

Может ли ИИ объяснить шутку? Не совсем - но это быстро учится
19 июня 2025 г.Авторы:
(1) Arkadiy Saakyan, Колумбийский университет (a.saakyan@cs.columbia.edu);
(2) Шреяс Кулкарни, Колумбийский университет;
(3) Тухин Чакрабарти, Колумбийский университет;
(4) Смаранда Мюресан, Колумбийский университет.
Примечание редактора: это часть 4 из 6 исследований, рассматривая, насколько хорошо крупные модели искусственного интеллекта обрабатывают фигуративный язык. Прочитайте остальное ниже.
Таблица ссылок
- Аннотация и 1. Введение
- 2. Связанная работа
- 3. v-Flute Задача и набор данных
- 3.1 Метафоры и сравнения
- 3.2 идиомы и 3,3 сарказма
- 3.4 Юмор и 3,5 Статистика набора данных
- 4. Эксперименты и 4.1 модели
- 4.2 Автоматические метрики и 4.3 результаты автоматической оценки
- 4.4 Человеческий базовый уровень
- 5. Оценка человека и анализ ошибок
- 5.1 Как модели работают в соответствии с людьми?
- 5.2 Какие ошибки допускают модели? и 5.3 Насколько хорошо оценка объяснения предсказывает человеческое суждение о адекватности?
- 6. Выводы и ссылки
- Статистика набора данных
- B API модели гиперпараметры
- C тонкая настройка гиперпараметров
- D подсказки для LLMS
- E Модель таксономия
- F By-Phenomenon Performance
- G Аннотаторский набор и компенсация
4 эксперименты
Мы эмпирически изучаем, как несколько базовых моделей выполняются по задаче объяснимого визуального въезда. Мы исследуем как готовую, так и произвольную производительность модели.
4.1 модели
Мы выбираем различные модели для нашего исследования (см. Таксономию в Приложении, Рисунок 10). ДляМодели готовых, мы исследуем как открытые, так и обжаренные модели. Для открытых моделей мы выбираем (текущие) современные модели Llava-1.6 (Liu et al., 2024). Llava является одной из самых простых, но одну из самых высокопроизводительных архитектур VLM в настоящее время. В нем используется предварительно проведенная модель большого языка (например, Mistral-7B (Jiang et al., 2023)) и кросс-модальный разъем на языке зрения (например, слой MLP) для выравнивания кодера зрения (например, Clip (Radford et al., 2021))) выходов к языковым моделям. Мы выбираем модели Llava-1.6 в их конфигурациях 7b и 34b (Llava-V1.6-7b и Llava-V1.6-34b соответственно) и называем их Llava-ZS-7B и Llava-ZS-34B. Обе модели были настроены на образцы настройки визуальных инструкций менее 1 м, чтобы выступать в качестве общих ассистентов по языку и зрения. Однако следует отметить, что эти модели в настоящее время не поддерживают несколько выстрелов мультимодальной подсказки.
В дополнение к тестированию с нулевым выстрелом, мы также проверяем эти модели, используя композиционную цепочку, предложенную Mitra et al. (2023). Метод сначала побуждает модель сгенерировать график сцены, а затем использует этот график сцены в другом приглашении, чтобы ответить на соответствующий вопрос. Метод работает с нулевым выстрелом, не требуя точной настройки. Мы называем эти модели Llava-ZS-7B-SG и Llava-ZS-34B-SG для конфигураций 7B и 34B Llava, описанных выше.
Для моделей на основе API мы выбираем три широко доступных современных VLMS: Claude-3 Opus (Claude-3-Opus-20240229) (антроп, 2024), GPT-4 (GPT-4-1106-Vision-Preview) (Openai, 2023) и Geminipro (Gemini-Prosision). Мы называем GPT-4 моделью «учителя», как большинство кандидатов были получены с ним.
Длятонко настроенныйМодели, мы фокусируемся на модели с тонкой настройкой Llava-1.5-7B (Liu et al., 2023a) (код создания для 1.6 модели не доступен в течение времени, когда документ был написан). Чтобы свести к минимуму смещение для одной инструкции, мы настраиваем и оцениваем модели на наборе из 21 обработки инструкции (см. Приложение Таблица 8). Три конфигурации модели протестированы:
• llava-evilКонтрольная точка Llava-V1.5-7b дополнительно настраивается на наборе данных Evil (E-Snlive) для объяснимого визуального въезда (Kayser et al., 2021) преобразовано в формат инструкции. Мы удалили нейтральные экземпляры метки, которые привели к 275 815 учебным экземплярам и 10 897 экземплярам проверки.
• llava-vfэто то же самое контрольно-пропускное значение, которое настраивается на тренировочном наборе V-Flute. Мы также настраиваем модель с белым квадратом вместо изображения VFLUTE (обозначенный −image).
• llava-evil+vfэто то же самое контрольно-пропускной пункт, созданный как на злом, так и на V-Flute.
Все гиперпараметры находятся в Приложении C.
4.2 Автоматические метрики
Подобно предыдущей работе (Chakrabarty et al., 2022), мы используем как классический балл F1, так и скорректированный балл, который учитывает качество объяснения: F1@Explanationscore. Объяснения вычисляют среднее значение между Bertscore (Zhang* et al., 2020) на основе модели Microsoft-Deberta-xlarge-Mnli (He et al., 2021; Williams et al., 2018) и Bleurt (Sellam et al., 2020) на основе Bleurt-20 (Pu et al., 2021). Поскольку наша цель состоит в том, чтобы убедиться, что модели дают ответ по правильным причинам, в идеале мы считаем только прогнозы правильными, когда объяснение также является правильным. Следовательно, мы сообщаем о F1@0 (просто F1 оценка), F1@53 (только прогнозы с оценкой объяснения> 53 считаются правильными) и F1@60. Пороговые значения отбираются на основе оценки качества объяснения человека в разделе 5.3.
4.3 Результаты автоматической оценки
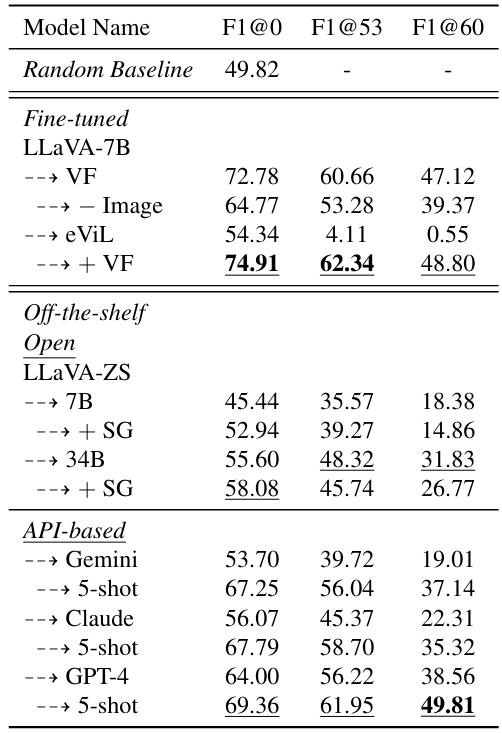
В таблице 3 показаны результаты на основе автоматической оценки. Мы также включаем результаты в соответствии с явлением в Приложении F и снижение производительности при учете оценки объяснений на рисунке 6. Наши результаты информируют следующие идеи:
Точная настройка на V-Flute приводит к лучшей производительности классификации в среднем по наборам данных.Our strongest fine-tuned model (LLaVA-7BeViL+VF) outperforms the best off-the-shelf model (GPT-4-5shot) in terms of the F1@0 score (p < 0.03; all p values reported via paired bootstrap test (Koehn, 2004)), and performs competitively when incorporating the explanations quality with GPT-4 leading slightly (F1@60 of 49.81 vs. 48.80 для лучшей тонкой модели), которая ожидается как GPT-4, является моделью учителя, с которой были созданы большинство кандидатов на объяснение. Добавление набора данных E-VIL немного улучшает производительность по сравнению с точной настройкой на V-Flute. Прекрасная настройка просто на электронном здании улучшается по сравнению с случайной базовой линией; Тем не менее, объяснения низкого качества.
Мы также используем базовую линию только для гипотезы (Poliak et al., 2018), включив модель, настраиваемый в наборе данных V-Flute, но без соответствующего
Изображение (с белым квадратом в качестве входного входа, обозначенного как -жальца). Тонкая настройка в полном наборе данных VFLUTE показывает улучшение более 8 баллов в F1@0 (лучше с p <0,002), что предполагает, что VLMS извлекает выгоду из визуальной информации при работе с фигуративными явлениями и не только полагается на входной текст, чтобы сделать их прогноз.
Открытые модели, настроенные на подготовку к нулевым выстрелуLlava-7b и 34b отстают от Claude 3 и GPT-4 в настройках с нулевым выстрелом. Тем не менее, подсказка графа сцены повышает производительность моделей на основе LLAVA, что позволяет им догнать производительность API с нулевым выстрелом (Gemini и Claude 3). Объяснения, полученные этими моделями, имеют тенденцию чрезмерно сосредоточиться на содержании графика сцены, а не на основных фигуративных явлениях, что, возможно, вызывает снижение показателя объяснения (и, следовательно, в F1@60). Модели API с несколькими выстрелами превосходят модели API с нулевым выстрелом и лучше, чем все конфигурации открытых моделей в F1@0, 53, 60, что указывает на эффективность нескольких выстрелов (недоступно для моделей на основе LLAVA на данный момент).
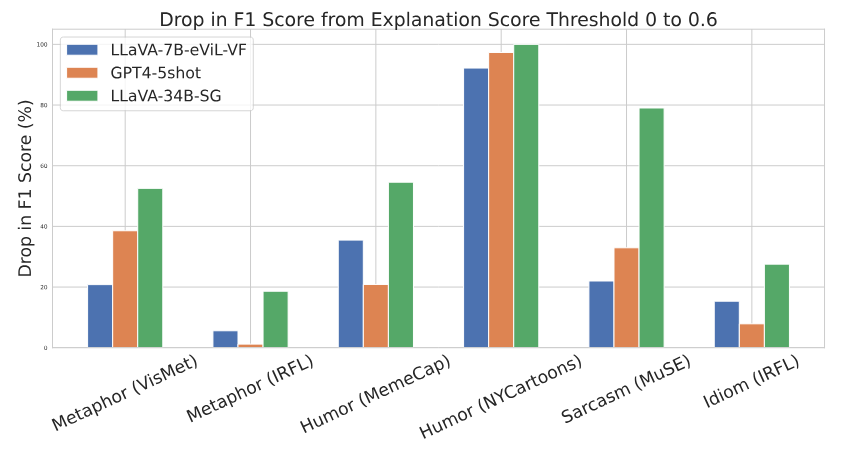
Производительность для моделей уменьшается при учете качества объяснения.Мы планируем относительное процентное снижение между f1@0 и f1@60 для Llava-evil-vf, llava-34bsg и GPT-4-5shot на рисунке 6. Более высокий относительный падение указывает на более высокую сложность генерации правильного объяснения. Для всех моделей мы видим существенное снижение производительности, особенно на сложных явлениях, таких как юмор (Nycartoons). Для подмножествам метафоры (IRFL), юмора (меморя) и идиомы (IRFL) GPT-4 демонстрирует самое низкое относительное снижение производительности, в то время как для метафоры (Haivmet), юмора (Nycartoons) и сарказма (Muse), тонкая настраиваемая модель имеет самое низкое падение.
Мы видим, что процентное падение существенно выше для всех моделей для подмножества Haivmet, а не набора данных IRFL, который содержит метафоры в изображении, а не в тексте.Это говорит о том, что моделям сложнее генерировать правильные объяснения, когда фигуративное значение содержится на изображении, а не в тексте, что указывает на необходимость расширения текущих наборов данных, чтобы включить изображения с фигуративным значением.
4.4 Человеческий базовый уровень
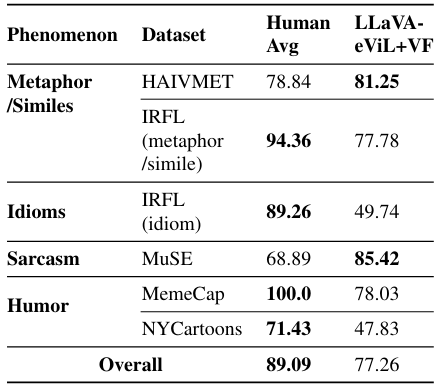
Чтобы выяснить, как люди выполняют задачу, мы нанимаем двух экспертных аннотаторов с формальным образованием в лингвистике. Мы представляем их с 10 примерами экземпляров, а затем просим их завершить 99 случайно отобранных экземпляров тестовых наборов. Мы также оцениваем нашу лучшую модель (см. Таблицу 3) в том же наборе. Результаты показаны в таблице 4. Человеческая производительность довольно сильная, почти достигая 90 F1@0 балла в целом. Человеческая производительность лучше, чем наша самая сильная модель с тонкой моделью (Llava-7b-evil+vf) с p <0,05 для аннотатора 1 и p <0,07 для аннотатора 2. Люди превосходят при интерпретации мемов, причем оба аннотаторов достигают 100% F1. Люди также заметно работают лучше в наборе данных Nycartoons и в подмножестве идиомы задачи. Модель имеет небольшое преимущество в производительности сарказма и подмножествами визуальной метафоры задачи, возможно, из-за сложности этих подмножеств и любых потенциальных ложных корреляций во время точной настройки.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Оригинал