
Сокращение стандартного времени расчета аудитории на 80 %
8 июня 2022 г.Audiences — один из самых гибких, мощных и активно используемых инструментов на платформе mParticle. Пользователи mParticle могут определять аудитории на основе любых связанных с пользователями данных, полученных из любого источника, будь то стандартный ввод, такой как Интернет, приложение для iOS или Android, или партнерский канал.
После создания аудиторий вы можете легко перенаправить их нижестоящим партнерам по активации, чтобы обеспечить широкий спектр вариантов использования, например стимулировать взаимодействие пользователей и загрузку приложений или визуализировать пути клиентов, и это лишь некоторые из них.
Поскольку Audiences занимает центральное место в ценности, которую клиенты извлекают из mParticle, этот набор функций имеет высокий приоритет, когда речь идет о работе по оптимизации производительности. Вот почему недавно был проведен проект по обновлению Standard Audiences — продукта, расширяющего функциональные возможности обычных Audiences.
В этой статье подробно рассказывается о том, как мы проводили исследования потенциальных областей оптимизации, реализовывали эти возможности и оценивали результаты.
Что такое стандартные аудитории?
Функция Стандартные аудитории на платформе mParticle позволяет определять и создавать аудитории на основе исторических пользовательских данных, которые хранятся в Amazon S3, хранилище долгосрочных данных mParticle.
Поскольку стандартные аудитории основаны на событиях, которые клиенты проводят в течение длительного периода времени, они очень полезны для таргетинга на подгруппы пользователей, которые продемонстрировали высокую пожизненную ценность.
Как рассчитываются стандартные аудитории?
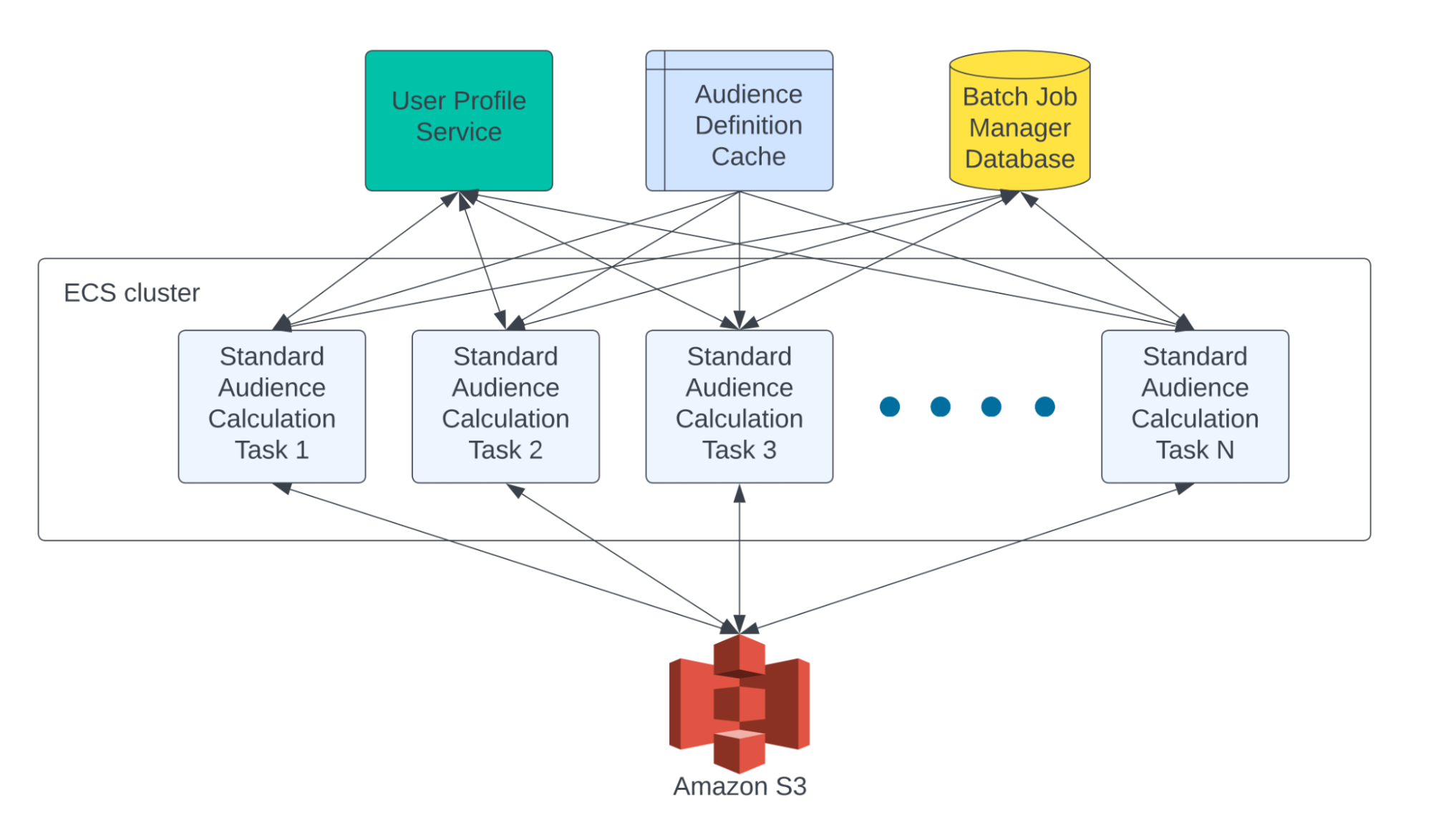
При расчете стандартной аудитории используется тот же движок, что и при расчете аудитории в реальном времени. Основное отличие заключается в том, как профиль пользователя и данные о событиях передаются в движок аудитории.
Расчет аудитории в реальном времени — это задание обработки потока, которое считывает пользовательские события в реальном времени из потока. С другой стороны, расчет стандартной аудитории — это пакетное задание, которое считывается из S3.
Типичное пакетное задание Standard Audience требует чтения многих терабайт (до нескольких петабайт) данных из S3. Таким образом, очевидно, что нам нужно разрезать всю работу на более мелкие части и обрабатывать их одновременно.
Пакетное задание «Стандартная аудитория» может быть представлено в виде DAG (направленного ациклического графа), состоящего из множества независимых задач, каждая из которых отвечает за расчет членства в аудитории для небольшого подмножества пользователей. В конце концов, результаты расчета стандартной аудитории сохраняются в уникальном месте для каждой DAG в S3.
Зависимости задач, статус задач и спецификации рабочей нагрузки задач управляются собственным диспетчером пакетных заданий, который использует базу данных MySQL для хранения группы обеспечения доступности баз данных и данных задач и отправляет задачи в AWS Batch для выполнения.
Определить возможности для оптимизации
Поскольку использование офлайн-аудиторий и объем пользовательских данных в S3 органически росли, мы заметили, что некоторые большие DAG стандартной аудитории, состоящие из сотен тысяч задач, могли выполняться шесть дней, что прерывало рабочие процессы наших клиентов, когда они результатов пришлось ждать почти неделю.
Мы решили исследовать узкие места в системе и выяснить, что мы можем сделать для повышения производительности. Мы добавили больше метрик и журналов для всех шагов в задаче расчета аудитории, и вот что мы обнаружили:
Вывод 1: логику вызовов API можно оптимизировать
Задача расчета аудитории выполняет вызовы API к службе профилей пользователей и диспетчеру пакетных заданий. Когда есть много одновременных вызовов, они могут стать вялыми или возвращать сбои. В случае сбоя задачи она будет повторяться до четырех раз.
Поскольку повторная попытка на уровне задачи влечет за собой запуск задачи с самого начала, это дорогостоящая операция.
Решения:
- Пересмотрите логику вызовов API и сделайте минимально необходимое количество вызовов.
- Правильный размер внешних служб/баз данных, чтобы справиться с рабочей нагрузкой, связанной с самой большой группой обеспечения доступности баз данных для стандартной аудитории.
- Добавить логику повторных попыток с экспоненциальной задержкой с дрожанием для всех вызовов API.
Результат:
- Сокращение времени выполнения и стоимости на 20%.
Вывод 2: требования к памяти для задач могут быть уменьшены
Требование к памяти для каждой отдельной задачи (настроенное в определении задания AWS Batch) составляет 30 ГБ, что было определено наихудшим сценарием.
Большинству задач не требуется столько памяти. Мы могли бы одновременно выполнять гораздо больше задач в одном и том же кластере ECS, если бы уменьшили требования к памяти для каждой задачи.
Решения:
- Уменьшите требуемый по умолчанию объем памяти до 7,5 ГБ. Если задача завершится с ошибкой из-за нехватки памяти, повторите попытку, в два раза превысив требуемую память предыдущего запуска (максимальный объем – 30 ГБ).
Результат:
- Четырехкратное увеличение количества задач, которые мы можем выполнять в том же кластере ECS.
* Двукратное увеличение пропускной способности, сокращение общего времени выполнения и стоимости DAG на 50%. Это 2x, а не 4x, потому что, когда мы запускаем 4x контейнера, используя 7,5 ГБ памяти, каждый контейнер на одном и том же экземпляре EC2, им требуется больше времени для завершения, и небольшой процент из них необходимо повторить с большим объемом памяти. Конечным результатом является примерно двукратное увеличение общей пропускной способности.
Вывод 3. Сделайте логику поиска данных более эффективной
Производительность ограничена операциями ввода-вывода. Большая часть времени уходит на получение данных для подмножества пользователей, за которое отвечает задача расчета офлайн-аудитории.
Поиск данных состоит из двух основных этапов: поиск данных и их загрузка. Поиск данных в S3 означает, что ListBucket вызывается из множества параллельных задач, что относительно быстро, но в совокупности занимает значительное время.
Решения:
- Рефакторинг логики поиска данных таким образом, чтобы небольшое количество вызовов S3 ListBucket могло найти данные для всех задач расчета аудитории. Поместите эту логику в новую задачу, от которой зависят все задачи расчета аудитории.
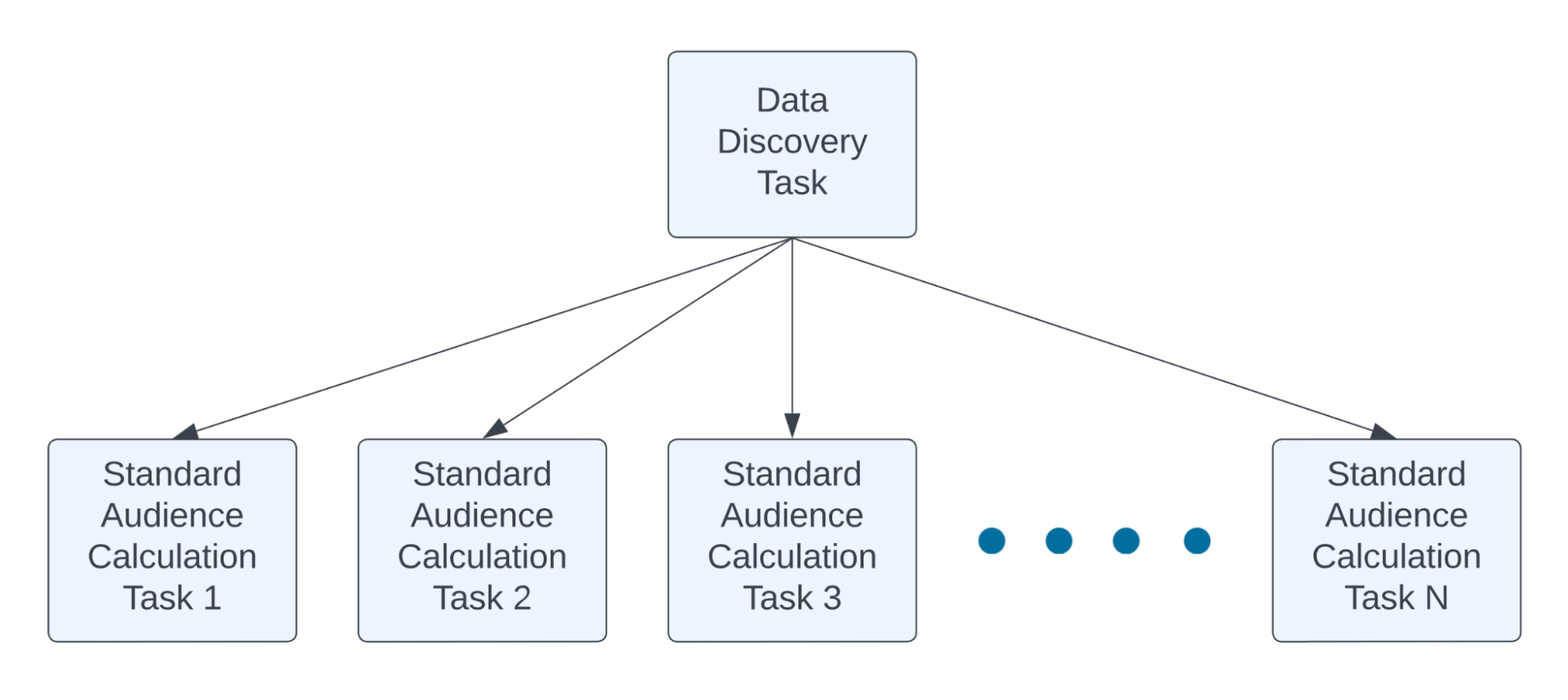
Результат:
- В среднем на 30 % сокращается общее время выполнения DAG.
Вывод 4: размеры разделов можно настраивать
Мы используем спотовые инстансы EC2 в кластерах ECS, управляемых AWS Batch. Это означает, что они могут быть прекращены в любое время. С одной стороны, мы хотим, чтобы каждая отдельная задача завершалась быстро, чтобы, когда они будут уничтожены из-за остановки точечного инстанса, мы не тратили много процессорного времени.
С другой стороны, мы хотим, чтобы каждая отдельная задача была довольно большой, потому что загрузка большего объема данных из S3 за один запрос требует меньших накладных расходов. Это означает, что размер раздела для отдельных задач должен быть настроен. п
Решения:
- Поиск оптимального размера раздела для отдельной задачи с помощью экспериментов.
Результат:
- Сокращение общего времени выполнения DAG на 30 %.
Теперь посчитаем: (1–20%)(1–50%)(1–30%)(1–30%) = 19,6%.
Так мы сократили время и стоимость расчета стандартной аудитории на 80%. Результат очень заметен. Теперь большинство групп DAG для стандартной аудитории завершаются в течение 10 часов, а максимальное время для DAG от наших крупнейших клиентов составляет приблизительно один день.
<цитата>Мы постоянно инвестируем в инфраструктуру, которая обеспечивает результаты для наших клиентов, и это очень ценно. Кроме того, эти проблемы очень интересно решать очень талантливыми инженерами. Этот проект был на пересечении Ценности, Веселья и Таланта, что очень интересно!
– Ли Моррис, старший вице-президент по разработкам
Оптимизация на основе данных
В описанных выше решениях мы использовали подход, основанный на данных, для поиска оптимальных параметров, таких как размер раздела или начальные требования к памяти. В частности, мы повторно запустили несколько DAG с разными параметрами, извлекли показатели производительности, а затем сравнили результаты с помощью ноутбуков Jupyter.
Мы не угадываем. Мы позволяем данным говорить самим за себя.
Метрики и мониторинг
Чтобы отслеживать производительность и стоимость групп DAG стандартной аудитории, мы добавили метрики для отслеживания событий, отсканированных для каждой группы обеспечения доступности баз данных, байтов, прочитанных для каждой группы обеспечения доступности баз данных, общей задержки для каждой задачи и времени, затрачиваемого механизмом расчета аудитории для каждой задачи, используя < strong>автоматизированная отчетность о расходах, созданная нашей собственной командой по обслуживанию данных.
Мы внедрили две версии этих метрик: одну для внутреннего мониторинга, а другую для метрик, ориентированных на клиентов. Например, для событий, просканированных в группе обеспечения доступности баз данных, мы отслеживаем фактическое общее количество событий, просканированных в каждой группе обеспечения доступности баз данных, для внутреннего мониторинга (включая события, просканированные сбоями, а затем повторными задачами), и отслеживаем общее количество событий, просканированных в результате успешных запусков задач в каждой группе обеспечения доступности баз данных, для целей выставления счетов клиентам.
Если некоторые задачи в группе обеспечения доступности баз данных были повторены, мы должны знать об этом, но мы не должны взимать с клиентов плату за повторные попытки.
Проанализировав показатели производительности, мы смогли установить SLO для групп DAG Standard Audience. Одним из ключевых SLO является общая задержка DAG в 24 часа. Мы настроили мониторинг DataDog для SLO, чтобы получать оповещения в случае их превышения.
Будущая работа
После этих оптимизаций стандартная аудитория по-прежнему требует большого количества операций ввода-вывода. Мы считаем, что можем улучшить производительность следующими способами.
- Создайте более качественные индексы для данных о пользовательских событиях на S3, сократив объем передаваемых данных.
2. Добавьте постоянные контрольные точки в задачу расчета стандартной аудитории, чтобы она могла возобновиться с того места, на котором она остановилась, если она будет остановлена из-за завершения спотового экземпляра.
3. Разработайте более совершенные схемы разбиения, чтобы избавиться от горячих разделов. Это разделит работу на разделы более равномерного размера.
Мы упрощаем начало работы и поддерживаем ценность, которую мы обеспечиваем. Вот почему мы предлагаем лучшую в отрасли многофункциональную бесплатную пробную версию на 30 дней. Зарегистрируйтесь сейчас!
Оригинал