

Создание нерушимого контракта: трубопровод для классификации и ремонта уязвимостей, способствующих искусственным технологиям.
2 июля 2025 г.Таблица ссылок
Аннотация и I. Введение
II Методы
Iii. Результаты
IV Заключение, будущая работа и ссылки
II Методы
A. Наборы данных
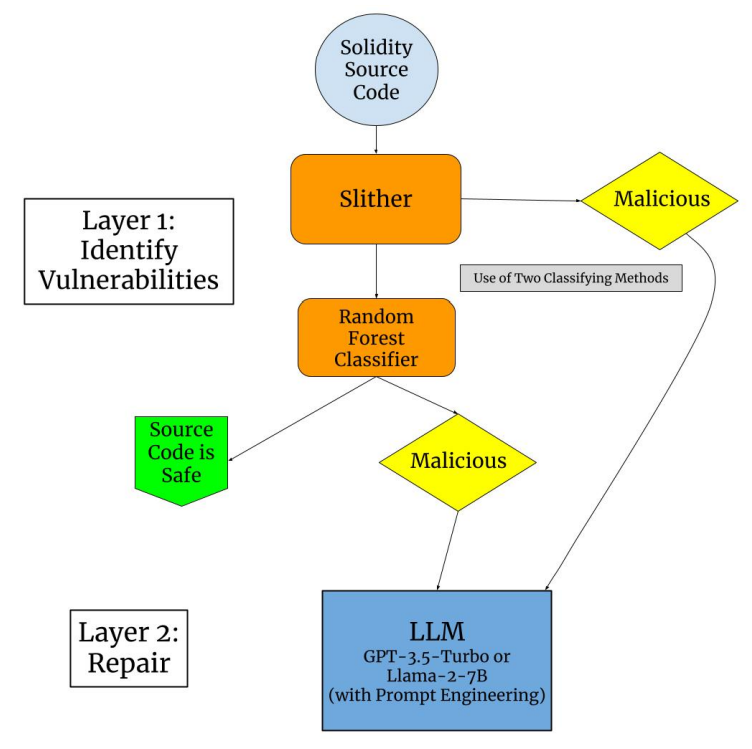
Для достижения высококачественных результатов при обучении нашей структуры с использованием randomForestClassifier и LLMS для классификации и ремонта (рис. 1) необходимо включить несколько важных функций.
Столбец исходного кода («источник контракта») необходим для запуска Slither и LLMS. Однако, поскольку наборы данных последовательно исключали исходный код, алгоритм сети, который использовал столбец «адрес договора», будет необходим для получения исходного кода от Etherscan и Generation (см. Подраздел D.). Чтобы учесть исходный код, который нельзя было скрепить через Etherscan, набор данных (200 000 контрактов) был уменьшен до 2500 строк.
Затем SLITHER был запущен в недавно приобретенном исходном коде (см. Подраздел B.), добавляя столбцы «уязвимость», «уверенность» и «воздействие». Время от времени SLITHER не смог предоставить каких -либо уязвимостей, на общей сложности 474 неудачных контрактов (80% успешная ставка выхода). Чтобы учесть это, набор данных был снова уменьшен до 2000 умных контрактов. Из набора данных 400 были помечены злонамеренными, а 1600 были помечены необработанными. Таблица I визуализирует сегмент окончательного набора данных.
Б. Слайтер
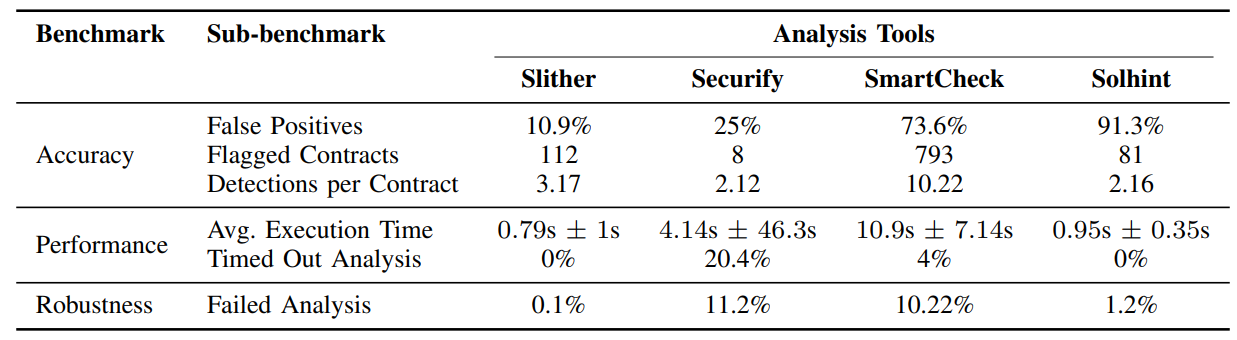
Slither - это статический анализатор кода, который проверяет интеллектуальные контракты на наличие уязвимостей без выполнения контракта. Первоначальный вход Slither исходит из Abstrict Syntax Tree (AST), сгенерированного компилятором Solidity из исходного кода контракта. Смарт -контракт затем упрощается в промежуточное представление под названием Slithir. Это промежуточное представление сравнивается с текущими отраслевыми стандартами и уязвимого вывода. SLITHER возглавляет отрасль в обнаружении уязвимости интеллектуального контракта, опережая других анализаторов статического кода практически в каждой метрике, как показано в таблице II. Это, в сочетании с нашим случайным классификатором леса, обеспечивает высокую точность в обнаружении уязвимых интеллектуальных контрактов.
После импорта и запуска всех 89 базовых детекторов, предоставленных API, мы добавили уязвимости каждого контракта в набор данных в качестве списка имен естественных языков Slither с пустыми списками, обозначающими контракты Slither, которые считаются безопасными.

C. Проблемы с данными и генерация
Когда дело дошло до сбора данных, были столкнулись конкретные проблемы. Наша самая большая проблема, извлечение исходного кода, оказалась сложной задачей. Например, в наборе данных, который был дан байт -кода, мы не увенчались успехом в том, чтобы разместить этот код в анализируемый исходный код, поскольку мы не знали о пределах декомпилятора. Мы также изо всех сил пытались найти дополнительный вредоносный исходный код для обучения модели, так как наш набор данных включал только 150 злонамеренных контрактов. Чтобы преодолеть это, мы внедрили GPT 3,5 Turbo OpenAI для генерации вредоносного исходного кода. Первоначальные попытки были запрещены этическими ограничениями GPT 3.5 (рис. 2). Тем не менее, после Jailbrieking GPT 3.5 с быстрой инженерией [18] GPT 3.5 создаст вредоносный исходный код, который может быть отремонтирован моделью.
Изменчивость набора данных затрудняла генерирование Slight Slenerainability для интеллектуальных контрактов, поэтому использовался подход с пустым шагом. Основной проблемой была 100+ версий, которые все контракты были написаны в сочетании с ограниченной обратной совместимостью солидности, то есть версия 0.4.11 могла работать на компиляторе версии 0.4.26, но не компилятор версии 0.5.0+. Обращение к этому необходимому изменению каждого контракта для чтения «Прочность Pragma ≥ {версия}», создавая пять различных сценариев и запустив каждый сценарий на весь набор данных с одной из пяти следующих версий прочности: 0.4.26, 0.5.17,

0,6,12, 0,7,6, или 0,8,21, с скользкой уязвимости сценариев, которые нельзя было собрать, записанные как нулевые, и те, которые можно было записано с английским названием уязвимости, полученные при анализе возвращенного JSON. Комбинирование этих списков привело к окончательному списку уязвимостей SLITHER для 75% интеллектуальных контрактов, для которых этот метод дал результаты.
Каждый класс детектора включает в себя уверенность и воздействие детектора. После создания пары ключевых значений английского имени каждого детектора и их уверенности плюс воздействие, этот список использовался для создания списков доверия и воздействия для всех уязвимостей для каждого умного контракта.
D. классификатор
Различные модели были реализованы для классификации умного контракта злонамеренностью. В конечном счете, RandomForestClassifier (RFC) обеспечил самую высокую точность после предварительной обработки завершенного набора данных.
RFC не может обучаться на наборе данных, как это обеспечивает патрой, генерация и скользящая обработка из-за обиливания ненужных функций на основе строк. Таким образом, ненужные функции сбрасываются, и для RFC обрабатываются необходимые функции. Например, «уверенность» и «уязвимость» сохраняют более слабую корреляцию с «злонамеренной» по сравнению с «воздействием», поэтому, чтобы избежать свертывания модели, оба отбрасываются. Таким образом, «источник контракта» и «удар» остаются как классифицирующие функции и «вредоносные» как целевой этикетку.
Поскольку все столбцы по -прежнему являются либо строковыми, либо логическими типами данных, RFC по -прежнему не может тренироваться в наборе данных. «Источник контракта» был токенизирован с использованием инструмента CountVectorizer (CV) из библиотеки Sci-Kit-Learn. «Злоупотребление» и «удара» были закодированы в полезные числовые значения путем картирования словарей. Поскольку «удар» содержал более двух возможных результатов, в отличие от «злонамеренных», результаты «удара» были масштабированы с 0-4.
После того, как токенизированные и закодированные столбцы объединяются, числовые предпосылки RFC выполняются.
Затем данные разделяются на расщепление тестирования поезда 0,6-0,4 и рандомизируются до того, как RFC подходит к набору поездов и предсказывает на наборе тестирования. Точность и путаница оцениваются вРезультатыПолем
E. Модели больших языков (LLMS)
1) Создание ламы-2-7B: Мы включили несколько крупных языковых моделей для ремонта интеллектуальных контрактов после того, как они были идентифицированы как злонамеренные с нашими двухслойными рамками. Лучшие результаты пришли из модели Llama-2-7B, которую можно найти на обнимании лица. Эта модель завершила обучение в июле 2023 года. Наш процесс создания состоялся примерно через три недели. Модель Llama-2-7B стала очень популярной благодаря низкому количеству параметров и надежности, что привело к менее интенсивной альтернативе для других LLM в отрасли.
Процесс создания состоялся в Google Colab с использованием чипа T4, который несет 16 ГБ VRAM. Однако сами веса Llama2-7B заполняют этот предел (7b * 2 байт = 14). Это также не включает в себя веса, оптимизаторы или градиенты. Таким образом, чтобы запустить Llama-2-7B и иметь возможность запускать его без ограничений на память на платформе, такой как Google Colab, мы будем использовать параметры-эффективного финиза (PEFT). В частности, мы будем использовать Qlora (эффективное создание квантовых LLMS), используя 4-битную точность вместо нормальной 16-битной точности. Этот процесс квантования позволяет создавать в колабах при одновременном обеспечении адекватной точности модели. Это связано с тем, что при сохранении 4-битной модели мы также сохраняем адаптеры Qlora, которые можно использовать с моделью.
Кроме того, Llama-2-7B является открытым исходным кодом, что означает, что модель доступна для загрузки и использования локально. Таким образом, традиционные проблемы конфиденциальности данных с LLMS являются аннулированными, поскольку все данные обрабатываются на локальной машине, а не на стороннем сервере. Это хорошо подлежит умным контрактам, так как многие заключают соглашения с конфиденциальной информацией и большими суммами денег. Llama-2-7B предоставляет преимущества и точность передового LLM, а также обеспечивает безопасность и универсальность, необходимую для технологии блокчейна.
Модель Llama-2-7B была точно настроена на пятьдесяти умных контрактов, которые когда-то были злонамеренными, а затем отремонтированы, используя подход к обучению. Эти умные контракты были собраны в сборе данных, упомянутых выше. В частности, исходный код был токенизирован и встроен, используя квантование, изложенное ранее. Модель была обучена на более чем 100 этапах, при этом потери тренировок последовательно уменьшались с каждым шагом (как показано на рисунке 3).
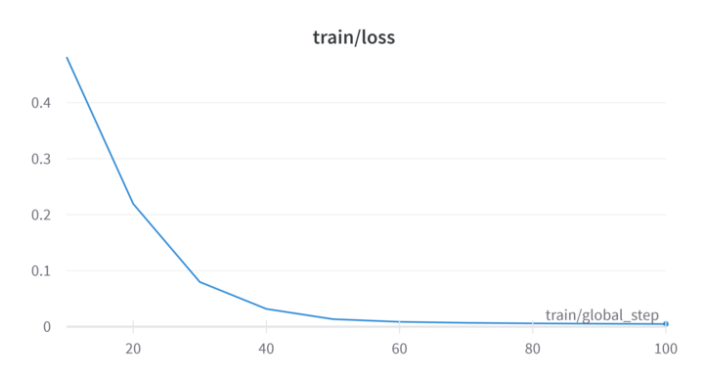
Процесс с точной настройкой контролировал модель понять взаимосвязь между злонамеренным исходным кодом и тем же исходным кодом, который был отремонтирован для эмуляции с любым другим контрактом.
2): Мы также использовали API Openai для использования GPT-3.5-Turbo для ремонта уязвимостей. OpenAI является одним из самых известных имен в отрасли с такими приложениями, как Dall -E и CHATGPT. В частности, в то время как все модели GPT оптимизированы для генерации кода, GPT-3.5-Turbo является лучшей комбинацией производительности и эффективности. Более того, используя «чат -бот», мы смогли использовать быструю инженерию для создания подсказки с наилучшей возможной производительностью. Прямая задача GPT-3.5-Turbo для ремонта вредоносного кода был неудачным. Подобно поколению злонамеренных умных контрактов, GPT-3.5-Turbo нежелание работать со злым исходным кодом (рис. 4).
Таким образом, быстрая инженерия была использована, чтобы обойти эту проблему.
Во -первых, использование слова «вредоносное» необходимо удалить. В то время как мы искали нашу LLM для ремонта вредоносных умных контрактов, вместо этого GPT-3.5 был предложено помочь нам «исправить уязвимые интеллектуальные контракты».
Затем мы использовали методы цепочки мышления, чтобы модель разрабатывала, какие изменения она внесла и почему. Это привело к более точным выводу исходного кода и более уязвимости отремонтирована. Кроме того, это предоставило больше информации для

Пользователь как конкретные уязвимости в злонамеренном интеллектуальном контракте были выделены и объяснены.

В конечном счете, наша подсказка (рис. 5) использовала исходный код Slither и уязвимости для предложения GPT 3.5 Turbo для ремонта интеллектуальных контрактов. В то время как Slither также выводит уровень воздействия и доверие к этим уязвимостям, мы обнаружили, что они включают их в подсказку, что повредит способности модели выводить отремонтированный исходный код или даже исходный код, который может быть составлен. По сути, использование других выходов Slither привело к переоснащению. Эта подсказка также использовалась с моделью Llama-2-7B, изложенной выше, чтобы создать равномерность между выходами. В обеих моделях подсказка позволила создать ремонтный исходный код, а также генерировать детали, которые объясняют любые изменения и дали объяснение.
В заключение мы закончили двумя основными моделями для ремонта исходного кода. Во-первых, лама-2-7B, которая была создана специально для ремонта умных контрактов. Во-вторых, было использование GPT-3,5-Turbo, которое научилось ремонтировать интеллектуальные контракты с помощью быстрого инженера.
Авторы:
(1) Абхинад Джайн, средняя школа Уэстборо, Вестборо, штат Массачусетс, и в равной степени внес свой вклад в эту работу (jain3abhinav@gmail.com);
(2) Эхан Масуд, Средняя школа Сансет, Портленд, Орегон, и в равной степени способствовал этой работе (ehanmasud2006@gmail.com);
(3) Мишель Хан, средняя школа Гранит Бэй, Гранит Бэй, Калифорния (Michellehan2007agt@gmail.com);
(4) Rohan Dhillon, школа Lakeside, Сиэтл, Вашингтон (rohand25@lakesideschool.org);
(5) Sumukh Rao, Bellarmine College College, Сан -Хосе, Калифорния (sumukhsf@gmail.com);
(6) Арья Джоши, Роббинсвилльская средняя школа, Роббинсвилл, Нью -Джерси (arya.joshi@gmail.com);
(7) Салар Чима, Университет Иллинойса, Шампейн, IL (salarwc2@illinois.edu);
(8) Саурав Кумар, Университет Иллинойса, Шампейн, Иллинойс (sauravk4@illinois.edu).
Эта статья есть
Оригинал