

За кулисами самостоятельного ведения языковой модели в масштабе
13 июня 2025 г.Крупные языковые модели (LLMS) везде, от повседневных приложений до передовых инструментов. Использовать их легко. Но что, если вам нужно запустить собственную модель? Независимо от того, работаете ли вы с тонкой настройкой или имеете дело с чувствительными к конфиденциальности данных, сложность увеличивается. В этом посте мы поделимся тем, что мы узнали, создав нашу собственную систему вывода LLM. Мы расскажем о моделях хранения и развертывании, разработке архитектуры обслуживания и решении реальных проблем, таких как маршрутизация, потоковая передача и управление микросервисами. Процесс связан с проблемами, но в конечном итоге мы создали надежную систему и собрали уроки, которые стоит поделиться.
Введение
LLMS питает широкий спектр приложений - от чат -ботов и агентов рабочих процессов до интеллектуальных инструментов автоматизации. В то время как извлечение с аугментированными генерациями, выталкивание инструментов и многоагентные протоколы важны, они работают на уровне выше основного двигателя: основополагающий LLM.
Многие проекты полагаются на внешних поставщиков, таких как
Вот где самостоятельное ведение становится необходимым. Обслуживание предварительной или тонкой модели обеспечивает контроль, безопасность и возможность адаптировать модель к конкретным потребностям бизнеса. Создание такой системы не требует большой команды или обширных ресурсов. Мы построили его со скромным бюджетом, небольшой командой и всего лишь несколькими узлами. Это ограничение повлияло на наше архитектурное решение, требуя от нас сосредоточиться на практичности и эффективности. В следующих разделах мы рассмотрим проблемы, с которыми сталкиваются решения, внедренные решения и уроки, извлеченные на этом пути.
Общий обзор
Это основные компоненты, которые образуют основу системы.
- Форматы и кодирование.Общий язык между услугами имеет важное значение. Это означает последовательные форматы запроса/ответа, схемы параметров генерации, структуры истории диалога и сериализацию, которая работает повсюду - от фронта до бэкэнда до модельных бегунов.
- Потоковая передача и маршрутизация.Обработка нескольких моделей, типов запросов и приоритетов хоста требует преднамеренных решений по маршрутизации. Мы рассмотрим, как входящие запросы пользователей направляются через систему - от начальной точки входа до соответствующего узла работника - и как ответы передаются обратно.
- Модель хранения и развертывание.Где живут модели и как они готовится к производству?
- Вывод.Мы обсудим ключевые тесты для выполнения, включая обеспечение надежности модели.
- Наблюдаемость.Откуда вы знаете, что все работает? Мы покажем, какие метрики мы отслеживаем, как мы контролируем сбои, и какие зонды, которые мы используем для обеспечения здоровья и надежности системы.
Схема и кодирование данных
Выбор правильной схемы для передачи данных имеет решающее значение. Общий формат между службами упрощает интеграцию, уменьшает ошибки и улучшает адаптивность. Мы стремились разработать систему для беспрепятственной работы как с самостоятельными моделями, так и с внешними поставщиками-без раскрытия различий с пользователем.
Почему дизайн схемы имеет значение
Там нет универсального стандарта для обмена данными LLM. Многие поставщики следуют схемам, похожими на
Придерживаясь одного предопределенного схемы поставщика имеет свои преимущества:
- Вы получаетеХорошо проверенный, стабильный APIПолем
- Вы можете положиться наСуществующие SDK и инструментыПолем
Но есть и настоящие недостатки:
- Это создаетЗаблокировка продавца, затрудняя поддержку нескольких поставщиков.
- Это ограничивает гибкость, чтобы расширить схему с помощью пользовательских функций, необходимых для потребностей бизнеса или требований команды по науке о данных.
- Вы подвергаетесь воздействиюнарушение измененийИли деформации вне вашего контроля.
- Эти схемы часто несутНаследие ограниченияЭто ограничивает мелкозернистый контроль.
Чтобы решить это, мы решили определить нашсобственная внутренняя модель данных- Схема, разработанная вокруг наших потребностей, которые мы можем затем составить на карту с различными внешними форматами, когда это необходимо.
Внутренняя схема дизайн
Прежде чем решать проблемы, давайте определим проблему и рассмотрим наши ожидания в отношении решения:
- Легкое преобразование в форматы, требуемые внешними поставщиками и наоборот.
- Полная поддержка функций, специфичных для наших команд по бизнесу и науке о данных.
- Убедитесь, что схема легко расширяется для удовлетворения будущих требований.
Мы начали с рассмотрения основных схем LLM, чтобы понять, как поставщики структурируют сообщения, параметры и выходы. Это позволило нам извлечьОсновные доменные сущностираспространено в большинстве систем, в том числе:
- Сообщения (например, подсказка, история)
- Параметры генерации (например,,
temperatureВtop_pВbeam_search)
Мы определили определенные параметры, такие какservice_tierВusage_metadata, илиreasoning_mode, как специфичный для внутренней конфигурации поставщика и бизнес -логики. Эти элементы лежат за пределами домена Core LLM и не являются частью общей схемы. Вместо этого они рассматриваются как дополнительные расширения. Всякий раз, когда функция становится широко принятой или необходимой для более широкой совместимости, мы оцениваем интеграцию в основную схему.
На высоком уровне наша входная схема структурирована с этими ключевыми компонентами:
- Модель- Используется в качестве ключа маршрутизации, действует как идентификатор маршрутизации, позволяя системе направлять запрос на соответствующий узел работника.
- Параметры поколения- Настройки основной модели (например,,
temperatureВtop_pВmax_tokens) - Сообщения- История разговоров и быстрое полезные нагрузки.
- Инструменты- Определения инструментов, которые модель может использовать.
Это приводит нас к следующей схеме, представленной в
class ChatCompletionRequest(BaseModel):
model: str # Routing key to select the appropriate model or service
messages: list[Message] # Prompt and dialogue history
generation_parameters: GenerationParameters # Core generation settings
tools: list[Tool] # Optional tool defenitions
class GenerationParameters(BaseModel):
temperature: float
top_p: float
max_tokens: int
beam_search: BeamSearchParams
# Optional, non-core fields specific to certain providers
provider_extensions: dict[str, Any] = {}
...
# Other parameters
Мы намеренно переместили параметры генерации в отдельное вложенное поле вместо того, чтобы помещать их на корневой уровень. Этот выбор дизайна делает различие междупостоянныйпараметры (например, температура, верхняя P, настройки модели) ипеременнаяКомпоненты (например, сообщения, инструменты). Многие команды в нашей экосистеме хранят эти постоянные параметры во внешних системах конфигурации, что делает это разделение практичным и необходимым.
Мы включаем дополнительное поле под названиемprovider_extensionsвнутриGenerationParametersсорт. Эти параметры значительно варьируются по разным поставщикам LLM, валидация и интерпретация этих полейДелегирован к конечному модулю, который обрабатывает вывод модели- Компонент, который знает, как общаться с конкретным поставщиком моделей. Таким образом, мы избегаем ненужного прохождения, вызванного избыточной проверкой данных в нескольких службах.
Чтобы обеспечить обратную совместимость, новые функции схемы вывода вводятся какЯвные, дополнительные поляв схеме запроса. Эти поля действуют как флаги функций - пользователи должны установить их для выбора конкретного поведения. Этот подход сохраняет основную схему стабильной, обеспечивая дополнительную эволюцию. Например, следы рассуждений будут включены только в вывод только в том случае, если соответствующее поле установлено в запросе.
Эти схемы сохраняются в общей библиотеке Python и используются в разных службах для обеспечения последовательной обработки запросов и ответов.
Работа со сторонними поставщиками
Мы начали с того, как мы построили нашу собственную платформу - так зачем беспокоиться о совместимости между внешними поставщиками? Несмотря на то, что полагается на нашу внутреннюю инфраструктуру, есть еще несколько сценариев, в которых внешние модели играют роль:
- Синтетическое генерация данныхдля прототипирования и экспериментов нашими научными группами.
- Общие задачигде некоторые проприетарные модели работают лучше из коробки.
- Нечувствительные варианты использованиягде конфиденциальность, задержка или контроль инфраструктуры менее важны.
Общий поток связи с внешними поставщиками может быть обобщен следующим образом:
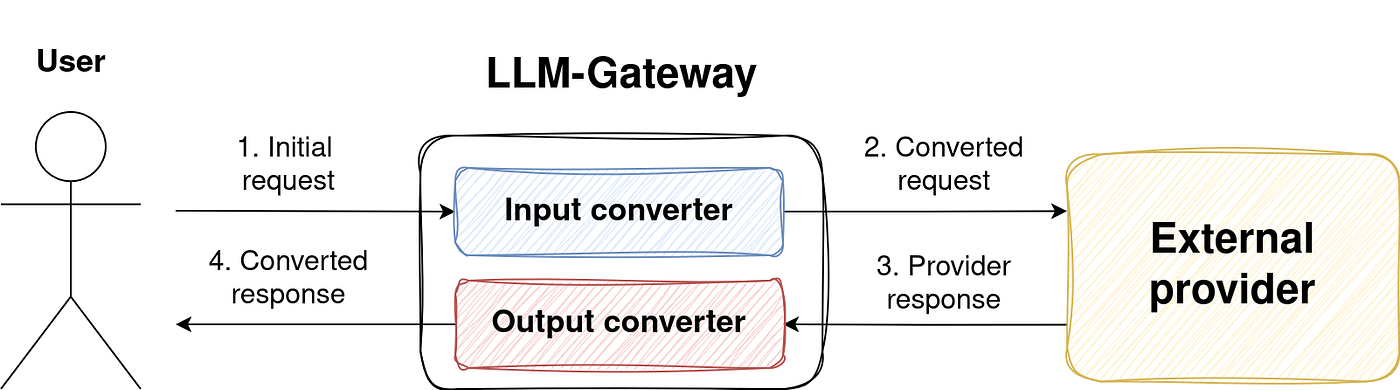
Этот процесс включает в себя следующие шаги:
- ОсобенныйLLM-Gateway ServiceОтвечает за связь с поставщиком получает запрос пользователя в нашем формате схемы.
- Запрос преобразуется в формат специфичного для поставщика, включая любой
provide_extensionsПолем - Внешний провайдер обрабатывает запрос и возвращает ответ.
- АLLM-Gateway ServiceПолучает ответ и отображает его обратно в нашу стандартизированную схему ответа.
Это схема высокого уровня, которая отвлекает некоторые отдельные микросервисы. Подробная информация о конкретных компонентах и формате потокового отклика будет рассмотрена в следующих разделах.
Потоковой формат
Ответы LLM генерируются постепенно - токен токеном, а затем агрегируются вкусочкиДля эффективной передачи. С точки зрения пользователя, будь то через браузер, мобильное приложение или терминал, опыт должен оставатьсяЖидкий и отзывчивыйПолем Это требует транспортного механизма, который поддерживаетНизкая задержка, потоковая передача в реальном времениПолем
Есть два основных варианта достижения этого:
Веб -вагоны : Полнодуплексный канал связи, который позволяет непрерывное двустороннее взаимодействие между клиентом и сервером.Серверные события (SSE) : Однонаправленный потоковой протокол на основе HTTP, который широко используется для обновлений в реальном времени.
Почему SSE над веб -вещами?
Хотя оба варианта жизнеспособны,SSE является более часто используемым решением для стандартного вывода LLM-особенно для API-интерфейсов OpenAI и аналогичных систем. Это связано с несколькими практическими преимуществами:
- Простота: SSE работает по стандартному HTTP, не требуя особого
обновления или переговоры Полем - Совместимость: Он работает изначально во всех основных браузерах без дополнительных библиотек.
- Однонаправленный поток: Большинство ответов LLM протекают только от сервера к клиенту, что соответствует дизайну SSE.
- По доверенности: SSE хорошо играет со стандартной HTTP -инфраструктурой, включая обратные прокси.
Из -за этих преимуществ,SSE обычно выбирается только для текстового, обратного потокового использованияПолем
Тем не менее, некоторые возникающие варианты использования требуют более богатой, двунаправленной связи с низкой задержкой, таких как транскрипция в реальном времени или речь к рече.
Поскольку наша система фокусируется исключительно наТекстовые взаимодействия, мы придерживаемсяSSEза его простоту, совместимость и выравнивание с нашей потоковой моделью.
Содержание потока ответов
СSSEВыбранный в качестве транспортного слоя, следующий шаг был определялчтоДанные для включения в поток. Эффективная потоковая передача требует больше, чем просто необработанный текст - он должен обеспечить достаточное количествоструктура, метаданные и контекстДля поддержки нижестоящих потребителей, таких как пользовательские интерфейсы и инструменты автоматизации. Поток должен включать следующую информацию:
- Метаданные уровня заголовка.Основная идентификационная информация, такая как идентификатор запроса.
- Фактические куски контента.Выход ядра - токены или строки, генерируемые моделью, - доставляется постепенно в виде последовательностей (
n) транслируются назад, кусочком. Каждое поколение может состоять из нескольких последовательностей (например,,n=2Вn=4). Эти последовательности генерируются независимо и транслируются параллельно, каждая из которых разбивается на свой собственный набор дополнительных кусков. - Использование и метаданные уровня токена.Это включает в себя количество сгенерированных токенов, данные о времени и дополнительную диагностику, такую как logprobs или следов рассуждений. Они могут использоваться для выставления счетов, отладки или оценки моделей.
После определения структуры потокового ответа мы также рассмотрели несколько нефункциональных требований, необходимых для надежности и будущей эволюции.
Наш дизайн потока предназначен:
- Структурированный- четко различив типы контента и границы событий.
- Расширяется- Способен носить дополнительные метаданные, не нарушая существующих клиентов.
- Крепкий- Устойчивые к удвоенным, отсроченным или частичным данным.
Во многих приложениях, таких какСравнение бок о бокилиРазнообразная выборка- Несколько последовательностей (завершения) генерируются параллельно как часть запроса одного поколения.
Наиболее полный формат для потоковых ответов определяется вchoicesмножество:
choicesмножество
Список вариантов завершения чата. Может содержать более одного элемента, если n больше 1. Также может быть пустым для последней части.
Хотя на практике отдельные куски обычно содержат только одну дельту, формат позволяет получать несколько обновлений последовательности на кусок. Это важно учитывать это, так как будущие обновления могут более широко использовать эту возможность. Примечательно, даже
Мы решили следовать той же структуре, чтобы обеспечить совместимость с широким спектром потенциальных функций. Приведенная ниже диаграмма иллюстрирует пример из нашей реализации, где одно поколение состоит из трех последовательностей, транслируемых в шесть кусков с течением времени:
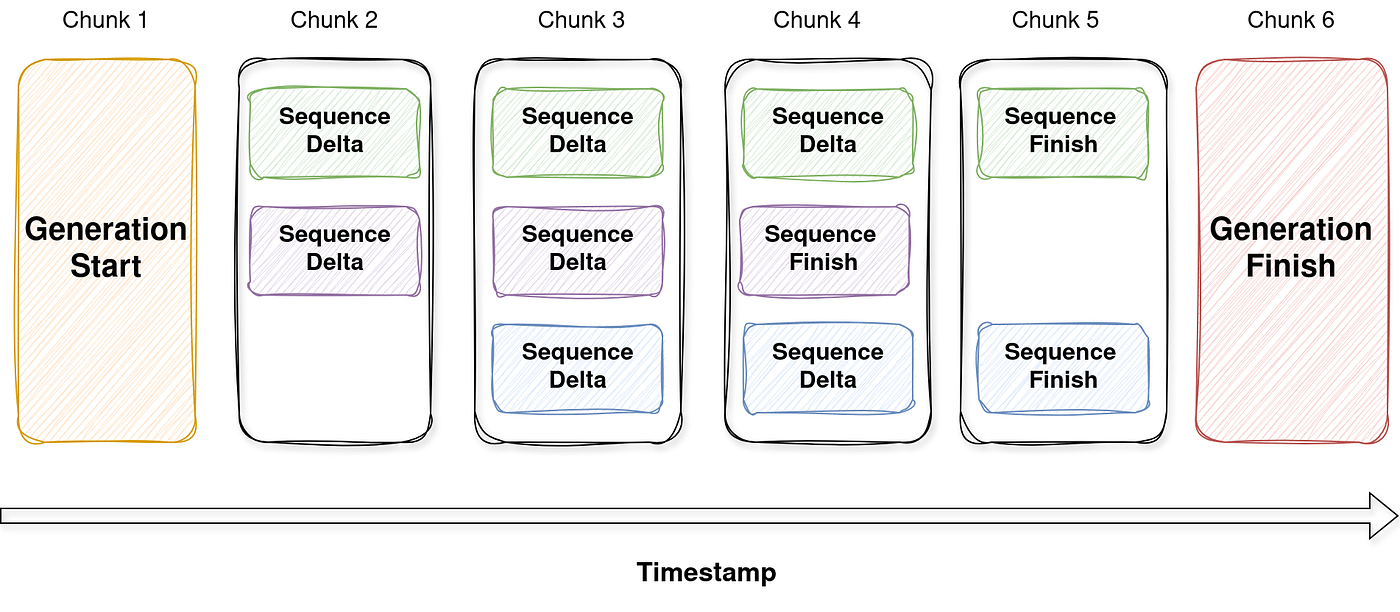
- Чунк 1 - начало поколения.Этот кусок знаменует собой начало всего поколения. Он не содержит никакого фактического содержания, но включает в себя общие метаданные, такие как идентификатор генерации, метка времени и роль (например, помощник и т. Д.).
- Чанк 2 - начало последовательности (зеленый и фиолетовый).Две последовательности начинают транслироваться параллельно. Каждый помечен уникальным идентификатором, чтобы отличить его от других.
- Чанк 3 - Столога последовательности (синий) и последовательность дельта.Третья последовательность начинается (синяя), в то время как первые две последовательности (зеленый и фиолетовый) инкрементный содержание потока через Delta Events.
- Chunk 4 - обновления и отделка в среднем течении (фиолетовый).Зеленые и синие последовательности продолжают транслировать Deltas. Фиолетовая последовательность заканчивается - это включает в себя структурированную Finish_Reason (например, остановка, длина и т. Д.).
- Чанк 5 - оставшаяся последовательность.Как зеленые, так и синие последовательности завершены. Жизненный цикл каждой последовательности в настоящее время полностью заключен между его соответствующими маркерами начала и отделки.
- Чунк 6 - Поколение финиш.Этот кусок закрывает поколение и может включать в себя глобальную статистику использования, количество токенов, информацию о задержке или другую диагностику.
Как вы видите, чтобы поток надежным и легче проанализировать, мы решилиЯвное начало сигнала и отделочные события как для общего поколения, так и для каждой отдельной последовательности, вместо того, чтобы полагаться на неявные механизмы, такие как нулевые проверки, EOF или жетоны магии. Этот структурированный подход упрощает анализ вниз по течению, особенно в средах, где несколько завершений транслируются параллельно, а также улучшает отзывность и изоляцию разломов во время разработки и проверки времени выполнения.
Более того, мы представляем дополнительноеОшибкакусок, который несет структурированную информацию о неудачах. Некоторые ошибки, такие как узоловые запросы или проблемы с авторизацией, могут быть обнаружены непосредственно через стандартные коды ответов HTTP. Однако, если возникает ошибкаВо время процесса генерацииУ нас есть два варианта: либо внезапно завершаем поток HTTP, либо излучает хорошо сформированное событие SSE. Мы выбрали последнее. Резкое закрытие соединения затрудняет клиенты, чтобы различать проблемы сети и фактические сбои модели/услуги. Используя выделенную ошибку, мы включаем более надежное обнаружение и распространение проблем во время потоковой передачи.
Бэкэнд служб и поток запросов
В центре системы находится единственная точка входа:LLM-GatewayПолем Он обрабатывает основные проблемы, такие как аутентификация, отслеживание использования и обеспечение соблюдения квот, форматирование запросов и маршрутизация на основе указанной модели. Хотя это может выглядеть так, как шлюз несет большую ответственность, каждая задача преднамеренно простая и модульная. Для внешних поставщиков он адаптирует запросы к их API и отображает ответы обратно в единый формат. Для самостоятельных моделей запросы направляются непосредственно на внутренние системы с использованием нашей собственной унифицированной схемы. Эта конструкция обеспечивает бесшовную поддержку как для внешних, так и для внутренних моделей посредством последовательного интерфейса.
Самостоятельные модели
Как упоминалось ранее,Серверные события (SSE)хорошо подходит для потоковых ответов на конечных пользователей, но это не практичный выбор дляВнутренняя Бэкэнд КоммуникацияПолем Когда приходит запрос, он должен быть направлен на подходящий узел работника для вывода моделя, и результат передается назад. В то время как некоторые системы обрабатывают это с использованием цепных HTTP-прокси и маршрутизации на основе заголовков, по нашему опыту, этот подход становится трудным для управления и развития по мере того, как логика растет в сложности.
Наша внутренняя инфраструктура должна поддержать:
- Приоритетное планирование-Запросы могут иметь разные уровни срочности (например, интерактивная и партия), и сначала должны быть выполнены задачи высокого приоритета.
- Аппаратная маршрутизация-определенные узлы, работающие на графических процессорах с более высокой производительности и должны быть предпочтительны; Другие служат переполнением.
- Специфичная для модели отправка- Каждый работник настроен на поддержку только подмножества моделей, основанную на совместимости аппаратного обеспечения и ограничениях ресурсов.
Для решения этих требований мы используемБрокер сообщенияЧтобы отделить маршрутизацию задач от доставки результатов. Этот дизайн обеспечивает лучшую гибкость и устойчивость в различных условиях нагрузки и маршрутизации. Мы используем
Теперь давайте подробнее рассмотрим, как эта система реализована на практике:
Мы используемВыделенные очереди на модель, позволяя нам маршрутизировать запросы на основе совместимости модели и возможностей узлов. Процесс заключается в следующем:
- Клиент отправляет запрос.Служба LLM-Gateway (представленная в качестве пользователя) инициирует HTTP-запрос для запуска задачи генерации текста.Сервис планировщиканачинает новыйЗапросить обработчикЧтобы управлять этим запросом.
- Маршрутизация задач через службу планировщика.Запрос обрабатываетсяПланировщик, который выбирает соответствующую очередь (помеченную зеленым на изображении) на основе запрошенной модели и добавляет к нему сообщение.
- Работник собирает задачу.СоответствующийВывода работника(Только один работник показан для простоты, но есть много), подписанных на очередь, поднимает задачу и начинает обработку. Этот работник запускает выбранную модель локально.
- Потоковая передача ответа.Работник транслирует ответ кусочком вОчередь ответов, на чтоОбработка реплики планировщика подписывается запросПолем
- Получение кусков ответа.Планировщик слушает очередь ответов и получает куски ответа по мере их прибытия.
- SSE потоковая передача.Куски преобразуются в формат SSE и транслируются в клиент.
Чтобы справитьсяБольшие полезные нагрузки, мы избегаем подавляющей брокера сообщения:
- Вместо того, чтобы встраивать большие входные или выходные данные непосредственно в задачу, мы загружаем их наВнешний S3-совместимый магазинПолем
- Ссылка (например, URL -адрес или идентификатор ресурса) включена в метаданные задачи, и работник получает фактический контент при необходимости.
Применение дизайна с RabbitMQ
Когда дело доходит доМаршрутизация и публикация сообщений, каждыйЗапросить очередьэто обычный кролик
Если потеря сообщения неприемлема, должно быть следующее:
Издатель подтверждает Чтобы убедиться, что брокер получил и сохранил сообщение.- Прочные очередииПостоянные сообщенияТаким образом, данные переживают перезагрузку.
Кворумские очереди для более сильной долговечности посредством репликации. Они также поддерживаютУпрощенное сообщение и потребительские приоритеты как Rabbitmq 4.0 Полем
Пока что мы рассмотрели, как публикуются задачи, но какпотоковой ответобрабатывали? Первый шаг - понять, каквременные очередиРабота в Rabbitmq. Брокер поддерживает концепцию под названием
Мы создаемодна эксклюзивная очередь на реплику услуги планировщика, гарантируя, что он автоматически очищается, когда реплика отключается. Тем не менее, это представляет собой задачу: в то время как каждая реплика обслуживания имеет единую очередь RabbitMQ, она должна обрабатыватьмного запросов параллельноПолем
Чтобы решить эту проблему, мы рассматриваем очередь RabbitMQ какТранспортный слой, маршрутизация ответов на правильную копию планировщика. Каждому пользовательскому запросу назначаетсяуникальный идентификатор, который включен в каждый отклик. ВнутриПланировщик, мы поддерживаем дополнительныйв памяти слой маршрутизацииС недолгими очередями в памяти-по одному на активный запрос. Входящие куски соответствуют этим очереди на основе идентификатора и соответствующим образом пересылаются. Эти очереди в памяти отбрасываются после завершения запроса, в то время как очередь RabbitMQ сохраняется в течение срока службы реплики услуг.
Схематично это выглядит следующим образом:
Центральный диспетчер в рамках планировщика отправляет куски на соответствующую очередь в памяти, каждый из которых управляется специальным обработчиком. Затем обработчики передают куски пользователям, используя SSE-протокол.
Вывод
Есть несколько зрелых рамок для эффективного вывода LLM, например, как
- Индивидуальная реализация поиска луча- Чтобы лучше соответствовать нашей логике поколения и поддержки структурированных ограничений.
- Поддержка структурированных выходных схем-Позволяет моделям возвращать результаты, соответствующие форматам, специфичным для бизнеса.
Через опыт мы узнали, что даже незначительные обновления библиотеки могутзначительно изменить поведение модели- Будь то качество выпуска, детерминизм или поведение параллелистики. Из -за этого мы создали надежный тестируемый трубопровод:
- Стресс -тестированиеЧтобы раскрыть проблемы параллелистики, утечки памяти или регрессии стабильности.
- Тестирование детерминизмаЧтобы обеспечить постоянные выходы для фиксированных семян и наборов параметров.
- Параметр Тестирование сеткиЧтобы покрыть широкий спектр настроек генерации, не переходя за борт.
Хранение и развертывание
Большинство современных систем работают вконтейнерные среды- либо в облаке, либо в Kubernetes (K8s). Хотя эта настройка хорошо работает для типичных сервисных услуг, она вводит проблемы вокругМодель весаПолем Модели LLM могут бытьдесятки или даже сотни гигабайт размером, и выпечка модели веса непосредственно в изображения Docker - быстро становится проблематичной:
- Медленные сборки-Даже при многоэтапных сборках и кэшировании передача больших модельных файлов на этапе сборки может значительно увеличить время CI.
- Медленное развертывание- Каждое развертывание требует вытягивания массивных изображений, которые могут занять несколько минут и вызвать время простоя или задержки.
- Неэффективность ресурса- Ни реестры Docker, ни узлы Kubernetes не оптимизированы для обработки чрезвычайно больших изображений, что приводит к раздутым использованию хранения и деформации полосы пропускания.
Чтобы решить это, мы отделяеммодель храненияИз жизненного цикла изображения Docker. Наши модели хранятся вВнешнее S3-совместимое хранилище объекта, и принесет незадолго до запуска услуг по выводу. Чтобы улучшить время запуска и избежать избыточных загрузок, мы также используем
Наблюдаемость
Такая система - построена напотоковая передача, очереди сообщений и генерация токенов в реальном времени- требуетнадежная наблюденияобеспечить надежность и производительность в масштабе.
В дополнение к стандартным показателям уровня обслуживания (процессор, память, частота ошибок и т. Д.), Мы обнаружили, что это необходимо контролировать следующее:
- Глубина очереди, отставание сообщений и количество потребителей- Мониторинг количества ожидающих сообщений, текущего размера очереди и количество активных потребителей помогает обнаружить раздачу задач и дисбалансы при использовании работников.
- Пропускная пропускная способность токена/чанка- Отслеживание количества токенов или кусков ответов, сгенерированных в секунду, помогает определить задержку или регрессии пропускной способности.
Распределенная трассировка - Чтобы точно определить, где запросы терпят неудачу или останавливаются по компонентам (шлюз, брокер, работники и т. Д.).- Вывод проверки здоровья двигателя- Поскольку процессы вывода могут сбой в редких условиях (например, плохие значения ввода или экстремальные параметры), упреждающий мониторинг жизнея и готовности имеет решающее значение.
Дальнейшие улучшения
Хотя наша система готова к производству, все еще существуют важные проблемы и возможности для оптимизации:
- ИспользованиеРаспределенный кв-кэшЧтобы повысить производительность вывода.
- ПоддержкаЗапрос отменыЧтобы сохранить вычисление, когда выходы больше не нужны.
- Создание аПростая модельная доставка трубопроводаДля научных групп.
Заключение
В то время как создание надежной и независимой от поставщика системы обслуживания LLM поначалу может показаться сложной, она не требует переосмысления колеса. Каждый компонент-потоковая передача через SSE, распределение задач через брокеров сообщений и вывод, обрабатываемый Trunttime, такими как VLLM,-это четкая цель и основан на существующих, хорошо поддерживаемых инструментах. При правильной структуре можно создать обслуживание и адаптируемую настройку, которая соответствует производственным требованиям без ненужной сложности.
В следующем посте мы рассмотрим более продвинутые темы, такие как распределенное квлажнение KV, обработка нескольких моделей по репликам и развертывание рабочих процессов, подходящих для ML-ориентированных команд.
Авторы
Благодарности
Оригинал