
Анализ влияния частоты предварительной подготовки на производительность с нулевым выстрелом в мультимодальных моделях
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
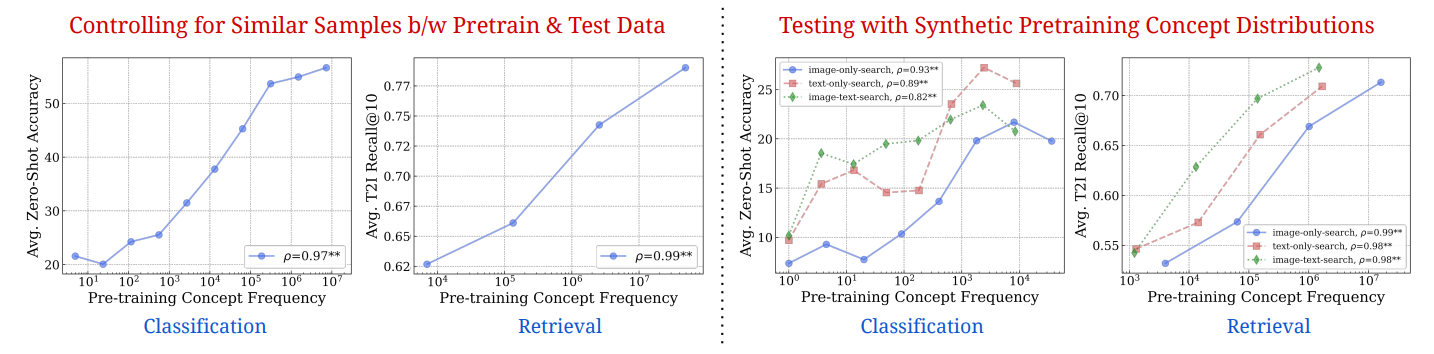
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
3 Сравнение частоты до подготовки и производительности «нулевой выставки»
Получив оценки частоты для наших нижестоящих концепций, мы теперь устанавливаем взаимосвязь между частотой концепции, соответствующими изображению, и показателями с нулевым выстрелом в течение классификации, поиска и задач генерации. Сначала мы подробно описываем наш экспериментальный подход, а затем обсудим ключевые результаты.
3.1 Экспериментальная установка
Мы анализируем два класса мультимодальных моделей: изображение-текст и текст к изображению. Для обоих мы подробно описываем наборы данных предварительной подготовки и тестирования, а также связанные с ними параметры оценки.
3.1.1 Модели Image-Text (CLIP)
Наборы данныхПолем Наша оценка состоит из 4 наборов данных предварительного подготовки, 2 наборов данных о поиске вниз по течению и 17 наборов данных о нижних классификациях, представленных в TAB. 1, охватывая широкий спектр объектов, сцен и мелкозернистых различий.
МоделиПолем Мы тестируем клип [91] модели с архитектурой Resnet [53] и Vision Transformer [36], с Vit-B-16 [81] и RN50 [48, 82], обученными CC-3M и CC-12M, Vit-B-16, RN50 и RN101 [61], обученным YFC-14, и Vit-B-16, Vit-B-32, и Vit-B-32, и Vit-B-32, и Vit-B-32, и Vit-B-32, и Vit-B-32, и Vit-B-32, Vit-B-32, и Vit-B-32, Vit-B-32, и Vit-B-32. [102]. Мы следим за открытым клипом [61], Slip [81] и Cyclip [48] для всех деталей реализации.
ПодсказкаПолем Для классификации с нулевым выстрелом мы экспериментируем с тремя стратегиями подсказки: {{classname}, «Фотография {classname}» и приглашенных-энмиблей [91], которая в среднем составляет более 80 различных вариантов быстрого приглашения {classname}. Для поиска мы используем изображение или заголовок в качестве ввода, соответствующего поиту I2T (изображение в текст) или T2I (текстовый в изображение) соответственно.
МетрикиПолем Мы вычисляем среднюю точность классификации с нулевым выстрелом для задач классификации [91]. Для поиска мы оцениваем производительность, используя традиционные метрики как для задач, так и для поиска с изображением в тексте [91] (Remeply@1, Remeply@5, Remeply@10).
3.1.2 Модели текста до изображения
Наборы данныхПолем Наш набор данных предварительной подготовки-Laion-Aestetics [103], с нисходящими оценками, проведенными на подменых версиях восьми наборов данных, выпущенных Heim [71]: Cub200 [121], Daily-Dalle [33],

Обнаружение [30], Parti-Prompts [130], Drawbench [98], Coco-Base [73], реляционное понимание [32] и винограунд [114]. Пожалуйста, обратитесь к Хейму [71] для получения более подробной информации об используемых наборах данных оценки.
МоделиПолем Мы оцениваем 24 модели T2I, подробно описанные в TAB. 2. Их размеры варьируются от 0,4b параметров (DeepFloyd-IF-M [9] и Dall · e mini [34]) до параметров 4,3B (DeepFloyd-IF-XL [9]). Мы включаем различные стабильные диффузионные модели [96], а также варианты, настроенные для конкретных визуальных стилей [6, 4, 5].
ПодсказкаПолем Текстовые подсказки из наборов данных оценки используются непосредственно для генерации изображений с 4 образцами изображений, сгенерированными для каждой подсказки.
МетрикиПолем Оценка состоит из выравнивания текста изображения и эстетических баллов. Для автоматизированных метрик [71] мы используем ожидаемый и максимальный показатель клипов [57] для измерения выравнивания текста изображения и ожидаемой и максимальной эстетической оценки [102] для измерения эстетики. Чтобы проверить достоверность автоматизированных метрик, мы сравниваем их с оценками по рейтингу человека (измеренными по 5-балльной шкале оценки) как для выравнивания текста изображений, так и для эстетики [71]. Чтобы дополнить оценки с рейтингом человека, предоставленные Хеймом [71], мы подтверждаем наши выводы, также выполняя небольшую оценку человека (см. Appx. C).
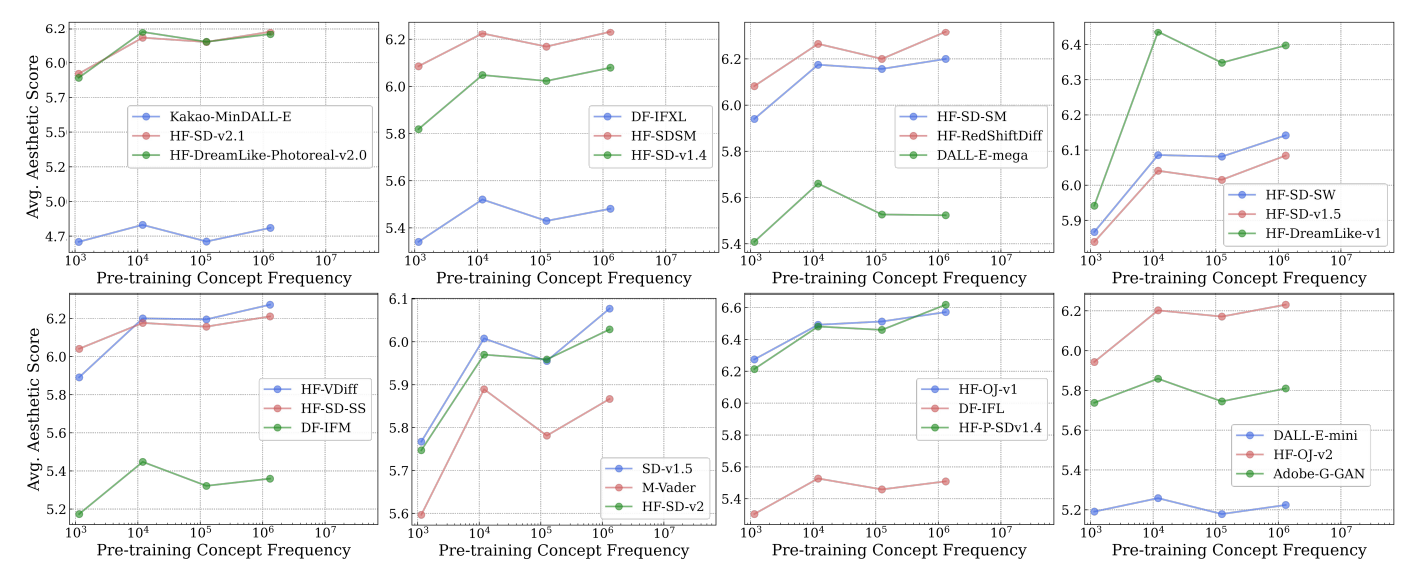
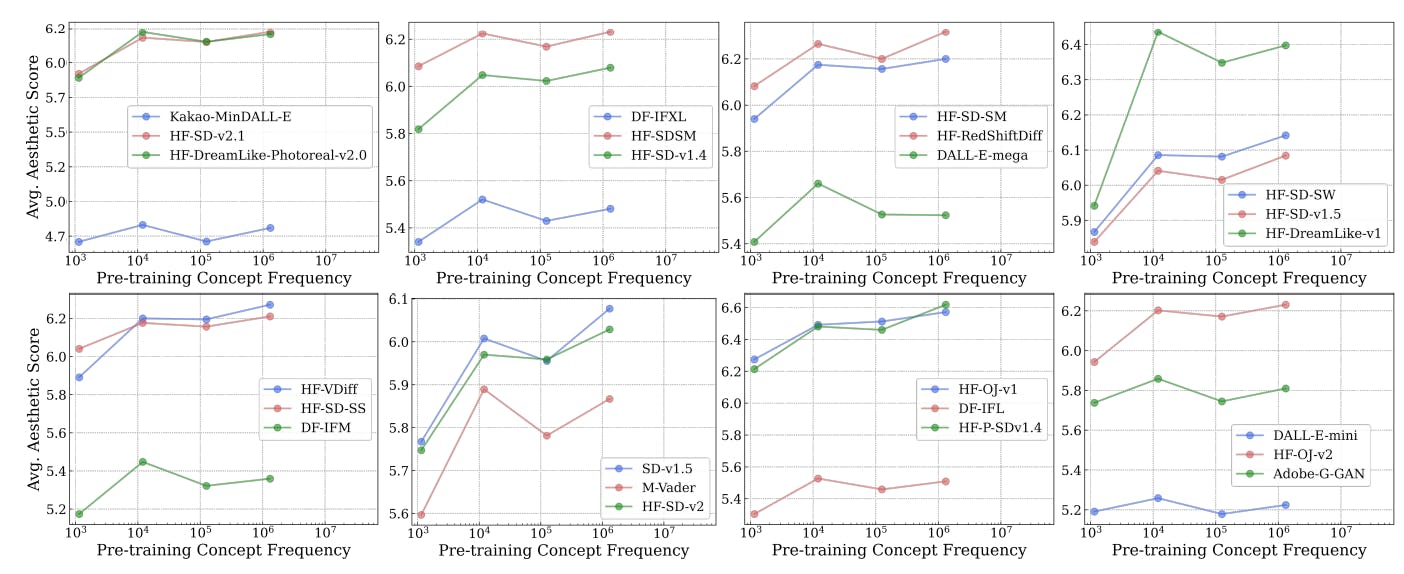
3.2
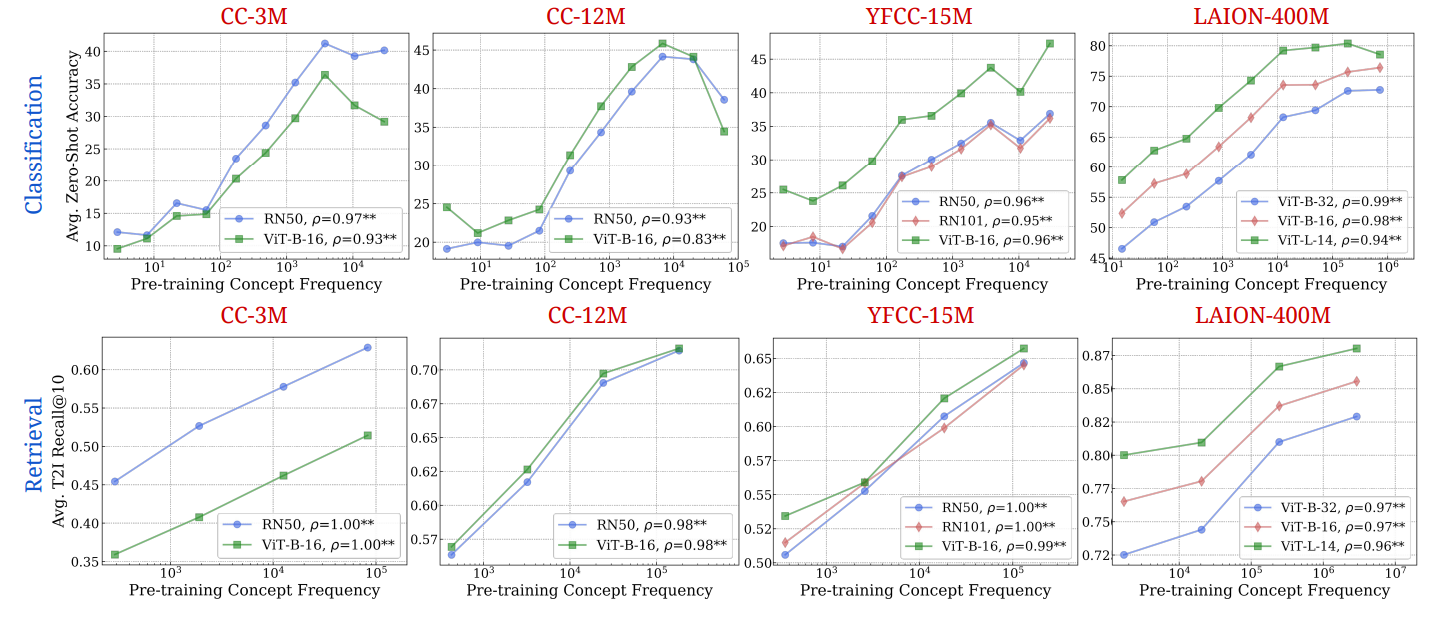
Теперь мы исследуем влияние частоты концепции на наборы данных предварительного подготовки на производительность с нулевым выстрелом моделей с изображением. Мы используем соответствующие частоты концепции концепции изображения для оценки частоты концепций во время предварительной подготовки. Наши выводы, проиллюстрированные всесторонне на рис. 2 и 3, демонстрируют, что частота концепции эффекта на производительность модели по различным задачам и типам моделей.
Понимание участков.Графики в основной статье представляют результаты классификации моделей текста-изображения (CLIP) с использованием точности и производительности извлечения текста до изображения с использованием Remeply@10. Точно так же мы представляем производительность генеративных моделей T2I по задачам генерации изображений, используя ожидаемую оценку эстетики. Для других вышеупомянутых показателей для поиска, а также для других автоматизированных показателей генерации, а также оценки с рейтингом человека, мы обнаруживаем, что они показывают аналогичные тенденции, и мы предоставляем их для справки в приложениях. B и C. Для ясности презентация данных упрощается с графиков рассеяния до сплоченной линии, похожей на работу Kandpal et al. [62] и Razeghi et al. [94]. Ось X имеет логарифмическое масштаб, а метрики производительности усредняются в контейнерах вдоль этой оси для простоты визуализации логарифмической корреляции. Мы удалили бункеры, содержащие очень мало концепций на корзину при стандартном удалении IQR [122] после Kandpal et al. [62]. Мы дополнительно вычисляем корреляцию Пирсона ρ для каждой строки и даем результаты значимости на основе двухстороннего t-критерия [110].
Находка ключей: логарифмическое масштабирование между частотой концепции и ноль-выстрелом.На всех 16 участках мы наблюдаем четкую логарифмическую линейную связь между частотой концепции и ноль-выстрелом. Обратите внимание, что эти графики варьируются в (i) дискриминационных и генеративных типах моделей, (ii) классификации в зависимости от поисковых задач, (iii) масштабами моделей и параметров, (iv) наборов данных предварительных обработок с различными методами курирования и шкалы, (v) различные показатели оценки, (vi) Появления по Zere-Shot Classification и (VII). которые показывают вариации (v) представлены в приложениях. Наблюдаемая логарифмическая тенденция масштабирования сохраняется во всех семи представленных измерениях. Таким образом, наши результаты четко показывают, что данные голодного данных, т. Е. Отсутствие способности современных мультимодальных моделей изучать концепции из наборов данных предварительного подготовки данных.
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал