
Помимо прототипа: 15 с трудом заработанные уроки для доставки готовых к производству агентов ИИ
9 июля 2025 г.Руководство для ai-engineers и строителей
Обычно это начинается с нескольких строк Python и ключа API CHATGPT.
Вы добавляете несколько строк контекста, нажимаете, и поражаете, что он вообще отвечает. Тогда вы хотите, чтобы это сделало что -то полезное. Тогда надежно. Тогда без тебя. Именно тогда вы понимаете, что вы больше не просто называете LLM. Вы строите агента.
Я провел последний год, поднимая сценарии и обертки, жонглируя цепями Лэнгкейна, которые больше напоминали карточный дом, чем на системы, и постоянно задаваясь вопросом »,«Как люди на самом деле отправляют этот материал?”
Я преследовал узоры, которые выглядели элегантно в теории, но рухнул момент, когда появились реальные пользователи. Я построил агентов, которые отлично работали в ноутбуке и впечатляюще провалились в производстве. Я продолжал думать о следующем репо, следующем инструменте, следующая структура решит все это.
Это не так.
Что мне помогло, так это замедление, отбрасывая вещи и обращали внимание на то, что на самом деле работало под нагрузкой, а не то, что выглядело умно на LinkedIn.Это руководство представляет собой дистилляцию этой с трудом заработанной ясностиПолем Если вы прошли через подобные проблемы, это написано для вас.
Думайте об этом как о прагматическом руководстве по переходу от оберток API и цепочек к стабильным, управляемым, масштабируемым системам ИИ.
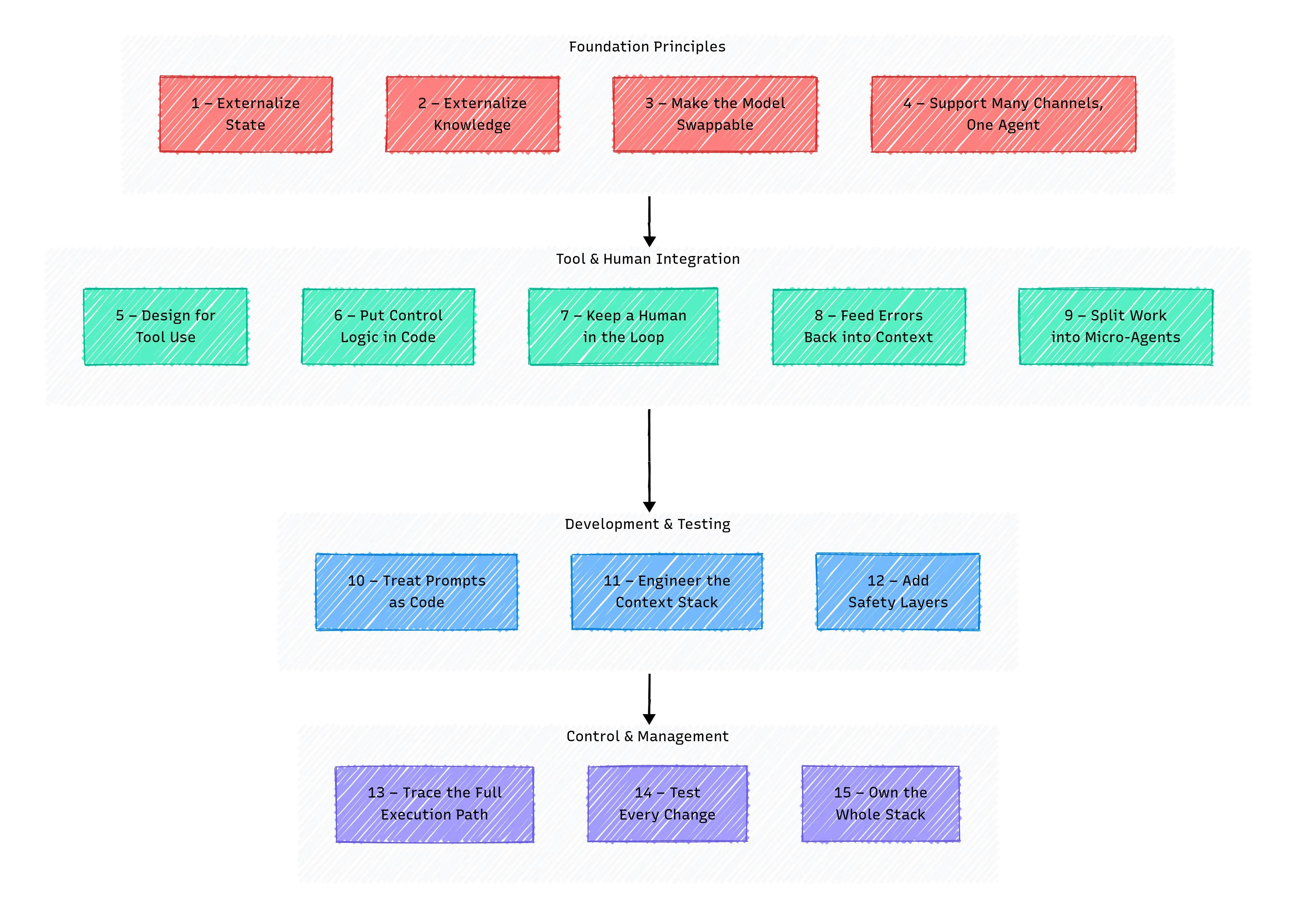
Часть 1 - Получите фундамент правильно
Ранние прототипы агента часто собираются быстро: несколько функций, некоторые подсказки и вуаля, это работает.
Вы можете спросить: «Если это работает, зачем усложнять вещи?»
Сначала все кажется стабильным: агент отвечает, запускает код и ведет себя так, как и ожидалось. Но в тот момент, когда вы поменяете модель, перезапустите систему или добавляете новый интерфейс, все сломается. Агент становится непредсказуемым, нестабильным и болью для отладки.
Обычно проблема не в логике или подсказках; это глубже: Плохое управление памятью, жесткие значения, отсутствие устойчивости сеанса или жесткая точка входа.
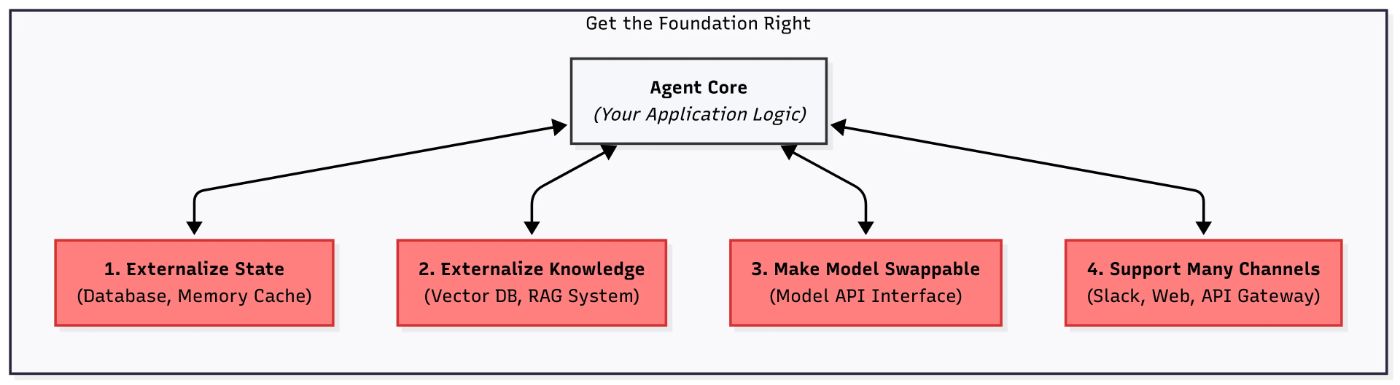
Этот раздел охватывает четыре ключевых принципа, которые помогут вам создать фонд Sock Solid, базу, где ваш агент может надежно выращивать и масштабировать.
1 - Внезо.
Проблема:
- Вы не можете возобновитьЕсли агент прерывается, вылетает, время от времени, что угодно. Он должен подобрать именно то, где он остановился.
- Воспроизводимость:Вы хотите воспроизвести то, что произошло для тестирования и отладки.
- Бонусный вызов: Рано или поздно вы захотите запустить части агента параллельно, например, сравнение параметров средней конвертации или логики ветвления (управление памятью-это отдельная тема, которую мы скоро рассмотрим.)
Решение: Переместите все состояние за пределами агента, в базу данных, кэш, уровень хранения или даже простой файл JSON.
Ваш контрольный список:
- Агент начинается с любого шага, используя толькоsession_idи внешнее состояние (например, сохранено в дБ или JSON).
- Вы можете прервать и перезапустить агента в любое время (даже после изменений кода), не теряя прогресса и не нарушая поведение.
- Состояние полностью сериализуется без потери функциональности.
- Одно и то же состояние может быть подарен на несколько экземпляров агентов, работающих параллельно во время разговора.
2 - Экскурсные знания
Проблема: LLM на самом деле не помнят. Даже на одном сеансе они могут забыть то, что вы им сказали, смешивают этапы разговора, потерять ветку или начать «заполнять» детали, которых там не было. Конечно, окна контекста становятся больше (токены 8K, 16K, 128K), но остаются проблемы:
- Модель фокусируется на начале и конец, теряя важные средние детали.
- Больше токенов стоят больше денег.
- Лимит все еще существует: трансформаторы работают с самопринятым при сложности O (N²), поэтому бесконечный контекст невозможно.
Это ударяется лучше, когда:
- Разговоры длинные
- Документы большие
- Инструкции сложны
Решение: Отдельная «рабочая память» от «хранения», как в классических компьютерах. Ваш агент должен обрабатывать внешнюю память: хранение, получение, суммирование и обновление знаний за пределами самой модели.
Общие подходы:
- Буфер памяти: хранит последние k -сообщения. Быстрый прототип, но теряет более старую информацию и не масштабируется.
- Суммизация памяти: Сжатие истории больше подходит в контексте. Сохраняет токены, но рискует искажения и потерей нюансов.
- Тряпка (поколение поиска-аугментирования): получает знания из внешних баз данных. Масштабируемый, свежий и проверенный, но более сложный и чувствительный к задержке.
- Графики знаний: Структурированные связи между фактами и сущностями. Элегантный и объясненный, но сложный и высокий барьер для входа.
Ваш контрольный список:
- Вся история разговоров хранится вне подсказки и доступна.
- Источники знаний регистрируются и многоразовые.
- История может расти на неопределенный срок, не попадая в пределы окна в контексте.
3 - Сделайте модель сменой
Проблема: LLMS развивается быстро: OpenAI, Google, Anpropic и другие постоянно обновляют свои модели. Как инженеры, мы хотим быстро использовать эти улучшения. Ваш агент должен легко переключаться между моделями, будь то для лучшей производительности или более низкой стоимости.
Решение:
- Используйтеmodel_idПараметр в конфигурациях или переменных среды, чтобы указать, какую модель использовать.
- СтроитьАбстрактные интерфейсыили классы обертки, которые общаются с моделями через унифицированный API.
- Необязательно, примените уровень промежуточного программного обеспечения с осторожностью (фреймворки поставляются с компромиссами).
Контрольный список:
- Изменение модели не нарушает ваш код и не влияет на другие компоненты, такие как память, оркестровка или инструменты.
- Добавление новой модели означает просто обновление конфигурации и, при необходимости, добавление простого слоя адаптера.
- Переключение моделей быстрое и беспрепятственное - в идеале поддерживая любую модель или, по крайней мере, легко переключаться в модельном семействе.
4 - один агент, много каналов
Проблема: Даже если ваш агент начинает с одного интерфейса (скажем, пользовательским интерфейсом), пользователи скоро захотят взаимодействовать: Slack, WhatsApp, SMS, возможно, даже CLI для отладки. Без планирования этого вы рискуете фрагментированной, труднодоступной системой.
Решение: Создайте унифицированный контракт ввода, API или универсальный интерфейс, в который подают все каналы. Держите логику для конкретной канала отдельно от ядра вашего агента.
Контрольный список:
- Агент работает через CLI, API, пользовательский интерфейс или любой другой интерфейс
- Все входные данные проводят через одну конечную точку, анализатор или схему
- Каждый интерфейс использует один и тот же входной формат
- Ни одна бизнес -логика не живет внутри какого -либо адаптера канала
- Добавление новых каналов означает просто написание адаптера - без изменений в коде основного агента
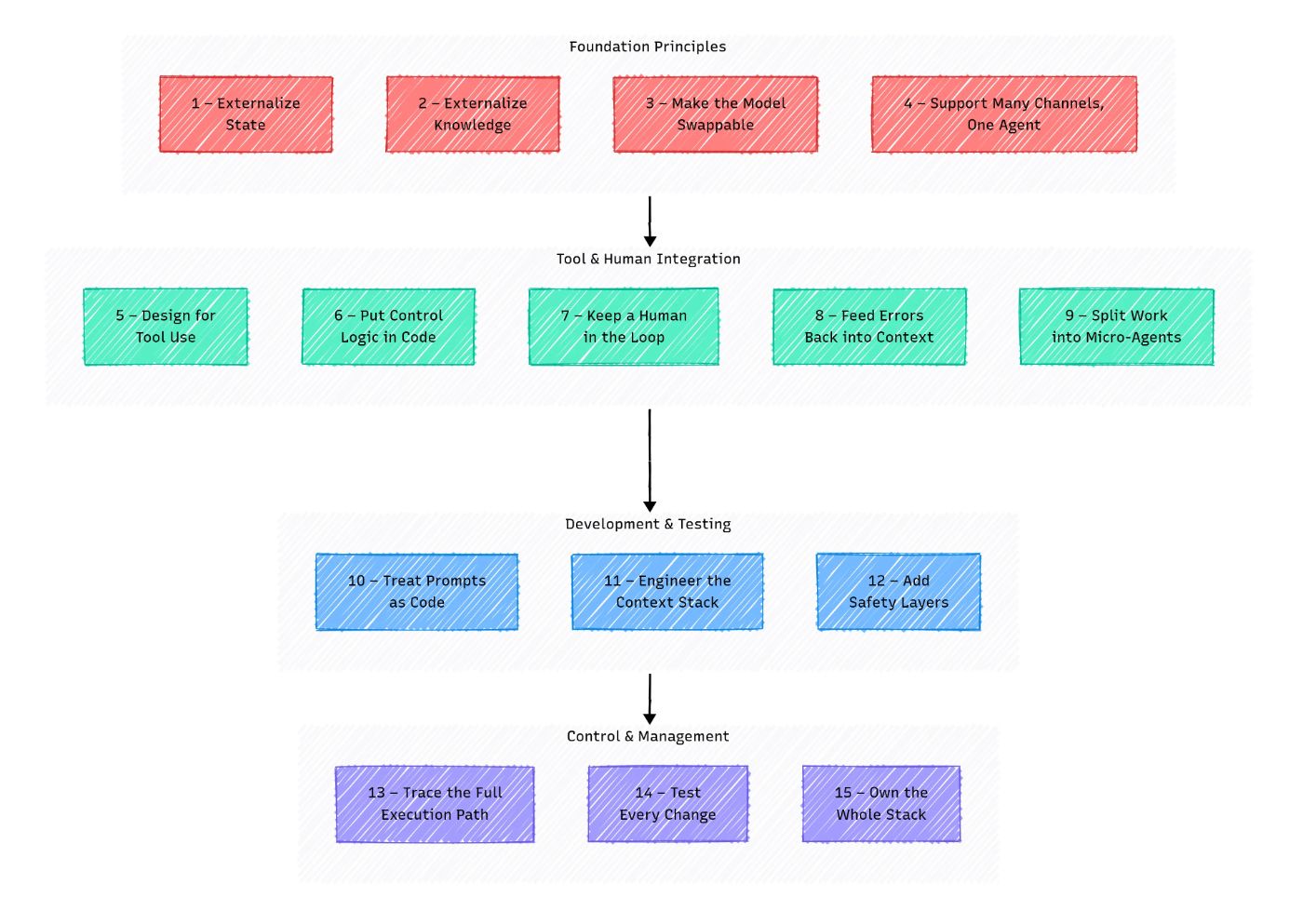
Часть 2 - переходите за пределы режима чат -бота
В то время как есть только одна задача, все просто, как в посты влиятельных лиц ИИ. Но как только вы добавите инструменты, логику принятия решений и несколько этапов, агент превращается в беспорядок.
Он теряет отслеживание, не знает, что делать с ошибками, забывает назвать правильный инструмент, и вы снова остались в одиночестве с журналами, где «ну, там, кажется, там написано».
Чтобы избежать этого, агенту нужна четкая поведенческая модель: что он делает, какие инструменты у него есть, кто принимает решения, как люди вмешиваются и что делать, когда что -то идет не так.
Этот раздел охватывает пять ключевых принципов, которые помогут вам вывести вашего агента за пределы простого чата, создавая последовательную поведенческую модель, которая может надежно использовать инструменты, управлять ошибками и выполнять сложные задачи.
5 - Дизайн для использования инструмента
Проблема: Это может показаться очевидным, но многие агенты по -прежнему полагаются на «простые подсказки + необработанные выводы LLM». Это все равно, что пытаться починить автомобильный двигатель, случайным образом поворачивая болты. Когда LLM возвращают простой текст, который мы затем пытаемся проанализировать с помощью режима или струнных методов, вы сталкиваетесь с несколькими проблемами:
- Бриттлис: Крошечное изменение в формулировке или порядок фразы может сломать ваш анализ, создавая постоянную гонку вооружений между вашим кодом и непредсказуемостью модели.
- Двусмысленность: Естественный язык расплывчат. «Позвони Джону Смиту». Какой Джон Смит? Какой номер?
- Сложность обслуживания: Код диапазона запутывается и трудно отлаживать. Каждый новый агент «навык» означает написание большего количества правил анализа.
- Ограниченные возможности: Трудно надежно вызвать несколько инструментов или пройти сложные структуры данных с помощью простого текста.
Решение: Пусть модель вернет JSON (или другой структурированный формат) и позвольте вашей системе обрабатывать выполнение. Это означает, что LLMS интерпретируют намерения пользователя и решаютчтоделать, и ваш код позаботится окакЭто происходит, выполняя правильную функцию через четко определенную интерфейс.
Большинство поставщиков (OpenAI, Google, Anpropic и т. Д.) Сейчас поддерживаютфункция вызоваилиструктурированный выход:
- Вы определяете свои инструменты как схемы JSON с помощью имени, описания и параметров. Описания являются ключевыми, потому что модель полагается на них.
- Каждый раз, когда вы называете модель, вы предоставляете ей эти схемы инструментов вместе с подсказкой.
- Модель возвращает JSON Указание: (1) Функция для вызова, (2) параметры в соответствии со схемой
- Ваш код проверяет JSON и вызывает правильную функцию с этими параметрами.
- Необязательно, вывод функции можно вернуть в модель для окончательного генерации ответов.
Важный: Описания инструментов являются частью подсказки. Если они неясны, модель может выбрать неправильный инструмент. Что, если ваша модель не поддерживает вызов функций, или вы хотите избежать этого?
Попросите модель производить выход JSON с помощью быстрого разработки и проверить ее такими библиотеками, как Pydantic. Это работает хорошо, но требует тщательного форматирования и обработки ошибок.
Контрольный список:
- Ответы строго структурированы (например, JSON)
- Инструментальные интерфейсы определены с помощью схем (схема JSON или Pydantic)
- Вывод проверен до выполнения
- Ошибки в формате не сбивают сбой системы (изящная обработка ошибок)
- LLM решаеткоторыйФункция для вызова, кодовые ручкиисполнение
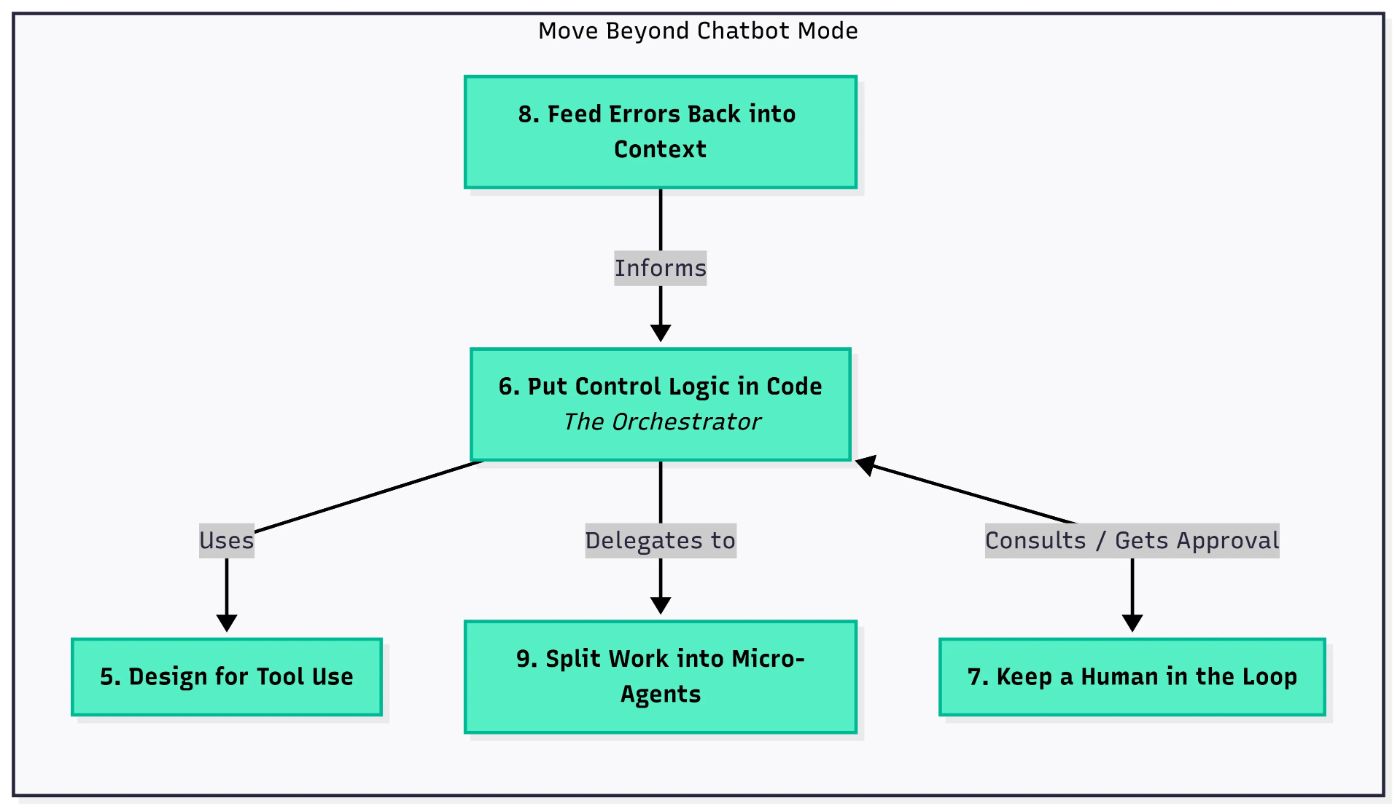
6 - Поместите логику управления в код
Проблема:Большинство агентов сегодня ведут себя как чат -боты: пользователь что -то говорит, отвечает агент. Это схема пинг-понга; Просто и знакомо, но глубоко ограничивает.
С этой настройкой ваш агент не может:
- Действовать самостоятельно без приглашения пользователя
- Выполнять задачи параллельно
- Планируйте и последовательность нескольких шагов
- Повторяйте неудачные шаги разумно
- Работать на заднем плане
Это становится реактивным, а не проактивным.Вы действительно хотите агент, который думает как планировщик: Тот, который смотрит на предстоящую работу, выясняет, что делать дальше, и продвигается вперед, не дожидаясь, когда их косу.
Это означает, что ваш агент должен иметь возможность:
- Принять инициативу
- Цепь несколько шагов вместе
- Восстановиться от неудачи
- Переключаться между задачами
- Продолжайте работать, даже когда никто не смотрит
Решение:Переместите поток управления из LLM в вашу систему. Модель все еще может помочь (например, решить, какой шаг будет дальше), но фактическая последовательность, повторная передача и логика выполнения должны жить в коде.
Это переворачивает вашу работу изоперативная инженериякДизайн системыПолем Модель становится одной частью более широкой архитектуры, а не марионеточным мастером.
Давайте разберем три способа, которыми команды приближаются к этому смене.
1. конечный штат Машина (FSM)
- Что это такое:Разбейте задачу на отдельные состояния с определенными переходами.
- Роль LLM:Действует внутри штата или помогает выбрать следующий.
- Лучше всего для:Линейные, предсказуемые потоки.
- Плюсы:Простые, стабильные, легко отлаживать.
- Инструменты:Stateflow, Yaml Configs, классический шаблон состояния в коде.
2. направленный ациклический график (DAG)
- Что это такое:Представляют задачи как график - узлы - это действия, края являются зависимостями.
- Роль LLM:Действует как узел или помогает генерировать график.
- Лучше всего для:Ветвящие потоки, параллельные шаги.
- Плюсы:Гибкий, визуальный, хорош для частичной рецидивы.
- Инструменты:Langgraph, Trellis, Llmcompiler, или DIY с графиком Lib.
3. Планировщик + исполнитель
- Что это такое:Один агент (или модель) строит план; Другие выполняют это шаг за шагом.
- Роль LLM:Большие планы модели, маленькие (или код) выполнить.
- Лучше всего для:Модульные системы, длинные цепочки рассуждений.
- Плюсы:Разделение проблем, масштабируемые, экономически эффективные.
- Инструменты:Планируйте и выполняйте планирование и собственный планировщик/архитектуру планировщика/исполнителя.
Почему это важно
- Вы получаете контроль над поведением агента
- Вы можете повторить, отлаживать и проверить отдельные шаги
- Вы можете масштабировать детали независимо или обмениваться моделями
- Вы делаете вещи видимыми и прослеживаемыми, а не непрозрачными и волшебными
Контрольный список
- Агент следует за структурой FSM, DAG или планировщиков
- LLM предлагает действия, но не управляет потоком
- Вы можете визуализировать прогрессию задач
- Обработка ошибок выпекается в логику потока
7 - Держите человека в цикле
Проблема:Даже с инструментами, потоком управления и структурированными выходами, полная автономия все еще остается мифом. Llms нетпониматьчто они делают. Они не могут быть привлечены к ответственности. И в реальном мире они сделают неправильный звонок (рано или поздно).
Когда агенты действуют в одиночку, вы рискуете:
- Необратимые ошибки:Удаление записей, обмена неверными сообщениями, отправка денег на мертвый кошелек.
- Проблемы соблюдения: нарушение политики, права или основных социальных норм.
- Странное поведение:Пропустить шаги, галлюцинирующие действия или просто делать то, что ни один человек никогда не будет.
- Сломан доверие: Пользователи не будут полагаться на что -то, что кажется вне контроля.
- Нет ответственности: Когда он сломается, неясно, что пошло не так или владеет беспорядком.
Решение: принесите людей в петлю (Hitl)
Относитесь к человеку как к пилоту, а не к запасному. Спроектировать вашу систему напаузаВпросить, илимаршрутрешения человеку, когда это необходимо. Не все должно быть полностью автоматическим. Иногда, «ты уверен?» это самая ценная функция, которую вы можете построить.
Способы включения людей
- Одобрение ворота:Критические или необратимые действия (например, отправка, удаление, публикация) требует явного подтверждения человека.
- Эскалационные пути:Когда уверенность модели низкая или ситуация неоднозначна, маршрут к человеку для обзора.
- Интерактивная коррекция:Позвольте пользователям просмотреть и редактировать ответы модели до их отправки.
- Петли обратной связи:Захватить человеческую обратную связь, чтобы улучшить поведение агента и обучать модели с течением времени (подкрепление обучения от обратной связи человека).
- Варианты переопределения:Позвольте людям прерывать, переопределить или перенаправить рабочий процесс агента.
Контрольный список
- Чувствительные действия подтверждаются человеком перед исполнением
- Есть четкий путь к эскалации сложных или рискованных решений
- Пользователи могут редактировать или отклонить выходы агента, прежде чем они станут окончательными
- Журналы и решения можно пересмотреть для аудита и отладки
- Агент объясняетпочемуэто приняло решение (насколько это возможно)
8 - ошибки подачи обратно в контекст
Проблема:Большинство систем сбой или останавливаются, когда происходит ошибка. Для автономного агента это тупик. Но слепо игнорировать ошибки или галлюцинация вокруг них так же плохо.
Что может пойти не так:
- Бриттли:Любая сбой, будь то внешняя ошибка инструмента или неожиданный выход LLM, может сломать весь процесс.
- Неэффективность:Частые перезагрузки и ручное исправление отработает время и ресурсы.
- Нет обучения:Без осознания своих собственных ошибок агент не может улучшить или адаптироваться.
- Галлюцинации:Ошибки, не сданные, могут привести к вводящим в заблуждение или сфабрикованным ответам.
Решение:Обработать ошибки как часть контекста агента. Включите их в подсказки или память, чтобы агент мог попробовать самокоррекцию и адаптировать его поведение.
Как это работает:
- Понять ошибку:Четко захватить сообщения об ошибках или причины сбоя.
- Самокоррекция:Агент размышляет об ошибке и пытается исправить ее путем: (1) обнаружения и диагностики проблемы, (2) корректируя параметры, перефразирование запросов или инструментов переключения, (3) повторение действия с изменениями.
- Контекст ошибки имеет значение:Подробная информация об ошибках (например, инструкции или объяснения) помогает агенту лучше исправить себя. Даже простые журналы ошибок улучшают производительность.
- Обучение самокоррекции:Включите примеры ошибки в модельную подготовку для повышения устойчивости.
- Человеческая эскалация:Если самокоррекция неоднократно терпит неудачу, обостряется к человеку (см. Принцип 7).
Контрольный список:
- Ошибки из предыдущих шагов сохраняются и подаются в контекст
- ЛОГИКА RETRY реализуется с адаптивными изменениями
- Повторные сбои запускают запасение в обзор человека или вмешательство
9-Разделенная работа на микроагенты
Проблема:Чем больше и беспорядочно задача, тем дольше контекстное окно и тем более вероятно, что LLM будет потерять сюжет. Сложные рабочие процессы с десятками шагов проталкивают модель мимо своей сладкой точки, что приводит к путанице, впустую токенам и более низкой точностью.
Решение:Разделите и победите. ИспользоватьМаленькие, специально построенные агенты, каждый несет ответственность за одну четко определенную работу. Оркестратор верхнего уровня лишает их вместе.
Почему работают маленькие, сфокусированные агенты
- Управляемый контекст: Более короткие окна держат модель резким.
- Четкое право собственности:Один агент, одна задача, нулевая двусмысленность.
- Более высокая надежность:Более простые потоки означают меньше мест, чтобы потеряться.
- Более легкое тестирование:Вы можете испытать единичный тест на каждого агента в изоляции.
- Более быстрая отладка:Когда что -то сломается, вы точно знаете, где искать.
Там нет волшебной формулы для разделения логики; Это отчасти искусство, частичный опыт, и граница будет продолжать меняться по мере улучшения моделей. Хорошее эмпирическое правило: если вы не можете описать работу агента в одном или двух предложениях, это, вероятно, слишком много.
Контрольный список
- Общий рабочий процесс-это серия звонков микроагрирования.
- Каждый агент может быть перезапущен и протестирован сам по себе.
- Вы можете объяснить определение агента в 1–2 предложениях.
Часть 3 - стабилизировать поведение
Большинство ошибок агента не отображаются как красные ошибки; Они появляются в виде странных выходов. Пропущенная инструкция. Половинный формат. Что -то, что почти работает ... пока это не так.
Это потому, что LLM не читают умы. Они читают токены.
То, как вы создаете запросы, то, что вы передаете в контекст, и как вы пишете подсказки, все это напрямую формирует результат. И любая ошибка в этой настройке становится невидимой ошибкой, ожидающей появления позже. Это то, что заставляет агента инженерность чувствовать себя нестабильным:Если вы не будете осторожны, каждое взаимодействие медленно уходит с курсаПолем
Этот раздел о затяжении этой петли обратной связи. Подсказки не являются односторонними строками, это код. Контекст не волшебство, это состояние, которым вы управляете явно. И ясность не является обязательной, это разница между повторяющимся поведением и творческой чушь.
10 - рассматривать подсказки как код
Проблема:Слишком много проектов обрабатывают подсказки, такие как одноразовые строки: жестко кодируются в файлах Python, разбросаны по кодовой базе или смутно сброшены в представление. Когда ваш агент становится все более сложным, эта лень становится дорогой:
- Трудно найти, обновить или даже понять, что делает каждая подсказка
- Нет контроля версий - нет способа отслеживать то, что изменилось, когда или почему
- Оптимизация становится догадкой: без петель обратной связи, нет A/B -тестирования
- И отладка проблемы, связанного с быстрым, похоже на попытку исправить ошибку в комментарии
Решение:Подсказки естькод. Они определяют поведение. Так что управляйте ими, как вы бы сделали настоящий код:
- Разделить ихИз вашей логики: хранить их в
txtВ.mdВ.yamlВ.jsonили используйте шаблонные двигатели, такие как Jinja2 или Baml - Версия ихс вашим репо (как функции)
- Проверьте их: (1) Ответы на единицу тестирования для формата, ключевых слов, достоверности JSON, (2) запустить эвалы по поводу быстрых изменений, (3) Используйте LLM-AS-A-a-a-gudge или эвристический балл для измерения производительности
Бонус:Обратите внимание на подсказки, такие как обзоры кода. Если изменение может повлиять на выходное поведение, оно заслуживает второго набора глаз.
Контрольный список:
- Подсказки живут вне вашего кода (и явно названы)
- Они версии и трудны
- Они тестируются или оцениваются
- Они проходят обзор, когда это имеет значение
11 - Инженер стек контекста
Проблема:Мы уже занялись забывчивостью LLM, разгрузив память и разделить агенты по заданию. Но все еще есть более глубокая задача:какМы форматируем и доставляем информацию в модель.
Большинство настроек просто бросают кучу роли: контент -сообщения в подсказку и называют это днем. Это работает ... пока это не произойдет. Эти стандартные форматы часто:
- Сжигать токены на избыточных метаданных
- Борьба за представление цепочек инструментов, состояний или нескольких типов знаний
- Несомненно руководствуйте моделью в сложных потоках
И все же, мы все еще ожидаем, что модель «просто разобралась». Это не инженерия. Это вибрации.
Решение: разработать контекст.
Относитесь к всему входному пакету как к тщательно разработанному интерфейсу, потому что это именно то, что есть.
Вот как:
- Владеть полным стеком: Контролируйте, что попадает, как это заказано, и где это появляется. Все, от системных инструкций до извлеченных документов до записей памяти, должно быть преднамеренным.
- Выходить за рамки формата чата: Построить богаче, более плотные форматы. Блоки в стиле XML, компактные схемы, сжатые трассировки инструментов, даже секции разметки для ясности.
- Думайте целостно: Context = все, что видит модель: приглашение, состояние задачи, предыдущие решения, журналы инструментов, инструкции, даже предыдущие выходы. Это не только «история диалога».
Это становится особенно важным, если вы оптимизируете:
- Информационная плотность:упаковка больше смысла в меньшее количество токенов
- Эффективность экономии:Высокая производительность при низком размере контекста
- Безопасность:контроль и помечение того, что видит модель
- Утилизация ошибок:Явно сигнализируя о краях, известных вопросах или инструкциях по отступлению
Итог:Подсказка - это лишь половина битвы.Контекст инженерияэто вторая половина. И если вы еще не делаете этого, вы будете, как только ваш агент вырастет.
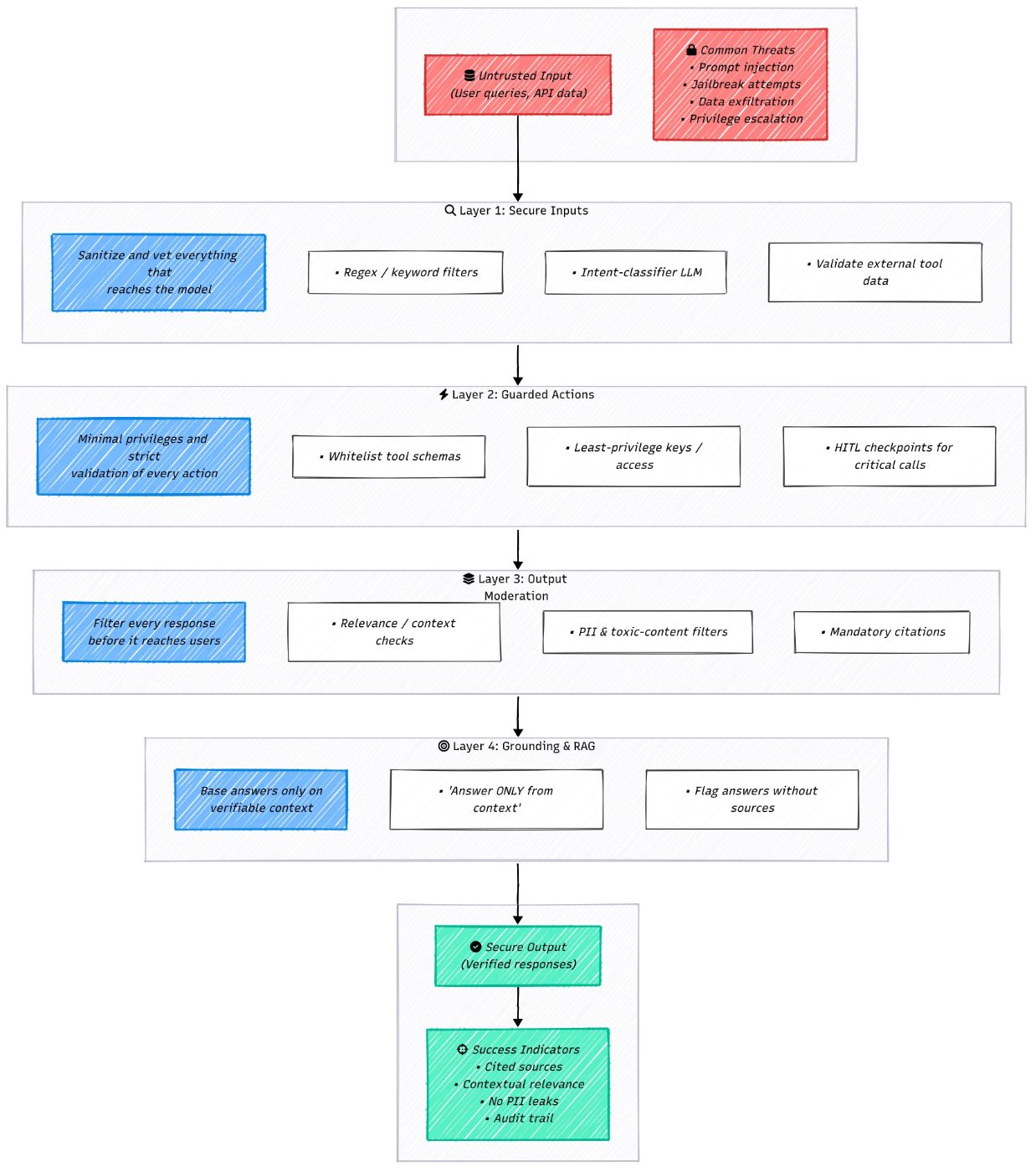
12 - Добавить слои безопасности
Даже с твердыми подсказками, памятью и потоком управления, агент все еще может уходить с рельсов. Думайте об этом принципе как о страховом полисе против худших сценариев:
- Оперативная инъекция:Пользователи (или другие системы) проникают в инструкции, которые захватывают агента.
- Утечки чувствительных данных:Модель выпускает PII или корпоративные секреты.
- Токсичное или злонамеренное содержание:Нежелательная ненавистная речь, спам или запрещенные материалы.
- Галлюцинации:уверенно, но ложные ответы.
- Действия вне положения: Агент «становится креативным» и делает то, что никогда не должен делать.
Ни один исправление не покрывает все это. Тебе нужноЗащита в глубине: Несколько гарантий, которые увлекаются проблемами на каждом этапе цикла запроса/ответа.
Быстрый контрольный список
- Проверка ввода пользователянаходится на месте (джейлбрейк, фразы, проверка намерений).
- Для фактических задач ответыНеобходимо ссылаться на контекст тряпкиПолем
- Подсказка явно говорит модели придерживаться полученных фактов.
- Выходной фильтрБлоки PII или запрещенный контент.
- Ответы включают цитату/ссылку на источник.
- Агент и инструменты следуютнаименьшая привилегияПолем
- Критические действия проходят черезХитлодобрение или мониторинг.
Обратитесь в эти слои как стандартные DevOps: войдите их, протестируйте их и не сможете безопасно. Вот как вы не даете «автономному» агенту стать неконтролируемой ответственностью.
Часть 4 - Держите его работать под нагрузкой
В производстве неудачи редко случаются одновременно, и часто вы не замечаете их сразу же, иногда совсем нет.
Этот раздел посвящен созданию инженерной дисциплины для постоянного контроля вашего агента, обеспечивающего плавное управление.От журналов и трассировки до автоматизированных тестов, эти практики делают поведение вашего агента ясным и надежным, независимо от того, активно ли вы наблюдаете или сосредоточены на создании следующего прорываПолем

13 - Прослеживайте полный путь исполнения
Проблема: Агенты неизбежно будут вести себя по величине во время разработки, обновлений или даже нормальной работы. Отладка этих проблем может потреблять бесчисленные часы, пытаясь воспроизводить ошибки и точности. Если вы уже реализовали ключевые принципы, такие как сохранение состояния вне и укрепления ошибок в контексте, вы впереди. Но независимо от того, планирование эффективной отладки с самого начала спасает вас серьезные головные боли позже.
Решение: Войдите по всему путешествию от запроса пользователя на каждом этапе процесса принятия решения и действий агента. Индивидуальных журналов компонентов недостаточно; Вам нужно сквозное отслеживание, охватывающее каждую деталь.
Почему это важно:
- Отладка: Быстро определить, где и почему все пошло не так.
- Аналитика: Найдите узкие места и возможности улучшения.
- Оценка качества: Измерить, как изменения влияют на поведение.
- Воспроизводимость: Воссоздайте любую сессию точно.
- Аудит: Поддерживать полную запись агентских решений и действий.
Минимальные данные для захвата
- Вход: Запрос пользователя и параметры из предыдущих шагов.
- Агентное государство: Ключевые переменные перед каждым шагом.
- Быстрый: Полное подсказку, отправленное в LLM (системные инструкции, история, контекст).
- Выход LLM: Необработанный ответ перед обработкой.
- Инструментальный звонок: Имя инструмента и параметры.
- Результат инструмента: Tool output or error.
- Агентное решение: Следующие шаги или ответы.
- Метаданные: Время, информация о модели, затраты, код и оперативные версии.
Используйте существующие инструменты отслеживания, где это возможно: Лэнгсмит, Ариз, Вес и смещения, OpenElemetry и т. Д. Но сначала убедитесь, что у вас есть основы (см. Принцип 15).
Контрольный список:
- Все шаги зарегистрировались с полной детализацией.
- Журналы связаны
session_idиstep_idПолем - Интерфейс, чтобы просмотреть цепочки полных вызовов.
- Способность полностью воспроизводить любую подсказку в любой момент.
14 - Проверьте каждое изменение
Проблема: К настоящему времени ваш агент может чувствовать себя готовым к запуску: он работает, может быть, даже как именно вы хотели. Но как вы можете быть уверены, что он будет продолжать работать после обновлений? Изменения в коде, наборах данных, базовых моделях или подсказках могут молча разбить существующую логику или ухудшение производительности. Традиционные методы тестирования не охватывают все причуды LLM:
- Модель дрифта: Производительность снижается со временем без изменений кода из -за модели или сдвигов данных
- Быстрое хрупкость: Небольшие настройки подсказки могут вызвать большие изменения выходных данных
- Недотерминизм: LLM часто дают разные ответы на один и тот же вход, усложняя тесты точных матчей
- Трудные ошибки: Даже при фиксированных входах ошибки могут быть трудно отслеживать
- Эффект бабочки: изменяет каскад непредсказуемо в разных системах
- Галлюцинациии другие риски, специфичные для LLM
Решение: Принять тщательную многослойную стратегию тестирования, объединяющая классические программные тесты с проверкой качества, ориентированной на LLM:
- Многоуровневое тестирование: Модульные тесты для функций/подсказок, интеграционных тестов и полных сквозных сценариев
- Сосредоточьтесь на качество выходов LLM: Актуальность, когерентность, точность, стиль и безопасность
- Используйте золотые наборы данныхс ожидаемыми результатами или приемлемыми диапазонами результатов для проверки регрессии
- Автоматизируют тестыи интегрировать их в трубопроводы CI/CD
- Привлекать людейДля критических или сложных оценок (человек в петле)
- Итеративно проверить и уточнить подсказкиПеред развертыванием
- Проверка на разных уровнях: Компоненты, подсказки, цепочки/агенты и полные рабочие процессы
Контрольный список:
- Логика модульная и тщательно протестируется индивидуально и в комбинации
- Качество вывода оценивается на сравнительные данные
- Тесты охватывают общие случаи, кромки, сбои и злонамеренные входы
- Надежность в отношении шумных или состязательных входов обеспечена
- Все изменения проходят автоматические тесты и контролируются в производстве для обнаружения незамеченных регрессий
15 - владеть всем стеком
Этот принцип связывает все вместе, это мета-правила, которая проходит через все остальные.
Сегодня существует бесчисленное множество инструментов и рамок для выполнения практически любой задачи, которая отлично подходит для скорости и простоты прототипирования, но это также ловушка. Слишком много полагаться на фронтальные абстракции часто означает жертвоприношение гибкости, контроля, а иногда и за безопасность.
Это особенно важно для развития агента, где вам нужно управлять:
- Присущая непредсказуемости LLMS
- Сложная логика вокруг переходов и самокоррекции
- Потребность в вашей системе адаптироваться и развиваться без переписывания основных задач
Фреймворки часто инвертируют управление: Они определяют, как должен вести себя ваш агент. Это может ускорить прототипирование, но усложнять долгосрочную разработку для управления и настройки.
Многие принципы, которые вы видели, могут быть реализованы с помощью готовых инструментов. Но иногда создание основной логики явно требует аналогичных усилий и дает вам гораздо лучшую прозрачность, управление и адаптивность.
С другой стороны, полное обычавое и переписывание всего с нуля-чрезмерно инженерная и одинаково рискованная.
КлючбалансПолем Как инженер, вы сознательно решаете, когда опираться на рамки, а когда взять на себя полный контроль, полностью понимая связанные с этим компромиссы.
Помнить: Инструментальный ландшафт ИИ все еще быстро развивается. Многие текущие инструменты были построены до укрепления стандартов. Завтра они могут устареть - но архитектурный выбор, который вы делаете сейчас, будет оставаться гораздо дольше.
Заключение
Создание агента LLM - это больше не просто вызов API. Речь идет о разработке системы, которая может обрабатывать реальную грязь: ошибки, состояние, контекстные ограничения, неожиданные входные данные и развивающиеся требования.
15 принципов, которые мы рассмотрели, не являются теорией, это проверенные в бою уроки из траншей. Они помогут вам превратить хрупкие сценарии в стабильные, масштабируемые и поддерживаемые агенты, которые не разбивают момент, когда появляются реальные пользователи.
Каждый принцип заслуживает рассмотрения, чтобы увидеть, подходит ли он вашему проекту. В конце концов, это ваш проект, ваши цели и ваше творение. Но помните: LLM мощный, но это всего лишь одна часть сложной системы. Ваша работа как инженера состоит в том, чтобы владеть процессом, управлять сложностью и поддерживать все это плавно.
Если вы заберут одну вещь, пусть это будет:замедлить, строить солидные основы и планировать на долгое хаул. Потому что это единственный способ пойти от «Ух ты, это ответило!» «Да, это продолжает работать».
Сохраняйте итерацию, тестирование и обучение. И не забывайте, что люди в петле не являются запасными, они поддерживают вашего агента заземленным и эффективным.
Это не конец. Это только начало строительных агентов, которые на самом деле доставляют.
Изо всех сил пытаетесь вырастить свою аудиторию как технический профессионал?
Техническая аудитория ускоритель-это новостной рассылку для создателей технологий, серьезно касаясь выращивания своей аудитории. Вы получите проверенные рамки, шаблоны и тактику, стоящие за моими 30 -метровыми впечатлениями (и подсчетом).
https://techaudienceaccelerator.substack.com/embed?source=post_page-------E58139D80299-----------------------------------------------------
Оригинал