

Могут ли модели искусственного интеллекта следовать инструкциям, которые они никогда не видели раньше?
19 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
4.2 Обобщение между инструкциями
Мы всесторонне изучаем способность нашей многозадачной модели-модели обобщать различные формы невидимых инструкций. В первую очередь мы стараемся выполнять просмотренные задачи с различными инструкциями, чем те, которые используются для обучения. Мы создаем новые подсказки для некоторых учебных задач и оцениваем надежность модели до вариаций в подсказке. Далее мы демонстрируем потенциал модели для использования надежного языкового понимания основного LLM для обобщения до совершенно новых задач, которые модель вообще не видела во время мультимодального создания.
4.2.1 Измерение устойчивости для быстрого вариации
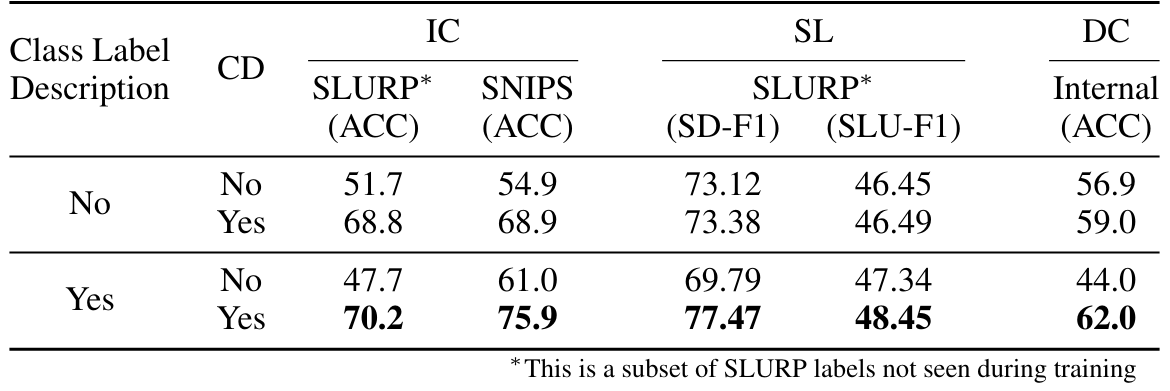
Чтобы оценить влияние различных подсказок на выполнение задачи обучения, мы протестировали нашу модель MultiTaskWLM с дополнительными подсказками для 3 различных задач: ASR, ST и AC. Мы тестируем с тремя подсказками для выполнения задачи, когда одно из них находится непосредственно из набора подсказок, используемых во время обучения, в то время как два дополнительных новых подсказок создаются с использованием другой формулировки и контекста. Как показано в таблице 5, модель демонстрировала аналогичные характеристики по подсказкам для каждой задачи. Для задачи ASR мы видим лишь незначительное изменение 0,3 в между наблюдаемыми и невидимыми подсказками. Точно так же для задачи ST и AC значения метрики падают очень мало с изменением подсказки. Эти небольшие различия показывают, что наша модель хорошо обобщала свои основные возможности и не сильно зависит от конкретной формулировки или контекста подсказок. Хотя быстрое проектирование остается важным для оптимальной производительности, эти результаты показывают, что модель изучила надежные навыки, конкретные, которые передают по выбору подсказок, по крайней мере, для задач, наблюдаемых во время обучения. Для задач, выходящих за рамки тех, которые можно увидеть во время обучения, мы изучаем быстрый дизайн отдельно в более позднем подразделе 4.3.1.
4.2.2.
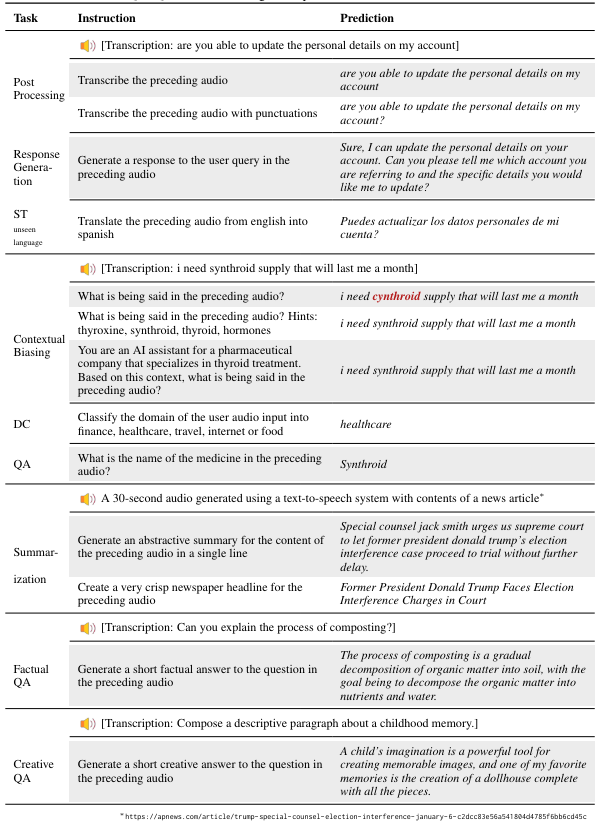
Чтобы изучить способность модели понимать открытые текстовые и речевые инструкции, мы побудили модель с несколькими неограниченными творческими запросами, которые не были частью нашей учебной программы. Мы перечисляем несколько таких примеров в таблице 6. Во многих из этих примеров модель должна демонстрировать глубокое понимание как разговорных, так и письменных директив для успешного выполнения задачи. Например, в творческой задаче QA модель должна понимать разговорную просьбу, а также подсказку об инструкциях, чтобы создать соответствующий ответ. В задаче суммирования модель должна правильно предположить разговорной контент, чтобы генерировать резюме. В задаче по контекстуальному смещению мы наблюдаем, что модель даже способна исправить свой собственный вывод, когда предоставляется подсказками. Надежные ответы модели с несколькими задачами с таким сдвигом распределения при вводе из учебных данных демонстрируют адаптивность ее основных инструкций после навыков. Вместо того, чтобы переоценить домен обучения, многозадачный подход к обучению позволяет модели изучать больше универсальных возможностей в понимании инструкций и выполнении, которые лучше передают новый контекст. Мы предоставляем некоторые количественные результаты по невидимым задачам и метке в следующем разделе.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал