
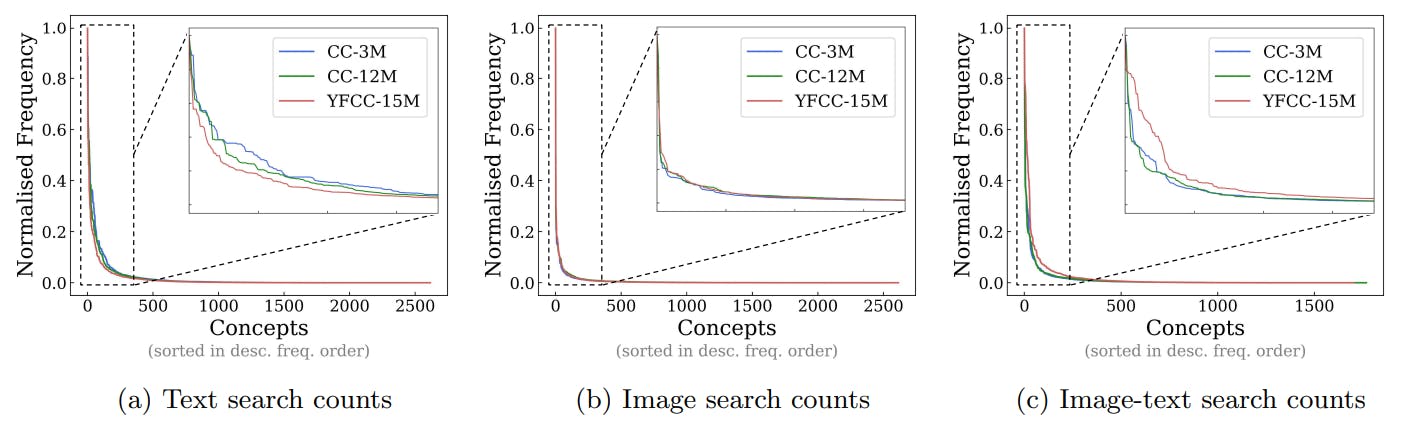
Модели ИИ, обученные синтетическим данным, все еще следуют тенденциям частоты концепции
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
4 стресс-тестирование тенденции масштабирования концепции частоты производительности
В этом разделе мы стремимся выделить влияние частоты концепции на производительность с нулевым выстрелом, контролируя широко известный влиятельный фактор [127, 79]: сходство в распределении между предварительными и нижестоящими данными тестов. Кроме того, мы стремимся подтвердить нашу гипотезу, изучая взаимосвязь между частотой концепции и эффективностью нижней части на моделях, обученных предварительному образующемуся данным с синтетически контролируемыми распределениями концепций, изображениями и подписями.
4.1 Контроль аналогичных образцов в предварительных и нижних данных
МотивацияПолем Предыдущая работа предположила, что сходство на уровне выборки между предварительной подготовкой и наборами данных вниз по течению влияет на производительность модели [62, 79, 127, 94]. Это оставляет открытой вероятность того, что наши результаты частоты производительности являются просто артефактом этого фактора, то есть, поскольку частота концепции увеличивается, вполне вероятно, что набор данных предварительного подготовки также содержит более похожие образцы с тестовыми наборами. Следовательно, мы исследуем, остается ли частота концепции прогнозирующей производительности нижней части после контроля сходства на уровне выборки.
НастраиватьПолем Мы используем набор данных LAION-200M [10] для этого эксперимента. Сначала мы подтвердили, что модель Clip-Vit-B-32, обученная набору данных LAION-200M (используется для изучения сходства образцов в предыдущей работе [79]), демонстрирует аналогичную логарифмическую тенденцию между частотой концепции и ноль-выстрелами. Затем мы используем метод почти обрезки от Mayilvahanan et al. [79] Чтобы устранить 50 миллионов образцов, наиболее похожих на наборы тестовых наборов из набора данных Pretristing Laion-200M. Мы предоставляем подробности для этого в Appx. E.1. Это удаляет наиболее похожие образцы между предварительной подготовкой и тестовыми наборами. Мы проверяем, что эта процедура резко влияет на производительность модели в результате выполнения нашей совокупной классификации и поиска соответственно, реплицируя результаты Mayilvahanan et al. [79].
Ключевой вывод:Частота концепции по -прежнему прогнозирующая производительность.Мы повторяем наш анализ по моделям, обученным этим контролируемому набору данных предварительного подготовки с 150 -метровыми образцами, и сообщаем результаты на одних и тех же наборах классификации и поиска нижестоящих классификаций и поиска на рис. 4 (слева). Несмотря на удаление наиболее похожих образцов между предварительной подготовкой и тестовыми наборами, мы по-прежнему постоянно наблюдаем четкую логарифмическую линейную связь между частотой концепций тестовых наборов предварительной подготовкой и характеристиками с нулевым выстрелом.
ЗаключениеПолем Этот анализ подтверждает, что, несмотря на удаление предварительных образцов, тесно связанных с наборами тестирования, логарифмическая связь между частотой концепции и ноль-выстрелом сохраняется. Обратите внимание, что это несмотря на существенное снижение абсолютной производительности, подчеркивая надежность частоты концепции в качестве показателя производительности.
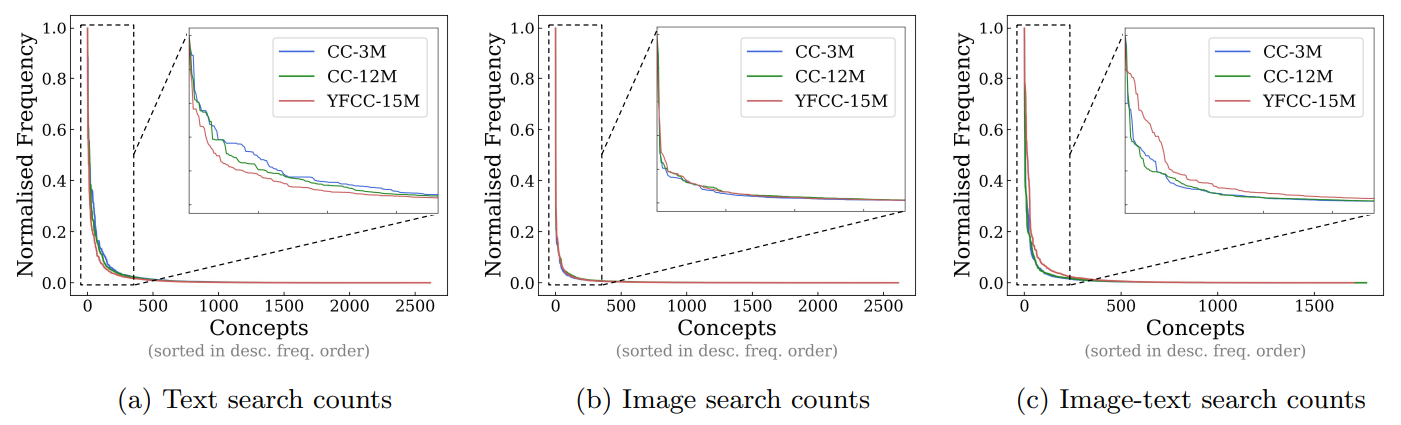
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
МотивацияПолем Отбор выборки в реальных данных может не привести к значительным различиям в распределении концепций, как мы позже покажем в гл. 5. Следовательно, мы повторяем наш анализ на синтетическом наборе данных, разработанном с явно различным распределением концепций [51]. Эта оценка направлена на понимание того, остается ли частота предварительного подготовки концепции значительным предиктором производительности в рамках синтетического распределения концепции, обобщая даже на моделях, предварительно предварительно подходящих на совершенно синтетических изображениях и подписях.
НастраиватьПолем Набор данных Synthci-30M [51] вводит новое распределение концепций, генерируя 30 миллионов паров с синтетическим текстом изображения. Используя общедоступные данные и модели из этого эталона, мы исследуем взаимосвязь между частотой концепции и эффективностью модели в этом режиме синтетических данных.
Ключевой вывод:Частота концепции по -прежнему предсказывает производительность.Мы сообщаем результаты по моделям, обученным их контролируемому набору данных на рис. 4 (справа). Мы по-прежнему постоянно наблюдаем четкую логарифмическую связь между частотой концепции и ноль-выстрелом.
ЗаключениеПолем Эта согласованность подчеркивает, что частота концепции является надежным индикатором производительности модели, расширяющей даже до совершенно синтетически сконструированных наборов данных и предварительных распределений концепции.
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал