надежные модели были конкретными атаками, стремящимися выявить токсичные результаты. Последние 400 подсказок состояли из четырех 100 наборов данных, охватывающих подсказки, нацеленные на гонку, возраст, пол и религию, взятые из набора данных Composition Cliterkation (CEB), предназначенного для анализа потенциальных различий в производительности по конкретным темам (S. Wang et al., 2024).
ПоказательПолем Модель Роберта-Хейт-Спеч-Динабенч-R4 использовалась для определения токсичности модельных поколений (Vidgen et al., 2020). Эта модель является показателем токсичности по умолчанию, предоставляемой библиотекой «Объявление оценить библиотеку», и определяет токсичность или ненависть, как «оскорбительную речь, нацеленную на конкретные характеристики группы, такие как этническое происхождение, религия, пол или сексуальная ориентация». Модель оценивает каждый вывод от 0 (не токсичный) до 1 (токсичный) и устанавливает порог по умолчанию> 0,5 для определения токсического вывода.
СравненияПолем Чтобы оценить влияние тонкой настройки на токсичность, мы проводим три эксперимента:
Сравнение базовых моделей с настраиваемыми инструкциями вариантамиПолем Мы анализируем, как тонкая настройка моделей влияет на токсичность.
Сравнение вариантов, настроенных на инструкции с настраиваемыми вариантамиПолем Мы сравниваем, как на токсичность влияет, когда варианты настроек, настроенные на инструкции, постоянно настраиваются с использованием нерасковного набора данных (Dolly), используя эффективную адаптацию с низкой настройкой параметра.
Сравнение вариантов, настроенных на инструкции с настраиваемыми вариантамиПолем Мы оцениваем, как на токсичность влияется на популярно используемые варианты сообщества моделей, настроенных на инструкции.
Для каждого эксперимента мы устанавливаем температуру на 0 для всех поколений моделей, чтобы определить наиболее вероятный ближайший токен. Для каждого поколения мы ограничивали выходы модели до 50 токенов. Все модели были доступны через модель обнимающего лица с использованием библиотеки трансформаторов. Эксперименты проводились с использованием Google Colab с использованием одного графического процессора L4. В общей сложности мы оценили 28 моделей, которые полностью перечислены в Приложении A.
ОценкаПолем Чтобы определить, существует ли достоверная разница между склонностью моделей к выводу токсического содержания, мы проводим анализ байесовских оценок (наилучших), чтобы сравнить результаты пар моделей. Мы проводим этот анализ с использованием показателя непрерывной токсичности (YIJ), предоставленного показателем токсичности, в диапазоне от 0 до 1. Мы предполагаем, что оценки для каждой модели J отображаются из T-распределения:
yij ∼ t (ν, µj, σj),
Где ν - степень свободы, µJ - средняя оценка токсичности для модели J, а σJ - параметр масштаба для модели J. Затем мы оцениваем заднее распределение разницы между группами группы (µ1 - µ2), используя байесовские выводы и методы марковской цепи Монте -Карло (MCMC). Мы используем слабо информативные априоры для µ и σ, со стандартным нормальным распределением, применяемым для предварительного распределения полу-каучи с бета-версией 10 в случае σ (Gelman, 2006).
Мы выбираем байесовский анализ, а не традиционные тесты значимости, такие как тест хи-квадрат или Z-тест по двум причинам. Во -первых, характер проведения оценок на генеративных моделях означает, что это может быть тривиальным для достижения статистически значимых, но практически небольших различий в выходах моделей. Во -вторых, различные ученые выделили ловушки сходящих непрерывных данных в дихотомические данные для целей анализа значимости (Dawson & Weiss, 2012; Irwin & McClelland, 2003; Royston et al., 2006). В результате мы пришли к выводу, что байесовский анализ был наиболее подходящим измерением для определения достоверных различий между скоростями токсичности для разных моделей.
Авторы:
(1) Уилл Хокинс, Оксфордский интернет -институт Оксфордского университета;
(2) Брент Миттельштадт, Оксфордский институт Интернета в Оксфордском университете;
(3) Крис Рассел, Оксфордский интернет -институт Оксфордского университета.
Эта статья естьДоступно на ArxivПо лицензии CC 4.0.
Оригинал