

Бенчмаркинг LLM восприимчивость к генерации уязвимого кода с помощью инверсии модели с несколькими выстрелами
29 июля 2025 г.Авторы:
(1) Хоссейн Хаджипур, Центр Cispa Helmholtz для информационной безопасности (hossein.hajipour@cispa.de);
(2) Кено Хасслер, Центр Cispa Helmholtz для информационной безопасности (keno.hassler@cispa.de);
(3) Торстен Хольц, Центр Cispa Helmholtz для информационной безопасности (holz@cispa.de);
(4) Lea Schonherr, Cispa Helmholtz Center для информационной безопасности (schoenherr@cispa.de);
(5) Марио Фриц, Центр Cispa Helmholtz для информационной безопасности (fritz@cispa.de).
Таблица ссылок
Аннотация и I. Введение
II Связанная работа
Iii. Технический фон
IV Систематическое обнаружение уязвимости безопасности моделей генерации кодов
V. Эксперименты
VI Дискуссия
VII. Заключение, подтверждение и ссылки
Приложение
A. Подробности моделей языка кода
B. Поиск уязвимостей безопасности в GitHub Copilot
C. Другие базовые линии с использованием CHATGPT
D. Влияние различных числа нескольких примеров
E. Эффективность в создании конкретных уязвимостей для C -кодов
F. Результаты уязвимости безопасности после дедупликации нечеткого кода
G. Подробные результаты передачи сгенерированных небезопасных подсказок
H. Подробная информация о генерации набора данных небезопасных подсказок
I. Подробные результаты оценки кодельмов с использованием набора данных небезопасного
J. эффект температуры отбора проб
K. Эффективность схемы инверсии модели при восстановлении уязвимых кодов
L. Качественные примеры, сгенерированные CodeGen и CHATGPT
М. Качественные примеры, сгенерированные GitHub Copilot
Абстрактный- Языковые модели (LLMS) для автоматического генерации кода достигли прорывов в нескольких задачах по программированию. Их достижения в области проблем программирования на уровне конкуренции сделали их важной опорой для парного программирования A-ассистента, а такие инструменты, как GitHub Copilot, появились в рамках ежедневного рабочего процесса программирования, используемых миллионами разработчиков. Данные обучения для этих моделей обычно собираются из Интернета (например, из репозитории с открытым исходным кодом) и, вероятно, содержат неисправности и уязвимости безопасности. Эти несаснационные данные обучения могут привести к тому, что языковые модели изучают эти уязвимости и распространять их во время процедуры генерации кода. Несмотря на то, что эти модели были широко оцениваются на предмет их способности производить функционально правильные программы, остается отсутствие комплексных исследований и контрольных показателей, посвященных аспектам безопасности этих моделей.
В этой работе мы предлагаем метод систематического изучения вопросов безопасности моделей языка кода для оценки их восприимчивости к созданию уязвимого кода. С этой целью мы вводим первый подход к автоматическому поиску сгенерированного кода, который содержит уязвимости в моделях генерации кодов черного ящика. Чтобы достичь этого, мы представляем подход к приблизительному инверсии моделей генерации кодов черного ящика на основе нескольких выстрелов. Мы оцениваем эффективность нашего подхода, изучая модели языка кода в создании слабых сторон безопасности высокого риска. Кроме того, мы устанавливаем коллекцию разнообразных небезопасных подсказок для различных сценариев уязвимости с использованием нашего метода. Этот набор данных образует эталон для оценки и сравнения слабых сторон в моделях языка кода.
I. Введение
Большие языковые модели представляют собой значительный прогресс в текущих разработках глубокого обучения. При увеличении размера их обучающая способность позволяет им применяться к широкому диапазону задач, таких как перевод текста [1], [2] и суммирование [3], [2], чат -боты, такие как CHATGPT [4], а также для задач по созданию кода и пониманию кода [5], [6], [7], [8]. Выдающимся примером является Github Copilot [9], программист AI Pair, основанный на Codex Openai [5], [10], который уже используется более чем миллионами разработчиков [11]. CHATGPT [4], Codex [5] и открытые модели, такие как Code Llama [12], Codegen [6] и Incoder [7], обучены крупномасштабному корпусу данных естественного языка и кода и обеспечивают мощную и легкую генерацию кода. Учитывая текстовую подсказку, описывающую желаемую функцию и заголовок функции (первые несколько строк желаемого кода), эти модели генерируют подходящий код на различных языках программирования и автоматически завершают код на основе предоставленного пользователем
контекст описание. Эти модели могут значительно повысить производительность разработчика программного обеспечения. Например, согласно GitHub, разработчики, которые используют GitHub Copilot, реализуют желаемые программы на 55 % быстрее [11], и почти 40 % кода, написанного программистами, которые используют Copilot, генерируются моделью [9].
Как и любая другая модель глубокого обучения, большие языковые модели, такие как CHATGPT, Codex, Code Llama и Codegen, демонстрируют нежелательное поведение в некоторых случаях из -за присущих собственных свойств самой модели и огромного количества несанированных данных обучения [13], [14]. Фактически, эти модели обучаются немодифицированному исходному коду, размещенному на GitHub. В то время как модель обучена, она также изучает стили кодирования данных обучающих данных и, даже более важные, - дураки, которые могут привести к уязвимости, связанной с безопасностью [15], [16]. Pearce et al. [15] показали, что незначительные изменения в текстовой подсказке (то есть входные данные модели) могут привести к ошибкам программного обеспечения, которые могут привести к повреждению потенциального вреда, если сгенерированный код используется неизменным. Авторы используют модифицированные подсказки вручную и не предоставляют способ автоматически найти уязвимости моделей генерации кода.
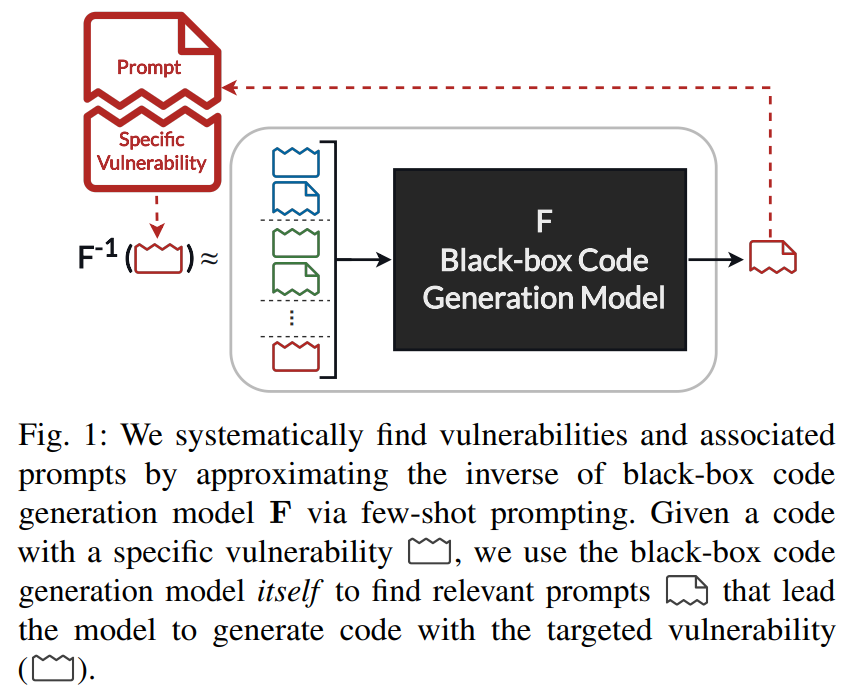
В этой работе мы предлагаем автоматизированный подход для проверки потенциала моделей кода в создании уязвимых кодов и оценки безопасности сгенерированной кода модели. Для Arxiv: 2302.04012V2 [CS.CR] 23 октября 2023 г. мы предлагаем автоматический подход к поиску подсказок, который систематически запускает генерацию кодов, содержащих конкретную уязвимость и позволяет изучить поведение моделей в больших масштабах, которые можно легко расширить на новый тип уязвимостей. Более конкретно, мы формулируем проблему поиска набора подсказок, которые заставляют модели потенциально генерировать уязвимые коды в качестве задачи инверсии. Наша цель состоит в том, чтобы иметь приближение обратной целевой модели, которая может генерировать подсказки, которые могут привести к целевой модели генерировать код с определенной уязвимостью. Тем не менее, неясно, как можно получить обратное в настройке черного ящика. Чтобы решить эту проблему, мы предлагаем подход для сформулирования инверсии, используя саму модель и меньшую подсказку (примеры в контексте) [1], которая недавно продемонстрировала удивительную способность обобщать новые задачи. Несколько подсказков содержит несколько примеров (входной и ожидаемый выход) конкретной задачи для обучения предварительно обученной модели для генерации желаемого вывода. В этой работе мы используем несколько выстрелов, чтобы направлять целевую модель черного ящика, чтобы действовать как собственное приближение. В частности, мы направляем модель на создание подсказок, которые будут генерировать код, содержащий конкретную уязвимость, предоставляя несколько примеров уязвимых кодов и их соответствующих подсказок.
Мы используем это приближение для создания подсказок, которые потенциально приводят модели к созданию кодов с конкретными уязвимостями и выявляют их проблемы уязвимости безопасности. Рисунок 1 Обзор нашего подхода к инверсии модели черного ящика. В наших экспериментах мы показываем, что эти сгенерированные подсказки передаются по разным моделям, и, в отличие от предыдущей работы, наши подсказки могут быть автоматически генерированы для целевых уязвимостей. Используя это доказательство, мы используем наш подход для создания набора небезопасных подсказок с использованием современных моделей кода. Эти подсказки образуют эталон для оценки и сравнения различных моделей в создании кодов с недостатками безопасности.
Таким образом, мы вносим следующие ключевые вклады в этой статье:
Мы предлагаем подход для тестирования потенциала модели в создании уязвимого кода. Мы достигаем этого, приближаясь к инверсии целевой модели черного ящика с помощью нескольких выстрелов.
Наш подход обнаружил разнообразный набор небезопасных подсказок, ведущих современные модели генерации кодов для создания более 2K Python и C-кодов с конкретными уязвимостями.
Мы предлагаем набор данных разнообразных небезопасных подсказок для оценки и сравнения восприимчивости кодовых моделей в создании уязвимых кодов. Эти подсказки были автоматически сгенерированы путем применения нашего подхода к оценке проблем безопасности в современных моделях.
С публикацией этой работы мы выпустим наш подход и сгенерировали набор данных в качестве инструмента с открытым исходным кодом, который можно использовать для оценки безопасности моделей генерации кодов Black-Box. Этот инструмент может быть легко распространен на недавно обнаруженные потенциальные уязвимости безопасности.
Эта статья есть
Оригинал