
Предвзятость в моделях машинного обучения для обнаружения депрессии
10 июня 2025 г.Таблица ссылок
- Аннотация и введение
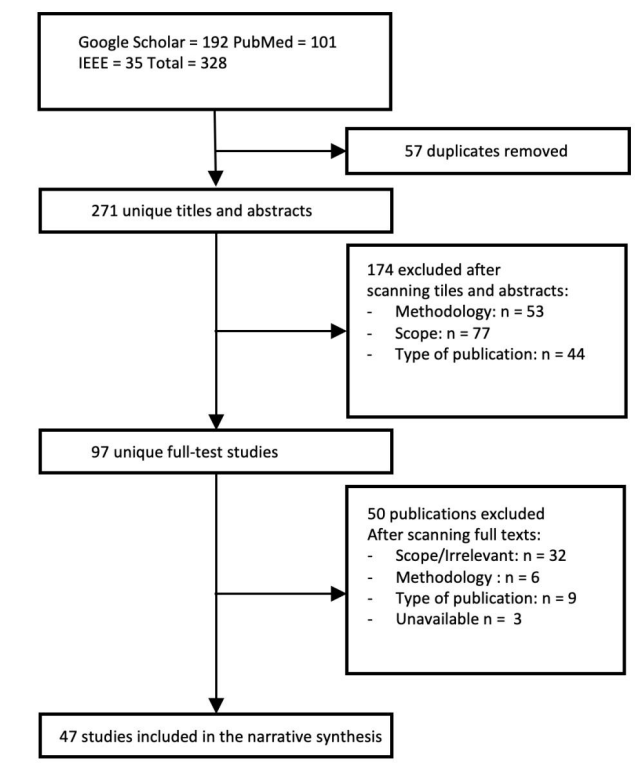
- Методология
- Результаты
- Обсуждение и ссылка
Дискуссия
Эскалация распространенности психических состояний, особенно депрессии, создает значительную глобальную задачу для здоровья. Платформы социальных сетей стали богатыми источниками данных, где люди выражают свои мысли и эмоции, предлагая уникальную возможность для выявления проблем психического здоровья с помощью передовых вычислительных методов. Модели машинного обучения и глубокого обучения обещают анализ этих обширных, неструктурированных данных для определения закономерностей, указывающих на депрессию. Этот систематический обзор был направлен на оценку эффективности этих моделей в обнаружении депрессии в социальных сетях, сосредоточенном на выявлении и анализе предубеждений на протяжении всего жизненного цикла ML.
Сводка ключевых выводов
Наш обзор обнаружил несколько ключевых предубеждений и методологических проблем, которые влияют на надежность и обобщение машинного обучения и моделей глубокого обучения в этой области. Обработки отбора проб появились из -за преобладающей зависимости от конкретных платформ социальных сетей, особенно в Twitter, которая использовалась в 63,8% исследований. Кроме того, большинство исследований были сосредоточены на английском языке и пользователях из конкретных географических регионов, в первую очередь в Соединенных Штатах и Европе. Эти предубеждения ограничивают репрезентативность результатов, поскольку они не отражают разнообразие глобальных пользователей социальных сетей. В предварительной обработке данных во многих исследованиях неадекватно обрабатывались лингвистические нюансы, такие как отрицания и сарказм. Только около 23% исследований явно учитывали обработку негативных слов или отрицаний, которые имеют решающее значение для точного анализа настроений при обнаружении депрессии.
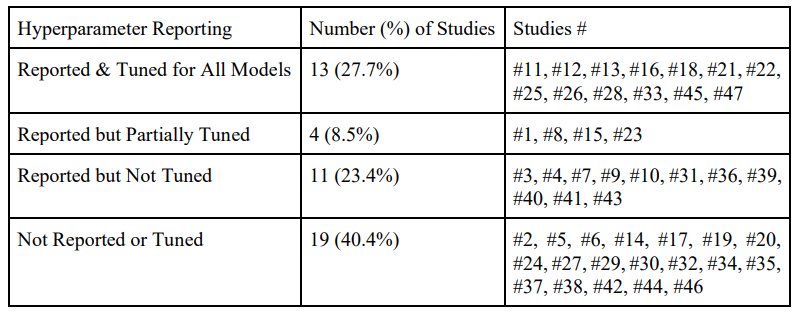
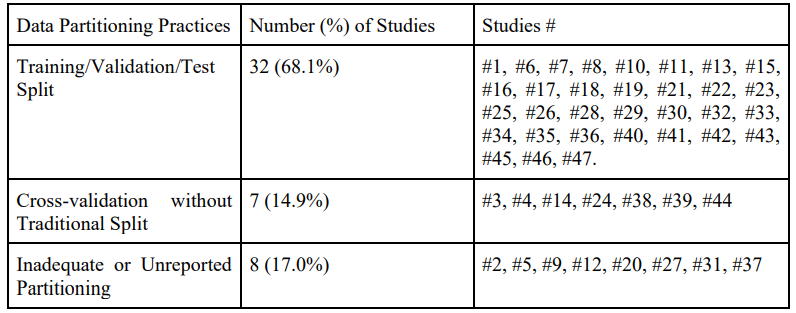
Проблемы разработки модели также были заметными. Наблюдались несовместимые методы настройки гиперпараметров, и только 27,7% исследований должным образом настраивали гиперпараметры для всех моделей. Более того, приблизительно 17% исследований не адекватно разделили свои данные на обучение, валидацию и тестовые наборы. Эти практики могут привести к переоснащению, уменьшая способность моделей обобщать новые данные. Что касается оценки модели, многие исследования в значительной степени основывались на точности как основной метрике оценки без устранения дисбаланса класса, присущих наборам данных по обнаружению депрессии. В то время как около 74,5% исследований использовали метрики, подходящие для несбалансированных данных, такие как точность, отзыв, оценка F1 и Auroc, другие не сделали, возможно, искажали оценку производительности модели. Наконец, несмотря на все исследования, включая раздел ограничений, прозрачность значительно варьировалась, с критическими методологическими деталями, такими как методы разделения данных и настройки гиперпараметра, часто занижаются. Это несоответствие препятствует воспроизводимости и способности полностью оценивать обоснованность результатов.
Сильные стороны и ограничения обзора
Этот систематический обзор выделяется благодаря его всестороннему объему, изучая предубеждения на протяжении всего жизненного цикла ML, от отбора проб до отчетности, при обнаружении депрессии в социальных сетях. Не ограничивая анализ конкретными аспектами, обзор предлагает целостное представление о том, как смещения могут влиять на достоверность модели. Другой силой является структурированный методологический подход, придерживаясь установленных руководящих принципов с четко определенной стратегией поиска и четкими критериями включения. Сосредоточив внимание на исследованиях, опубликованных после 2010 года, отражает последние достижения в области ML и DL для психического здоровья.
Использование установленных инструментов оценки смещения, особенно вероятного, добавляет строгости, систематически оценивая смещение между ключевыми методологическими доменами. Кроме того, подробный процесс извлечения данных обзора способствовал структурированному анализу, что позволило определить модели и предоставлять действенные рекомендации, такие как диверсификация источников данных и повышение прозрачности.
Однако обзор также имеет ограничения. Ограниченное охват базы данных и ограничение только для английского языка могут исключить ценную информацию из неанглийских исследований, что потенциально влияет на обобщение результатов. Основное внимание на недавних исследованиях (после 2010 года) могло бы упускать из виду более ранние влиятельные работы, в то время как неоднородность в дизайне исследований препятствовала прямым сравнениям и исключала количественный метаанализ. Более того, предвзятость публикации может исказить результаты в отношении положительных результатов, и за исключением серой литературы означает, что новые методологии могут быть не полностью захвачены. Наконец, хотя этические соображения были признаны, более глубокое исследование таких вопросов, как конфиденциальность данных и информированное согласие, является оправданным.
Эти ограничения предполагают области для улучшения в будущих исследованиях, такие как расширение базы данных и языкового охвата, включая серую литературу и проведение мета-анализа, где это возможно. Управляя этими областями, будущие исследования могут повысить надежность моделей ML для обнаружения психического здоровья и обеспечить более полное, этическое и глобально значимое понимание этой области.
Последствия для будущих исследований
Для повышения обобщения и применимости машинного обучения и моделей глубокого обучения в обнаружении депрессии в социальных сетях необходимо решать определенные предубеждения. Во-первых, диверсификация источников данных на многочисленных платформах социальных сетей и включение неанглийских языков и недопредставленных регионов улучшит репрезентативность и обобщение. Улучшение методов отбора проб имеет решающее значение. Комбинирование выборки на основе ключевых слов с помощью методов случайной выборки может помочь уменьшить смещение выбора и захватить пользователей, которые могут явно не упомянуть депрессию, но демонстрируют соответствующее поведение. На этапе предварительной обработки данных исследователи должны стандартизировать практики, чтобы явно обрабатывать лингвистические нюансы, такие как отрицания и сарказм, которые жизненно важны для точного анализа настроений. Кроме того, применение методов повторной выборки или повторного взрыва может помочь сбалансировать наборы данных, гарантируя, что оба класса, особенно депрессивный класс меньшинства, адекватно представлены. Должны использоваться расширенные методы обработки естественного языка, которые учитывают лингвистические нюансы, такие как сарказм и контекстные значения.
Последовательная и всеобъемлющая настройка гиперпараметрической настройки во всех моделях имеет важное значение для обеспечения справедливых сравнений и оптимизации производительности модели. Должны быть реализованы надлежащие методы разделения данных, включая использование валидации и наборов тестов, чтобы предотвратить переживание и оценку обобщения модели. При оценке моделей исследователи должны расставлять приоритеты в метрик, которые учитывают дисбаланс класса, такие как точность, отзыв, оценка F1 и Auroc. Эти показатели обеспечивают более сбалансированную оценку эффективности модели и более информативны в контексте обнаружения депрессии, где класс меньшинства представляет основной интерес.
Заключительные замечания
Этот систематический обзор подчеркивает значительные методологические ограничения в текущих исследованиях обнаружения депрессии с помощью анализа социальных сетей с использованием моделей машинного обучения и глубокого обучения. Устранение этих ограничений имеет решающее значение для разработки более точных, надежных и обобщаемых моделей, которые могут эффективно идентифицировать людей, подвергающихся риску депрессии. Будущие исследования должны сосредоточиться на диверсификации источников данных, улучшении методов отбора проб, улучшения предварительной обработки данных и методов разработки моделей, а также использования соответствующих показателей оценки для обеспечения сбалансированных и значимых оценок.
Продвигая эти методологические подходы, исследователи могут внести свой вклад в развитие инструментов обнаружения психического здоровья, которые являются этически обоснованными и эффективными для различных групп населения и платформ. Такие достижения имеют потенциал для облегчения стратегий раннего вмешательства, в конечном итоге улучшив результаты психического здоровья в глобальном масштабе.
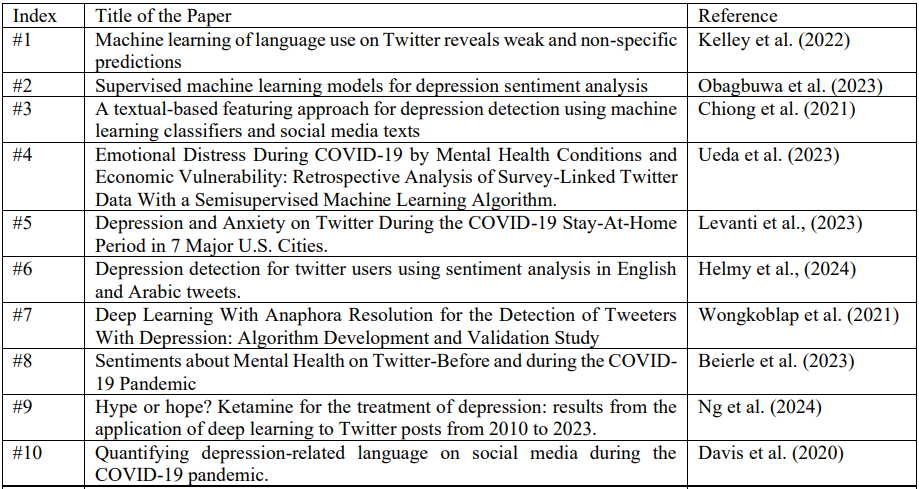
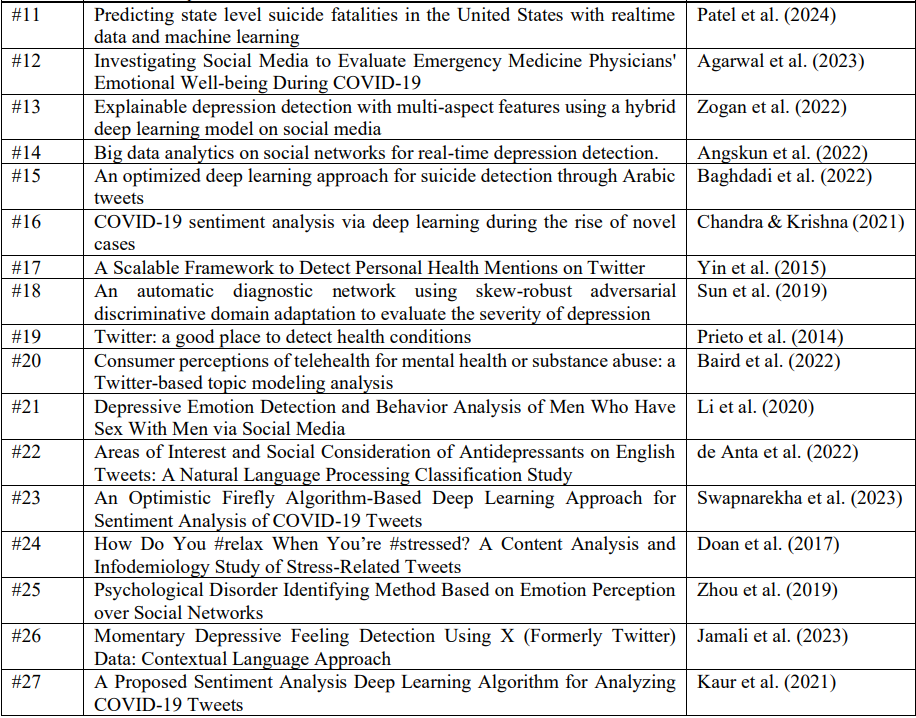
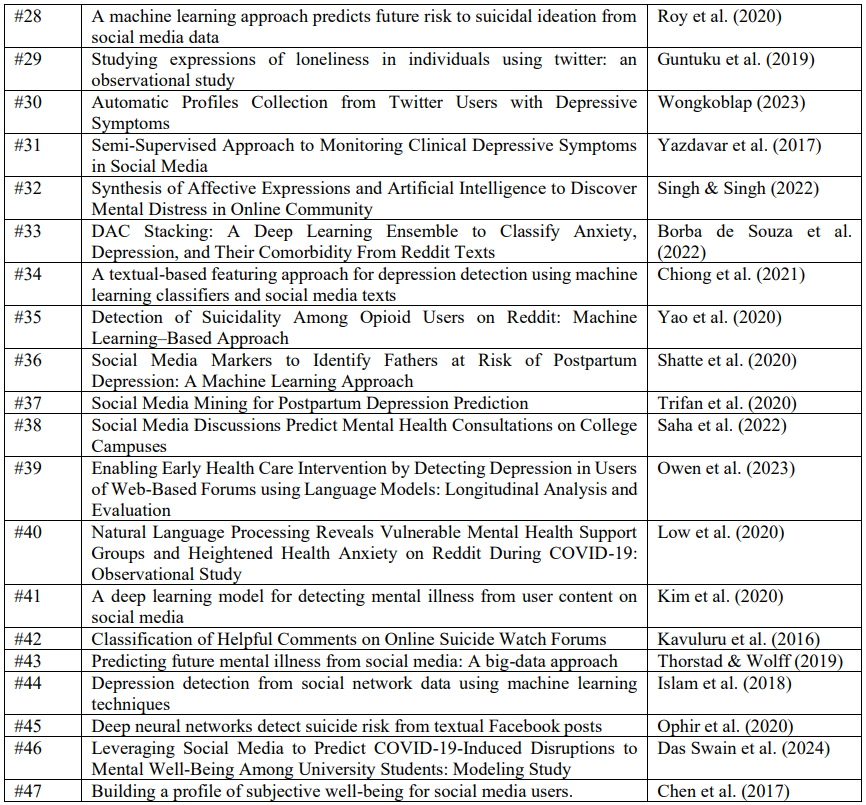
Приложение 1. Обзорные исследования моделей машинного обучения для обнаружения депрессии в социальных сетях
Ссылка:
Agarwal, A.K., Mittal, J., Tran, A., Merchant, R. & Guntuku, S.C. (2023). Исследование социальных сетей для оценки эмоционального благополучия врачей неотложной медицины во время Covid19. Jama Netw Open, 6 (5), E2312708. https://doi.org/10.1001/jamanetworkopen.2023.12708
Angskun, J., Tipprasert, S. & Angskun, T. (2022). Аналитика больших данных в социальных сетях для обнаружения депрессии в реальном времени. J Big Data, 9 (1), 69. https://doi.org/10.1186/S40537-022-00622-2
Багдади, Н. А., Малки, А., Магди Балаха, Х., Абдулазем, Ю., Бадави, М. и Элхоссейни, М. (2022). Оптимизированный подход глубокого обучения для обнаружения самоубийств через арабские твиты. Peerj Comput Sci, 8, E1070. https://doi.org/10.7717/peerj-cs.1070
Baird, A., Xia, Y. & Cheng, Y. (2022). Восприятие потребителям телездравоохранения для психического здоровья или злоупотребления психоактивными веществами: анализ тематических тематических моделирования в Твиттере. Jamia Open, 5 (2), OOAC028. https://doi.org/10.1093/jamiaopen/ooac028
Beierle, F., Pryss, R. & Aizawa, A. (2023). Чувства о психическом здоровье в Твиттере до и во время пандемии Covid-19. Здравоохранение (Базель), 11 (21). https://doi.org/10.3390/healthcare11212893
Бишоп, С. М. (2006). Распознавание и машинное обучение. Спрингер. Издатель Описание http://www.loc.gov/catdir/enhancements/fy0818/20069225222-d.html
Borba de Souza, V., Campos Nobre, J. & Becker, K. (2022). Упаковка DAC: ансамбль глубокого обучения для классификации тревоги, депрессии и их сопутствующей патологии из текстов Reddit. IEEE J Biomed Health Inform, 26 (7), 3303-3311. https://doi.org/10.1109/jbhi.2022.3151589
Calvo, R.A., Milne, D.N., Hussain, M.S. & Christensen, H. (2017). Обработка естественного языка в приложениях психического здоровья с использованием неклинических текстов. Инжиниринг естественного языка, 23 (5), 649-685. https://doi.org/10.1017/S1351324916000383
Chandler, J. & Shapiro, D. (2016). Проведение клинических исследований с использованием удобных образцов краудсорсинга. Annu Rev Clin Psychol, 12, 53-81. https://doi.org/10.1146/annurevclinpsy-021815-093623
Чандра Р. и Кришна А. (2021). Анализ настроений Covid-19 с помощью глубокого обучения во время роста новых случаев. PLOS One, 16 (8), E02555615. https://doi.org/10.1371/journal.pone.0255615
Chawla, N., Japkowicz, N. & Kołcz, A. (2004). Редакция: Специальный выпуск по обучению несбалансированным наборам данных. Sigkdd Explorations, 6, 1-6. https://doi.org/10.1145/1007730.1007733
Chen, L., Gong, T., Kosinski, M., Stillwell, D. & Davidson, R.L. (2017). Создание профиля субъективного благополучия для пользователей социальных сетей. PLOS One, 12 (11), E0187278. https://doi.org/10.1371/journal.pone.0187278
Chiong, R., Budhi, G.S., Dhakal, S. & Chiong, F. (2021). Текстовый на основе подхода к обнаружению депрессии с использованием классификаторов машинного обучения и текстах социальных сетей. Comput Biol Med, 135, 104499. Https://doi.org/10.1016/j.compbiomed.2021.104499
Claesen, M. & De Moor, B. (2015). Поиск гиперпараметра в машинном обучении.
Danet, B. & Herring, S.C. (2007). Многоязычный интернет: язык, культура и общение онлайн. Издательство Оксфордского университета.
Das Swain, V., Ye, J., Ramesh, S.K., Mondal, A., Abowd, G.D. & De Choudhury, M. (2024). Использование социальных сетей для прогнозирования COVID-19, вызванных нарушениями психического благополучия среди студентов университета: модельное исследование. Jmir Form Res, 8, E52316. https://doi.org/10.2196/52316
Дэвис, Б. Д., Макнайт, Д. Э., Теодореску, Д., Куан-Хааас, А., Чунара, Р., Фише, А. и Лизотт, Д. Дж. (2020). Количественная оценка языка, связанного с депрессией в социальных сетях во время пандемии Covid-19. Int J Popul Data Sci, 5 (4), 1716. https://doi.org/10.23889/ijpds.v5i4.1716
De Anta, L., Alvarez-Mon, M.A., Ortega, M.A., Salazar, C., Donat-Vargas, C., Santomavilaclara, J., Martin-Martinez, M., Lahera, G., Gutierrez-Rojas, L., Rodriguez-Jimenez, R., Quintero, J., & Alvarez, M. (202). Области интересов и социального рассмотрения антидепрессантов на английских твитах: исследование классификации обработки естественного языка. J Pers Med, 12 (2). https://doi.org/10.3390/jpm12020155
De Choudhury, M., Counts, S. & Horvitz, E. (2013). Социальные сети как инструмент измерения депрессии в популяциях. Материалы 5 -й ежегодной конференции ACM Web Science,
De Choudhury, M., Gamon, M., Counts, S. & Horvitz, E. (2013). Прогнозирование депрессии через социальные сети. Международная конференция AAAI по веб -и социальным сетям,
Devlin, J., Chang, M.W., Lee, K. & Toutanova, K. (2018). Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка. https://arxiv.org/abs/1810.04805
Doan, S., Ritchart, A., Perry, N., Chaparro, J.D. & Conway, M. (2017). Как вы #Relax, когда вы #строй? Анализ контента и инфодемиология исследования твитов, связанных с стрессом. Jmir Public Health Surveill, 3 (2), E35. https://doi.org/10.2196/publichealth.5939
Fernández, A., García S., Galar, M., Prati, R., Krawczyk, B. & Herrera, F. (2018). Обучение у несбалансированных наборов данных. https://doi.org/10.1007/978-3-319-98074-4
Goodfellow, I., Bengio, Y. & Courville, A. (2016). Глубокое обучение. MIT Press.
Guntuku, S.C., Schneider, R., Pelullo, A., Young, J., Wong, V., Ungar, L., Polsky, D., Volpp, K.G. & Merchant, R. (2019). Изучение выражений одиночества у людей, использующих Twitter: обсервационное исследование. BMJ Open, 9 (11), E030355. https://doi.org/10.1136/bmjopen2019-030355
Guntuku, S.C., Yaden, D.B., Kern, M.L., Ungar, L.H. & Eichstaedt, J.C. (2017). Обнаружение депрессии и психических заболеваний в социальных сетях: интегративный обзор. Современное мнение о психологии, 18, 43-49. https://doi.org/10.1016/j.copsyc.2017.07.005
Hargittai, E. (2015). Больше всегда лучше? Потенциальные предубеждения больших данных, полученные из сайтов социальной сети. Анналы Американской академии политических и социальных наук, 659, 63-76. http://www.jstor.org/stable/24541849
Hastie, T., Friedman, J.H. & Tibshirani, R. (2009). Элементы статистического обучения: интеллектуальный анализ данных, вывод и прогноз. Спрингер.
He, H. & Garcia, E.A. (2009). Обучение у несбалансированных данных. IEEE транзакции по знаниям и разработке данных, 21 (9), 1263-1284. https://doi.org/10.1109/tkde.2008.239
Helmy, A., Nassar, R. & Ramdan, N. (2024). Обнаружение депрессии для пользователей Twitter, используя анализ настроений на английском и арабском твитах. Artif Intell Med, 147, 102716. https://doi.org/10.1016/j.artmed.2023.102716
Ислам, М. Р., Кабир, М. А., Ахмед, А., Камаль, А. Р. М., Ван, Х. и Ульхак, А. (2018). Обнаружение депрессии из данных социальной сети с использованием методов машинного обучения. Health Inf Sci Syst, 6 (1), 8. https://doi.org/10.1007/S13755-018-0046-0
Jamali, A.A., Berger, C. & Spiteri, R.J. (2023). Мгновенное обнаружение депрессивных чувств с использованием данных X (ранее Twitter): подход к контекстуальному языку. Jmir AI, 2, E49531. https://doi.org/10.2196/49531
Japkowicz, N. (2013). Метрики оценки для несбалансированного обучения. Институт инженеров по электротехнике и электронике, Inc. https://doi.org/10.1002/9781118646106
Japkowicz, N. & Stephen, S. (2002). Задача дисбаланса класса: систематическое исследование. Интеллект Данные анал., 6, 429-449. https://doi.org/10.3233/ida-2002-6504
Johnson, K.I., Andersson, G. & Carlbring, P. (2019). Использование Интернета для решения психологических проблем: хорошее, плохое и уродливое. Международный журнал экологических исследований и здравоохранения, 16 (23), 4593. https://doi.org/10.3390/ijerph16234593
Kaur, H., Ahsaan, S. U., Alankar, B. & Chang, V. (2021). Предложенный анализ настроений глубокий алгоритм обучения для анализа твитов Covid-19. Inf Syst Front, 23 (6), 1417-1429. https://doi.org/10.1007/S10796-021-10135-7
Kavuluru, R., Williams, A.G., Ramos-Morales, M., Haye, L., Holaday, T. & Cerel, J. (2016). Классификация полезных комментариев на онлайн -форумах для наблюдения за самоубийством. ACM BCB, 2016, 32-40. https://doi.org/10.1145/2975167.2975170
Kelley, S.W., Mhaonaigh, C.N., Burke, L., Whelan, R. & Gillan, C.M. (2022). Машинное изучение языка в Твиттере раскрывает слабые и неспецифические прогнозы. NPJ Digit Med, 5 (1), 35. https://doi.org/10.1038/S41746-022-00576-y
Кесслер, Р. С. Б., П.; Демлер, О.; Джин, Р.; Уолтерс, Э. Э. (2005). Распространенность пожизненного времени и распределение расстройств DSM-IV в репликации национального обследования сопутствующей патологии. Архивы общей психиатрии, 62 (6), 593-602. https://doi.org/10.1001/archpsyc.62.6.593
Khandelwal, A. & Sawant, S. (2020). Негиберт: подход к обучению передачи для обнаружения отрицания и разрешения объема. Материалы конференции и оценки двенадцатого языка и оценки (LREC 2020),
Kim, J., Lee, J., Park, E. & Han, J. (2020). Модель глубокого обучения для обнаружения психических заболеваний от пользовательского контента в социальных сетях. Sci Rep, 10 (1), 11846.
Levanti, D., Monastero, R.N., Zamani, M., Eichstaedt, J.C., Giorgi, S., Schwartz, H.A. & Meliker, J.R. (2023). Депрессия и беспокойство в Твиттере во время периода проживания в Covid-19 в 7 крупных городах США. AJPM Focus, 2 (1), 100062. https://doi.org/10.1016/j.focus.2022.100062
Li, Y., Cai, M., Qin, S. & Lu, X. (2020). Депрессивное обнаружение эмоций и анализ поведения мужчин, которые занимаются сексом с мужчинами через социальные сети. Передняя психиатрия, 11, 830. https://doi.org/10.3389/fpsyt.2020.00830
Лоу, Д. М., Рамкер, Л., Талзар Т., Турс Дж., Чекки, Г. и Гош, С.С. (2020). Обработка естественного языка выявляет уязвимые группы поддержки психического здоровья и повышенную тревогу здоровья в Reddit во время Covid-19: обсервационное исследование. J Med Internet Res, 22 (10), E22635. https://doi.org/10.2196/22635
Morstatter, F.P., Jürgen; Лю, Хуан; Карли, Кэтлин М. (2013). Достаточно ли хороший образец? Сравнение данных из потокового API в Twitter с 7 -й международной конференцией AAAI по блокам и социальным сетям в Twitter, ICWSM 2013, http://www.scopus.com/inward/record.url?scp=84892704954&partnerid=8yflogxk
Нг, А. (2018). Машинное обучение тоска. https://info.deeplearning.ai/machine-learningyearning-book
NG, Q. X., Lim, Y.L., Ong, C., New, S., Fam, J. & Liew, T.M. (2024). Шумиха или надежда? Кетамин для лечения депрессии: результаты применения глубокого обучения на посты в Твиттере с 2010 по 2023 год. Фронт Психиатрия, 15, 1369727.
Obagbuwa, I.C., Danster, S. & Chibaya, O.C. (2023). Наблюдаемое модели машинного обучения для анализа настроений депрессии. Фронт Artif Intell, 6, 1230649. Https://doi.org/10.3389/frai.2023.1230649
Olteanu, A., Castillo, C., Diaz, F. & Kiciman, E. (2019). Социальные данные: предубеждения, методологические ловушки и этические границы. Передние большие данные, 2, 13. https://doi.org/10.3389/fdata.2019.00013
Офир Ю., Тикочински Р., Астерхан С. С., Сиссо И. и Рейхарт Р. (2020). Глубокие нейронные сети обнаруживают риск самоубийства по текстовым сообщениям в Facebook. Sci Rep, 10 (1), 16685. https://doi.org/10.1038/S41598-020-73917-0
Организация, В. Х. (2020). Депрессия https://www.who.int/news-room/factsheets/detail/depression
Owen, D., Antypas, D., Hassoulas, A., Pardinas, A.F., Espinosa-Anke, L. & Collados, J.C. (2023). Включение раннего вмешательства в области здравоохранения путем обнаружения депрессии у пользователей на веб -форумах с использованием языковых моделей: продольный анализ и оценка. Jmir AI, 2, E41205. https://doi.org/10.2196/41205
Owen, D., Antypas, D., Hassoulas, A., Pardinas, A.F., Espinosa-Anke, L. & Collados, J.C. (2023). Включение раннего вмешательства в области здравоохранения путем обнаружения депрессии у пользователей на веб -форумах с использованием языковых моделей: продольный анализ и оценка. Jmir AI, 2, E41205. https://doi.org/10.2196/41205 с данными и машинным обучением в реальном времени. Npj Ment Health Res, 3 (1), 3. https://doi.org/10.1038/S44184-023-00045-8
Прието В. М., Матос С., Альварес М., Кашеда Ф. и Оливейра Дж. Л. (2014). Твиттер: хорошее место для обнаружения состояний здоровья. PLOS One, 9 (1), E86191. https://doi.org/10.1371/journal.pone.0086191
Probst, P., Boulesteix, A.-L. & Bischl, B. (2019). Настройка: важность гиперпараметров алгоритмов машинного обучения. Журнал исследований машинного обучения, 20 (53), 1-32.
Roy, A., Nikolitch, K., McGinn, R., Jinah, S., Klement, W. & Kaminsky, Z.A. (2020). Подход машинного обучения предсказывает будущий риск для суицидальных представлений из данных в социальных сетях. NPJ Digit Med, 3, 78. https://doi.org/10.1038/S41746-020-0287-6
Rude, S., Gortner, E.-M. & Pennebaker, J. (2004). Использование языка депрессивных и депрессивных студентов колледжа. Познание и эмоция, 18 (8), 1121-1133. https://doi.org/10.1080/02699930441000030
Saha, K., Yousuf, A., Boyd, R.L., Pennebaker, J.W. & De Choudhury, M. (2022). Дискуссии в социальных сетях предсказывают консультации по психическому здоровью в кампусах колледжа. Sci Rep, 12 (1), 123. https://doi.org/10.1038/S41598-021-03423-4
Shatte, A. B.R., Hutchinson, D.M., Fuller-Tyszkiewicz, M. & Teague, S.J. (2020). Маркеры социальных сетей для идентификации отцов, подверженных риску послеродовой депрессии: подход машинного обучения. Киберпсихол поведение Soc Netw, 23 (9), 611-618. https://doi.org/10.1089/cyber.2019.0746
Shatte, A. B.R., Hutchinson, D.M. & Teague, S.J. (2019). Машинное обучение в области психического здоровья: обзор методов и применений. Психологическая медицина, 49 (9), 1426-1448. https://doi.org/10.1017/S0033291719000151
Singh, A. & Singh, J. (2022). Синтез аффективных выражений и искусственного интеллекта, чтобы открыть психическое расстройство в онлайн -сообществе. Int J Ment Health Addict, 1-26. https://doi.org/10.1007/s11469-022-00966-z
Sun, B., Zhang, Y., He, J., Xiao, Y. & Xiao, R. (2019). Автоматическая диагностическая сеть с использованием адаптации дискриминационной доменной домены адаптации с помощью перекоса и роста для оценки тяжести депрессии. Компьютерные методы Программы Biomed, 173, 185-195. https://doi.org/10.1016/j.cmpb.2019.01.006
Pnarekha, H., Nayak, J., Behera, H.S., Dash, P. B. & Pelusi, D. (2023). Оптимистичный подход на основе алгоритма Firefly на основе глубокого обучения для анализа настроений твитов Covid-19. Math Biosci Eng, 20 (2), 2382-2407. https://doi.org/10.3934/mbe.2023112
Thorstad, R. & Wolff, P. (2019). Прогнозирование будущих психических заболеваний от социальных сетей: подход больших данных. Методы поведения, 51 (4), 1586-1600. https://doi.org/10.3758/S13428-019- 01235-Z.
Trifan, A., Semeraro, D., Drake, J., Bukowski, R. & Oliveira, J.L. (2020). Добыча социальных сетей для прогнозирования депрессии послеродового происхождения. Stud Health Technol Inform, 270, 1391-1392. https://doi.org/10.3233/shti200457
Ueda, M., Watanabe, K. & Sueki, H. (2023). Коррекция: эмоциональный стресс во время COVID-19 с помощью психического здоровья и экономической уязвимости: ретроспективный анализ данных, связанных с опросом в Твиттере, с полусущным алгоритмом машинного обучения. J Med Internet Res, 25, E47549. https://doi.org/10.2196/47549
Wolff, R.F., Moons, K.G.M., Riley, R.D., Whiting, P.F., Westwood, M., Collins, G.S., Reitsma, J. B., Kleijnen, J., Mallett, S. & Group, P. (2019). Проблема: инструмент для оценки риска смещения и применимости исследований моделей прогнозирования. Анналы внутренней медицины, 170 (1), 51–58. Https://doi.org/https://doi.org/10.7326/m18-1376
Wolff, R.F., Moons, K.G.M., Riley, R.D., Whiting, P.F., Westwood, M., Collins, G.S., Reitsma, J. B., Kleijnen, J., Mallett, S. & Group, P. (2019). Проблема: инструмент для оценки риска смещения и применимости исследований моделей прогнозирования. Анналы внутренней медицины, 170 (1), 51–58. Https://doi.org/https://doi.org/10.7326/m18-1376
Wongkoblap, A., Vadillo, M.A. & Curcin, V. (2021). Глубокое обучение с разрешением Анафоры для обнаружения твитеров с депрессией: исследование разработки и валидации алгоритма. Jmir Ment Health, 8 (8), E19824. https://doi.org/10.2196/19824
Ян Л. и Шами А. (2020). О оптимизации гиперпараметрических алгоритмов машинного обучения: теория и практика. Нейрокомпьютинг, 415, 295-316. https://doi.org/https://doi.org/10.1016/j.neucom.2020.07.061
Yao, H., Rashidian, S., Dong, X., Duanmu, H., Rosenthal, R.N. & Wang, F. (2020). Обнаружение суицидальности среди пользователей опиоидов на подходе Reddit: машинное обучение. J Med Internet Res, 22 (11), E15293. https://doi.org/10.2196/15293
Yazdavar, A.H., Al-Olimat, H.S., Ebrahimi, M., Bajaj, G., Banerjee, T., Thirunarayan, K., Pathak, J. & Sheth, A. (2017). Полубегающий подход к мониторингу клинических симптомов депрессии в социальных сетях. Proc IEEE ACM Int Conf Adv Soc Netw Anal Min, 2017, 1191-1198. https://doi.org/10.1145/3110025.3123028
Yazdavar, A.H., Mahdavinejad, M.S., Bajaj, G., Romine, W., Sheth, A., Monadjemi, A.H., Thirunarayan, K., Meddar, J.M., Myers, A., Pathak, J. & Hitzler, P. (2020). Мультимодальный анализ психического здоровья в социальных сетях. Plos One, 15 (4). https://doi.org/10.1371/journal.pone.0226248
Инь, З., Фаббри Д., Розенблум, С. Т. и Малин Б. (2015). Масштабируемая структура для обнаружения личных упоминаний о здоровье в Твиттере. J Med Internet Res, 17 (6), E138. https://doi.org/10.2196/jmir.4305
Zhou, T.H., Hu, G.L. & Wang, L. (2019). Психологическое расстройство, определяющее метод, основанный на восприятии эмоций в социальных сетях. Int J Environ Res Public Health, 16 (6). https://doi.org/10.3390/ijerph16060953
Zogan, H., Razzak, I., Wang, X., Jameel, S. & Xu, G. (2022). Объяснимое обнаружение депрессии с помощью многоуровневых функций с использованием гибридной модели глубокого обучения в социальных сетях. World Wide Web, 25 (1), 281-304. https://doi.org/10.1007/S11280-021-00992-2
Авторы:
(1) Ючен Цао, Колледж компьютерных наук Хури, Северо -Восточный университет;
(2) Цзяньглай Дай, факультет EECS, Университет Калифорнии, Беркли;
(3) Чжуньян Ван, Центр наук о данных, Нью -Йоркский университет;
(4) Yeyubei Zhang, Школа инженерии и прикладных наук, Университет Пенсильвании;
(5) Сяоруи Шен, Колледж компьютерных наук Хури, Северо -Восточный университет;
(6) Юнбун Лю, Школа инженерии и прикладных наук, Университет Пенсильвании;
(7) Yexin Tian, Технологический институт Джорджии, Колледж компьютеров.
Эта статья естьДоступно на Arxivпод CC по 4,0 лицензии.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
Categories
- Технологии и IT (25303)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (270)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
