

Введение в силу векторного поиска для начинающих
6 декабря 2022 г.Если вы хоть как-то ориентируетесь в технологиях — вплоть до любопытства — то вы должны были слышать о векторном поиске. Если вы еще не поняли или все еще чувствуете себя немного потерянным, вот введение, которое все прояснит.
Краткая история поиска
Человеческая память ненадежна. Таким образом, пока мы начали собирать «знания» в письменной форме, нам приходилось придумывать, как искать релевантный контент, не перечитывая повторно одни и те же книги. Вот почему некоторые блестящие умы ввели перевернутый индекс. В простейшей форме это приложение к книге, обычно помещаемое в конце, со списком основных терминов и ссылками на страницы, на которых они встречаются. Термины расположены в алфавитном порядке. Раньше это был составленный вручную список, требующий больших усилий для подготовки. С началом цифровизации стало намного проще, но все же мы сохранили те же общие принципы. Это работало и до сих пор работает.
Если вы ищете конкретную тему в конкретной книге, вы можете попытаться найти родственную фразу и быстро попасть на нужную страницу. Конечно, при условии, что вы знаете правильный термин! Если вы этого не сделаете, вы должны попробовать несколько раз и потерпеть неудачу или найти кого-то другого, кто поможет вам сформировать правильный запрос.

Упрощенная версия инвертированного индекса
Прошло время, и у нас уже давно не было особых изменений в этой области. Но наша коллекция текстовых данных начала расти более быстрыми темпами. Поэтому мы также начали создавать множество процессов вокруг этих перевернутых индексов. Например, мы разрешили нашим пользователям вводить много слов и начали разбивать их на части. Это позволило найти некоторые документы, которые не обязательно содержат все слова запроса, но, возможно, часть из них. Мы также начали преобразовывать слова в их корневые формы, чтобы охватить больше случаев, удалять стоп-слова и т. д. По сути, мы становились все более и более удобными для пользователя. Тем не менее, идея, лежащая в основе всего процесса, основана на самом простом поиске по ключевым словам, известном со времен Средневековья, с некоторыми изменениями.
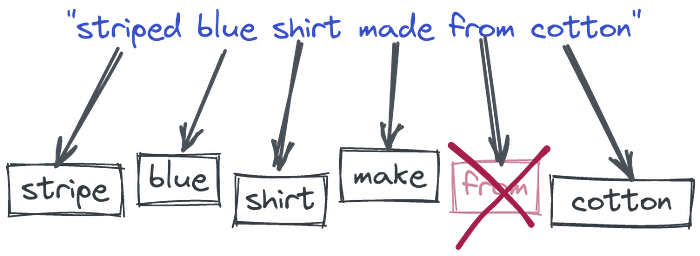
Процесс токенизации с дополнительным удалением стоп-слов и преобразованием в корневую форму слова
С технической точки зрения, мы кодируем документы и запросы в так называемые разреженные векторы, где каждой позиции соответствует слово из всего словаря. Если входной текст содержит определенное слово, он получает ненулевое значение в этой позиции. Но на самом деле ни один из текстов не будет содержать более сотни разных слов. Таким образом, большинство векторов будут иметь тысячи нулей и несколько ненулевых значений. Вот почему мы называем их редкими. И они уже могут быть использованы для вычисления сходства на основе слов путем поиска документов с наибольшим совпадением.

Пример запроса, преобразованного в разреженный формат
Разреженные векторы имеют относительно высокую размерность; равно размеру словаря. А словарь получается автоматически из входных данных. Таким образом, если у нас есть вектор, мы можем частично реконструировать слова, использованные в тексте, создавшем этот вектор.
На пути к повышению надежности поисковых систем
Вавилонская башня
Время от времени, когда мы обнаруживаем новые проблемы с инвертированными индексами, мы придумываем новую эвристику, чтобы хотя бы частично их решить. Как только мы поняли, что люди могут описывать одно и то же понятие разными словами, мы начали создавать списки синонимов, чтобы преобразовать запрос в нормализованную форму. Но это не сработает для случаев, которые мы не предусмотрели. Тем не менее, нам нужно создавать и поддерживать наши словари вручную, чтобы они могли поддерживать язык, который со временем меняется. Еще одна трудная проблема возникает в многоязычных сценариях. Старые методы требуют создания отдельных конвейеров и привлечения людей для поддержания качества.

Вавилонская башня, Питер Брейгель
Революция в представлении машинного обучения
Последние исследования в области машинного обучения для NLP в значительной степени сосредоточены на обучении моделей глубокого языка. В этом процессе нейронная сеть принимает на вход большой объем текста и создает математическое представление слов в виде векторов. Эти векторы создаются таким образом, что слова со схожим значением и встречающиеся в сходных контекстах группируются вместе и представляются похожими векторами. И мы также можем взять, например, среднее значение всех векторов слов, чтобы создать вектор для всего текста (например, запроса, предложения или абзаца).

Векторизация текста с помощью Deep Neural Networks
Мы можем взять эти плотные векторы, созданные сетью, и использовать их в качестве другого представления данных. Они плотные, потому что нейронные сети редко выдают нули в любой позиции. В отличие от разреженных, они имеют относительно низкую размерность — всего сотни или несколько тысяч. К сожалению, если мы хотим посмотреть и понять содержание документа, взглянув на вектор, это уже невозможно. Размеры больше не отображают наличие определенных слов.
Плотные векторы могут отражать смысл, а не слова, используемые в тексте. При этом Модели больших языков могут автоматически обрабатывать синонимы. Более того, поскольку эти нейронные сети могли быть обучены многоязычным корпусам, они переводят одно и то же предложение, написанное на разных языках, в аналогичные векторные представления, а также называемые вложениями. И мы можем сравнить их, чтобы найти похожие фрагменты текста, рассчитав расстояние до других векторов в нашей базе данных.
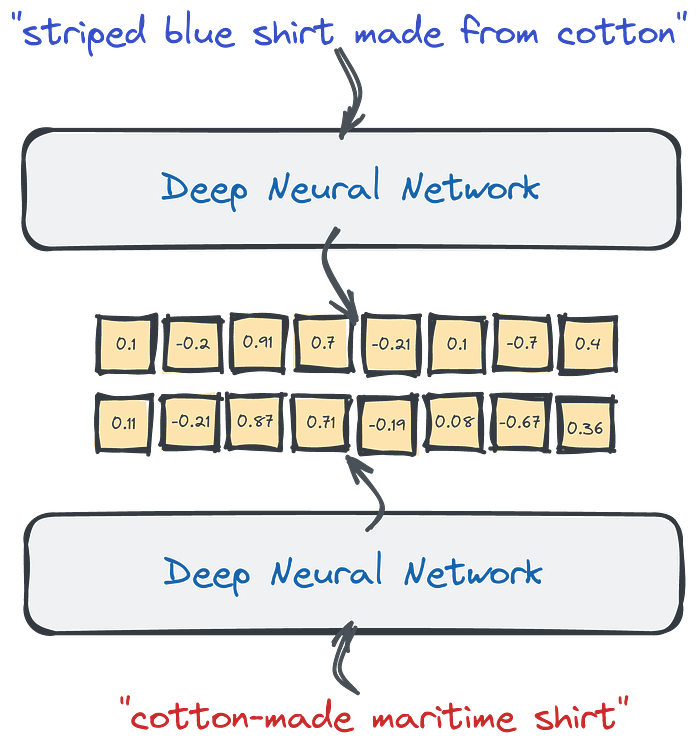
Входные запросы содержат разные слова, но они по-прежнему преобразуются в похожие векторные представления, поскольку нейронный кодировщик может улавливать смысл предложений. Эта функция может фиксировать не только синонимы, но и разные языки.
Векторный поиск — это процесс поиска похожих объектов на основе сходства их вложений. Хорошо, что вам не нужно проектировать и обучать свою нейронную сеть самостоятельно. Доступно множество предварительно обученных моделей либо на HuggingFace, либо с использованием таких библиотек, как SentenceTransformers. Однако, если вы предпочитаете не пачкать руки нейронными моделями, вы также можете создавать вложения с помощью инструментов SaaS, таких как co.embed. API.
Цель Qdrant
Проблема с векторным поиском возникает, когда нам нужно найти похожие документы в большом наборе объектов. Если мы хотим найти самые близкие примеры, наивный подход потребует вычисления расстояния до каждого документа. Это может работать с десятками или даже сотнями примеров, но может стать узким местом, если у нас их больше. Когда мы работаем с реляционными данными, мы настраиваем индексы базы данных, чтобы ускорить работу и избежать полного сканирования таблиц. И то же самое верно для векторного поиска. Qdrant — это полноценная векторная база данных, которая ускоряет процесс поиска за счет использования графообразной структуры для поиска ближайших объектов за сублинейное время. Таким образом, вы вычисляете расстояние не до каждого объекта из базы данных, а только до некоторых кандидатов.

Векторный поиск с помощью Qdrant. Благодаря графику HNSW мы можем сравнивать расстояние до некоторых объектов из базы данных, а не до всех
При выполнении семантического поиска в масштабе, поскольку это то, что мы иногда называем векторным поиском в текстах, нам нужен специализированный инструмент для его эффективного выполнения — такой инструмент, как Qdrant.
Подведение итогов
Векторный поиск — отличная альтернатива разреженным методам. Это решает проблемы, которые у нас были с поиском по ключевым словам, без необходимости вручную поддерживать множество эвристик. Для преобразования текста в векторы требуется дополнительный компонент, нейронный кодировщик. Однако вы также можете выбрать инструменты SaaS для их создания и избежать создания собственной модели. Настроить проект векторного поиска с помощью Qdrant Cloud и Cohere co.embed API довольно просто, если вы будете следовать руководству. .
В векторном поиске есть еще одна интересная вещь. Вы можете искать данные любого типа, если существует нейронная сеть, которая будет векторизовать ваш тип данных. Думаете ли вы об обратном поиске изображений? Это также возможно с векторными встраиваниями.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
Categories
- Технологии и IT (25303)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (270)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
