

Традиционные хранилища данных пожирают агентским ИИ?
18 июня 2025 г.Абстрактный:С точки зрения технической архитектуры, я считаю, что эта волна ИИ глубоко изменит всю программную экосистему. Системы DSS разработаны вокруг логики принятия людей человеческими решениями как конечный потребитель. Однако с появлением агентской эпохи ИИ, окончательный «потребитель» более вероятно, что является агентом. Это приведет к полной редизайне - или даже устранению - традиционных хранилищ данных и сложных трубопроводов ETL. Традиционные хранилища данных подчеркивают структуру и модели запросов, но они будут заменены агентскими архитектурами стека данных, фокусирующимися на семантике и шаблонах ответа.
ВВЕДЕНИЕ: сигнал, стоящий за изменением генерального директора Snowflake
Весной 2024 года Snowflake, звезда облачных хранилищ данных, объявила об изменении лидерства: Шридхар Рамасвами, бывший глава рекламного бизнеса Google, сменил легендарного генерального директора Фрэнка Столмана, который помог Snowflake достичь оценки в 60 миллиардов долларов.
Если вы думаете, что это просто обычный исполнительный случай, вы не видите полной картины. Настоящим подразумевается, что парадигма мирового мира данных проходит тихое, но глубокое преобразование.
Технологическая эволюция никогда не бывает линейной - это о скачках. От баз данных OLTP до хранилищ данных MPP, от локализованных вычислений MPP до векторизованных облачных двигателей данных, каждый этап представляет собой скачок к технологии следующего поколения и от одного доминирующего продукта до следующего.
Slootman представлял «золотой век хранилища данных». Он делает ставку на облачные, мультитенантные архитектуры и позиционировал снежинок в качестве центрального центра платформы данных следующего поколения. Под его руководством снежинка непосредственно нарушила моего первого работодателя - Teradata, бывшего гиганта хранилища данных - который видел, как его рыночная стоимость упала с 10,2 миллиарда долларов до всего 2 миллиарда долларов.
По мере того, как он ушел в отставку, ключевые слова в официальном блоге Snowflake тонко переключились на: AI-Perst, Agater-Presence и семантически ориентированной архитектуры данных.
Это не случайность - это признак времени.
В то же время наиболее дальновидные венчурные капиталисты в Силиконовой долине делают ставки на новую концепцию: «Агент AI». В этой новой парадигме ИИ больше не является просто моделью - это агент, который может воспринимать, действовать, ставить цели и сотрудничать.
Итак, вот вопрос:
Когда ИИ больше не является просто «инструментом чата», а интеллектуальным агентом, способным воссоздать бизнес -изменения, понимание намерений и выполнять действия - могут могут быть традиционные хранилища данных, предназначенные длялюди, все еще удовлетворяют потребности агентов?
Хранилиты данных, которые когда -то считались жизненно важными «активами данных», в настоящее время подвергаются риску стать просто «библиотеками материалов данных» для агентов. Фактически, даже термин «материал» теряет ценность, потому что агент-стек данных может напрямую получить доступ к необработанным данным и подавать его агентам по продажам высшего звена, агентам риска и другим в формате семантического + данных. Между тем, избыточные, несемантические данные на традиционных складах остаются для потребления инструментов BI и данных BI.
Настоящая опасность не просто устраняется - это то, что вы все еще действуете по старым правилам, в то время как мир уже перевернул сценарий.
Речь идет не о уничижительных хранилищах данных, а о повторяющихся циклах истории технологий. Подобно тому, как Hadoop и Aceberg когда -то изменили ландшафт озера данных, агент AIT теперь переписывает архитектуру больших данных предприятия.
1970–2024 гг.: Эволюция архитектур хранилища данных
1970: отец хранилища данных - Билл Инмон
Билл Инмон, «Отец хранилища данных», был первым, кто предложил концепцию EDW (хранилище данных предприятия) в качестве «предмета, ориентированного, интегрированного, варианта во времени и нелетательного сбора данных», закладывая основу для архитектуры предприятий в течение следующих полвека.
Мне повезло учиться и участвовать в переводе первого изданияСоздание хранилища данныхБолее 20 лет назад во время моего пребывания в Пекинском университете под руководством профессора Тан Шивэй. Описания этой книги о предметных областях, архитектуре уровня данных и медленно меняющихся измерениях (таблицы, связанных с историей), пережились с прошлого века до сегодняшнего дня, став основополагающими концепциями для хранилища данных.
1983: Терадата рождается - архитектура MPP выходит на сцену
В 1983 году была основана Teradata - компания, которая доминировала в корпоративной инфраструктуре хранилища данных в течение следующих 30 лет. Это была также моя первая работа после окончания учебы. Teradata была первой, кто внедрил архитектуру MPP (массивно параллельной обработки) в системы данных. Благодаря тесному интегрированному программному и аппаратному и Bynet Design MPP, Teradata значительно превзошел Oracle и DB2 в массовой обработке данных и сложных запросах SQL.
В первый раз, когда я использовал Teradata, я был так же поражен, как и когда я позже попробовал Clickhouse для широких запросов.
Когда я присоединился к Teradata, это был все еще отдел под NCR, и моя визитная карточка выглядела так. Для тех, кто интересуется Teradata, посмотрите мою статьюПрощай с моей альма -матер с хранилищем данных - Teradata официально выходит из КитаяПолем

1996: Кимбалл предлагает «схему снежинки»; Энтеры Olap появляются
После Билла Инмона Ральф Кимбалл представил концепцию «Mart Mart» и пересмотренного моделирования данных со схемой Star и Snowflake. В течение следующих нескольких десятилетий архитекторы данных постоянно обсуждали, должны ли сначала создавать централизованное хранилище данных или отдельные марки данных. «Размерное моделирование» и «Схема снежинки» стали визитными картами для инженеров данных.
На слое BI двигатели MOLAP, такие как Hyperion Essbase и Cognos, начали появляться. Технология OLAP наконец -то имела систематическую методологию для следования.
Спустя десятилетия новое поколение компаний хранилища данных даже приняло «Snowflake» в качестве своего бренда, вдохновленного схемой снежинки.
2013: бум больших данных - Hadoop берет мир штурмом
С выпуском Apache Hadoop в 2006 году Enterprises начали широко внедрять системы больших данных с низкими затратами на хранение. ВБольшие данные: революция, которая изменит то, как мы живем, работаем и думаем, Виктор Майер-Счёнбергер определил большие данные с «4VS»:ОбъемВСкоростьВРазнообразие, иЦенитьПолем

Это ознаменовало начало массивной волны конструкции платформы больших данных. В течение следующих 10 лет появилось новое поколение технологий больших данных - Apache Hadoop, Hive, Spark, Kafka, Dolphinscheduler, Seatunnel, Aceberg и других. Платформы больших данных начали дрожать доминирование традиционных хранилищ данных. Фактически, после 2015 года большинство китайских предприятий, занимающихся хранением данных в масштабе Petabyte, больше не использовали традиционные архитектуры хранилища данных MPP. Вместо этого они создали свои платформы, используя архитектуры больших данных/озера «Озера/озера» на основе айсберга.
2015: снежинка вырывается на сцену, новый стек данных поднимается
С ростом облака и выпуском бумаги Марцина Зуковского по «векторизованным» двигателям, снежинка появилась с облачной архитектурой, которая разделяла вычислительные и хранения, полностью нарушая традиционное мышление хранилища данных. Впервые инженеры BI могли бы наслаждаться эластичным масштабированием «по требованию», не беспокоясь о планировании кластера или распределении ресурсов.
Снежинка превратила «хранилище данных» в «облако данных». Это привело к появлению совершенно нового поколения технологий хранилищ данных. Последовали инструменты, такие как FiveTran, Dagster, Airbyte, DBT и Whalestudio, вызываяНовый стек данныхТенденция в Силиконовой долине. Действительно, предыдущее поколение ETL и инструментов разработки данных - Informatica, Talend, DataStage - созданные в 1980 -х годах. Рост новых технологий требовал совершенно новой экосистемы.
В целом, в течение последних десятилетий, будь то традиционные хранилища данных, платформы больших данных, облачные хранилища данных или озера данных, их архитектуры по существу следовали структуре, показанной на диаграмме ниже:
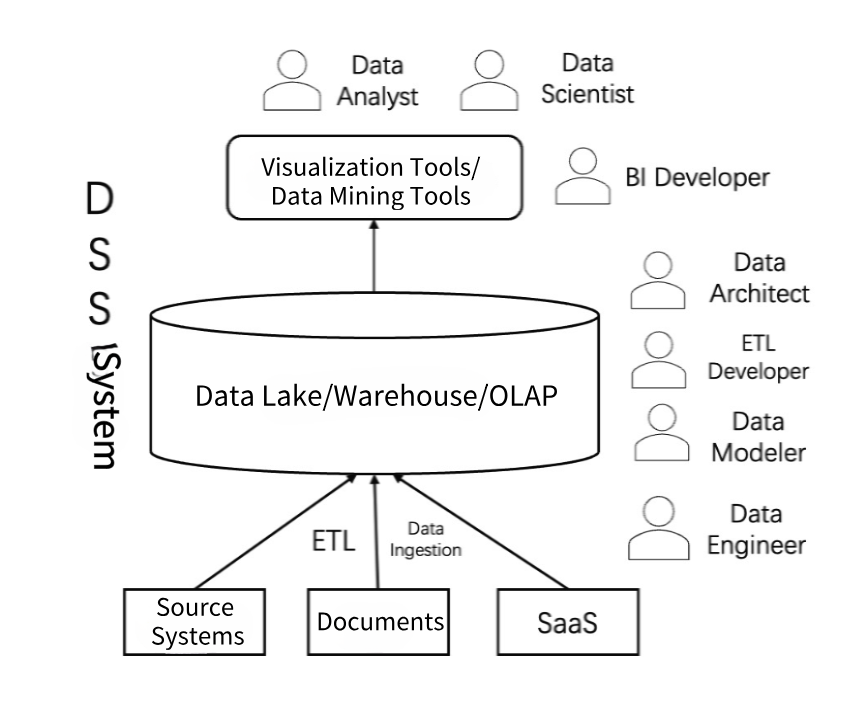
В эпоху INMON эта архитектура называлась DSS -система (система поддержки принятия решений). Как следует из названия,«поддержка» всегда была предназначена для людей.Весь технический стек Gatahouse был разработан для пользователей.
Архитектура хранилища данных была также разработана для инженеров данных. Вот почему у нас было несколько предметных областей, атомных слоев, слоев агрегации и слоев метрик, чтобы помочь инженерам ETL в разработке. Инструменты BI также необходимы для определения схемы STAR и снежинок с перетаскиванием интерфейсов для отчетов и панелей мониторинга. Все потребители были людьми.
Но в эпоху больших моделей все это вот-вот изменится.
Агенты пожирают традиционные хранилища данных?!
В конце 2022 года Openai выпустил Chatgpt, начав эпоху крупных языковых моделей.
С 2023 года Llama, Claude, Gemini, GPT-4O, DeepSeek… мультимодальные модели быстро развивались. ИИ больше не просто языковая модель, а «общий разведывательный двигатель», способный понять и принимать решения для сложных задач.
В 2024 году технология тряпичной (поиск-аугментированное поколение) стала основной. Такие инструменты, как Lmamaindex, Langchain и Dify, получили широкое распространение. ИИ начал интегрировать знания в области предприятия, став действительно «осведомленным помощником».
К 2025 году архитектура агента полностью поднялась. Появились технологии и протоколы, такие как AutoGPT, вызов функций и протокол MCP. ИИ больше не просто инструмент чата - теперь он имеет возможности восприятия, планирования и выполнения, становясь «цифровым работником».
В области данных прибытие крупных моделей также вызвало серьезные нарушения. Вы использовали аналитик данных CHATGPT? Если это так, вы, вероятно, были поражены его производительностью. Это может помочь бизнес -пользователю генерировать подробный аналитический отчет из набора данных с нескольких точек зрения. Это может практически заменить младшего аналитика данных. На различных уровнях появилось также много инструментов «автоматизации», таких как чатби и txt2sql,-это использует большие модели и агенты для автоматизации или полуавтоматических процессов разработки хранилища данных.

В будущем появится все больше и больше агентов - не только в анализе данных, но и в оптимизации рекламных кампаний, обслуживании клиентов и управлении рисками. Эти агенты будут постепенно освобождать бизнес -персонал, заменив их взаимодействие на системы.
В конечном счете, ИИ больше не будет «пассивным инструментом для ответа», а «интеллектуальным агентом активно достигает целей».
В течение последних 20 с лишним лет «пользователями» платформ данных, как правило, были инженерами, аналитиками и специалистами BI.
В ближайшие 20 лет,Каждая роль - от аналитика до оператора цепочки поставок - может быть пересмотрена агентами:
У маркетологов будет агент кампании, который автоматически интегрирует многоканальные данные, оптимизирует размещение и генерирует копирование;
У представителей обслуживания клиентов будет агент поддержки, который будет больше, чем чат-бот-это будет помощник по контексту с графами знаний и памятью;
Команда цепочки поставок будет иметь агента по закупкам, который анализирует заказы, отслеживает сроки доставки, получает данные ERP и автоматические инвентаризации;
У юридических групп будет агент по соблюдению, у HR будет агент по найму, и даже у совета директоров может быть агент правления…
SQL, который вы использовали каждый день, составляли отчеты, которые вы составляли, и встречи OPS, которые вы посещали, становятся инициированными агентами действиями, семантическими командами и автоматическими ответами.
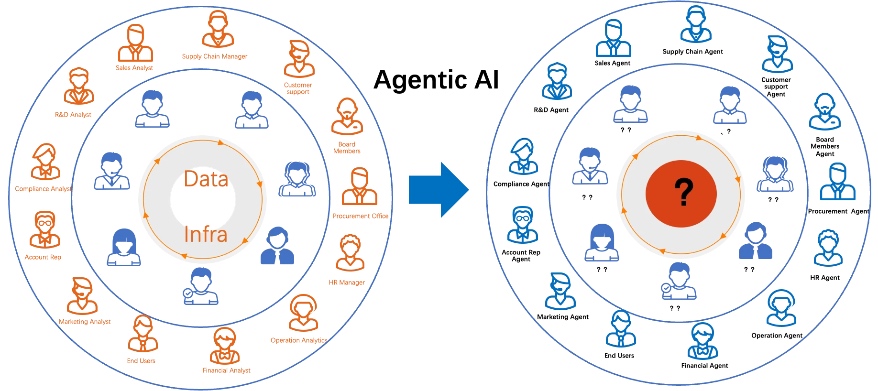
Но насущная реальность следует:
Если конечные пользователи данных являются агентами, и даже разработка хранилища данных осуществляется агентами-и конечные лица, принимающие решения, использующие данные, являются агентами, а не «людьми»-оригинальная архитектура хранилища данных DSS (система поддержки принятия решений) по-прежнему имеет смысл?
Любой, кто изучал разработку программного обеспечения, знает первую диаграмму, которую вы рисуете при разработке системы, - это диаграмма «вариант использования» - она определяет пользователей, границ и сценариев поведения системы.
Когда пользователь хранилища данных переходит от человека к агенту, архитектура DSS, представляемая Биллом Инмоном, больше не имеет воды. По крайней мере, на мой взгляд, это не так.
Когда пользователь меняется, программное обеспечение тоже должно измениться.
Рост агентов - это не просто победа для больших моделей - это полное нарушение того, как мы воспринимаем пользовательский опыт:
Традиционные системы данных, работающие в «модели тяги»: пользователь знал проблему, запросил данные и извлекал выводы.
Будущие агенты работают в «Push Model»: система активно определяет изменения, понимает намерения и генерирует предложения принятия решений.
Это похоже на переход от традиционных карт к GPS Navigation:
Вам больше не нужно знать «где дорога» - вы просто сообщаете системе, куда вы хотите пойти, и это отвезет вас туда.
Традиционные хранилища данных сосредоточены на структуре и запросе, тогда как агентские архитектуры приоритет семантике и отзывчивости.
Проще говоря: тот, кто понимает деловой язык, будет управлять миром данных.
Агент стек данных и контекстный блок данных (CDU): данные со встроенной семантикой
Чтобы агенты могли автоматически разрабатывать и использовать данные, сегодняшний дизайн хранилища данных не подходит - он никогда не предназначен для крупных моделей или агентов. Что хранятся внутри, так это «необработанные» данные - просто численные значения и имена столбцов. То, что на самом деле означают эти значения или поля, хранятся в отдельной системе управления «активами данных». Понимание каждого значения или поля требует полноценного проекта «управление данными». Этот дизайн недружелюбен к крупным моделям и агентам, которые зависят от семантических рассуждений. Итак, если бы мы перепроектировали систему хранения данных для агентов и крупных моделей, нам придется хранитьДанные и семантика вместеПолем Я называю это:
Контекстуальная единица данных (CDU): двойной элемент, объединяющий данные + семантическое объяснение-каждый ввод данных имеет свое значение с ним.
Он объединяет информацию, традиционно хранящуюся в каталогах данных непосредственно в каждом вводе данных, сокращая время поиска и частоту ошибок, когда к нему доступ к агентам или крупным моделям.
Между тем, семантика в CDU получена из бизнес -систем - они дистиллированы и абстрагируются агентами потока данных в источнике. ХДС образуется во время приема, впадая в озеро агента, а не сгенерировано впоследствии. Другими словами, управление данными и происхождение встроены в сам процесс разработки, управляемый агентами, а не применяются задним числом после того, как данные въехали на склад, избегая конфликта и двусмысленности.
На данный момент вы должны понимать мое мышление: в эпоху агентского искусственного интеллекта все, от ETL до хранилища до приложения данных, будет изменено, потому чтоПотребители теперь являются агентами и моделями.Чтобы обслуживать эти интеллектуальные агенты, традиционные платформы данных должны развиваться в архитектуру, управляемую событиями, управляемая агентом,-то, что мы называемАгент стек данныхПолем
Агент-стек данных: в эпоху агента новый стек технологий данных, который охватывает от инструментов для получения «Data + Semantics», до платформ, которые вычисляют и хранят данные CDU-формата, и, наконец, до уровня взаимодействия, который предоставляет эти данные агентам.
Вот мой смелый прогноз того, что может включать в себя стек агента данных:
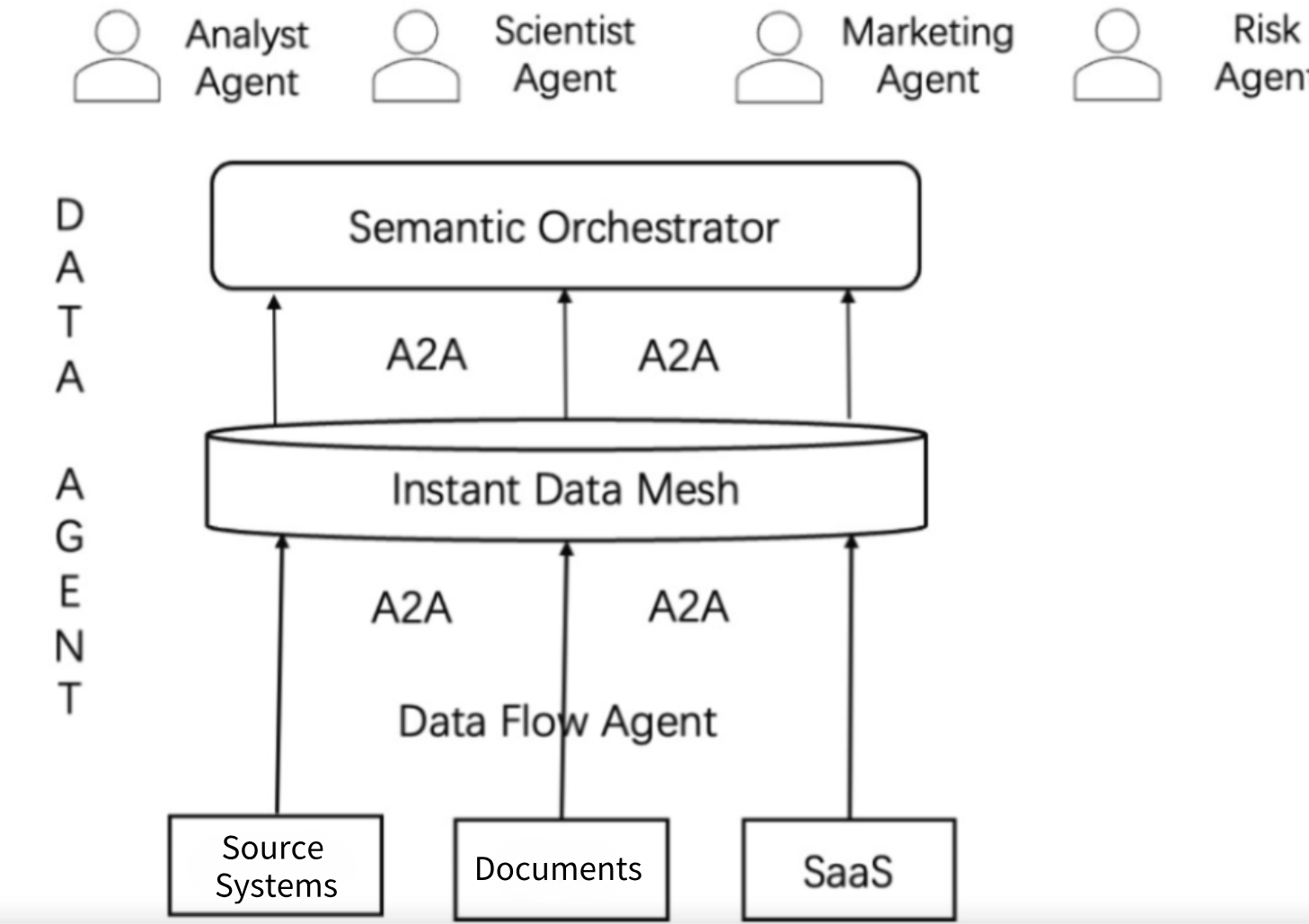
Семантический оркестратор (слой взаимодействия):Это больше не интерфейс BI/Dashboard, а «мозг» и «командный центр» агентской архитектуры. Благодаря возможности понимания естественного языка и семантических рассуждений он связывает других агентов с базовыми активами данных, обеспечивая интеллектуальное, много круглый взаимодействие и генерацию услуг.
Сетка данных (уровень хранения):Больше не традиционное хранилище данных или озеро Data-это ориентированный на услуги, удобный вычисленный слой слияния, который хранит данные с семантикой. Он может предоставлять данные для сложных вычислений с помощью LLMS, а также поддерживает обработку в реальном времени.
Агент потока данных (обработка слоя):Не только «перемещение данных», но и понимание и организуют данные. Не запланировано периодически, а управляемым событиями и намерениями. Способен обнаружить изменения данных, анализировать схемы, понимание бизнес -логики и соответствующим образом реагировать.
В агентскую эпоху ИИ цикл строительных платформ данных будет резко сокращаться. Новые данные обнаруживаются агентами по потоку данных, предварительно хранящиеся в сетке данных и интерпретируются семантическим оркестрером с выравниваемыми бизнесом определениями, что позволяет «мгновенные вычисления» от бизнес-спроса до вывода данных.
LLMS обеспечивает мозговую точку. Агенты - это руки и ноги. Агент -стек данных дает им доступность данных, необходимую в эпоху больших моделей.
С ростом стекла агента, стоимость строительства «хранилищ данных» следующего поколения резко снижается. Наличие возможностей запросов естественного языка и доступ к соответствующим данным не будут просто привилегией крупных предприятий-он станет доступным для малых предприятий и даже отдельных лиц. Вы можете захватить свои файлы Google Drive, Home NAS, PDFS на вашем ноутбуке и заказы приложений с вашего телефона в ваш персональный хранилище данных через агент потока данных. Затем задайте вопрос, например, «Сколько я потратил посещение Диснея в прошлом месяце?» - что ранее требовалось экспорт с нескольких платформ и вручную создавать листы Excel. Еще более сложные запросы, такие как «Найти мой страховой контракт с 5 лет назад» становятся выполнимыми.
И это не фантазия. Недавно под руководством Whaleops сообщество Apache Seatunnel выпустило Apache Seatunnel MCP -сервер, который уже движется к тому, чтобы стать агентом потока данных. Конечно, все еще есть технические препятствия для преодоления - такие как незрелые протоколы A2A, недоказанные семантические+модели хранения данных в слое сетки данных, и преобразование унаследованных выходов управления в входные данные для семантического оркестратора.
Но прибытие эпохи LLM и агента изменит индустрию анализа данных так же, как это произошло изобретение SQL.
Это никогда не является вашим «видимым» конкурентом, который бьет вас. История: Когда я был ребенком, два популярных велосипедных бренда были навсегда и Феникс. Они соревновались на скорости с помощью «ускоренных оси». Но то, что нарушило велосипедный рынок, было не лучшим велосипедом - это была компания по доставке продуктов питания, запускающая общие велосипеды, переворачивая всю отрасль. По мере роста агентов некоторые основные пути продукта, в которые мы когда -то верили, могут потерять смысл. Держа голову на исполнение, не забудьте посмотреть на небо.
Вывод: живите в настоящем, см. В будущем
Когда я поделился этим видением в Aicon, AWS Community Day и других технических саммитах, аудитория всегда разделилась на два лагеря. «Верующие» думают, что я слишком консервативен в том, чтобы сказать, что агент -стек данных находится в 5–10 лет - они считают, что ИИ развивается так быстро, что мы увидим его полностью сформированным в течение 5 лет. «Скептики» думают, что влияние агентов ИИ на архитектуру хранилища данных сильно преувеличено. Они утверждают, что сегодняшние проекты хранилища данных являются самым высоким форматом ROI, и все, что менее эффективное не будет масштабироваться коммерчески-это просто пирог в небе.
Лично я «центрист»: яПоверьте, возникновение стека агентских данных неизбежно.Эта волна ИИ повлияет на архитектуру программного обеспечения таким образом, что это принципиально отличается от предыдущих волн.Мы должны рассмотреть общую стоимость и результаты строительства и эксплуатации хранилища и операций хранилища предприятий, а не только для хранения или вычисления ROI.
В настоящее время мы видим тенденции: рост хранилищ данных в реальном времени, расширение озер данных и сокращение слоев в современном дизайне склада. (Я бы даже утверждал, что теперь, когда наше поколение архитекторов моделирования данных, обученных Teradata, выходит на пенсию, на рынке отсутствуют профессионалы, которые могут не отставать от быстро развивающейся бизнес-логики). Таким образом, традиционное моделирование само по себе является итерационным-склады в реальном времени теперь часто используют 2 слоя вместо 3–4. Я просто указываю на больший скачок впереди в эпоху агента. В соответствии с балансом, рентабельность инвестиций агентского стека данных, вероятно, превзойдет ткань нового стека данных.
Тем не менее, переход не произойдет в одночасье. Мне потребовалось с 2016 по 2020 год, чтобы помочь Clickhouse стать фактическим двигателем OLAP в режиме реального времени Китая, и это было с уже доступным продуктом. С другой стороны, агент-стек только имеет несколько компонентов на ранней стадии и стартапов. Большинство из них еще не существует - это определенно не доминирует на рынке менее чем за 5 лет. Если мы думаем поэтапно, это, вероятно, последует после того, как склады в реальном времени и озера получит более широкое принятие предприятий.
Это не ИИ, который заменяет вас - это человек, который знает, как использовать ИИ. Дело не в том, что хранилища данных пожирают, а их модель, ориентированную на структуру и цифру, заменяется семантикой и ориентированной на получение ответа архитектуры. Точно так же, как, как только вы использовали GPS, вы не вернетесь на бумажную карту.
Ворота в стек агента открываются.
Вы готовы?
Оригинал